深度学习算法与组合范畴语法的比较研究
2020-11-26赵靓
赵 靓
(天津财经大学 管理可计算建模协同创新中心, 天津 300222)
0 引言
近年来随着深度学习算法应用到自然语言处理(NLP),语义可计算的问题有了突破性进展。NLP中所谓的“词嵌入”(word embedding)就是用高维空间中的实向量来表示词,用来表示词的向量也就称为“词向量”。这种研究语义的方式也被称为“分布语义学”。事实上,词向量用来分析自然语言中词与词之间联系的方法很早就有比较成功的经验,但是传统的方法都是纯统计的方法。仅靠统计方法对词向量分布的改进一直持续到2012年(1)Jeffrey L. Elman,“Finding Structure in Time”,Cognitive Science,Vol.14,No.2,1990;Yoshua Bengio,Réjean Ducharme,Pascal Vincent,Christian Jauvin,“A Neural Probabilistic Language Model”,Journal of Machine Learning Research,Vol.3,No.6,2003.。Mikolov等使用神经网络算法首次展示了vking-vman+vwoman=vqueen(king去掉man的性质,换上woman的性质,对应的词是queen)这个被广泛引用的结果(2)Tomáš Mikolov,Wen-tau Yih,Geoffrey Zweig,“Linguistic Regularities in Continuous Space Word Representations”,in Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,Atlanta,2013,pp.746-751.,标志着统计方法进入深度学习阶段的跨越得以实现,此时的词向量模型和先前的纯统计学模型已经有质的区别。尽管深度学习算法在NLP领域异军突起,尤其是语义相关性方面的效果十分显著,但是这种算法在分析句法结构、识别句法成分方面的表现却并不能尽如人意。
组合范畴语法(Combinatory Categorial Grammar,CCG)不仅活跃在语言学和逻辑学的交叉领域,而且在NLP的实际操作中也已经有广泛应用的语料库。作为语言学参照标准的宾州树库(PTB)也已经有官方CCGbank和宾州中文树库(PCTB),而非官方的中文CCG库的建设也有很多版本(3)陈鹏:《汉语组合范畴语法研究及树库的构建——语言、逻辑与计算互动的视角》,博士后出站报告,2016年;Daniel Tse,James R. Curran,“Chinese CCGbank:extracting CCG derivations from the penn Chinese treebank”,in Proceedings of the 23rd International Conference on Computational Linguistics(Coling 2010),Beijing,2010,pp.1083-1091.。这些语料库的建立使得CCG有可能和深度学习算法得到的结果进行直接对比,而对比分析的结果又可以对CCG和深度学习算法进行双向的修正和优化。
1 深度学习算法求解的语义理解模型
1.1 深度学习算法简介
