基于高速公路货车收费数据库的全息样本遴选
2021-01-22黄秋实
马 暕, 黄秋实
(长安大学 经济与管理学院,西安 710064)
一、引言
在统计学范畴,很多时候研究者无法选择所有数据进行调查,一般采用从整体中抽取样本进行调研。抽样即为了得到总体的某些特征及分布信息,按照一定规则,从总体中抽取若干个体进行观察实验的方法,抽取的个体即样本。定理表明,当样本容量足够大时,样本分布函数依概率收敛于总体分布函数,这是用样本推断总体的理论依据。在目前的高速公路流量分析研究中,虽然大数据技术已不断完善,但考虑到处理海量数据的冗繁性,大而全的数据并不一定比合理的样本数据对流量分析研究更加方便,反而会在一定程度上造成人力、物力的浪费,这一点在下文处理国内某省全年的高速公路收费流水数据库时就有所体现,因此抽样仍是一种必不可少的研究手段。在目前的主流抽样方式中,对样本的选择有一套传统的方法,但这些选择方法在实际高速公路流量分析中适用性不强,也很少有研究者能够严格按照要求进行,样本选择存在一定的随机性,导致分析结果存在一定程度的偶然性。针对此情况,从大数据角度出发,运用大数据的处理方法,压缩全年数据,尽可能将完整的数据库压缩到一个可接受的最小样本范围,如果这个样本能够完整反映数据库中的全部有用特征,压缩后的样本可认为是理想中的全息样本。寻找到这个全息样本,就可以在以后的高速公路流量分析中达到便于处理且真实反映全体特征的目的,有效节约人力、物力。
为了解决这个问题,本文主要论证如何选择一个最能代表全年流量特征的全息样本,以国内某省高速路网一年的完整数据来分析,利用Python、SPSS、Matlab等软件,找出一个能够代表全年趋势与特点的全息样本,作为日后高速公路流量分析的数据样本。确定样本容量时,考虑到实际工作中使用的便捷与分析的直观,选择自然月份这一时间范围作为样本容量,在此基础上将全年十二个月的数据单独提取整理。