基于评分填充与信任信息的混合推荐算法
2020-10-18沈学利李子健赫辰皓
沈学利,李子健,赫辰皓
(1.辽宁工程技术大学软件学院,辽宁葫芦岛 125105;2.辽宁工程技术大学电子与信息工程学院,辽宁葫芦岛 125105)
(*通信作者电子邮箱zijianli1122@163.com)
0 引言
我们生活在一个信息时代,每天都有越来越多的书籍、期刊文章、网页和电影问世。越来越庞大的数据总量造成了信息筛选的困难,这便是信息过载问题。推荐系统是解决信息过载问题的一个重要手段,然而推荐系统长期面临着数据稀疏性的问题。造成此种问题的主要原因是用户仅仅为其交互过的少数项目评分,常用数据集的评分稀疏度均在5%以下,而一些真实数据集的评分稀疏度甚至不足0.1%,评分数据的大量缺失造成推荐算法提取数据关系时缺乏足够的依据,造成推荐偏差。
为了缓解数据稀疏性问题,研究者们主要从以下两个方面进行改进:一方面,使用混合推荐的方法。利用一种算法对评分矩阵中缺失值进行填充,再使用另一种方法基于填充后的矩阵上生成预测结果。比如杜倩[1]使用聚类获取用户近邻的评分均值实现评分填充;Liu 等[2]使用奇异值分解(Singular Value Decomposition,SVD)算法实现矩阵缺失值的填充。另一方面,在评分信息之外,通过引入辅助信息(side information),增加算法中的有效信息量,从而达到缓解数据稀疏性的目的。比如,刘方婷等[3-5]分别将时间因素、社交关系与用户(项目)属性信息引入到推荐算法中。
上述两种方法从两个不同的角度,对于数据稀疏性问题起到了一定的缓解作用。为了进一步提高推荐准确度,本文对两种方法分别加以改进与融合,提出一种基于评分填充与信任信息的混合推荐算法RTWSO(Real-value user item restricted Boltzmann machine Trust WSO):
首先,使用基于用户与项目的实值受限玻尔兹曼机(Real-value User Item Restricted Boltzmann Machine,RUIRBM)算法对评分矩阵进行填充。受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一种二层神经网络模型,由Salakhutdinov 等[6]于2007年首次应用在推荐系统中,取得了良好的推荐效果。本文提出使用一种基于实值的,同时对项目与用户建模的受限玻尔兹曼机(RUI-RBM)模型对用户-项目评分矩阵进行填充,以达到更加精确的评分填充效果。
