基于霍夫变换的书脊识别研究
2020-12-14王钰深黄悦恒黄谦刘冲
王钰深 黄悦恒 黄谦 刘冲

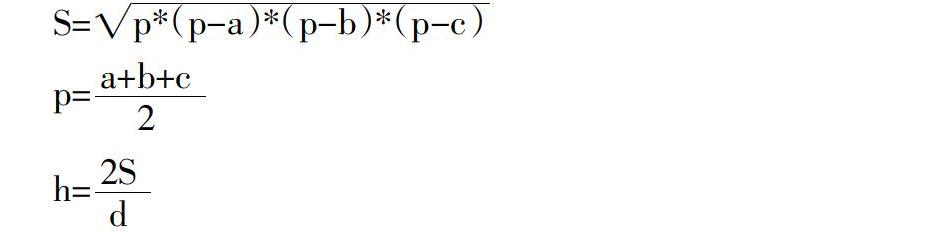
摘 要:针对机器人自动整理图书研究中的关键问题——利用机器视觉识别书脊问题展开研究。文章提出一种基于轮廓的书脊识别方法。利用Canny算子检测书脊边缘,根据书脊两侧轮廓为平行的线段特点,利用概率霍夫变换提取书脊两侧的轮廓,通过线段位置关系得到书脊ROI区域;根据书脊上文字与书脊颜色,亮度相差较大的特点,利用K-means对色调和亮度进行聚类,并通过判断形态特征得到文字区域,通过文字排列方式判断是否为书脊。将文章方法应用于实际检测中,并与利用LSD识别书脊的方法进行对比,实验结果表明文章方法识别正确率更高。
关键词:机器视觉;书脊识别;概率霍夫变换;Canny算子
中图分类号:TP242.6 文献标志码:A 文章编号:2095-2945(2020)36-0007-05
Abstract: Research on the key problem in the study of automatic book sorting by robots-the use of machine vision to identify the spine of the book. This paper proposes a method of spine recognition based on outlineand uses Canny operator to detect the edge of the spine. According to the characteristics of parallel line segments on both sides of the spine, the Probabilistic Hough Transform is used to extract the contours on both sides of the spine. The ROI area of the spine is obtained through the position relationship of the line segments; according to the text on the spine and the color of the spine, the brightness is different. The larger feature uses K-means to cluster the hue and brightness, and obtains the text area by judging the morphological characteristics, thus judging whether it is the spine by the text arrangement. The method in this paper is applied to actual detection and compared with the method of using LSD to identify the spine. The experimental results show that the method in this paper has a higher recognition accuracy.
Keywords: machine vision; spine recognition; Probabilistic Hough Transform; Canny operator
1 概述