为能全面反映交通流量的多维度特征,从数据库中将字段分类,建立基于时间结构、空间结构、轴型结构三个维度的相似评价体系,进而计算三种维度下的各月和周及天分时段车辆到达数据、OD分布数据、车轴组成数据与全年对应数据之间的距离接近度及形状相似度,并通过熵值法赋予距离接近度和形状相似度相应的权重,整合数据,定义出不同样本与全年数据之间的离散度。根据计算出的离散度,对不同样本与全年的相似性排序,离散度最低的样本可认为是符合要求的全息样本。
关于高速公路收费流水数据库全息样本的研究,有不少学者研究与探讨了高速公路收费数据库与数据相似性度量。在高速公路收费数据库研究方面,有的学者分析与高速公路流量相关的数据指标类型,有的运用收费数据库进行预测分析研究。王维凤等研究与公路流量关联度较高的主要指标,并进行预测[1-2]。袁长伟对高速公路中的货车流提出收费车型结合轴型的组合分层统计方法[3]。杨洁等采用动态时间弯曲距离作为相似性度量指标,分析城市干道交通流量信息[4]。杨春霞等以短时交通流预测为切入点,分析了流量数据[5-11]。胡闰秀和李梦雪提出基于收费数据的车型数据转换方法来计算断面交通量[12]。
而针对高速公路收费数据库中的数据,主流的定义更多是将其归类到时间序列数据来讨论,本文所探讨的全息样本遴选可认为是在高速公路收费数据库中进行时间序列数据的相似性探究。自Agrawal等首次提出使用离散傅里叶变换将时间序列的时间域转换为频率域,并将其应用于时间序列相似性搜索开始,时间序列数据相似性度量的研究方法越来越丰富[13]。董晓莉等研究基于形态相似距离的时间序列相似性度量方法,并给出相应的距离公式,以度量时间序列的相似性[14-16]。弓晋丽针对城市道路交通流数据,讨论5种模式相似性距离的聚类效果[17]。陈海燕等综述了常用的相似性度量方法[18]。董建华等主要通过PAC来判断水质相似度[19]。周永通过用户签到数据描绘用户的轨迹路线,并对其兴趣区域进行相似性度量[20]。Cha等为了获得更多关于数据模式和特征的信息,考虑用一个带幂的模糊测度来测算相似度[21]。李建勋等将时空数据趋势状态表征为图像的结构信息,以趋势面图像之间的相似度来表征时空数据的相似度[22]。