广义斯科伦项刻画量词辖域问题分析
2020-11-26石运宝
石运宝
(湘潭大学 碧泉书院, 湖南 湘潭 411105)
1 背景介绍
Mark Steedman等系统阐述了如何应用广义斯科伦项解决量词辖域歧义问题(1)Mark Steedman,Taking Scope:The Natural Semantics of Quantifiers,Cambridge,Mass.:The MIT Press,2012,pp.111-117.。该方案是经典一阶方案的择代方案,优势在于给出组合性的分析,不牵涉到移位(movement)等操作。像下面(1)这样的句子,在一阶逻辑框架内,通常被分析为两个不同辖域的表达式(2)和(3):
(1)Every boy likes some girl.
(2)∀(x)[boy(x)→∃(y)[girl(y)∧like(x,y)]]
(3)∃(y)[girl(y)∧∀(x)[boy(x)→like(x,y)]]
(2)是说,每个男孩喜欢某个(可能不同的)女孩,(3)是说,存在一个特定的女孩,每个男孩都喜欢她。这两种解读都是有效的,差别在于,(2)是全称辖域宽于特称辖域,(3)是特称辖域宽于全称辖域。从语义上来说,这两种解读是没有歧义的,但问题是,像组合范畴语法(CCG)这种受表层形式(surface forms)驱动的系统,只面向自然语言的表层结构,不承认深层结构(deep structure),所以不接受(3)这种解读需要借助于量词移位(quantifier movement)或量化嵌入(quantifying in)的操作。由(1)的句法形式来看,(2)的解释是符合组合原则的,(3)作为(1)的解释,则需要有个移位操作,特称量词要移出原来的位置,而凡是牵涉到移位操作的,都不符合组合原则。因为组合原则要求整体表达式的意义只由该表达式的直接构成成分的意义和组合方式的意义决定,不能再有移位这样的因素决定整体表达式的意义了。这里需要解决的问题是,如何给出一个语义解释,刻画上面两种解读。以往,学界有两种思路解决上述量词辖域歧义问题,一是通过类型改变操作来强化推演能力,二是丰富词库和语义实体。Mark Steedman沿着第二种思路给出两种推演(2)Mark Steedman,“Alternation Quantier Scope in CCG”,in Robert Dale,Ken Church,eds.,Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics,San Francisco:Morgan Kaufmann,1999,pp.301-308.,从词库中给every和some各两个范畴和类型,这样就避免了改变结构,
即改变语句的原有的表层结构形态。Dimitrios Kartsaklis则沿着第一种思路在CCG框架内给出了比较恰当的解决方案(3)Dimitrios Kartsaklis,Wide-Coverage CCG Parsing with Quantifier Scope,Edinburgh:University of Edinburgh,2010,pp.10-11.:
(4)全称量词宽辖域的刻画(4)量词在宾语位置,与名词生成类型为<
所用到的推演规则如下:
( (>) X/Y∶f Y∶a⟹X∶f(a) 推演如下: (5)特称量词宽辖域的刻画: 所用到的推演规则如下: (>B) X/Y∶f Y/Z∶g ⟹ X/Z∶λx·f(g(x)) (<) Y∶a XY∶f ⟹ X∶f(a) 推演如下: (4)和(5)两种刻画对应全称量词宽辖域和特称量词宽辖域两种分析。这种解决方案符合逻辑语义学关于自然语言语义分析的预设:每个非词条的歧义,即不能化归为词条的歧义,应该对应推演的歧义。然而,尽管在CCG框架内可以推演出上述两种分析,但对于无关量词辖域歧义的句子,CCG也无法刻画辖域和句法表层结构之间的联结。像英语、汉语都还有这样的句子:“有些女孩,所有男孩都喜欢。”这种宾语提前的句子是合法的,它的恰当分析应该是特称量词在外层,做“宽辖域”处理,然而,特称量词做“窄辖域”处理的分析依然存在。也就是说,就(1)′来说,下面的(3)是恰当的刻画,而(2)则不是我们想要的,但(2)这种解读却依然存在(虽然无法从句法上得到支撑)。 (1)′Some girl,every boy likes. (2)∀(x)[boy(x)→∃(y)[girl(y)∧like(x,y)]] (3)∃(y)[girl(y)∧∀(x)[boy(x)→like(x,y)]] 另外,像“Some representative showed some company some sample.”这种多重量化语句,存在“义同形异”的冗余解读问题。随着特称量词的排列组合的变化,如(6)所示,存在6种形式上不同而语义相同的解读(省略了后三种解读): (6)a.∃x[repr(x)∧∃y[company(y)∧∃z[sample(z)∧showed(x,y,z)]]] b.∃x[repr(x)∧∃z[sample(z)∧∃y[company(y)∧showed(x,y,z)]]] c.∃x[company(y)∧∃x[repr(x)∧∃z[sample(z)∧showed(x,y,z)]]] d.… 在一个有n个量词的句子里,有n的阶乘数量的语义解读。这样数量的冗余解读,对任意一个系统都会造成负担。Koller和Thater统计了“For travelers going to Finnmark there is a bus service from Oslo to Alta through Sweden.”的3960种不同的解读,这些解读都是互相等值的(5)Alexander Koller,Stefan Thater,“An Improved Redundancy Elimination Algorithm for Underspecified Representations”,in Nicoletta Calzolari,Claire Cardie,Pierre Isabelle,eds.,Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics,Sydney:The Association for Computer Linguistics,2006,pp.409-416.。 量词辖域问题与并列结构一起出现,会造成更复杂的问题。比如: (1)″Every boy likes,and every girl detests,some singer. 该句子由“and”联结,“likes”后省略了宾语。Geach观察到,辖域问题受到并列结构的约束,或推广来说,量词辖域分析受到表层结构的影响。Geach认为,所有男孩和所有女孩喜欢厌恶某个共同的歌手,或所有男孩和所有女孩喜欢/厌恶某个可能不同的歌手,这两种解读是对的;但下面的两种解读则均不合法(6)Peter T. Geach,“A Program for Syntax”,Synthese,Vol.22,No.1-2,1970.: 〈1〉存在某个歌手,比如,张一,所有男生都喜欢,而所有女生都厌恶某个可能不同的歌手; 〈2〉存在某个歌手,比如,张二,所有男生都喜欢,并且,存在某个歌手,比如,张三,所有女生都厌恶。 上述这些量词问题,很难使用传统的量化嵌入或量词移位来做简单处理,比如,按照传统的转换生成语法来说,在上述(1)″类型的并列结构中,存在一个深层结构,把(1)″转换之后,不论对“some singer”做何种移位,在某种具体的解读中,“some singer”在两个合取支中的辖域是相同的,这是理想的解读。