其次,使用填充完整的评分矩阵,通过加权Slope One(Weighted Slope One,WSO)算法对评分进行预测。本文算法中的权值将使用信任信息相似度。本文提出一种基于矩阵分解的信任关系相似度计算算法,此算法通过概率矩阵分解[7]获得用户间的间接信任关系,并且同时考虑信任信息中的信任与被信任情况。
本文算法RTWSO通过对两个算法的线性组合,缓解了单一算法所存在的数据稀疏性问题,并对信任信息进行合理化建模,提高了算法的精确度。
1 相关工作
Salakhutdinov 等[6]提出的应用于推荐系统的受限玻尔兹曼机模型示意图如图1 所示,模型包含一个可见层与一个隐藏层。对于包含m个用户、n个项目,评分范围1~k的推荐情景,此模型对每一个用户建立一个RBM 模型,每个模型的可见层中包含n个包含k个节点的Softmax 单元,用于表示此用户对所有项目的评分,可见层每个节点与隐藏层形成全连接。
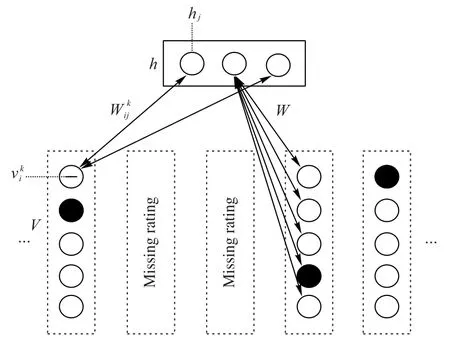
图1 受限玻尔兹曼机模型Fig.1 Constrained Boltzmann machine model
RBM模型主要存在以下缺陷:
1)模型的可见单元使用k维的Softmax 单元表示,导致模型所涉及的参数变为原来的k倍,大幅降低了模型的运算效率;
2)由于每个RBM 模型间共享权值和偏置,这使得如果两用户对同一项目进行评价,那么它们所对应的RBM 模型将在该项目的可见单元与隐单元得到同样的权重与偏置,缺乏可解释性。
针对上述两个问题,Georgiev 等[8]提出将评分数值直接应用在可见层,降低了算法的复杂度;霍淑华[9]提出一种基于项目的RBM 模型,取得了较优的推荐效果。本文在此基础上,使用一种基于实值的,并同时对项目与用户建模的受限玻尔兹曼机模型(RUI-RBM),模型如图2 所示。此模型主要进行了如下两点改进:
1)在模型的可见层中,评分值直接使用用户评分值表示,未评分数据由0 表示,相对于Softmax 单元,削减了参数数量,使训练时间大大缩短;
2)不同于传统RBM 模型只针对用户或项目进行建模,本模型同时对用户与项目建模,评分值由两模型权重与偏置共同决定,模型具有更强的可解释性。
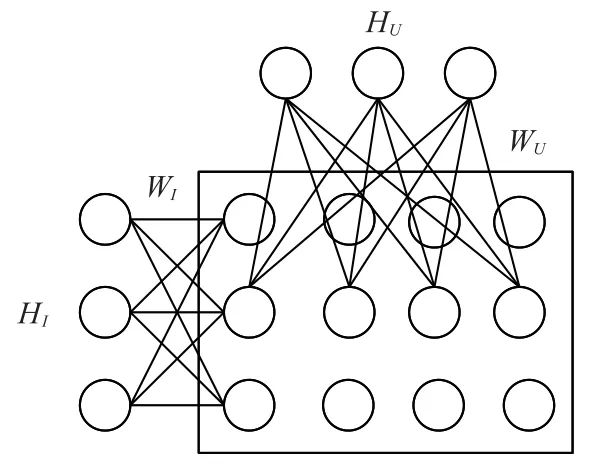
图2 RUI-RBM模型Fig.2 RUI-RBM model