Clapper等通过控制两个结构上可对齐的对象共享部分的比例,来确定相似性是否会对自由分类产生分级影响[23]。Liu Dong等基于相似性的偏好顺序技术,提出基于加权马氏距离和灰色关联分析的理想解决方案评估模型[24]。王慧通过面板数据的接近性和相似性判断关联度的方法进行公理化的证明[25]。
通过相关文献的分析可以发现,关于高速公路收费数据库研究中,研究者多是直接运用数据库或根据主观判断选择样本进行研究与分析,没有学者系统讨论样本的选择,这一现象在众多的交通调查中非常普遍。关于时间序列数据相似性度量研究中,大多处于相似性证明方法的探究,属于方法论的层面,未将时间序列数据相似性度量与具体的现实问题结合。针对这两方面的问题,将时间序列数据的相似性探讨运用到高速公路收费数据库的样本寻找中是本文拟讨论的问题。通过现有较为成熟的距离接近度与形状相似度两种相似性度量方法,压缩高速公路货运收费流水数据库,探寻能够表示全年特征的最小全息样本,从而为今后的交通流量分析研究提供一个合理的样本选择策略。
二、基础概念
(一)全息样本
全息片段概念用在高速公路交通流量分析领域,主要意在寻找一个可以代表全年交通流量特征的时间片段。寻找的这个时间片段要能代表这一年中交通流的各方面数据特征,例如到达时间分布、车轴结构、OD数据分布等。样本若想代表全年的交通流量特征,仅凭某一维度的数据衡量是不够的,本文讨论的全息样本应基于多个维度的数据支持之上。倘若这个时间段的数据均符合要求,就可以把这个时间段称为“全息样本”。全息样本的确定可以使研究者选取样本时,能够尽可能地排除主观因素的影响,且不用对整体冗繁的数据再次筛选分析,大大节约交通预测过程中的人力、物力。在具体分析过程中,出于现实预测便于使用需要,也为了使结果更直观且易于检测,分别以月份、周数、天数为样本区间来划分一年的数据,并以此求取分析离散度结果。
(二)形状相似度与距离接近度