然而,为什么会这样移位,而不是得到上述不合法的那两种解读,这是不清楚的。 就这些难题,Partee和Rooth等采用了比CCG更为灵活的类型改变操作,以应对句法上的特殊结构(如上面的并列结构导致宾语“some singer”的量词辖域也受到句法结构影响,其辖域必须在合取支中相同)所导致的辖域问题(7)Barbara Partee,Mats Rooth,“Generalised Conjunction and Type Ambiguity”,in Rainer Bäuerle,Christoph Schwarze,Arnim von Stechow,eds.,Meaning,Use,and Interpretation of Language,Berlin:de Gruyter,1983,pp.361-383.。 尽管这些方案所涉及的语法满足了面向语言表层结构等要求,但无疑,它们使得理论繁琐、复杂化,这不是理想的后果。类型改变操作必然导致为每个单词指派无穷多范畴,由此会导致更为复杂的排序问题、完全性问题、可解析性问题等等。 广义斯科伦项方案则可以成功避免上述不令人满意的结果的出现,大大简化灵活的范畴指派带来的各种问题。 在给出核心论点之前,先梳理下学界已有的关于辖域问题的解决方案,通过分析这些方案的不足可以了解斯科伦化方案提出的优势所在。 Kempson和Cormack最早提出了一种能给出有关量词辖域问题的所有可能的解读却不指定每个量词特定位置的方案(8)Ruth M. Kempson,Annabel Cormack,“Ambiguity and Quantication”,Linguistics and Philosophy,Vol.4,No.2,1981.。该方案提出后,出现了很多追随者,并且他们在Kempson和Cormack的工作基础上进行了改良。沿着该思路,Cooper提出了一种被称之为“基于存储”(Storage-based)的方案(9)Robin Cooper,Quantification and Syntactic Theory,Dordrecht:D. Reidel Publishing Company,1983,pp.52-78.。仍以(1)“Every boy likes some girl.”为例,该方案的思想可简述为: (7)〈λxλy.lile(x,y),(λp.∀x[boy(x)→p(x)],1),(λq.∃y[girl(y)∧q(y)],2)〉 (7)中的1和2标记了量化表达式的位置,值得说明的是,尽管看上去量词的位置是固定的,但实际上恰恰相反,尖括号里的三个表达式并没有固定量词的先后顺序。(2)和(3)可以通过“检索”(retrieve)来实现,即从之前“存储”的数据里检索并取回量词表达式,然后还原出(1)本该有的两种含义。如果先“检索”∀boy表达式,那么可以得到(2)的解读;如果先“检索”∃girl表达式,那么可以得到(3)的解读。这种方案至少存在两个缺陷,一个是导致前述冗余解读问题,另外一个是无法很好地处理复杂结构,如否定句。 Bos提出了一种“缺口”语义学方案(hole semantics approach),将通常λ表达式位置替换为一个表示缺口的符号,另外附加一些限制性条款(10)Johan Bos,“Predicate Logic Unplugged”,in Paul Dekker,Martin Stokhof,eds.,The Proceedings of the 10th Amsterdam Colloquium,Amsterdam:ILLC,University of Amsterdam,1996,pp.133-142.。除了这些工作之外,还有很多人对量词辖域问题作出了贡献。