隨着社会的发展,图书馆的使用频率越来越高,造成了大量书籍的借阅与归还。由于归还量较大,工作人员无法在短时间内将图书整理完,这给其他读者在查询、借阅时带来了巨大的不便。随着人工智能、机器人等技术的发展,越来越多的学者提出了利用机器人自动整理图书的想法。成功识别图书书脊是利用机器人自动整理图书的基础。目前书脊识别主要分为两种思路,一种思路是利用深度学习识别书脊上文字或索书号,以此完成对书脊的识别[1,2],另一种思路是通过书脊轮廓和颜色等特征完成对书脊的分割与识别。后一种思路的难点在于:书脊图像比较复杂,难以区分单本图书与相邻图书的轮廓;书脊颜色多样,难以用固定的阈值进行筛选。方建军[3]等人提出一种基于小波分析和概率Hough变换的书脊识别系统,该算法可以很好解决因运动造成的图像模糊导致识别率下降的问题,但是需要根据书脊的厚度设置不同的Hough参数;孙继周等人[4]提出利用颜色结合LSD检测分割图书,通过索书标签进行图书识别的算法,但该方法对阈值设置依赖较高;殷策[5]提出了基于LSD的书籍轮廓提取算法,该方法对摆放混乱的书脊识别效果较好,但是该方法耗时较长,无法满足实时监测的需求。N.Tabassum等人[6]提出一种针对多行图书书脊的分割方法,但是该种方法目前只能检测较厚的排列好的书籍,无法应用于薄书籍和摆放较为混乱的书籍。曹海清等人[7]提出一种利用投影算子分割书脊,获得索书号,利用模板匹配识别文字与数字,该方法书脊分割效果较好,识别准确率较高,但对光线条件要求较为严格。本文与实际项目结合,利用概率霍夫变换与K-means聚类方法,实现了一种基于轮廓的书脊识别的算法。该方法对光线条件要求较低,对阈值依赖程度较低,在与基于LSD的书籍识别方法对比中,本文方法取得了更优异的识别效果。
2 算法流程
本文算法主要分为以下几个步骤:
S1.图像预处理:转为灰度图,利用滤波去除噪声;
S2.利用Canny算子检测书脊边缘直线;
S3.利用概率霍夫变换(PPHT)提取书脊轮廓线段;
S4.对S3得到的符合条件的线段融合;
S5.进行平行线检测,将不符合条件的线段去除,符合条件的线段进行配对,得到书脊ROI区域;
S6.将图像转换到HSV色彩空间,利用K-means对色彩和亮度聚类,结合形态学的筛选获得文字轮廓,并计算文字的相对位置关系。将通过筛选的文字的所在书脊输出,未通过的删除。
3 边缘检测
本部分希望提取的轮廓符合以下要求:(1)轮廓完整;(2)不同书脊轮廓可以区分。根据经验与各个算子的综合表现,本算法选取Canny算子作为轮廓提取算子。
Canny算子由John F.Canny于1986年提出[8],其主要流程如下[9,10]:
(1)对图像进行高斯滤波去除噪声;
(2)计算梯度幅值M和梯度方向θ:
利用Sobel算子计算水平方向梯度Gx与竖直方向梯度Gy,梯度大小为M=,梯度方向为θ=arctan();
(3)非极大值抑制:
为精确确定边缘,需将图像细化到1个像素宽度。将梯度方向归化到图2所示的4个方向之一,将此方向作为梯度方向。使用3*3的模板作用于幅值图像,用模板中心像素与梯度方向上的两个像素比较,若模板中心点处的幅值M(i,j)比梯度方向上的两个相邻点幅值小,则M(i,j)赋值为零;
(4)阈值化和边缘连接:
对经过非极大值抑制的图像Q(i,j)采用双阈值处理,低阈值处理结果为A1,高阈值处理结果为A2。以A2为基础,用A1补充连接边缘。
4 轮廓提取
经典霍夫变换思想是利用点和线的对偶性,将图像中的曲线转换为极坐标系的一点。在笛卡尔坐标系中直线方程为:
霍夫变换利用在极坐标系中的曲线交点检测直线。在极坐标系中越多的曲线交于一点,代表着这个交点表示的直线由越多的点组成。当交于一个点的曲线数量大于设定的阈值,即可认为这个交点代表的参数在笛卡尔坐标系中为一条直线。但是经典霍夫变换计算量较大,不能够保证实时性,本文采用概率霍夫变换(PPHT),对书脊轮廓的直线进行检测和提取。概率霍夫变换无需对边缘所有像素点进行检测,仅是从边缘点集中随机选取点进行计算。具体过程如下[11,12]:
(1)随机选取前景点,并在极坐标系中绘制图像;
(2)当极坐标系中存在交点达到阈值,将该点对应的图像在笛卡尔坐标系中的直线L绘制出来;
(3)寻找前景点,将在直线L上的点连成线段,记录相应参数(起始位置,终止位置,线段长度),然后将这些点删除;
(4)重复前三步,直到前景点集为空。
通过以上4步,即可快速的提取到图像中的直线。
5 ROI区域选取
5.1线段融合
经过PPHT提取直线后,存在许多非书脊轮廓的线段,进行线段融合,减少非目标直线。利用直线的相对位置关系进行筛选,首先通过直线方程y=kx+b或x=c描述线段。删除长度小于30像素的线段(图像大小640*480),删除存在交点的线段。关注垂直方向的线段,忽略k∈(0,5)∪(-5,0)的线段;按照k值进行分组,每组限差为±10。计算同一组内线段之间的距离,依次在2条线段4个端点中选3个,共构成4个三角形,使用如下公式计算三角形的高:
(1)新的线段斜率取两条线段斜率的平均值;