针对时间序列数据进行相似度分析,可采用灰色关联分析基本思想中的两大类方法:一是根据时间数据序列曲线几何形状的相似程度来判断关联程度的大小,二是根据时间数据序列的接近程度来判断关联程度的大小。对于空间中的向量而言,一方面向量夹角越小,表示相似程度越高,关联程度越大;另一方面,两向量之差的模长越小,表示两组数据间的距离越小,关联程度越大。因此,可以利用向量夹角和向量差的模长来描述相似性与接近性关联度。
对两组向量数据之间的夹角即形状相似度可通过公式(1)计算
(1)
对两组向量数据的模长即距离接近度可通过公式(2)计算
(2)
在上述公式中,
根据这些理论,对两组面板数据之间的相似判断分为数值接近度与形状相似度两个角度讨论。对数值型数据主要根据欧氏距离讨论两组数据之间的接近程度,对比例型数据则主要根据向量夹角来讨论两组数据之间的形状相似程度,并将得出的两组结果进行熵值法加权,得出样本评分加以对比。
(三)离散度
采用上述方式处理数据后,通过熵权法确定不同维度形状相似度与距离接近度的权重,并加权得到修正后的样本相似度评分。
由于各项指标的计量单位不统一,在计算综合指标前,先进行标准化处理,即把指标的绝对值转化为相对值,从而解决各项指标的同质化问题。考虑到Matlab进行熵值法运算时的适用性问题,选择正向极值法作为标准化方法,如公式(3)所示
(3)
通过这种方法标准化的数据虽然一定程度上保留了原数据的差异化,但因为距离接近度与形状相似度两个数据属于负向数据,数值越大,表示对应的关联度越低,因此将相似度评分计算结果定义为离散度,这一数值与关联度相对应,离散度数值越大,表示关联度越低,反之亦然。
三、数据说明与相似评价指标体系构建
(一)数据说明
高速公路收费站数据以车辆在高速公路两收费站间的一段行程作为一个体,数据中包括车辆的众多运行信息,但其中有部分数据与流量分析相关性不强。整理与选择数据库中的可用数据,表1为一个体中的有用数据字段。

表1 国内某省高速收费公路数据字段说明
(二)相似评价指标体系构建