这些工作都具有启发性,但都存在诸如冗余解读等问题,而斯科伦化方案则在一定程度上克服了上述疑难。 一般来说,斯科伦化方案是指用斯科伦函项替代特称量项,只保留全称量项的一类方案。广义斯科伦项方案在原有文献基础上,面向自然语言处理,做了推广工作。不论是经典斯科伦化方案,还是广义斯科伦项方案,在分析量化表达式的时候,都存在一些关于特称量项的基本假设,下面先简要论述这些假设。 2.2.1 斯科伦化方案的基本假设 斯科伦化方案通过区分广义量词和其他纯粹指示性表达式来分析辖域歧义问题。为了能刻画(1)′和(1)″这种复杂的量词辖域问题,斯科伦化方案假设像(1)、(1)′和(1)″中“some girl”和“some singer”等不定代词的窄辖域解读源于对这些不定代词的非量化解释,这种不定代词的非量化解释与“some girl”和“some singer”的窄辖域的量化解释可等同视之,即都能取得正确的语义解释。这种非量化的解释将“some girl”和“some singer”这些不定代词转化为指称性表达式,即下面的斯科伦项。这种做法的合理性在处理“驴子句”难题时得到印证。将不定代词解释为纯粹指称性的方案并不新奇,这种解释源于对本体论上的个体更详尽的划分。Kit Fine提出“任意对象”(arbitrary objects)的概念,任意对象指的是那些可以与属性相关联但其现实的外延身份并不指定的对象(11)Kit Fine,Reasoning with Arbitrary Objects,Oxford:Oxford University Press,1985,p.220.。按照这个概念,任意对象与斯科伦项是相似的,后者是一阶谓词演算的证明论中使用存在消去规则得到的。在处理“驴子句”难题时,令代词指向斯科伦项会得到一些推论: (8)Every farmer who owns a donkeyibeats iti. 将“a donkey”处理为斯科伦项并将后面的代词“it”与该斯科伦项关联,则可以得出这样的推理:如果我们听说了标准的驴子句(8),并且知道每个农民拥有不止一头驴子,我们大概能推出,如果某个原因使得农民打任意一头驴子,则农民会打所有的驴子。但下面的例子则不会出现这样的推论: (8)′Everyone who had a dime in their pocket put it in the parking meter. 假如每个人口袋里都有不止一枚十分硬币(dime),过停车收费器(parking meter)时,人们不会从投任意一枚十分硬币,推出投所有的十分硬币,因为我们知道投硬币的原因,而(8)没有给出原因。 2.2.2 斯科伦化方案基本思路 2.1中的方案均源起于全称量词和特称量词的“依赖”关系,一种简化这种依赖关系的方案便是比较合理的。 斯科伦化方案便是通过移去特称量词,放宽了两种量词之间的依赖关系。具体来说,每个特称量词被一个函数所替代,该函数的所有变元被全称量词所约束,并且特称量词落在全称量词的辖域中,如(9)所示: (9)∀x∃y∀z.P(x,y,z)⟺∀x∀z·P(x,sk(x),z) (9)中∃y前面只有一个全称量词∀x约束,所以用“∀x…sk(x)…”去替代“∀x∃y…y…”。但假如特称量词处于宽辖域,由于前面没有全称量词,则替代性函数的论元为空,即常函数sk( ): (10)∃y∀x∀z.P(x,y,z)⟺∀x∀z·P(x,sk( ),z) 回到(1)“Every boy likes some girl.”这个例子,斯科伦化方案消去特称量词,给出了两种“组合地”或“在原地”(insitu)的刻画: (11)∀x[boy(x)→(girl(sk1(x))∧like(x,sk1(x)))] (12)∀x[boy(x)→(girl(sk1( ))∧like(x,sk1( )))] 在(11)中,斯科伦项(12)虽然“函数”与“项”涵义不同,但谓词逻辑中函数作用于论元生成的是项,二者还是具有统一性的。