自动驾驶汽车车道目标及后座乘客检测识别研究
2021-01-11戚金凤罗国荣
戚金凤, 罗国荣
(广州科技职业技术大学 汽车工程学院,广州 510550)
随着汽车的普及,汽车驾驶安全问题日益突出。据统计,与驾驶员行为有关的汽车交通事故约占事故总数的80%[1]。这些交通事故主要是由驾驶员低头玩手机、接听电话或交谈等人为因素造成的。为此,实现汽车的自动驾驶,能有效地缓解上述问题。自动驾驶汽车是机械、电气、电子、计算机等高新技术的综合体,是汽车发展的一个重要方向。车道汽车目标识别是自动驾驶汽车在行驶过程中保证安全的汽车核心技术之一,被用于防止汽车发生碰撞而引发的交通事故。然而,汽车停车后也会带来安全隐患。近年来,在汽车停车后将儿童锁在车内造成儿童窒息死亡的事故时有发生。为解决自动驾驶汽车的安全性问题,本文针对车道汽车的识别和车厢内乘客的识别进行了研究,建立了基于单目摄像头和YOLOv2神经网络的汽车目标检测模型,实现对车道汽车目标的识别。针对汽车停车后将儿童反锁在车内的问题,本文提出了一种汽车车内乘客目标图像识别模型,该模型在ResNet-18模型的基础上,构建了基于迁移学习的卷积神经网络模型,实现在汽车停车后对车厢内乘客的智能检测。本文利用Matlab软件平台分别对道路车辆目标和车内乘客识别进行建模并仿真,并通过试验验证了模型的有效性和可行性。
一、道路车辆检测
自动驾驶汽车的构架是由传感器融合层、决策规划层、运动控制层和执行操作层组成[2-3],其中道路车辆检测从属于传感器融合层。本文通过视觉系统中的单目摄像头获取外界交通环境,再通过YOLOv2卷积神经网络检测道路车辆,以供决策规划层使用。
YOLOv2共25层,其中包括1个图像输入层、7个卷积层、6个批量归一化层、6个ReLU层、3个最大池化层、1个变换层、1个输出层,如表1所示。
图像输入层是进行YOLOv2网络的图像输入,图像输入的像素尺寸(长×宽×通道)为448×448×3。
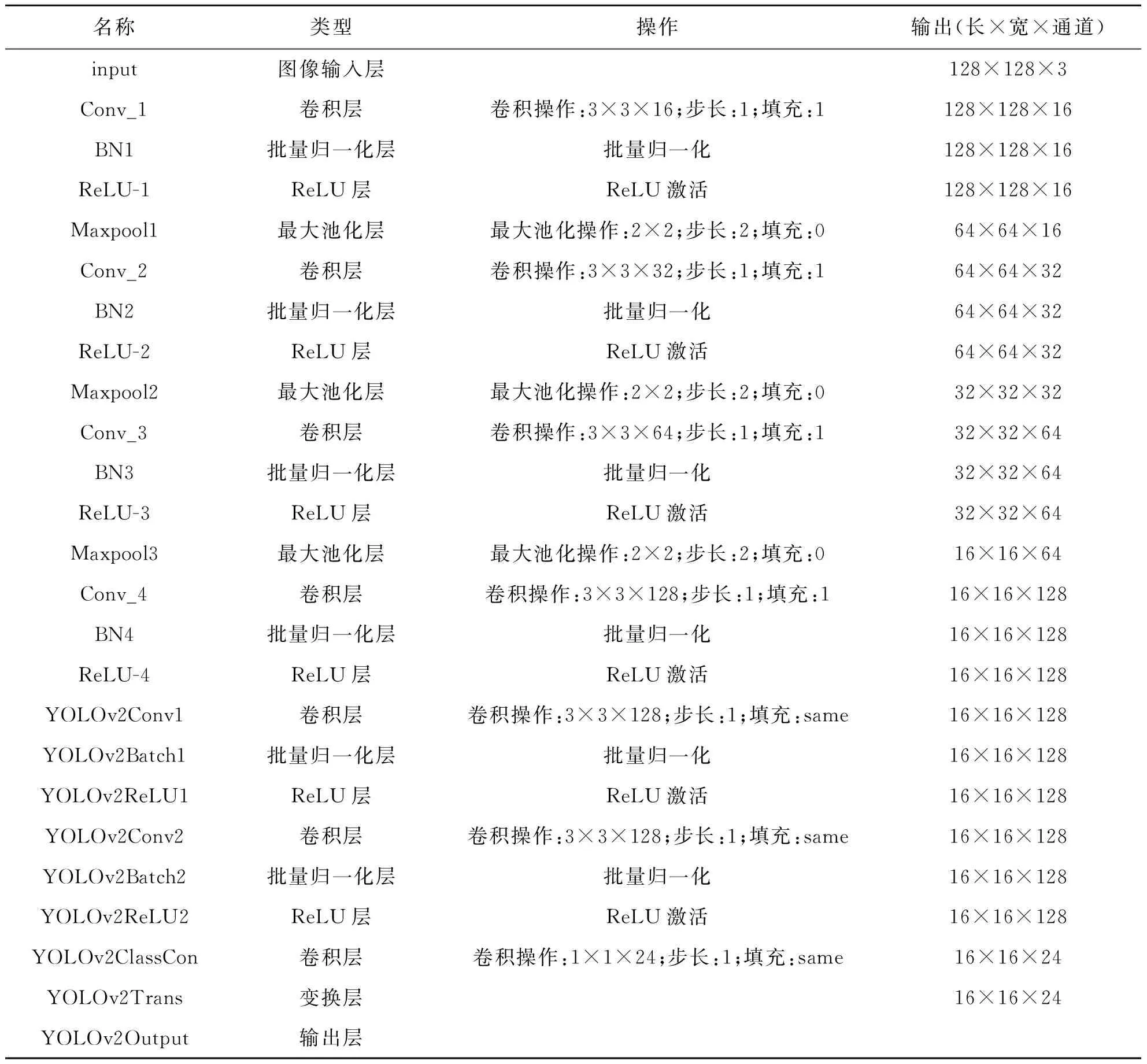
表1 YOLOv2网络结构
卷积层的主要作用是对图像进行特征提取,具有大小和深度两个属性的卷积核,通过迭代优化权重参数可得到多个特征图输出。卷积层计算公式[4]为:
(1)
输出特征张量尺寸计算公式[5]为:
(2)
式(2)中,Os为输出特征张量的尺寸,Is为输入图像的大小,Df为卷积核的大小,P为膨胀因子,Fs为扩充数量,S为滑动步长。
批量归一化层可使深层神经网络更容易收敛,而且能降低模型过拟合的风险,加快网络训练速度,从而提高模型训练精度。该层将卷积层输出的数据进行归一化处理,即将所有数据强制在统一的数据分布下,使数值更稳定,以便激活层使用。批量归一化层的操作分为归一化处理和变换重构处理2个步骤。归一化处理公式为:
(3)
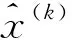
第K维的平均值公式及标准差公式分别为:
(4)
(5)
式(4)(5)中,N为样本数,xj为该批训练数据中的第j个神经元。
归一化处理后即进行变换重构,变换重构是为了解决归一化后的数据被限制在正态分布下而使网络的表达能力下降这一问题,变换重构公式为:
(6)
式(6)中,yk为重构变换后的输出值,γk为拉伸(scale)学习参数,βk为偏移(shift)学习参数。
激活层的作用是通过函数将上一层神经元的特征留存并映射出来,引入非线性因素,使得神经网络能够有更好的模型表达能力。激活层采用ReLU函数,ReLU函数公式为:
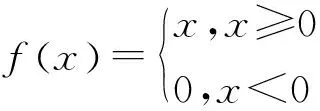
(7)
式(7)中,x为函数输入值,f(x)为函数输出值。
池化层主要用来对输入特征图进行压缩,去除多余信息、精简网络复杂度、提高计算速度。若采用最大池化和2×2的池化,则池化层的计算公式为:
(8)
式(8)中,fpool为池化的输出结果,Sm,n为特征图上第m行和第n列上的元素。
变换层是通过提取最后一个卷积层的特征来提高网络的稳定性,以保证输出层的稳定输出。
二、车内乘客目标图像识别
自动驾驶汽车不仅要确保行车过程中的安全,也要保证停车后的安全。为了检测汽车停车后车厢内是否有乘客滞留,防止乘客或儿童被锁在汽车车厢内[5],在ResNet-18模型的基础上,构建了基于迁移学习的网络模型。该模型与YOLOv2网络模型一样,都是在卷积神经网络的基础上构造。该模型共71层,包括1个输入层、20个卷积层、17个ReLU层、1个最大池化层、1个全局平均池化层、20个批量归一化层、1个全连接层、8个加法层、1个softmax层、1个分类输出层,其中输入层的图像大小为224×224×3。该模型的卷积、池化等层与YOLOv2网络模型一样,不再赘述。