基于全息样本的多特征要求,本文考虑根据收费公路数据库中字段,选择构建全息样本相似评价指标体系。指标选择方法主要根据分析中常用的“5W1H”法,即“Why、What、Where、When、Who、How”,并结合交通流量的实际特征与数据库数据的具体内容,考虑到运输目的、运送人员、运输货物内容等与本研究的契合度较低,且在收费数据库中难以量化,选择根据时间结构、空间结构、轴型结构三个维度来构建全息样本相似评价指标体系。
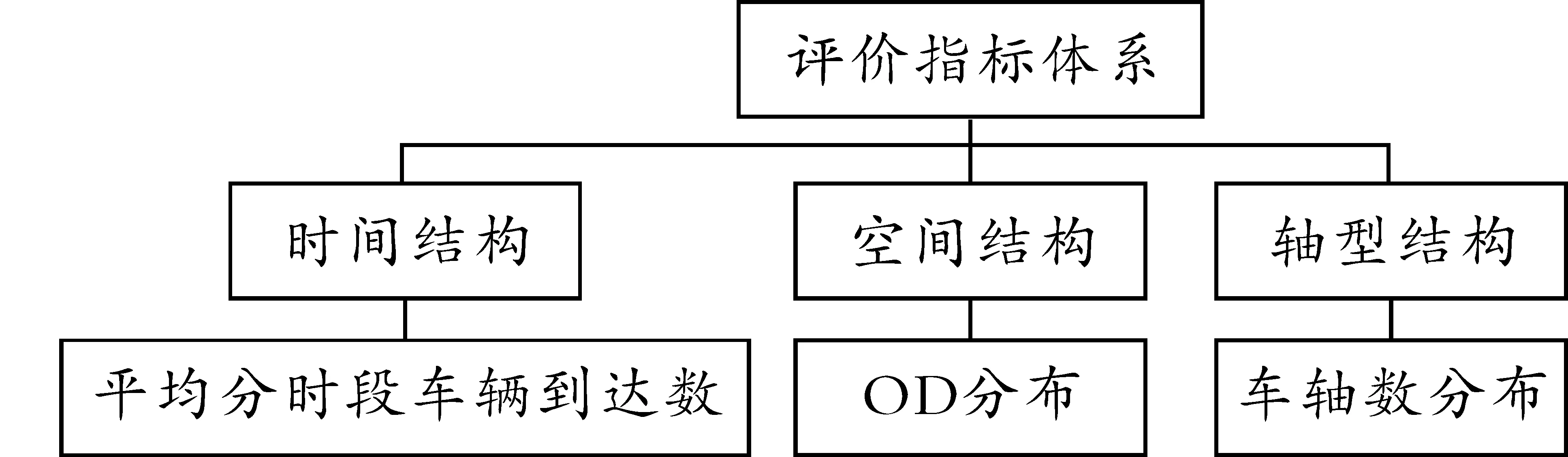
图1 评价指标体系
其中,由入口时间整理出来的平均分时段车辆到达数可作为时间结构维度的主要考量数据,即何时车辆进入收费站;由入口站点与出口站点整理出来的OD分布数据可作为空间结构维度的主要考量数据,即车辆由哪来、到哪去的问题;针对车辆运行的多个要素,如车型、车轴、车重等,考虑到近期国家提出的将收费方式转变为按轴型收费的政策,选择车轴分布数据作为最后一个要素维度,也就是轴型结构维度的考量数据,这一评价指标在一定程度上能够代表运送货物的车辆自身信息与车重信息。根据相关指标,确定后的全息样本相似评价指标体系如图1所示。
若两组高速公路收费流水数据在三个维度的数据分布上均表现为距离接近、角度相似,就可以认为两组数据符合相似性的定义。
四、实例分析
全息样本讨论以国内某省2017年11月—2018年10月为期一年的27 330 513条高速公路货运收费流水数据为依据进行分析。
(一)全息“月份”遴选
针对国内某省为期一年的高速公路货运收费流水数据,排除一些错误数据后,运用SPSS软件,以小时为单位,统计月平均分时段车辆到达数、月平均OD分布数据(175*156型矩阵)、月平均车轴构成数据。对数据进行比例处理,因篇幅有限,具体数值及处理结果略。依据公式(1)(2),求取三个维度各月份与全年数据之间的距离接近度和形状相似度,两者用角度与距离表示,结果见表2。
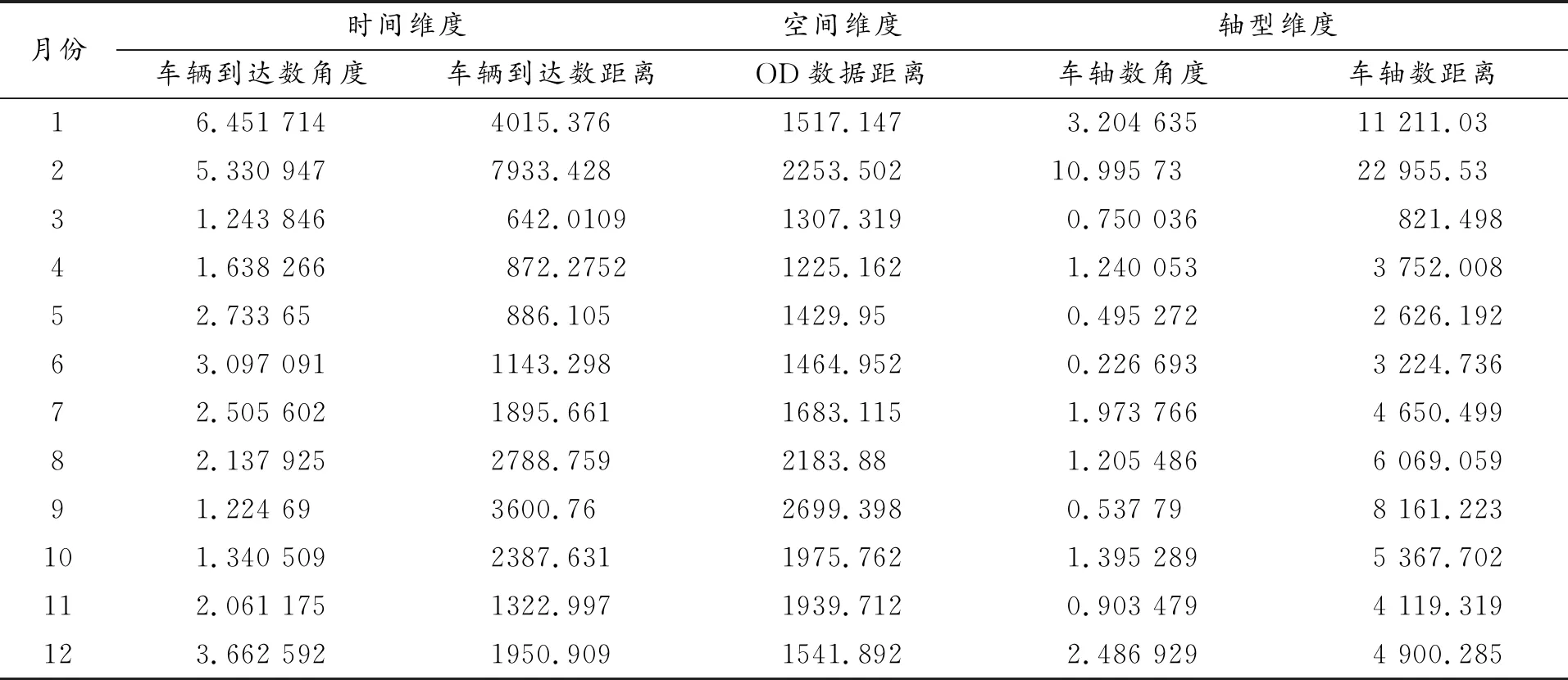
表2 三维度平均形状相似度与距离接近度数据(月)