一般意义上的算法是人为设定的一些规则,机器能做的只是严格地执行这些规则,而机器学习算法本质上是从没有规则的数据中总结出规则的算法。也就是说,机器学习算法不是直接定义机器工作所需要的规则,而是使机器自己总结工作所需要的规则,而且面对不同的数据,会总结出不同的规则。可以说,机器学习算法是“授人以渔”而不是“授人以鱼”。比如,我们想让机器识别人类喜怒哀乐所呈现的不同面部表情,但是我们并不使用五官的位置规则来直接告诉机器什么是喜怒哀乐的表情,而是通过输入很多标注喜怒哀乐表情的图像数据,让机器自己从中总结各种情感所对应的五官位置、面部肌肉形态等信息构成的规律。这种算法的运行过程就是机器从数据得到规律的过程,也就是“机器学习”的过程。
从最简单的线性回归,到现在最流行的人工神经网络,都是“学习算法”,因为这些算法都是从数据得到规律的算法,而“深度学习算法”是学习算法的一类,在实际使用中几乎可以和“人工神经网络”互相替换,其中“深度”是相对于传统两三层的人工神经网络来讲,深度学习算法使用的人工神经网络的层数通常是上百层。而人工神经网络应用在语义识别上的突破性成果就是引言中提到的Mikolov等(2013)撰写的这篇论文,其中所使用的人工神经网络只有一层,增加更多层的神经网络反而会出现过拟合现象。至于只有一层人工神经网络的学习算法是否叫“深度学习算法”仅仅是名称分类的问题,并没有实际的意义。本文中“深度学习”这个词倾向于采用参与创建“谷歌大脑”深度学习项目的吴恩达教授在多次演讲中反复强调的观点,也就是把具有不断消化数据来改进最优化问题数值解性质的算法,都称为深度学习算法。因此,即使只有一层人工神经网络的算法,只要具有上述性质的话,也可以称为深度学习算法。
包括人工神经网络在内的所有机器学习算法从本质上讲都是数值最优化的问题。也就是说,有一个目标函数,我们试图找到这个函数的自变量取值,使得函数值尽可能的小,也即求函数最小值的问题。这个目标函数也称为这个数值最优化问题的“模型”。不同的问题对应不同的目标函数,换言之,建立了不同的数学模型,好比不同的应用题,根据题目列出来的方程也不一样。不同的目标函数,求函数最小值方法也多种多样,即使采用机器学习的算法来求函数最小值,这种学习算法也有几十个大类。其中,人工神经网络是解决图像识别、语音识别、语义识别等“模式识别”类问题的一种比较有效的方法。
做应用题分为两步:第一步,列方程;第二步,解方程。我们现在面对的问题是让机器听懂人话的问题,也就是语义识别的问题。面对这个问题我们也要先“列方程”(给出目标函数),再“解方程”(求函数最小值)。其中,关于求函数最小值的这个过程不限于人工神经网络,可以是任何机器学习算法,而最优化问题的求解过程和算法实现也不是本文要讨论的内容。本文要讨论的是“列方程”的问题,或者说,给问题建立数学模型的问题。具体说,是给出目标函数的问题,以及这个目标函数及其最优解和组合范畴语法之间的对比修正关系。
1.2 词向量和目标函数
无论是文字还是讲话,机器都是不能直接理解的。机器只擅长做一件事,那就是数值计算。所以,让机器听懂人话的第一步就是把“人话”变成“数字”,具体来讲就是把自然语言中的每个词都对应上一串数字,这串数字就是这个词对应的词向量。一门语言的词汇表中每一个词汇都变成了一串数字。词汇表数字化之后的词向量表就是我们要优化的变量,相当于列方程之前设好了要求解的未知数。一般把向量化之后的词汇表记作θ,这就是目标函数要优化的自变量。
词汇变成数字后的词向量已经可以给机器输入了,那么是否把整本包含所有词汇的词典给机器输入,加上快速的检索能力机器就能学会“人话”呢?答案是否定的。首先,词典中的每个词都是用其他词来解释的,而这些用来解释的词也是需要词典来解释的,所以任何包含所有词汇的词典必然会出现循环定义,因而最核心、最基本的词实际上等于没有定义。另外,实际使用的句子中词汇组合的结果往往是词典中没有出现的,但是这些词汇的组合出现却是有规律的。词典不能穷举完一种语言所有可能的组合情况,所以机器必须从有限的语料数据中自己总结出规律来,而从数据到规律就是深度学习算法的拿手好戏。