由图2 所示,方框内表示包含m个用户、n个项目所形成的评分矩阵,评分范围1~k的推荐情景,RUI-RBM 模型可视为基于用户的受限玻尔兹曼机(Real-value User Restricted Boltzmann Machine,RU-RBM)模型以及基于项目的受限玻尔兹曼机(Real-value Item Restricted Boltzmann Machine,RI-RBM)模型叠加而成,RU-RBM 与RI-RBM 分别包含各自的连接权重Wu与Wi,以及各自的隐单元偏置bu、bi,可见单元偏置cu、ci,两模型共享评分矩阵。在模型构建过程中,RUI-RBM模型将会对评分矩阵同时从基于用户以及基于项目的角度进行建模,RU-RBM 与RI-RBM 共享评分矩阵,但训练过程相互独立,下面以RI-RBM为例来对模型训练过程加以说明。
图3表示一个RI-RBM模型,模型包含一个可见层V,层内包含m个实值节点,隐藏层包含n个二值单元,用于提取数据间特征。可见层与隐层各节点均包含一个偏置,使用bj表示第j个隐节点偏置,ci表示第i个可见节点的偏置,所有偏置值初始值设为0;wij表示第i个可见节点与第j个隐节点的连接权重,使用满足正态分布N(0,0.01)的随机数进行初始化。由RBM 的结构可知:当给定可见单元的状态时,隐单元各节点激活条件独立;反之,给定隐单元状态时,可见单元取值也是独立的。可见节点使用实值表示评分,应在原RBM 能量模型基础上加入一个二次方项,此模型的能量计算公式为:
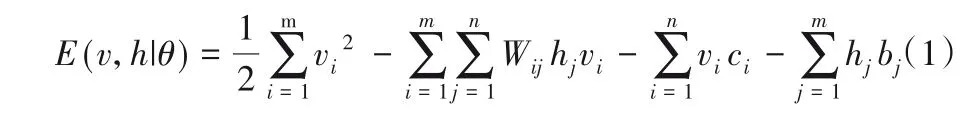
根据能量公式,则当可见层数据已知时,第j个隐单元的激活概率为:
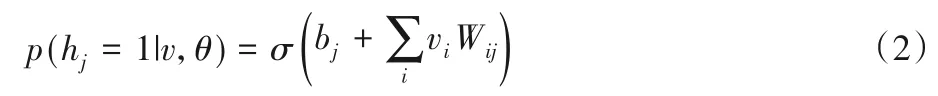
当隐单元的状态确定时,第i个可见单元的值为:

参数的更新方式使用对比散度方法,参数更新准则为:
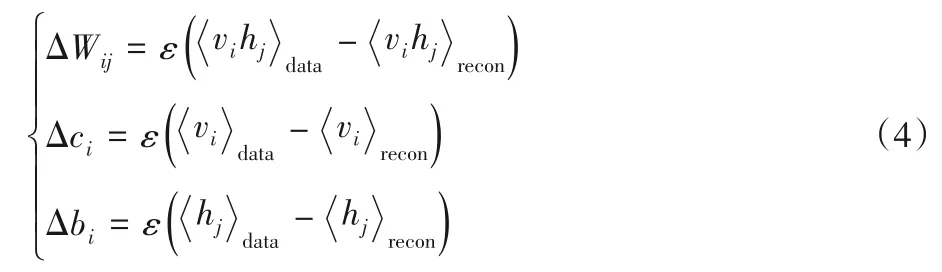
其中:ε为学习率;为一次重构后模型定义的分布。
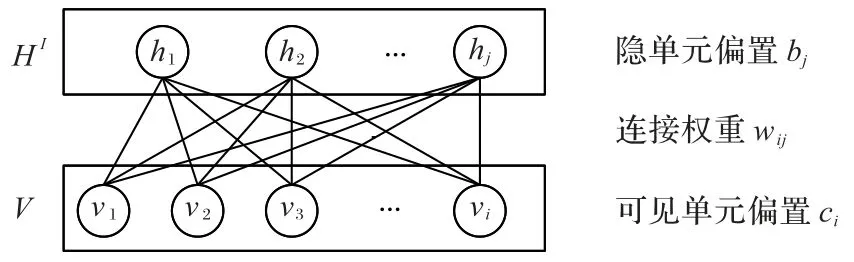
图3 RI-RBM模型Fig.3 RI-RBM model
RU-RBM 与RI-RBM 的训练过程类似,RUI-RBM 模型对两模型的训练加以整合,RUI-RBM 的训练过程分为三个阶段:
1)正阶段(positive phase),可见单元状态已知,给定数据样本、训练周期和隐单元数,得到隐单元激活概率。
2)负阶段(negative phase),根据上一阶段获得的隐单元状态,重构可见单元的值。
3)更新阶段(update phase),更新参数的值。
模型参数设置:使用CD(Contrastive Divergence)算法对RU-RBM 与RI-RBM 进行训练,CD 算法中学习率ε设置为0.1,Gibbs 采样步数T设置为1,权重衰减损失函数中的正则化参数通过实验选取λ=0.000 2,momentum 冲量设置为0.5[10]。