(2)用一条线段的上端点与下端点分别连接另一条线段的下端点与上端点,连线交點作为新线段中心点;
(3)将融合前较长线段的长度作为新线段的长度。
5.2 平行线判断
按中心点横坐标从小到大的顺序进行平行线匹配。匹配规则如下:
(1)若第一条线段向第二条线段投影的长度大于第一条线段长度的30%,则认为这两条线段为一本书的书脊两侧直线,匹配成功;
(2)若投影长度小于第一条线段长度的15%~30%,认为它们可能为一本书的轮廓,继续向下寻找,若存在投影长度更高的则将那两条线段匹配;若投影长度小于第一条线段长度的15%,则将该条线段删除;
(3)规定进行匹配的线段的中心点横坐标之间的距离应小于第一条线段长度的40%,若在此范围内无法匹配成功,则将该线段删除;
(4)匹配仅在同组直线内进行;
(5)若第一条线段与第二条线段匹配成功,则使用第二条线段继续进行匹配,直至所有直线都经过匹配。
5.3 选取书脊ROI区域
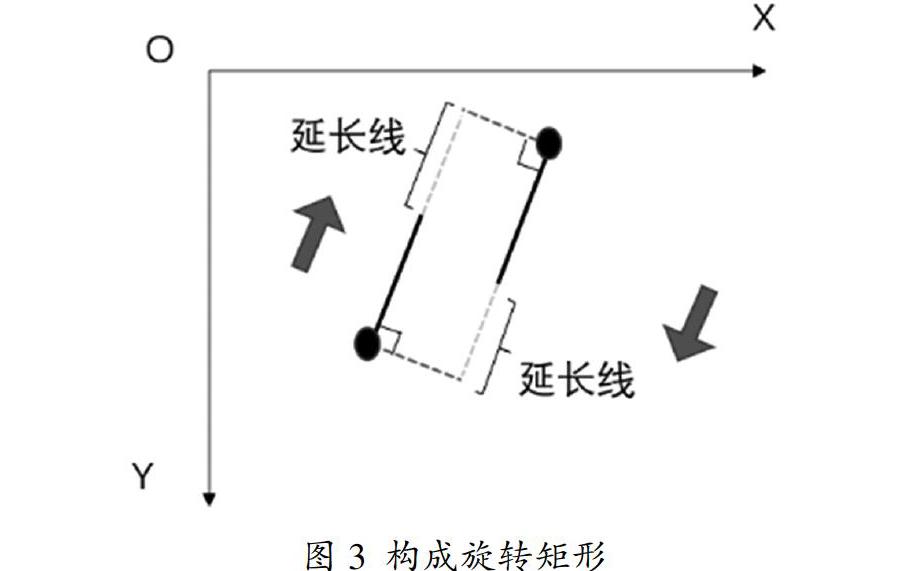
取匹配成功的线段端点纵坐标最大值与最小值的点,分别过该点做与其所在线段的垂线,延长另外一条线段,使其与垂线相交,如图3所示。构成旋转矩形区域,通过仿射变换得到书脊的ROI。
5.4 文字相对位置关系判断
这部分对识别到的区域做进一步筛选,同时解决因书脊边缘处梯度变化较小,而无法提取其轮廓的问题。
根据对书脊观察,总结出如下特征:多数书脊上存在文字,且文字的颜色,亮度与其他部分差距较大;文字的大小、排列方式有一定规律。根据这些特征,提出如下筛选方法及步骤:
(1)将ROI从RGB转换为HSV色彩空间;
(2)对H和S分量利用K-means聚类,将ROI区域分成3类;
(3)用矩形框选每一类图像,认为存在文字的矩形长应小于书脊长度的20%,且矩形长宽比应在0.8至1.2之间;
(4)将矩形按中心点横坐标分组,每组内横坐标差值不应大于ROI宽度的20%。取ROI两侧线段斜率的平均值过每组内y值最小的矩形中心点做直线,判断穿过矩形的情况与数量。与矩形上下边有交点,则直线穿过该矩形。若穿过矩形的数量不小于3个,则认为矩形区域即为文字区域;
(5)若无文字区域,则该区域为非书脊区域,若有一组及以上的文字区域,则认为该区域为书脊区域。若仅有单组文字,则直接将该区域输出,若有多组文字,则计算y值最大与最小的矩形中心点连线的斜率ki,并计算该组内矩形中心点横坐标平均值xi。然后计算相邻两组之间平均横坐标,计算平均斜率,找到ROI的中心点,取其纵坐标y,过(,y)以斜率做长度与ROI的高度相同的线段,将新的线段作为新添的书脊轮廓,与原有轮廓共同输出。
6 实验验证
实验目的:验证本文的方法的可行性和有效性,与传统方法对比,证明本文算法识别效果更好。
实验说明及结果:
(1)线段融合
利用PPHT提取线段并经过本文所述方法融合的效果图如图4a所示。
(2)文字框选
利用本文的方法对书脊ROI中的文字进行框选,矩形框到的区域代表文字所在区域,如图4b所示。
(4)书脊识别效果
展示本次实验最终识别效果,证明本文程序的有效性。其中标注圆点的书脊代表识别到的书脊(圆点为程序计算书脊第一个文字的中点),线段代表分割效果,如图4c所示。
7 结果分析
在本次实验中,图像中总共存在12本书,但程序总共识别出11本书的书脊。按照从左至右的顺序给书脊编号,为1至12。
因为第2本书的书脊与第1本的书脊的边缘灰度值相差较小,导致Canny算子未正确提取轮廓,如图5a所示,进而导致在PPHT检测线段时未检测到。但1号与2号书的书脊上文字与书脊颜色差距较大,通过判断文字相对位置,成功找到1号与2号的边界。利用同样方法成功区分第11本书与第12本书。
第9本书两侧的轮廓成功提取,并通过线段位置關系的检测,但在检测文字相对位置关系时未通过。书脊上的文字与书脊其他部分在色调和亮度上差距较小,在K-means聚类时未成功区分出文字与书脊其他区域,导致检测失败,如图5b所示。在图4c中,第9本书两侧的轮廓为它旁边两本书的轮廓,并非它本身的轮廓。
从实验结果来看,本算法效果较理想。缓解了颜色相近两本书之间轮廓无法提取的缺陷。通过对书脊色调和亮度的聚类识别文字区域,并利用其空间位置关系进行筛选,提高了基于轮廓识别书脊的准确性,降低了对阈值的依赖,提高了算法的鲁棒性。
8 实验对比
相机分辨率:640*480。