针对表2的数据,时间维度数据与结构维度数据采用熵值法,对角度与距离进行加权运算,得出对应维度离散度得分,空间维度因OD矩阵无法求取角度数据,故对OD数据距离结果进行归一化处理,与其余两维度保持统一度量。处理方式如下
(4)
处理后离散度得分见表3。
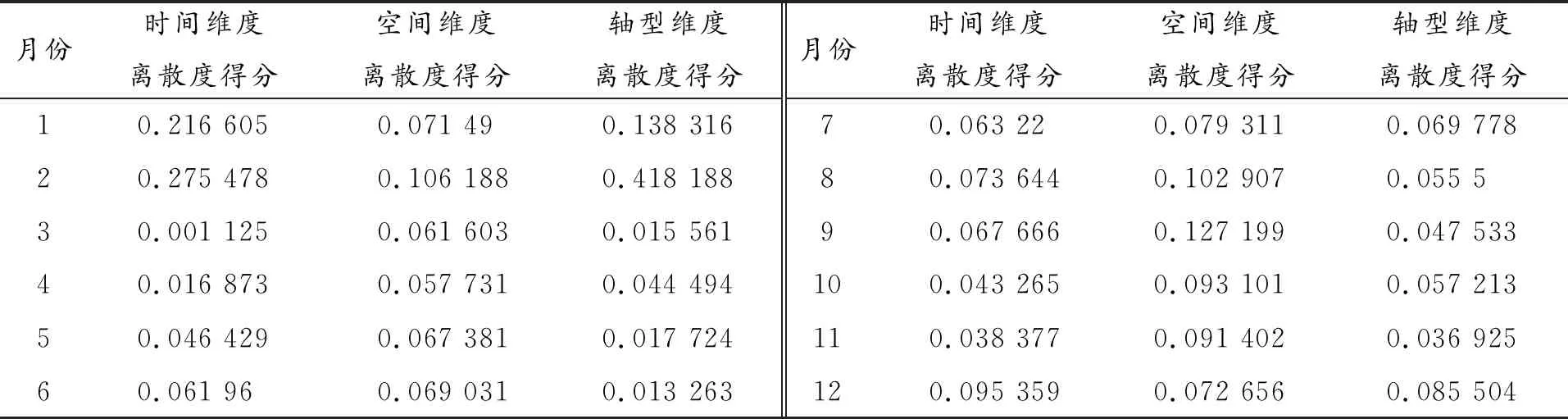
表3 三维度离散度得分(月)
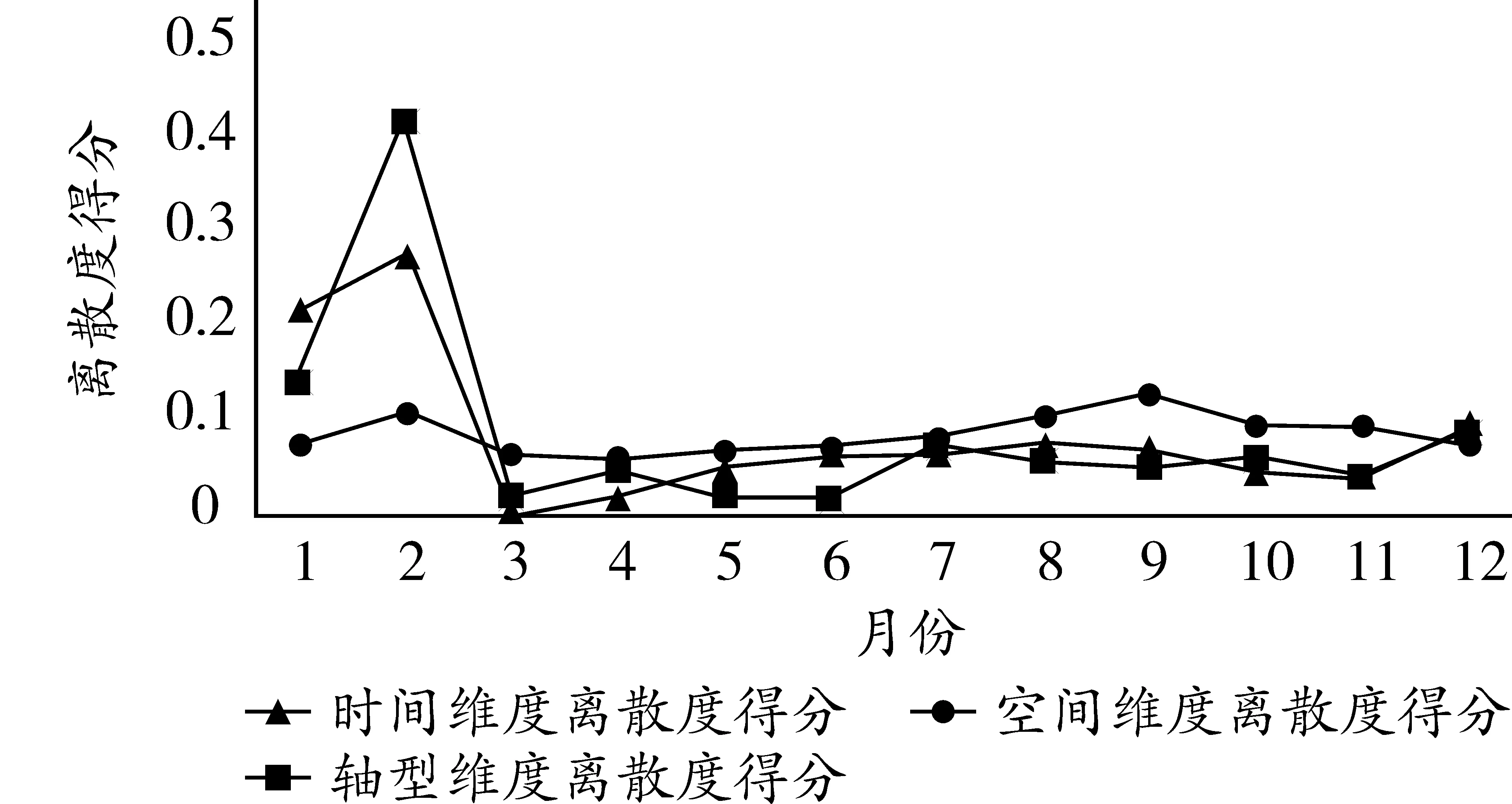
图2 三维度月离散度得分
由图2可以发现,三个维度虽然大致趋势类似,但离散度最大和最小的月份有出入。其中,时间维度离散度最高的是二月,离散度最低的是三月;空间维度离散度最高的是九月,离散度最低的是四月;结构维度离散度最高的是二月,离散度最低的是六月。这说明如果不是特定的研究需要,任意单一维度对全年的代表性均有一定瑕疵,不能完整反映交通流量的所有特征。综合考虑三个维度,进行全息样本遴选。
针对这个问题,对表3中的三个维度数据进行熵权法赋权处理,得到表4和表5。

表4 各指标权重得分(月)

表5 综合维度离散度得分(月)
将表5的离散度得分反映到图3。
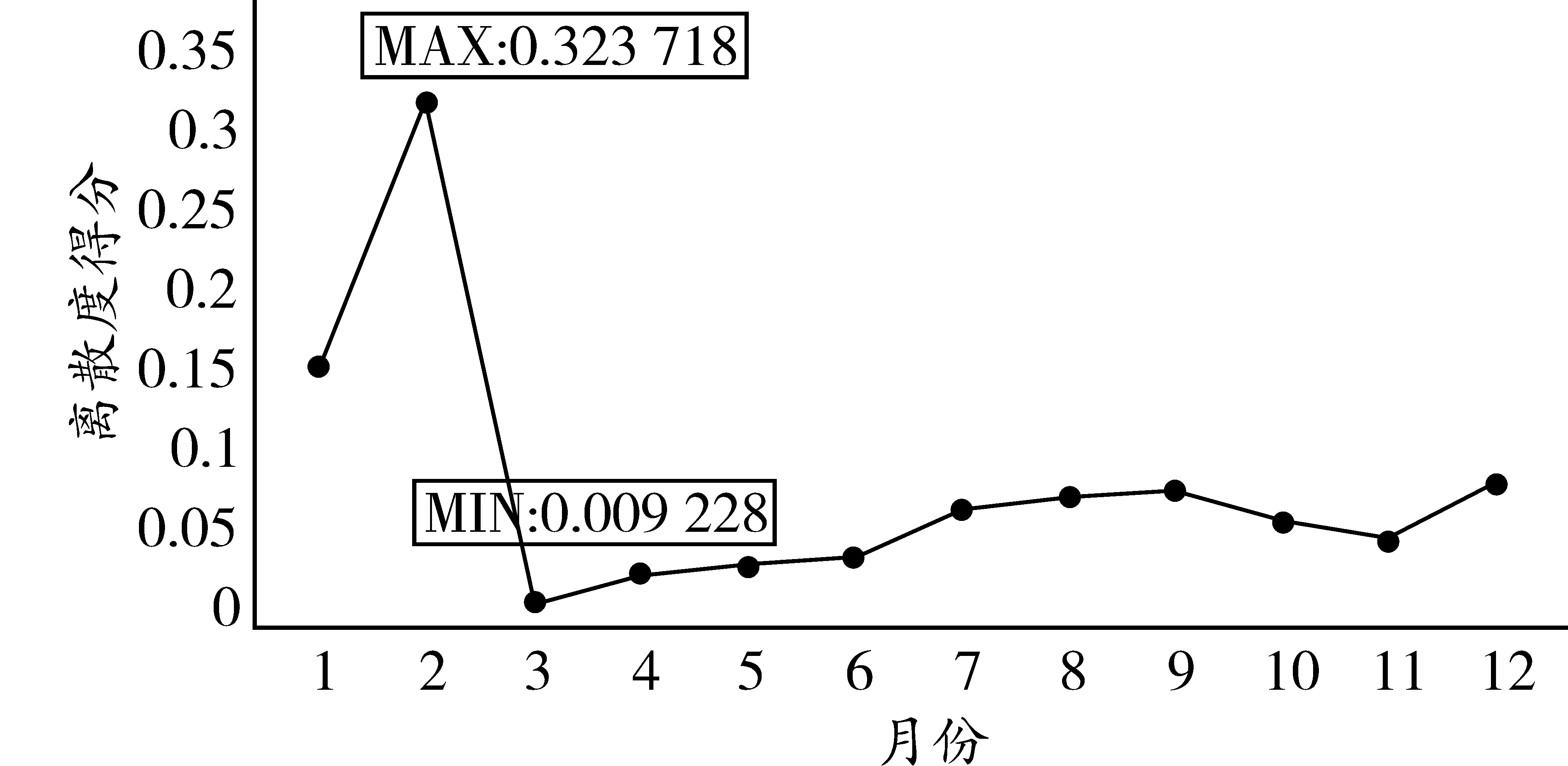
图3 综合维度月离散度得分
由图3可以发现,三月是与全年离散度最低的月份,其次是四月与五月,而二月的数据则与全年数据有着较大的差别。在具体研究中,为了更精确的研究,可以采用三月的数据代表全年数据进行预测。
为验证上文得出的结论,拟对几个典型月份与全年数据进行图表描述对比。通过分析全年各月份的离散度,决定选用一月、二月、三月、五月、九月、十一月的数据与全年对比,以便更直观地体现全息月份的拟合度。可以发现,三月、五月与全年数据有较高拟合度,而离散度最高的二月则在数据量上差别较大,但趋势均类似。
(二)全息“周”遴选
与全息月份遴选过程类似,继续细分时间区间,根据常用日期所示的自然周进行相似度分析,即将2018年1月1—7日作为一周,结果见表6。
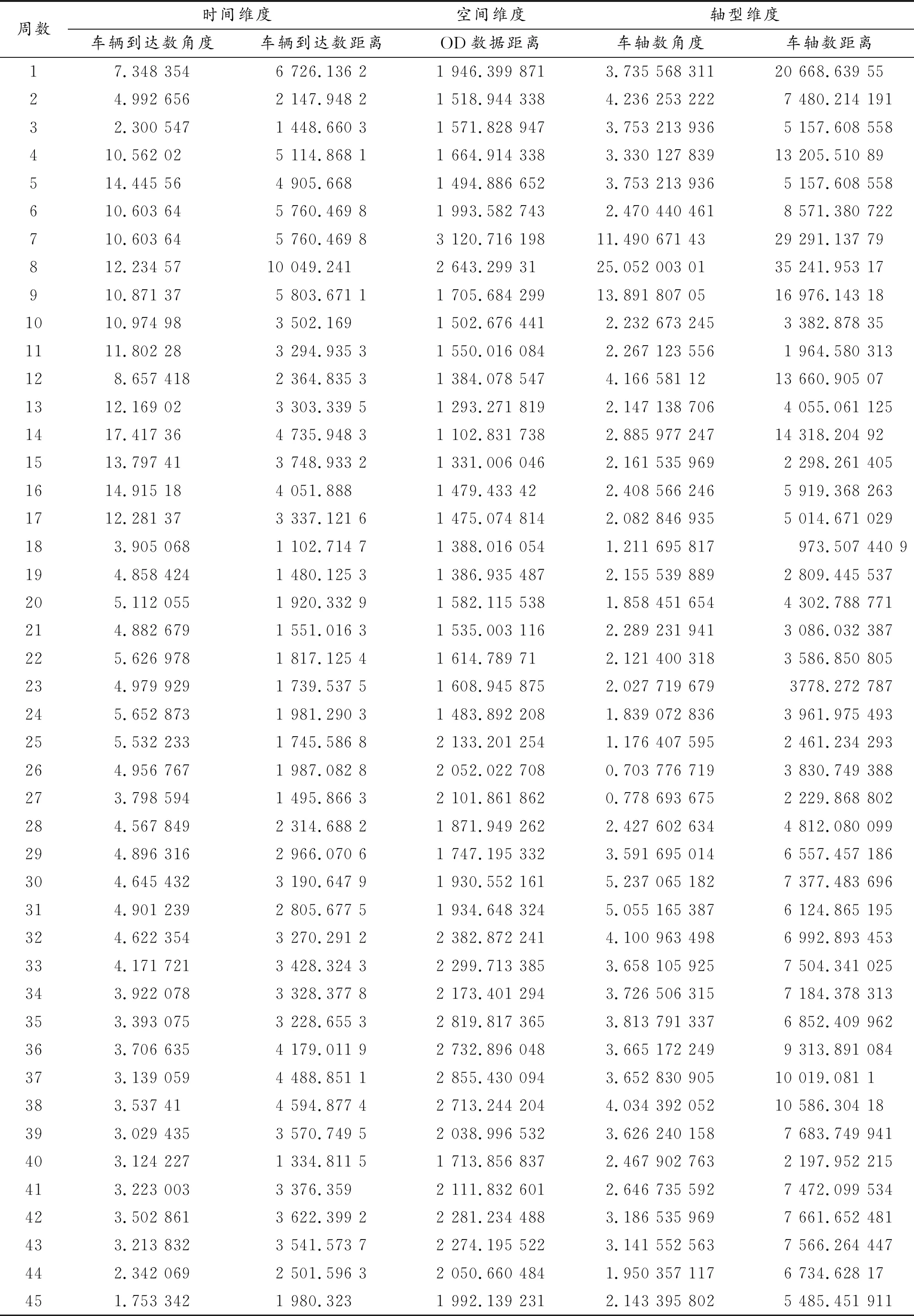