为了训练一个RUI-RBM,用上述方法分别训练RU-RBM与RI-RBM,负阶段之后,每一个RBM 会对可见单元值进行重构,重构后的可见单元值可视为RBM 模型对评分的一次预测。在更新阶段,使用RU-RBM 与RI-RBM 分别重构后的评分矩阵的均值来代替原评分矩阵,并使用新矩阵中数值更新RU-RBM与RI-RBM的可见单元,评分更新公式为:
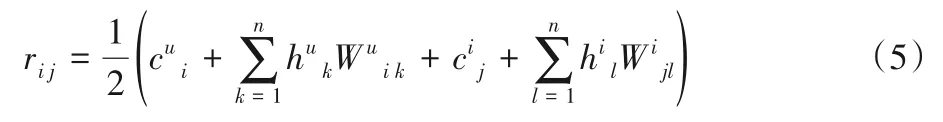
模型的误差计算使用原评分矩阵中所有评级与重构后对应评分来计算,使RBM 预测评分接近真实评分。当RUI-RBM模型达到收敛或达到训练次数时,训练过程完成,此时得到的重构后的评分矩阵R′可视为使用RUI-RBM 模型的预测结果填充完整的评分矩阵。至此,便完成了对于稀疏评分矩阵的填充。
2 信任关系相似度计算方法
信任关系假设用户与其信任的用户有着相似的喜好,在将信任关系引入模型的过程中,研究者遇到了以下两点问题:第一,在信任关系中分为信任与被信任两种关系,两种关系存在非对称性,即用户A信任用户B,并不意味着用户B对A有着同样的信任程度,但信任与被信任关系都在一定程度上反映着用户的喜好特征;第二,在实际应用场景中,所能提取到的直接信任关系往往十分稀少,用户可用的信任关系较少(往往少于5 个甚至为0),较少的可信用户不足以反映用户的喜好。针对以上两点问题,学者提出使用双向信任关系[11-12]以及间接信任关系来[13-14]改善推荐效果。本文信任关系度量将在现有算法基础上,将两者进一步改进并加以融合,提出一种融合双向信任关系的间接信任相似度计算方法。
2.1 信任与被信任关系
信任网络中的每个用户,都扮演着两个不同的角色:信任者与被信任者,作为信任者,评分可能与被信任者一致,而作为被信任者,评分可能会影响其信任者。用户担任不同角色时,表现出的偏好可能不尽相同。比如,一个摇滚乐手A,出于对绘画的喜爱,关注了画家B,同时被乐迷C关注,那么可以预见,在音乐作品上,A与C的偏好更加相似,而在绘画作品上,A与B的偏好更加一致。所以,在对评分进行预测的过程中,同时考虑用户作为信任者与被信任者两种角色的情形更加合理。故本文中使用Rtk×n和Rek×n分别代表信任矩阵与被信任矩阵。
2.2 隐含信任相似度
针对直接信任信息稀疏性问题,提出使用基于矩阵分解的隐含信任关系相似度算法。首先由信任关系T中提取出信任与被信任矩阵Rt和Re,使用概率矩阵分解(Probabilistic Matrix Factorization,PMF)对矩阵T进行分解,假设信任关系T由关于用户的信任向量Rt和Re的正态分布生成,则其条件概率分布如下所示:
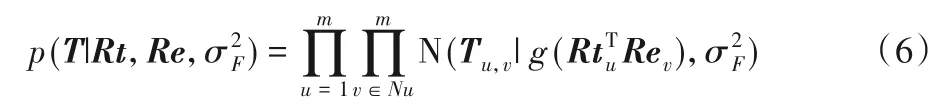
其中:g(x)=为sigmod 函数。同时,为了避免过拟合,Rt、Re分别满足正态分布:
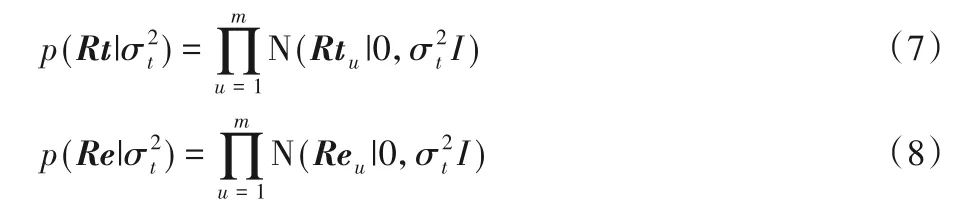
两者的后验概率分布为:
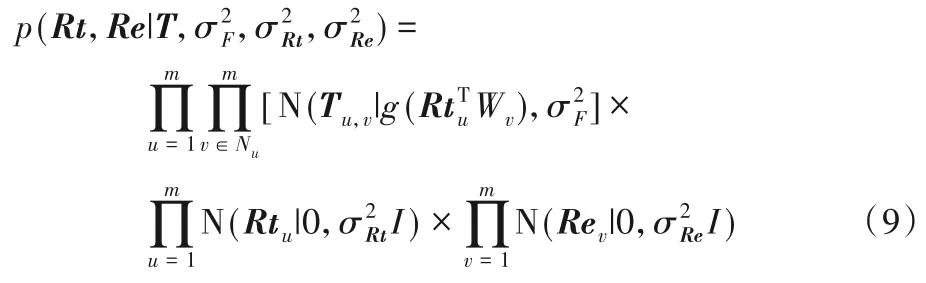
损失函数如式(10)所示:
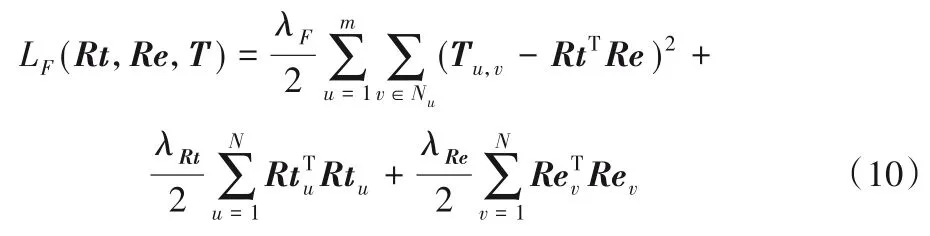
对此损失函数使用梯度下降法求解可得Rt与Re。
根据所得Rt与Re向量,可计算两用户之间的隐含信任相似度,用户u与用户v均作为信任角色时的隐含相似度为:

两用户同时作为被信任角色时的隐含相似度为:

用户间信任相似度将信任隐含相似度与被信任隐含相似度按一定比例加和,以权值k∈(0,1)来调整二者所占比重,隐含信任相似度计算如式(13)所示:

3 使用WSO算法生成预测结果
Slope One 算法[15]是一种基于项目的协同过滤算法,采用简单的一元线性模型f(x)=x+b形式进行表示。其中,b表示用户对两个项目评分矩阵的偏差平均值。基于此种思想,则在一个给定的训练集x中,项目i对于项目j的偏差公式如下:

其中:sj,i(x)为同时评价过两项目的用户集合;card(sj,i(x))为sj,i(x)中的用户个数。
在计算用户u对项目j的预测评分时,则需选取除j外所有被用户u评分的集合Rj中的项目,取评分的平均值作为用户u对项目j的预测评分。公式如下所示:
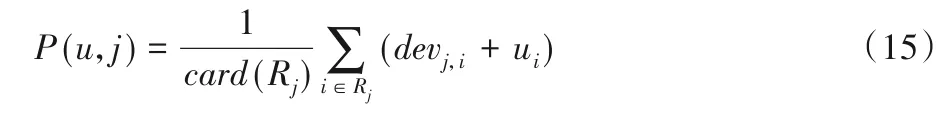
其中:|Rj|表示同时评分的项目总数。
由于Slope One 算法基于线性模型,相较于其他协同过滤算法有着较高的计算效率;并且由于其协同过滤思想,相较于较常使用的取近邻用户评分均值或加权均值的方法,使用偏差项修正不同用户的评分标准不一的问题,使结果更加合理。故本文使用Slope One 算法进行最终的评分预测。Slope One算法所存在的数据稀疏性问题,由矩阵填充方法解决,但评分矩阵由稀疏矩阵变为满元矩阵带来运算时间的大幅增加,为了缩短运算时间,通过选择与用户相似度最高的前N个用户组成的近邻集O,来替代偏差计算公式中sj,i(x)。另外,为了引入用户间的信任信息,将隐含信任相似度作为权值加入到算法中。故本文所使用的WSO 的偏差公式与预测公式如下所示:
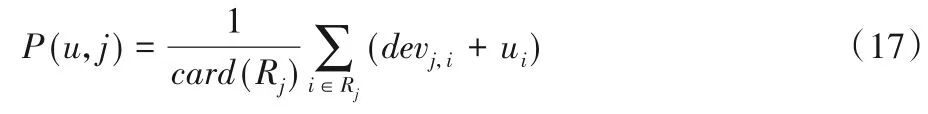
4 实验与结果分析
4.1 数据集及评价指标
实验数据集选用Epinions 数据集及Ciao 数据集,数据集中包含用户对项目的评分信息以及用户间的信任信息。实验采用5 折交叉验证的方式,将数据集分为5 份,每次抽取一份作为测试集,其余作为训练集,取5 次实验平均值作为实验结果。实验分为两个部分,首先,通过Epinions 数据集上实验结果确定模型各项参数最优值并验证混合算法是否提升了推荐效果;其次,通过Epinions 与Ciao 两个数据集上的实验,将本文算法与相关算法进行对比,验证本文算法的性能。
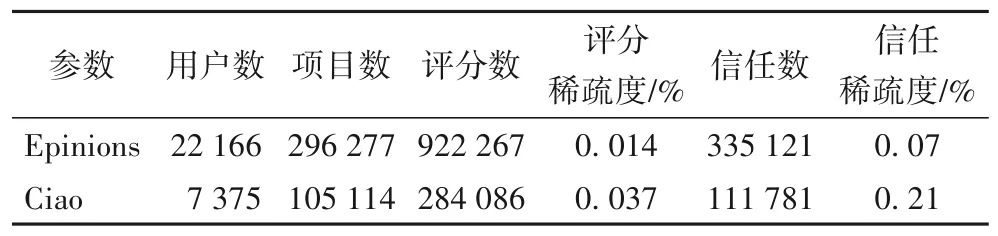
表1 数据集统计Tab.1 Statistics of datasets
实验使用平均绝对误差(Mean Absolute Error,MAE)及均方根误差(Root Mean Square Error,RMSE)作为评价指标。
MAE的计算公式如下:

RMSE的计算公式如下:
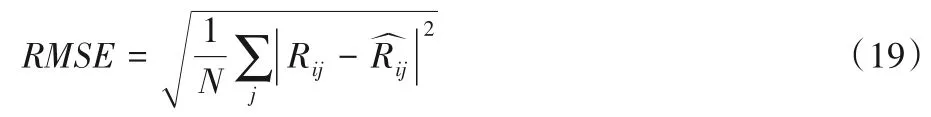
4.2 RUI-RBM模型对矩阵填充效果实验
4.2.1 隐单元数对RUI-RBM模型填充效果影响
本实验对RUI-RBM 中隐单元数对模型填充效果的影响。实验采用epochs=100 进行实验,探究不同隐单元数对RUIRBM 模型推荐效果的影响。实验设置隐单元数范围10~200,步长设置为10进行实验,实验结果如图4所示。
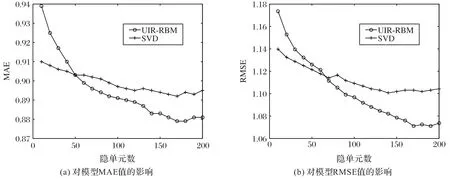
图4 隐单元数对RUI-RBM模型矩阵填充效果的影响Fig.4 Impact of hidden element number on matrix filling effect of RUI-RBM model
分析图4中数据可知,本文所提出的RUI-RBM模型,在隐单元数少于50 的MAE 值和在隐单元数少于70 的RMSE 值时,推荐效果弱于SVD 算法,而随着隐单元数量的增加,推荐效果超过SVD 算法,并在隐单元数在120个左右时,推荐效果趋于稳定,此时相较于SVD 在MAE 与RMSE 上分别下降3%左右。本实验验证了本文所提出的RUI-RBM 算法在数据集上对于矩阵填充的效果优于SVD 算法,并在隐单元个数n=170时取得较优推荐效果。
4.2.2 隐RUI-RBM模型中训练次数对矩阵填充效果实验
本实验建立在隐单元个数n=120 上,对RUI-RBM 中训练次数对矩阵填充效果进行实验,实验设置训练次数epochs上限为100,实验结果如图5所示。