采用引文5中基于LSD书脊识别的方法与本文所述方法进行对比,识别结果如表1所示。
9 总结
本文提出了一种基于霍夫变换的书脊识别方法,通过Canny算子提取边缘,利用PPHT检测书脊轮廓线段,利用线段的空间位置关系得到书脊ROI区域,通过对色调和亮度的聚类,配合对文字轮廓的检测,得到文字区域,利用文字排列关系进一步检测书脊。实验结果表明,本文识别效果优于传统基于轮廓的识别方法。但本文算法也存在一定缺陷,若书脊色彩过于复杂,文字之间颜色亮度不统一或与书脊的颜色亮度差距较小,会导致无法正常识别。下一阶段将进一步完善本文算法,解决目前存在的缺陷,降低算法用时,并将算法应用于机器人,进行实际的书籍整理实验,提高算法的实际应用价值。
参考文献:
[1]Anegawa R,Aritsugi M. Text Detection on Books Using CNN Trained with Another Domain Data[J].2019 IEEE Intl Conf on Dependable, Autonomic and Secure Computing:170-176.
[2]Cao Li-na, Liu Ming-di, Dong Zhu-qing, Yang Hua. Book SpineRecognition Based on OpenCV and Tesseract[J].201911th International Conference on Intelligent Human-MachineSystemsan
dCybernetics (IHMSC): 332-336.
[3]方建军,杜明芳,庞睿.基于小波分析和概率Hough变换的书脊视觉识别[J].计算机工程与科学,2014,36(01):126-131.
[4]孙继周,王小雄,罗佳佳.基于图像识别的错位图书检测技术研究[J].现代电子技术,2016,39(05):58-62.
[5]殷策.基于计算机视觉的书脊识别算法研究[D].江西理工大学,2016.
[6]曹海青,王丹煜,姚志英,等.基于投影算子的图书索书号自动识别[J].计算机系统应用,2018,27(03):240-245.
[7]Tabassum N,ChowdhuryS, Hossen M K,Mondal S U.An approach to recognize book titlefrom multi-cell bookshelf images[J].ICLVPR, Dhaka, 2017:1-6.
[8]Canny J. A computational approach to edge detection[J].IEEE-PAMI,1986:679-698.
[9]WojciechM, Marek S. Canny edge detection algorithm modification[J]. Computer Vision and Graphics-International Conference, ICCVG 2012, Proceedings.533-540.
[10]Rong Wei-bin, Li Zhang-jing, Zhang Wei, Sun Li-ning. An improved Canny edge detection algorithm[J]. 2014 IEEE International Conference on Mechatronics and Automation (ICMA),2014,25(12):60-63.
[11]Mochizuki.Y, Torii.A, Imiya.A. N-point Hough transform for line detection[J]. Journal of Visual Communication and Image Representation,2009,20(4):242-253.
[12]Mu Zi-xin, Li Zi-fan. A Novel Shi-Tomasi Corner Detection Algorithm Based on Progressive Probabilistic Hough Transform[J]. 2018 Chinese Automation Congress (CAC): 2918-2922.