语言的规律大体来讲分为两个方面:一方面,不同语法功能的词在句子中的出现有固定顺序;另一方面,语义有关联的词汇经常同时邻近出现。语义关联的信息就是向量夹角的信息,因而也是数字化的。深度学习算法对于分析语义关联的规律效果显著。
深度学习算法给出目标函数的思路就是计算一个词汇出现的条件下另一个词汇出现的条件概率。然后,根据这个目标函数来判断现实中的语言实际情况是否吻合,如果不吻合的话,那么要调整目标函数中词汇向量表里每个词向量的数值,再用语言实际情况来判断是否吻合得更好了一些。如此反复,不断地调整目标函数中词汇向量表里每个词向量的数值,直到不能再改进为止。
同一个应用题,可以根据题目中不同的数量关系列出两个不同的方程,但都能求得应用题的解。同样地,面对识别语义关联的问题也可以列两个不同“方程”,或者说建立不同的模型,具体说就是给出不同目标函数,而它们的最优解都能够实现识别语义关联的能力。目前比较常用的两个模型是Skip-Gram(SG)模型和Continuous Bag of Words(CBOW)模型。SG模型的目标函数反映的是当前词出现的情况下,当前词附近出现哪些词的概率比较高,而CBOW模型的目标函数反映的是已经出现一些当前词,中间缺失哪个词的概率比较高。用不太准确的比喻来解释,SG模型是“给词造句”,而CBOW模型是“选词填空”。实际中,这两个模型目标函数给定的方式和最优解计算的过程都是对称的。
1.3 深度学习算法小结
通过对NLP深度学习算法的介绍,可以看出算法本身依赖统计学的基本假设,但是深度学习算法和纯统计学算法有本质的区别。纯统计学算法是从统计方法到统计结果,而深度学习算法是从无序到有序。也就是说,纯统计学的算法是利用统计学的知识,得到统计上的结果,人类从这些统计结果中发现并得到规律,而机器学习算法是利用统计学知识作为工具,从无序的词向量空间中构建出有序的空间结构,机器从有序的空间结构中发现并学习到规律。简单讲,一个是人在学习,人知道自己学习到了什么规律;一个是机器在学习,人不知道机器学习到什么规律。面对“学有所成”的机器,人类还需要测试机器的自学成果。
2 组合范畴语法(CCG)简介
把统计学直接应用在CCG上的尝试由来已久(4)Miles Osborne,Ted Briscoe,“Learning stochastic categorial grammars”,in T. Mark Ellison,ed.,CoNLL97:Computational Natural Language Learning,Proceedings of the 1997 Meeting of ACL Special Interest Group in Natural Language Learning,Madrid,1997,pp.80-87;Ted Briscoe,“Grammatical acquisition:Inductive bias and coevolution of language and the language acquisition device”,Language,Vol.76,No.2,2000;Aline Villavicencio,The acquisition of a unification—based generalised categorial grammar,Technical Report,No.533,Cambridge:University of