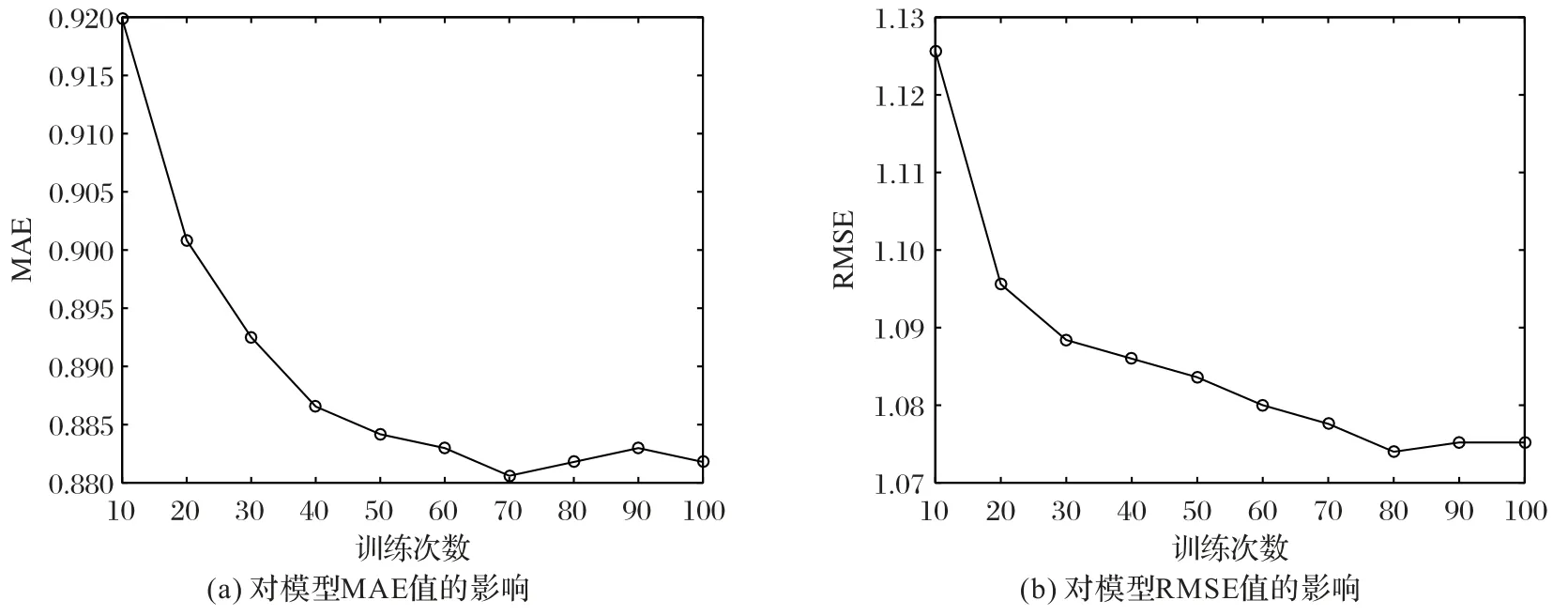
图5 训练次数对矩阵填充的影响Fig.5 Impact of training time on matrix filling effect
由图5 可见,RUI-RBM 模型在训练次数小于60 时,模型的MAE 与RMSE 值呈递减趋势;在训练次数达到70 后,模型趋于平稳。故模型选用epochs=70为默认参数。
4.3 Trust-WSO算法参数实验
4.3.1 最近邻居数目对推荐效果的影响
本节将对信任WSO(Trust-WSO)算法中,不同最近邻居数目N对模型推荐效果的影响进行实验。实验相似度选取为本文所提出的项目混合相似度计算方法,相似度计算方法中k值暂取0.5,初始使用步长为10,测试10~100 近邻个数时,算法分别在数据集上的MAE 值变化情况。实验结果如图6所示。
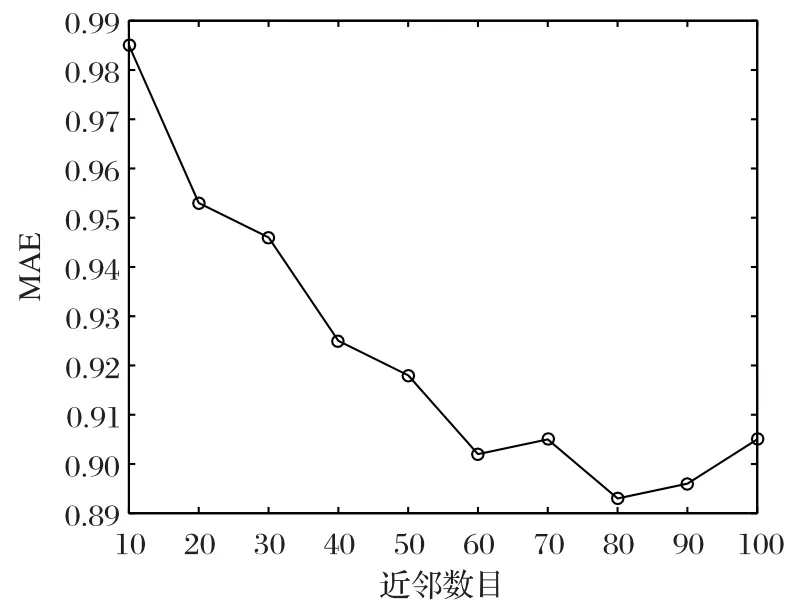
图6 近邻数目对模型推荐效果的影响Fig.6 Impact of nearest neighbor number on model recommendation effect
分析图5~6 中数据可知,在Epinions 数据集中:当10≤N≤30时,由于近邻数量较少,模型产生了比较大的波动,且MAE值表现较差;当60≤N≤80 时,推荐效果趋于平稳,并在N=80 时,得到最佳效果;当N>80 时,MAE 值呈现平稳上升状态。根据实验结果,选取N=80作为默认参数。
4.3.2 社交相似计算中k值对推荐效果的影响
由于相似度计算中采取两种相似度加权的形式,两种相似度计算方法以不同的权重相结合,对推荐准确度可能会产生较大的影响,故设计本实验以探究不同的k值对实验结果的影响。实验的目的主要有以下两点:首先,验证两种相似度方法的结合是否有效,即使用综合相似度计算方法的推荐准确度是否优于使用单个相似度;其次,在数据集中确定一个最优k值作为算法的默认参数。本实验对k值在[0,1]区间上以步长为0.1,取得11 个数据点来对加权Slope One 算法准确度进行实验,k值表示项目评分相似度在相似度计算方法中所占的比重,特别地,当k=0时,表示仅使用信任相似度;当k=1时,表示仅使用被信任相似度。
分析图7中数据可知,仅使用项目属性信息时,算法MAE值为0.917;仅使用项目评分相似度时,算法MAE值为0.910,而将两种方法以不同权值进行结合时,即k值由坐标轴向中间逐步靠近时,算法MAE 值呈现下降的趋势。说明本文将两种相似度方法的结合,有效地提升了推荐的准确度。在k=0.4 时,算法取得最优MAE 值0.889。故本实验确定0.4 作为k的默认值。
