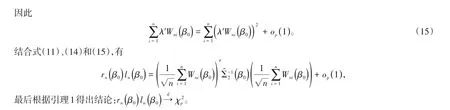右删失数据下半参数线性转换模型的经验似然推断
2021-01-26刘宇,李霓
刘 宇,李 霓
(海南师范大学 数学与统计学院,海南 海口 571158)
右删失数据是删失数据中最常见的一种,经常出现在医学研究和临床试验。在试验中,试验的时间是固定的并且每一个被研究的对象是以不同的时间进入试验中。在试验研究中,一些被研究的对象可能在研究未结束之前就已经死亡,这种情况下,他们的生存时间是确定的;而有些被研究的对象可能在试验研究未结束之前中途退出或者突然失踪,对于这种情况,他们的生存时间存在删失;除了之前所提及的情况,还存在一些被研究的对象在试验结束之后仍然存活,因此他们的生存时间至少是进入试验研究到研究结束这段时间。由于右删失的存在,对回归参数的估计通常使用秩估计方法,然而这种估计方法的算法很复杂并且参数的方差不容易被计算,因此,本研究考虑使用经验似然方法进行统计推断。
经验似然的方法是由Owen[1-3]提出,其思想起源于Thomas和Grunkemeier[4],该方法是一种非参方法并且对数据的分布函数不需要做任何的假设,与传统的正态逼近方法的不同之处是不需要估计协方差去构造置信区间,自Owen 将经验似然方法引入统计研究领域以来得到了广泛的应用。Qin 和Lawless 介绍了经验似然方法以及该方法的核心估计方程[5]。Qin和Jing考虑了经验似然方法在部分线性模型下的应用,并通过数值模拟比较传统的渐近正态方法,结果表明经验似然方法的结果明显优于渐近正态方法[6]。Zhang和Zhao为区间删失时间数据的线性变换模型提出了经验似然方法[7]。
无偏转换量法是处理右删失数据的一种有效的方法,该方法有三种类型:Buckley-James估计[8-9]、KSV估计[10]和Class K估计,其中KSV估计是Class K估计的一种特殊情形。在一般的模型研究中,首先采用合成数据方法将右删失数据完整化,即用合成变量代替响应变量,并且二者的期望是相等的,之后应用经验似然方法估计未知参数。如Li 和Wang 在对右删失数据下的线性模型进行经验似然推断中考虑了Koul、Susala 和Ryzin的KSV方法,并在此基础之上构造了调整因子,得到的调整经验似然统计量收敛于标准的卡方分布,提高了线性模型中未知参数置信区间的精度[11]。Qin等利用KSV方法对删失数据进行处理分析,研究了部分线性模型中的经验似然推断[12]。孙志猛等提出了基于KSV 方法的线性变换模型回归系数的经验似然推断[13]。邓文丽等对删失的响应变量运用无偏转换量,并利用最小二乘方法得到回归系数的估计,其估计具有相合性和渐近正态性[14]。Fang等基于线性模型提出了一种新的经验似然方法,在此过程中使用了Buckley-James估计,证明了KSV方法比Buckley-James需要更强的假设,并且进行了数值模拟研究,结果显示该方法优于Li和Wang的方法[15]。
本研究基于线性转换模型,采用Buckley-James估计将右删失数据完整化,并对完整化后数据进行经验似然推断,之后进行了数值模拟,模拟结果显示在较弱的条件下,本研究所提出的方法优于孙志猛等的方法。最后,给出了引理和定理的证明。
1 统计模型和推导过程

若H和μX是已知的,检验假设H0就等于H。然而H和μX是未知的,因此需要估计H和μX的值并且将其代入式(3)中。首先对于μX,用样本均值-X作为其估计值;其次对于H,采用Chen等基于鞅的性质得到的H的有效估计值Ĥ[16]。将所得到的估计值Ĥ和-X代入式(3),记


2 数值模拟
为了更好地评估所提出的经验似然方法的性能,本研究进行了数值模拟,把基于Buckley-James方程所提出的经验似然方法(ELBJ)和孙志猛等基于KSV方法所提出的经验似然方法(ELSD)[13]相比较。模拟研究中考虑了两种模型:模型1,协变量X的分布是伯努利分布且成功概率为0.5,删失变量C的服从均匀分布[0,c],其中c决定删失率,ε的分布是零均值的极值分布;模型2,协变量X服从正态分布N(0,0.52),其他变量与模型1的选择是相同的。
在这两种模型中,H选取自然对数函数,回归参数β= 1,响应变量T由各个模型生成。此模拟研究考虑的删失率(CR)为15%、30%、45%,样本容量( )n为60、80、100。两种模型所得出β的置信区间覆盖率分别展示在表1和表2。

表1 模型1中β的置信区间覆盖率Table 1 Coverage probabilities of confidence region for β in model 1

表2 模型2中β的置信区间覆盖率Table 2 Coverage probabilities of confidence region for β in model 2
从表1和表2中很容易看出,在这两种模型中,β的覆盖率均接近正态水平且当删失率增大时,β的覆盖率减少。在删失率较大且样本量小时,基于Buckley-James方程的经验似然方法得出的β的覆盖率明显优于基于KSV方法的经验似然方法,此时显示出文中所提出的方法是有效的。
3 引理和定理的证明