Cambridge,Computer Laboratory,2002.,但首次利用统计学方法建立覆盖大规模语料的CCG解析器的工作是Clark和Hockenmaier(5)Stephen Clark,Julia Hockenmaier,“Evaluating a Wide-coverage CCG Parser”,in Proceedings of the LREC 2002 Beyond PARSEVAL Workshop,Las Palmas,2002,pp.60-66.实现的。而后,Hockenmaier的博士论文更加全面地介绍了这个工作(6)Julia Hockenmaier,“Data and Models for Statistical Parsing with Combinatory Categorial Grammar”,PhD dissertation,University of Edinburgh,2003.。下面对CCG和CCG树库做简单的介绍。
2.1 范畴语法简介
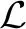

2.1.1 范畴形成规则
(原子范畴) S是范畴,NP是范畴。
(复合范畴) 如果X、Y都是范畴,那么X/Y和XY也都是范畴。
在实际中,给出的原子范畴可能更多,但仍然是有限的几个原子范畴,而根据生成规则,理论上可以生成的范畴是可数无穷多的。
2.1.2 函数应用规则
(>规则) X/Y Y→X
(<规则) Y XY→X
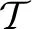
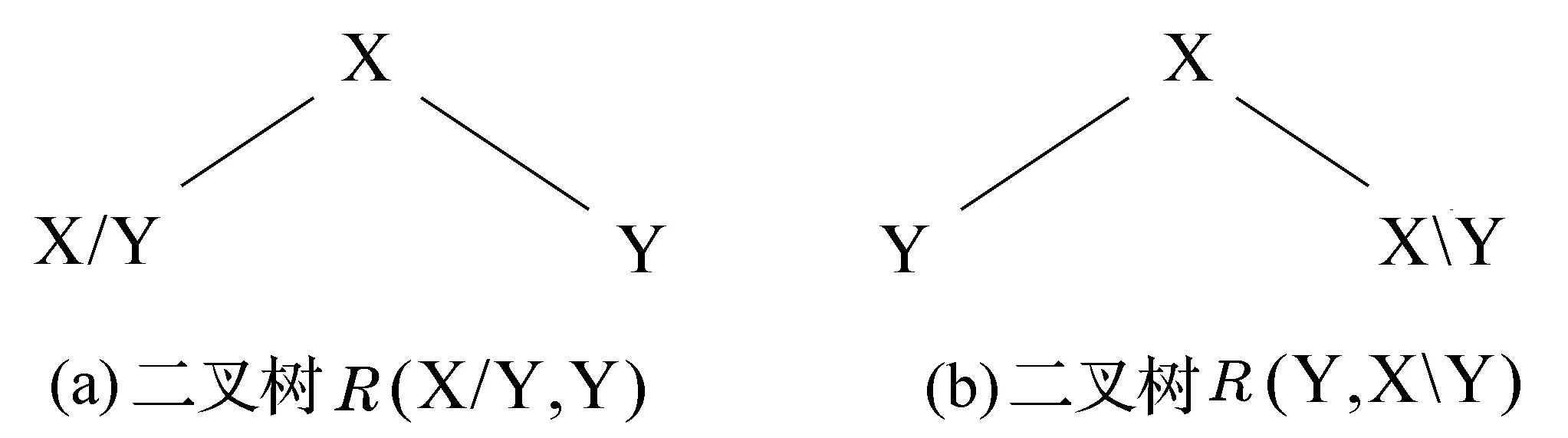
(图1) 范畴二叉树

2.1.3 范畴二叉树的生成

这个范畴指派生成的范畴二叉树是:
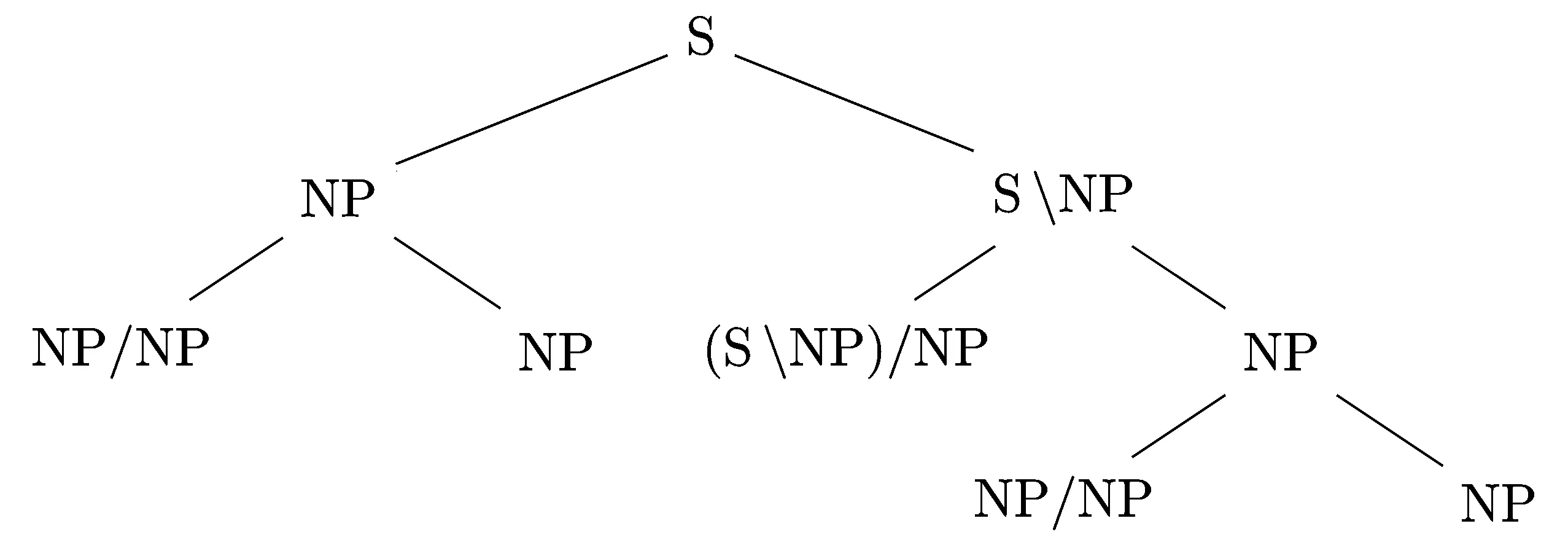
2.2 引入组合规则和范畴提升规则
仅使用函数应用规则的话,对语句的解析能力还是不够强,而且不够灵活。组合范畴语法(CCG)的“组合”指的就是在范畴语法的基础上引入的范畴复合规则和范畴提升规则,从而使得同一个语句有更多的解析方式。

范畴复合规则(B规则)>B规则X/YY/Z→X/Z 利用B规则和T规则在保持解析树可生成的前提下可以改变解析树生成的顺序,同时也使得同一个句子能生成更多的解析树,也即更多的理解方式。 (图2) B规则和T规则的使用效果 图2(a)中没有使用范畴提升规则和范畴复合规则,因而解析树的生成只能是从句末到句首。而图2(b)通过使用范畴提升规则和范畴复合规则使得解析树的生成顺序变为从句首到句末,这样的顺序即是语言生成的自然顺序,也使得解析树的生成方向可以有统一的范式,从而给计算过程带来便利。 作为参考标准的宾州树库的词例有929552例,其中词条75669条。换做前面深度学习算法中的变量,词例数量就是929552,而词汇表中词汇的数目就是75669。这个规模和深度学习算法语料库的规模相去甚远。原因是最原始的宾州树库的POS标签并不能实现完全的自动标注,每个词的POS标签都需要专业人士的审核,这就限制了语料库的规模。而深度学习算法使用的语料库中的语料是未经任何加工的原始语料,尤其是利用当前的互联网语料资源,获得十亿词例的原始语料并不是困难的事情。 深度学习算法应用在语言学上的成功主要表现在能够正确地抓住语义信息以及语义之间的联系,但是深度学习缺乏对语言的句法结构的规律总结,因而不能够像CCG一样推演组合出语言句子的语义。而组合范畴语法对句法结构的规律总结不但系统和精练,而且便于计算,但是缺乏对语义外延信息的存储和分析。