全局平均池化层是通过计算输入特征图的高度和宽度的平均值来执行下采样,这样每个特征图可以得到一个输出类别特征。通过加强特征图与类别的一致性,卷积结构更简单,而且不需要参数优化,避免了过拟合。
全连接层的每一个结点都与上一层的所有结点相连,用来把前面各层提取到的特征综合起来并映射到样本标记空间里,在整个卷积神经网络中起到“分类器”的作用。
加法层是为了加快网络的运算速度,将卷积神经网络前面某一层值直接传递到后面的某一层。
softmax 层的主要作用是计算最终的分类概率,其公式为:
(9)
式(9)中,yr(x)为分类概率,其值范围[0,1],ar(x)为向量中第r个输入函数,j为函数的顺序数,k为总数。
分类输出层是为了衡量期望值与实际值之间的误差,采用交叉熵函数来计算,其公式为:
(10)
式(10)中,C为代价值,N为样本数量,K为类别数量,tij为属于第j类的第i个样本的期望输出值,yij为属于第j类的第i个样本的实际输出值。
三、试验与分析
试验是在Matlab 2020a及其 Deep Learing Tool工具箱软件环境下完成的。硬件环境中,CPU采用intel四核T3500,主频2.1 GHz;显卡采用AMD Mobility radeon HD 5000 Series,1GB 显存,内存8GB。数据集是从安装在汽车前挡风玻璃单目摄像头记录的视频集中摘取。
(一)道路车辆检测试验
道路汽车目标检测首先对YOLOv2网络进行训练,再利用训练好的YOLOv2网络对汽车目标进行检测。
YOLOv2的训练分4个步骤进行:
(1) 设计并载入神经网络 (CNN)。
(2) 载入数据集。本文使用由295 张图片组成车辆小数据集。
(3) 配置训练选项。训练的优化算法选取SGDM算法,初始学习速率为0.001,最小批量为16,最大训练轮数(epochs)为30。
(4) 训练YOLOv2网络,训练结果如图1所示。
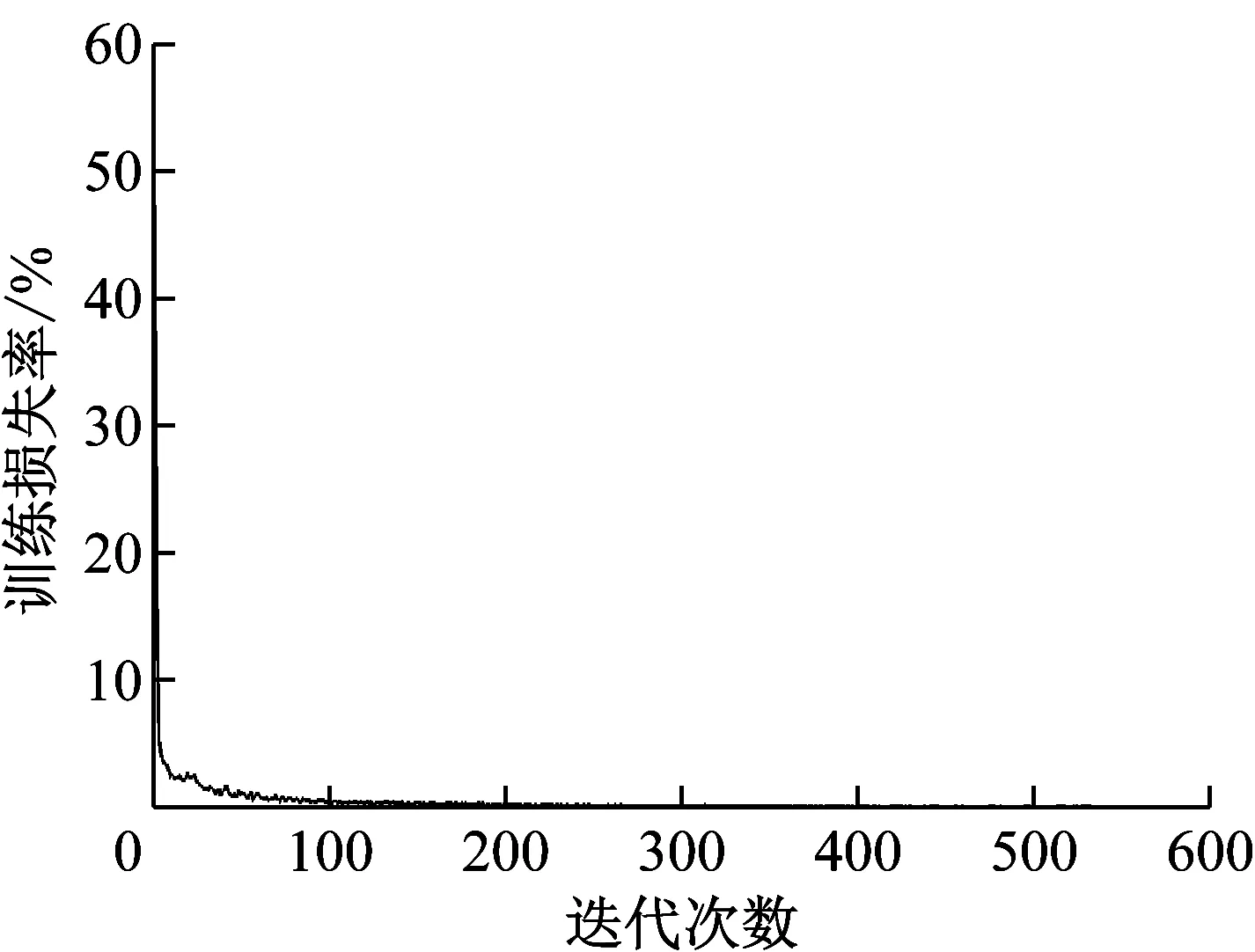