表6 三维度平均形状相似度与距离接近度数据(周)
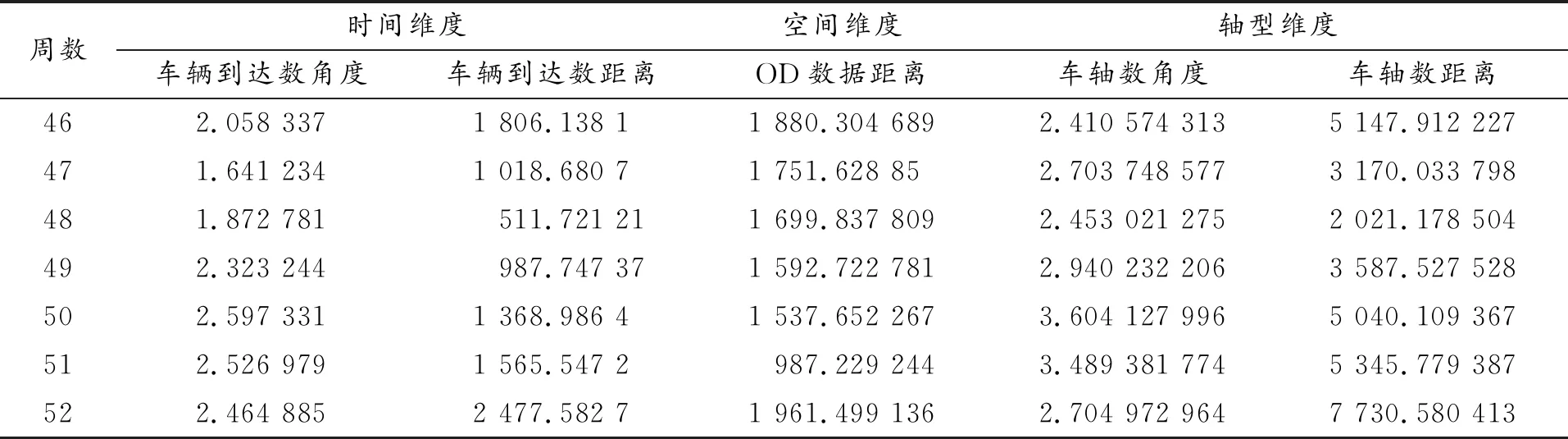
续表
针对表6的数据,通过熵值法确定权重,得到表7和表8。

表7 各指标权重得分(周)
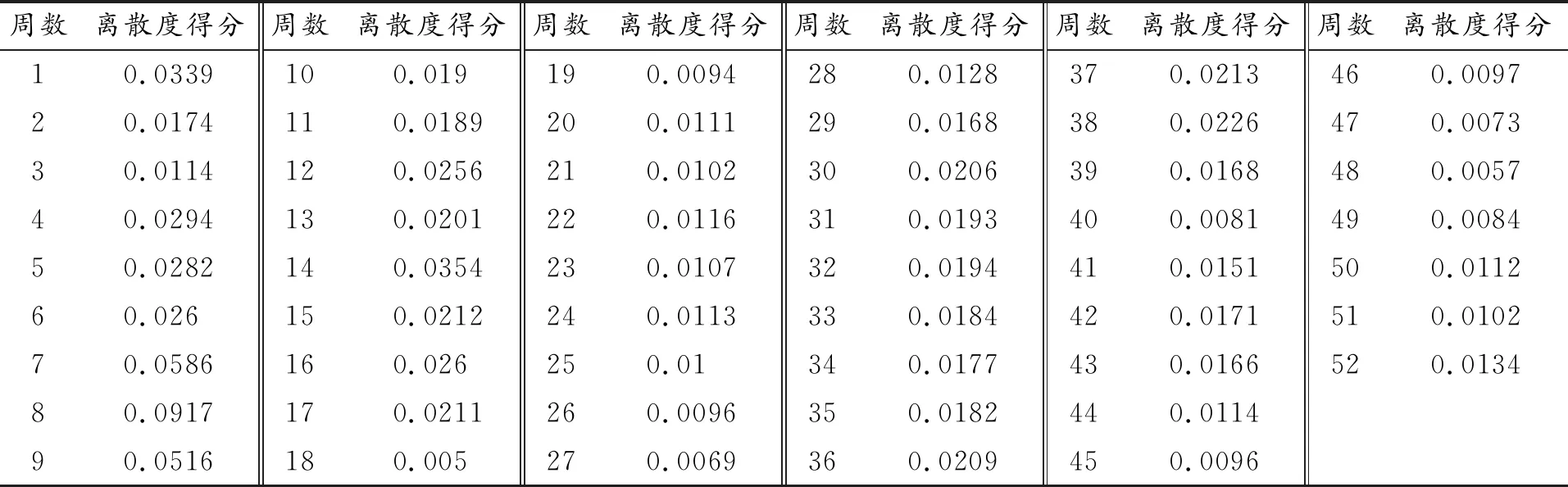
表8 综合维度离散度得分(周)
考虑到周一级数据量较大,故将三维度独自离散度数据整理,并结合表8,得到图4所示离散度得分比较。
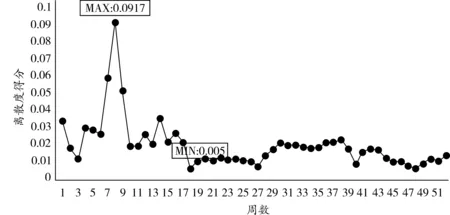
图4 综合维度周离散度得分
由表8可知,综合维度下第8周离散度最大,第18周离散度最小,这一时间范围的确定进一步佐证了全息月份遴选结果的可靠性,全息周样本时间范围与全息月样本时间范围出入不大。该全息样本主要适用于可选数据区间较小时采用。在交通调查中,若只调查某一周数据来描述全年交通流状态,应避开6—10周这一区间,着重考虑第18周附近数据。
(三)全息“天”遴选
除全息月份、全息周样本外,交通调查中最常用的是抽一周内某一天去观察交通流状态。为了使样本能够更好地贴近显示数据,选择周几是一个很重要的问题。主要对全年数据按周几属性归类,分“周一、周二、周三、周四、周五、周六和周天”七天进行离散度分析。具体计算过程同上文所述。
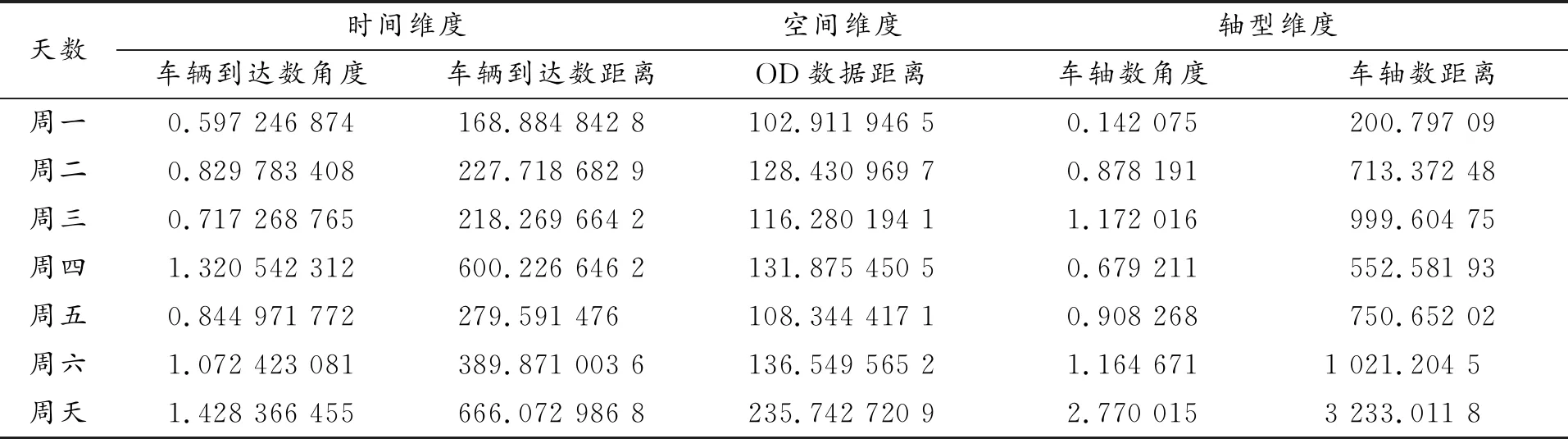
表9 三维度平均形状相似度与距离接近度数据(天)
根据表9,通过熵值法确定权重,得到表10和表11。

表10 各指标权重得分(天)

表11 综合维度离散度得分(天)
将表11计算的天离散度得分反映到图5和图6。
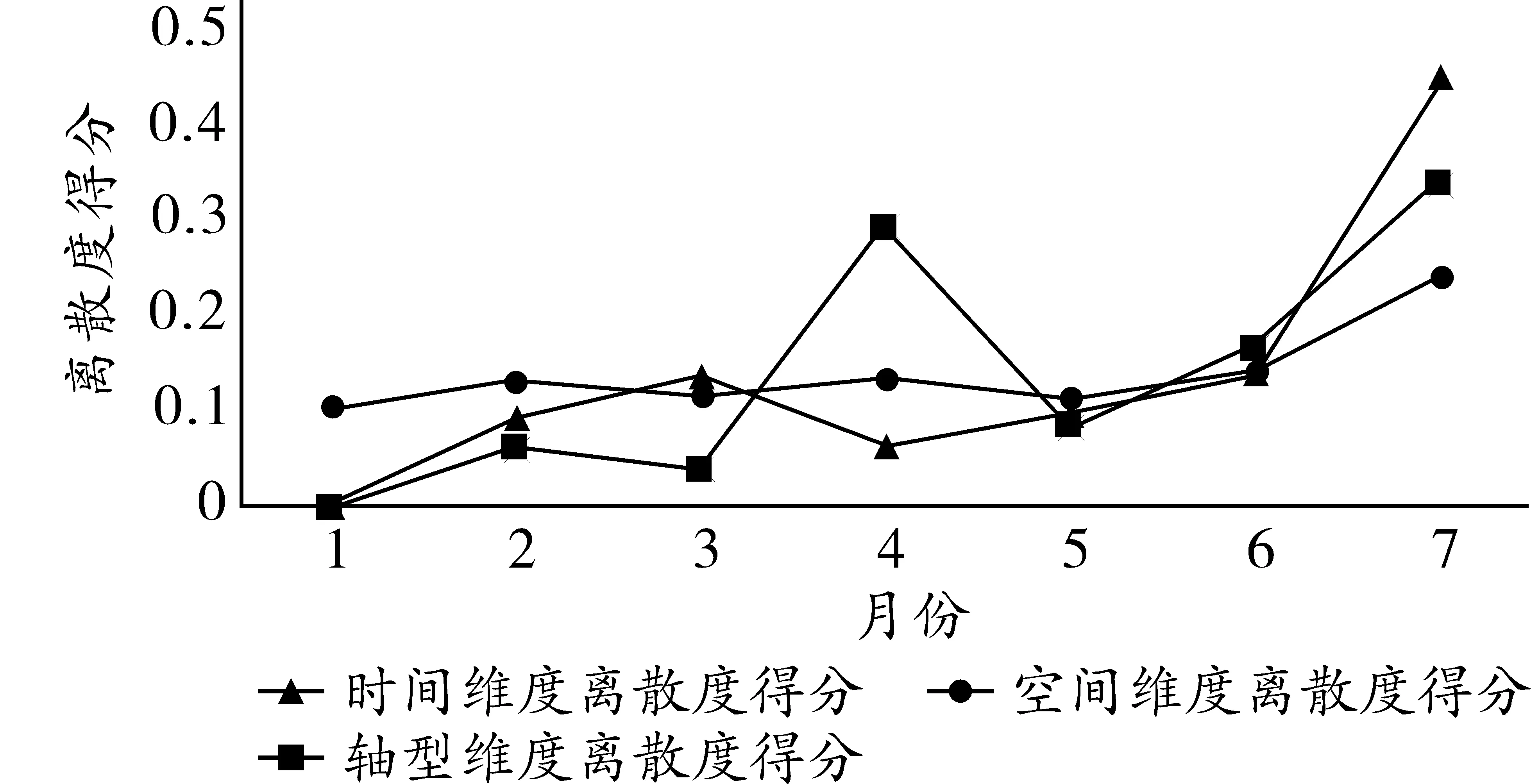
图5 三维度天离散度得分
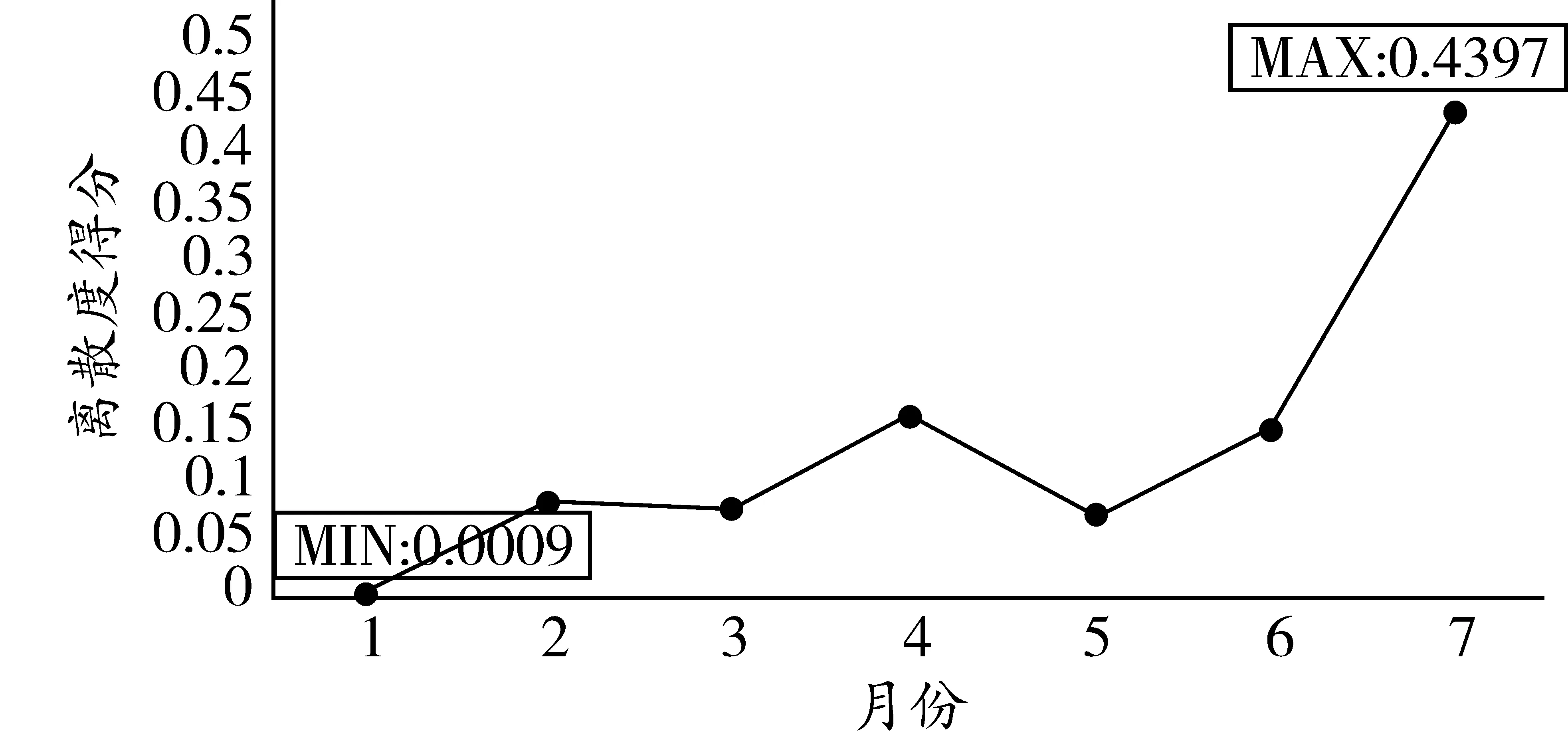
图6 综合维度天离散度得分