是x的函数,(11)是说,每个不同的男孩都有各自喜欢的女孩,即sk1(x)。而在(12)中,斯科伦项是一个常函数,这是由于该解读中特称量词是宽辖域,(12)是说,同样的一个女孩被每个男孩所喜欢。由(11)和(12)可以看出,斯科伦化方案使得两种解读分享同一个结构,差异取决于每个斯科伦函数的参数集。为了能够处理更多更复杂的量词辖域问题,有必要对斯科伦函数进行推广,下面介绍推广性成果,即广义斯科伦项。 可以将斯科伦项概念加以推广,进而给出广义斯科伦项的概念,目的是在CCG框架内,通过使用广义斯科伦函数来解决诸多量词辖域问题(13)Dimitrios Kartsaklis,Wide-Coverage CCG Parsing with Quantifier Scope,pp.16-18.。广义斯科伦项方案的核心观点为: (a)英语中最恰当的限定词应该是every、each及其类似的量化短语; (b)非全称的量词应该与广义斯科伦项相结合进行刻画。 尽管(13)和(14)非常类似于(11)和(12),但广义斯科伦项式刻画存在着一个重要差异,即在(13)和(14)中不需要单独出现谓词girl,其被直接包含到广义斯科伦项之中。下面展示在CCG框架内如何应用广义斯科伦项刻画量词辖域问题。 为了达到这个目标,首先要给出every和some的词条解释: (15)every——NP/N∶λp.λq.∀x[p(x)→q(x)] (16)some——NP/N∶λp.λq.q(skolem(p)) 有了(15)和(16),便可以在CCG框架内给出想要的两种推演结果。 (17)广义斯科伦项刻画全称量词宽辖域解读: (18)广义斯科伦项刻画特称量词宽辖域解读: 由于斯科伦项在推演过程中可以随时根据参数集确定某个量词是宽辖域还是窄辖域,所以上述两种解读都可以获得。这也说明了参数集的重要意义所在,如果参数集不同,则推演不同。 (23)buy(a,b)→own(a,b) ((21)(22),一阶定理) (24)∀x∀y[buy(x,y)→own(x,y)] ((23),全称量词引入) (25)buy(eBay,Microsoft) (假设) (26)own(eBay,Microsoft) ((24)(25)分离规则) (19)是运用广义斯科伦项思想对“购买行为”所预设存在的“社会约定”进行刻画;(20)是列举几个“约定”的内容;(22)可以认为是这些属性集合断定蕴含“own”属性;(23)和(24)结论性地得出“buy”行为蕴含“own”行为;(25)到(26)则回应Mark Steedman给出的例子:如果eBay与Microsoft公司之间有“buy”行为,则他们之间满足“own”关系。 英语中的广义量词,如“at least three”、“few”、“four”以及“at most two”等都可以用广义斯科伦项予以刻画。例如(27): (27)Four students read a book. 假定为“read”指派的范畴和语义标签如下: 则(27)存在(29)和(30)两种刻画: (29)是说,存在同一本书,四个学生都读它,这是集体式解读(collective reading),两个{}内为空表示存在四个学生和存在一本书,且前面都没有要参考的变量;(30)是说,四个学生每个人可能读的不是同一本书,这是分布式解读(distributive reading),第二个参考集为{z},表示对于四个学生中的任何一个z来说都存在一本可能不同的书,z阅读它。 再比如,下面的广义量词例子(31),同样有集体式解读(32)和分布式解读(33)两种解读: (31)Most farmers own a donkey. 