可见,深度学习算法和组合范畴语法之间应该是互补的关系而不是竞争的关系。 Mikolov等(2013)确实也使用宾州树库作为参照系进行了对比。作为开创性的实验,Mikolov等(2013)用的语料库有三亿两千万词例(320M),而词汇表中的词汇有八万两千词项(82k)。其中和宾州树库能够重合的语料中的词例267M,也就是能够用宾州树库POS标记的词例。其中对最常用的形容词、名词和动词之间语法的类比关系进行了测试。对于“man:men=king:kings”、“see:saw=catch:caught”这种语法上的类比,深度学习算法的正确率也达到了40%左右。因为参照的是人工审核POS标注的宾州树库,无人监督的深度学习对语法结构的理解能力已经很可观,但和人类专业人士比较起来还是有不小差距。而宾州树库以及宾州树库转换来的其他树库对“man:woman=king:?”这样的非语法的语义信息就完全无能为力了。 这里给出深度学习算法和CCG两个方面进行对比的具体方案:一方面是CCG对语句解析能力和深度学习算法对语句出现概率的对比分析(表1),这里是依据CCG库的结果来评价深度学习的效果;另一方面是CCG解析树允许的范畴和深度学习算法计算出的概率上推荐的范畴的对比,参见图3和公式(2),这里是用深度学习的计算结果来评价CCG库中解析树和范畴的合理性。Mikolov等(2013)已经使用宾州树库的POS标注作为参考标准来评价深度学习算法对句法掌握的程度,这也是后续一系列算法改进的标准做法。事实上,从宾州树库转译来的CCG库不但可以作为评价深度学习算法的标准,而且还可以直接优化深度学习算法,因为嵌入多维空间的词向量中的目标函数优化的初衷就是评价一个句子出现的概率。 下面使用范畴语法简介中的例句,给出使用CCG库对比深度学习,作为深度学习结果评价标准的一个解决方案。 PoorJohnlovesluckyMary. 在词嵌入实现中,无论是采用SG模型,还是CBOW模型,看似都没有考虑句子中词的出现顺序,而只是计算一个词出现的前提下另一个词出现的模型,但是词出现的顺序却影响整个句子的概率。比如“Poor”、“John”、“loves”、“lucky”、“Mary”这五个词同时按照句子中的顺序出现的概率。 (表1) CCG语句解析能力和深度学习算法语句概率对比示意表 此时,根据算法的最优解θ*就可以给出“Poor John loves lucky Mary.”这句话S1的概率P(S1)。而这五个词总共有120种排列的可能,其中有的是符合语法的句子,有的是不符合语法的句子。对于是否符合语法,CCG库可以给出明确的对错判断,而深度学习算法给出的是概率判断。 如果有一种句法分析器对于上述五个词的120种词序的句子只能对其中前四种给出解析树,而其他的句子认为是不能进行解析的句子的话,那么这种解析器对句法的要求就过于严苛,不能反应语言实际使用中的灵活性。但是,如果一种句法解析器能够对上述五个词的120种词序的句子都给出解析树,那么这种解析器对句法的要求就过于宽松,相当于没有任何句法规则可以遵循。而组合范畴语法能够给出大部分可能词序构成的句子的解析树,并且同一个句子可以给出一种以上的解析树,所以组合范畴语法是对句法的宽松和灵活把握比较适度的一种逻辑语法。 深度学习算法不能给出任何解析树,对可能词序构成的句子是否符合句法也没有“是”和“否”这样的二值判断,甚至对句子中词性的判断正确率也不到一半,但是深度学习算法却能够给出所有可能词序构成句子的一个数值上的判断,也就是当前词序出现的句子符合句法的概率P(Si)。 同时,一个词对应多个范畴的情况,使得组合范畴语法(CCG)能够解析更多的词序构成的句子,但同时也使得同一个词序的句子有两个以上的理解方式。