相较于全息月份与全息周,全息天的结果更明确。其中,在综合维度下,周一是离散度最小的一天,周天的离散度则相对最大,与实际的认知相契合。故在实际交通调研全样本中,若只能选取某一天的样本进行交通流描述或预测,最好选取周一的数据。
五、结论与展望
(一)结论
通过对国内某省高速公路收费站流水数据库货车数据的分析,测算每月货车流量数据与全年货车流量数据之间的离散度值,对月份排序,得出一个较为符合事实的全息样本。
第一,建立一个基于时间结构、空间结构、轴型结构三种维度的评价体系,并在高速公路收费站流水数据库中,针对每个维度选择一个较有代表性的字段作为分析比对字段。
第二,根据实际工作中的使用需要与可度量性,依次以自然月份、周、天为样本时间区间,测算全息样本离散度大小。
第三,探讨不同维度下的全息样本选择方案,为特定目的的研究提供样本选择方案。并针对单维度衡量失真的情况,通过熵值法科学地对不同维度赋予权重,综合得到各样本在相似评价指标体系下的综合离散度,为交通研究提供可靠的样本选择依据。
第四,综合考虑评价体系中的三种维度后,在样本区间为月份时,三月是作为全息样本的最佳选择,其次是四月、五月等离散度较低的月份,且其中离散度特别高的二月、一月不应作为样本选取的考虑范围。此外,在全息周的遴选过程中,第8周离散度最大,第18周离散度最小,这一时间范围与以月份为样本区间时遴选的结果出入不大。当着重考虑一周内的哪一天更适合作为样本时,在测算结果中发现周一是离散度最小的一天,周天的离散度则相对最大。
(二)展望
通过系统讨论与分析,对各月与全年的相似程度进行度量,仍存在一些继续研究的方向。第一,在实例分析中主要数据是国内某省全年两千万余条数据,数据量充足,但作为时间序列数据方面,时间跨度仅一年,涉及区域仅一省,成果存在一定程度的偶然性,可寻找更多年份、更多省份数据对现有结论进行佐证,得到普适性的结论。第二,目前研究主要是针对货运数据,若数据库充足,可考虑分析客运数据,并比价讨论客货运的区别。第三,全息月份是基于实际需要确定的最佳样本选择,后续在学术研究方面可通过时间序列数据的遍历算法,寻找与全年数据库相似度最高的最短全息样本。