量词在语言中起着举足轻重的作用,关系到语言的精确性等问题。量词辖域歧义问题是每种自然语言都固有的问题,影响到真实文本的句法和语义解读,如果得到很好地解决,会对人工智能领域的自然语言处理和机器理解语言起到推进作用。 在量词辖域处理文献之中,使用广义斯科伦项消解特称量词是比较新颖的一类方案。该方案克服了传统方案的不足,比较自然地面向表层结构分析自然语言的量词问题,不添加额外的装置,摒弃了“移位”或等价的结构转变策略等深层结构构思。以真实文本进行实验,结果表明,按照广义斯科伦项方案进行分析,跟理论预期相比相差无几,准确率非常高,高达92.4%(15)Dimitrios Kartsaklis,Wide-Coverage CCG Parsing with Quantifier Scope,p.76.。这说明将广义斯科伦项融入λ-演算增强组合范畴语法的语义层,对提高组合范畴语法处理自然语言的精度非常有帮助。CCG在前期的发展中,更多地依赖句法层面上大规模语料的训练来提高语法的处理精度,这使得CCG分析器不能逃脱“天花板效应”——在语言生成精度达90%以上之后,指标难以提升。广义斯科伦项方案表明,通往其余10%的精度的“钥匙”,就在被忽略的逻辑语义之中。虽然92.4%较往常的90%提升有限,但经过不断完善和新语义思路的提出,处理自然语言的精度会得到不断提升。 值得注意的是,广义斯科伦项方案刻画自然语言中的不定代词的过程,侧面揭示了自然语言与逻辑语言之间存在的细微差异。通常,从逻辑学视角来看,出现不定代词往往要处理为特称量化结构,但“驴子句”等现象非常有力地表明,不定代词不适合处理为标准的特称量词。用斯科伦项取代特称量词,刻画不定代词,揭示了这些名词短语的指称功能,而非量化结构。凡是适合用广义斯科伦项进行刻画的名词短语,如果落到全称量词的辖域中,这时可以认为是“取窄辖域”;如果没有落到全称量词辖域中,则可以认为是“取宽辖域”。当然,自然语言中确实存在一些短语,它们非常倾向于被刻画为特称量词,这也是自然语言丰富性所决定的,需要仔细考察具体的语境来考虑如何处理。 用斯科伦项刻画了最简单的量词辖域问题以及像“most”这种简单的广义量词,后续可以将该思路扩展到更多的量词语句,即使用广义斯科伦项处理更多广义量词。将英语的量词预设理论扩展到汉语,以检验该理论处理汉语的能力,也是非常有意义的尝试。另外,模态词与量词问题纠缠在一起,用广义斯科伦项方案加以分析,能在一定程度上消解量词辖域问题,但能否通过该方案彻底予以解决,则有待检验。标准的模态分析方法,尤其是可能世界语义学,不是特别适合分析自然语言中的模态词,尤其是被称为“动态模态词”的一类成分。这表明,对自然语言中的模态词详加区分才能准确刻画自然语言的语义。如果组合范畴语法要将广义斯科伦项方案推广到含有模态词的语句,可以结合潜力语义学进行分析(16)Barbara Vetter,“‘Can’ without Possible Worlds: Semantics for Anti-Humeans”,Philosophers Imprint,Vol.13,No.16,2013.。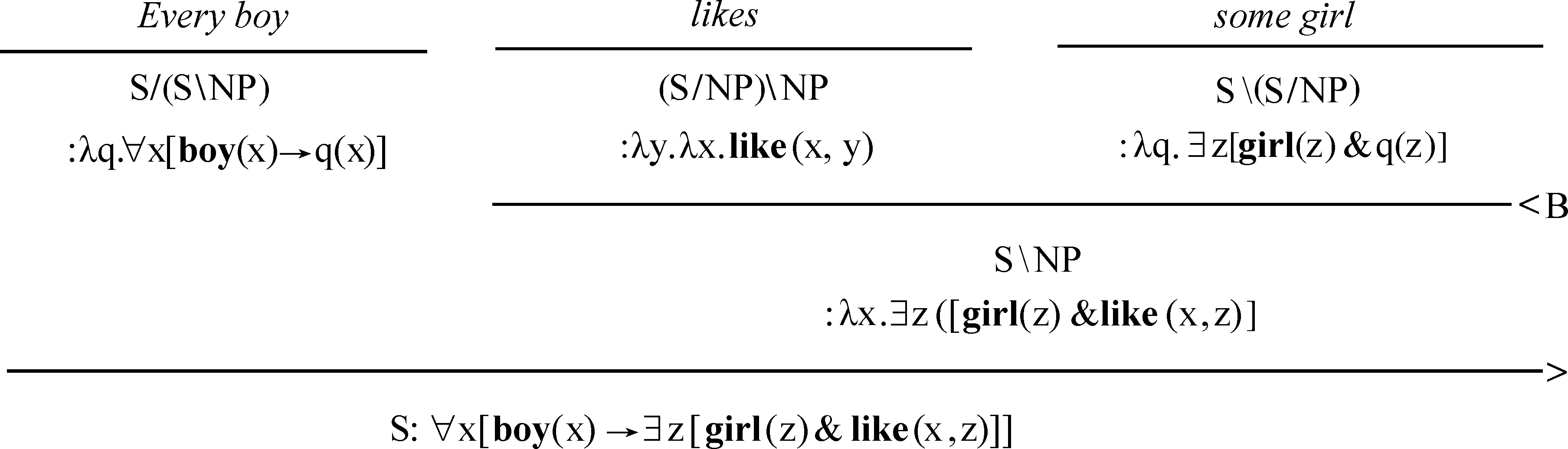

2 广义斯科伦项方案
2.1 已有方案及其不足
2.2 斯科伦化方案
2.3 广义斯科伦项方案
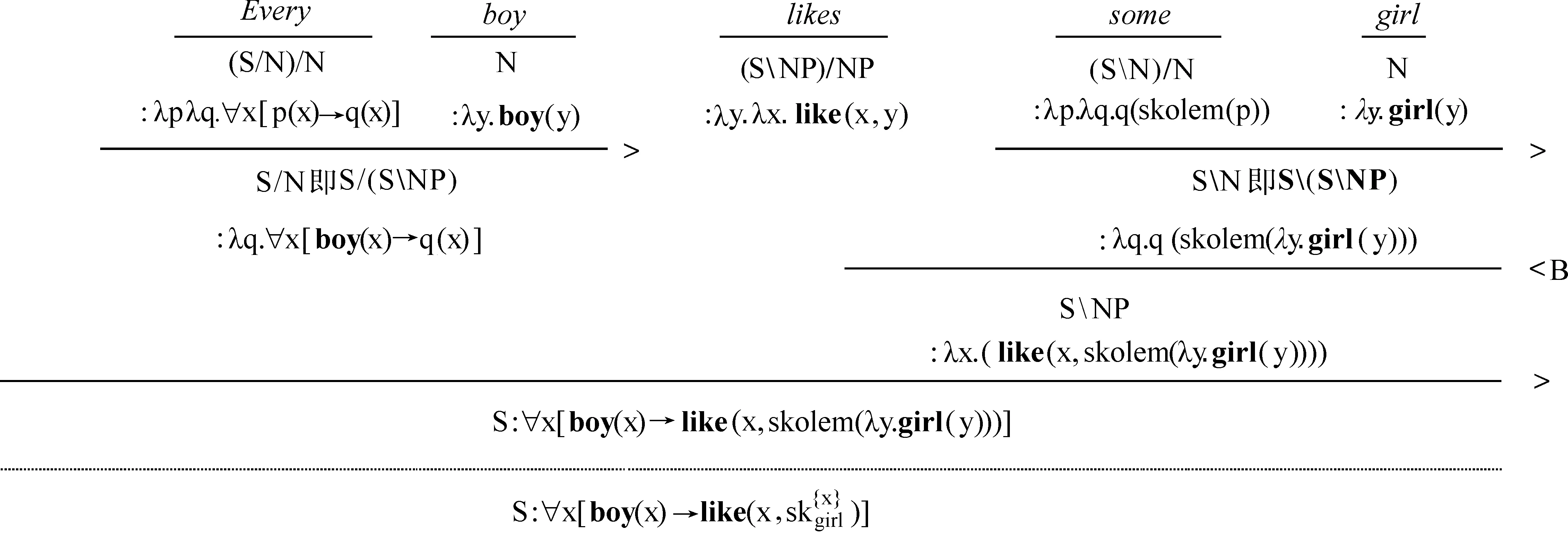

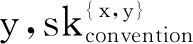
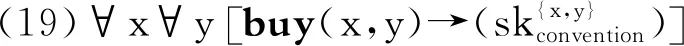
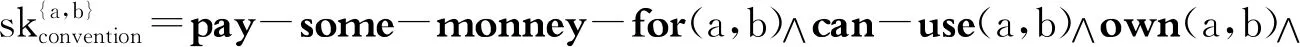
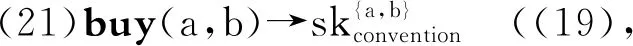

2.4 从标准量词推广到广义量词
3 总结