图1 训练损失率
训练结果表明,经过540次迭代,YOLOv2网络训练损失率由最初的52%下降到0.078%,车辆目标识别精度得到进一步的提高。
载入汽车前挡风玻璃单目摄像头记录的视频,利用训练好的YOLOv2网络对车辆目标进行检测,并用矩形框和图像坐标标注检测到的车辆,图2为视频某一时序下的检测试验结果。结果证明,应用训练好的YOLOv2网络能快速准确地检测汽车目标。

图2 车辆目标检测
(二)车内乘客目标图像识别试验
车内乘客目标图像识别也是先将ResNet-18模型进行迁移学习训练,通过检测P挡信号和车门上锁信号判断汽车停车,再通过安装在车内的摄像头拍照,根据得到的照片进行模型预测,判断乘客是否滞留在车内。训练步骤与YOLOv2网络相同,但图像数据集不同。
从多角度进行拍摄,分别采集了车厢载人和车厢无人的图像各150幅,并通过网络搜集获得图像450幅,试验样本共计750幅。为了提高识别准确率,将这750幅图像分别进行旋转变换和翻转变换,将图像扩充至3750幅。在学习速率为0.001的情况下分别应用SGDM、RMSprop、Adam 3种优化算法训练,结果表明SGDM优化算法是3种优化算法训练测试准确率最高的一种,准确率为98.89%,如图3所示。因此,选择SGDM优化算法和0.001的学习速率作为训练参数选项得到本项目的ResNet-18模型训练结果,应用训练好的模型测试新拍摄的汽车车厢照片,其中4次的检测结果如图4所示,4次检测准确率都为100%。结果证明,通过迁移学习的ResNet-18卷积神经网络模型具有较好的判断车内乘客目标的预测效果。
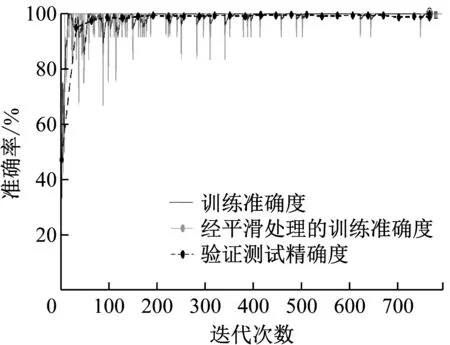
图3 SGDM算法训练准确率


四、结语
为解决自动驾驶汽车的安全性问题,本文分别从汽车行驶中和停车后两个应用环境研究汽车的安全性。针对行驶中的汽车,在自动驾驶汽车感知层建立了基于单目摄像头的车辆识别模型,实现了车道上的汽车识别;针对停车后的汽车,建立了车内乘客目标图像识别模型,实现了在汽车停车后对车厢内乘客的智能检测,为后续自动驾驶汽车的决策规划层、运动控制层和执行操作层提供了感知信息,并通过试验分析,证明了模型的有效性和可行性。