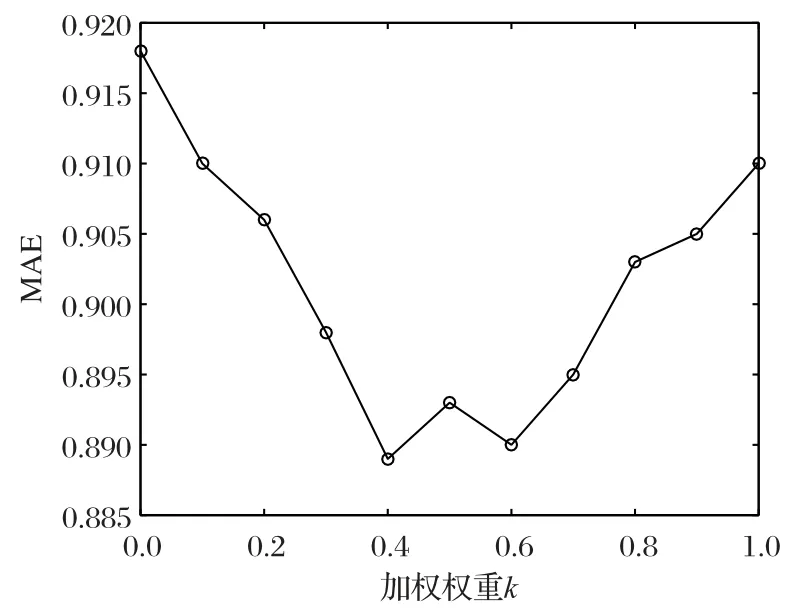
图7 k值对实验结果的影响Fig.7 Impact of k value on experimental result
4.4 RTWSO算法对比参数实验
本实验对RTWSO 算法的推荐效果进行实验,使用Epinions 与Ciao 两个数据集,选取组成算法RUI-RBM 以及S-WSO 算法进行对比,以探究两种算法的混合是否改善了推荐效果;另外,使用文献[15]中提出的基于信任关系隐含相似度的社会化推荐SocialIT(Social recommendation algorithm based on Implict similarity in Trust)模型;同时对信任者及被信任者建模的TrustMF(Trust Matrix Factorization)模型[11],使用SVD 与Slope One 混合推荐算法的SVD-Slope One 模型[16]以及文献[17]中提出的基于用户与项目,并引入属性信息层IC-CRBMF(Item Category-Conditional Restricted Boltzmann Machine Frame)模型进行对比。
实验结果如表2 所示。从表2 可知:本文所提出的RTWSO 算法,相较于其组成算法RUI-RBM 与S-WSO,在推荐准确度上有着较大的提升,说明两算法的混合有效地改善了单一算法的数据稀疏性问题;在与相关算法的比较中,RTWSO 分别取得了1.2%~8.4%的提升,说明本文所提出的算法具有较高的推荐效率。
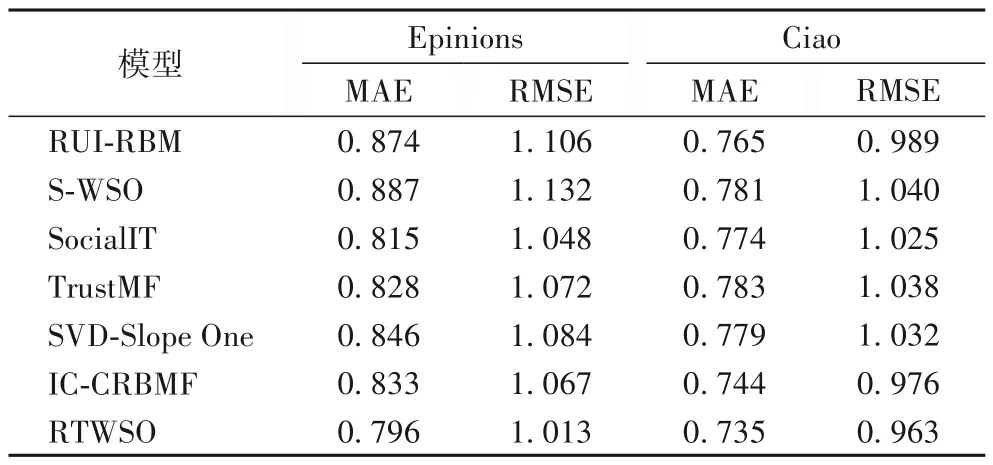
表2 RTWSO算法与其他算法的推荐效果对比Tab.2 Recommendation effect comparison of RTWSO algorithm and other algorithms
5 结语
本文提出一种基于评分填充与信任信息的混合推荐算法,首先使用基于用户与项目的实值受限玻尔兹曼机算法对原始评分矩阵进行评分填充,以缓解评分稀疏性问题,之后使用基于信任信息的WSO 算法对待评分进行预测。实验结果表明,本文算法在Epinions 以及Ciao 数据集上显示出较高的推荐准确度。本文主要针对数据稀疏性问题进行探索,在数据处理过程中去除了冷启动用户及项目对推荐结果所造成的影响,在下一步的工作中将对冷启动问题进行研究。