也就是说,同一个词有两个以上的范畴标注,同一个句子有两个以上的解析树生成。对于词序比较灵活的汉语而言这种情况更加普遍。比如汉语中“鱼我所欲”对应词序的英文“fish I want”就极少在英文中出现。古汉语中“所”其实对宾语前置做了标识,但是现代汉语中没有这个标识,而宾语前置的现象仍然非常普遍,例如: “喜欢”的宾语后置虽然我不懂旋律,但我喜欢歌词。“喜欢”的宾语前置虽然旋律我不懂,但歌词我喜欢。不及物动词“喜欢”虽然旋律我不懂,但老师我喜欢。 其中,以“?-我-喜欢”这三个词构成的结构为例: w1w2w3w11歌词我喜欢w12老师我喜欢 以陈鹏(2016)给出的汉语CCG解析器为例,这个解析器可以给出图3中的结果(a)和(b),但是不能给出结果(c)。 (图3) CCG库给出的解析树和实际理解的解析树对比 我们看到,(a)和(b)的范畴指派和解析树的结构是完全一样的,分别把句子理解成((歌词(我))喜欢)和((老师(我))喜欢),其中“喜欢”是不及物动词,“歌词我”和“老师我”都是当作名词词组。而(c)中的理解是(歌词((我)喜欢)),其中“喜欢”是及物动词,而“歌词”是“我喜欢”的前置宾语。 “老师我”之所以是汉语实际理解能接受的,原因是“老师”是对人的称呼,但是“歌词”却不是对人的称呼,所以“歌词我”作为名词短语的理解是不符合实际情况的。这其中的细微差别需要借助更细致的语义分析才能发现,而语义分析正是深度学习算法的优势。一个优化好的θ很有可能包含了这样细致的语义信息,此时可以计算任意一个词出现的前提下另一个词出现的条件概率。即P(wj|wi),其中,w11=歌词,w12=老师,w2=我,w3=喜欢,此时应该有 P(w11|w2)< (1) 这说明“我”出现的条件下“歌词”出现的概率相对来讲应该远小于“老师”出现的概率。对比(a)和(c)整句的概率计算应该有结果 P(w3|(w11∩w2))< (2) 这说明“歌词我”出现的条件下“喜欢”出现的概率相对而言应该远小于“我喜欢”出现的条件下“歌词”出现的概率,从而需要给出(c)的解析树,以及对应的范畴指派。 由于汉语CCG树库是从英语宾州树库转译过来的,所以汉语中常见的宾语前置的句法结构在英文中几乎不会出现。树库中“喜欢”做不及物动词的时候范畴是SNP,而“喜欢”做及物动词的时候范畴只能是(SNP)/NP,但是宾语前置这种结构的及物动词“喜欢”的范畴应该是(c)中的(SNP)NP。这个范畴在宾州树库以及汉语CCG库中都不存在。所以,此时深度学习的算法可以使得(SNP)NP的存在合理性得到实际语料计算而来的数据支持,丰富句法的规则,扩充范畴的数目。 词向量嵌入高维空间的深度学习方法虽然对语义信息的提取和语义关联的识别效果显著,但是对句法结构的分析能力跟受过专业知识训练的人类相比还是差距较大。范畴逻辑的二叉树生成规则相当于对相邻词出现与否的筛选规则,并且二叉树结构使得句子中相距较远的两个词也能使用二叉树生成规则。CCG的这种规则和深度学习算法中SG模型以及CBOW模型中描述的当前词窗口中的周围词出现概率的方式原理上很类似,只不过CCG做出的是外围词能否出现的二值判断,而深度学习算法做出的是外围词出现的概率判断。基于这个事实,用CCG来优化SG模型以及CBOW模型才有可能实现。一方面,深度学习算法的结果和CCG库生成的二叉树进行对比,另一方面,CCG的结果用来对深度学习的算法进行优化。在实际应用中两个方法也可以并列使用。
2.3 CCG树库简介
3 范畴语法和词向量对比
3.1 CCG作为深度学习算法的评价标准

3.2 深度学习算法改进CCG的方式



4 结语
