基于多维社交关系嵌入的深层图神经网络推荐方法
2020-10-18何昊晨张丹红
何昊晨,张丹红
(武汉理工大学自动化学院,武汉 430070)
(*通信作者电子邮箱zhangdh@whut.edu.cn)
0 引言
随着社交网络的发展,利用用户间的社会关系进行推荐的方法能利用好友或信任等关系来改善推荐结果[1],更好地模拟现实社会中的推荐过程,更能体现出人在推荐过程中的作用,因此社会化推荐成了产业应用的研究热点。具有一定联系的用户之间的兴趣具有一定的关联,这是社会推荐系统的主要基础[2]。社交推荐系统通过用户之间的社交信息构建社交网络,可以改善协作过滤(Collaborative Filtering,CF)并解决冷启动和稀疏性问题。对于新用户,只要与其他用户有直接或间接的社交关系,就可以通过已知用户的社交关系和兴趣模式有效地推荐新物品。这种社会化推荐的策略是合理且科学的:一方面,社交网络分析(Social Network Analysis,SNA)的研究结果表明,基于网络社区中社交上下文信息的相互关系,相互关联的用户之间的兴趣爱好和行为规范相似[3];另一方面,随着社交网络和在线平台的广泛应用,在线用户的行为和习惯越来越体现出社区和网络的特征[4]。此外,在线社交网络的分析结果展现了社交推荐理论是有效和正确的[5],社交上下文信息无疑可以改善推荐系统。
在线社交网络中有相当多的研究,其中大部分集中在对社交图的结构分析上[6]。社交网络的人际关系,尤其是朋友圈,可以解决冷启动和稀疏性问题,通过社交网络之间的关系能有效推荐用户喜欢的物品(item)[7],例如音乐[8]、视频[9]、品牌/产品[10]、首选标签[11]、位置[12]、服务[13]等。
社交网络中的用户关系具有多样性,针对不同的社交网络有许多不同角度的研究,例如Yang等[14]建议使用基于社交网络上好友圈中“推断信任圈”的概念来推荐用户喜欢的物品。该方法不仅改善了复杂网络中的人际信任,而且减少了大数据的负载;同时,除了人际关系的影响外,Jiang 等[15]发现个人偏好也是社交网络中的重要因素。就像人和人之间想法会互相影响一样,由于偏好的相似性,通过概率矩阵分解模型构造的用户潜在特征应该与他的朋友相似[16]。Huang 等[17]将学习者的年龄和班级作为一个重要的特征应用在用户关系的研究中。Zheng 等[18]将文本主题模型融合到社会化推荐中。Lu 等[19]通过研究发现了电子商务系统中信任关系对购买行为有非常重要的影响。Yuan 等[20]探索了一种社会关系,将成员关系及其与朋友的结合作用这两种不同类型的社会关系通过分解过程融合到基于协作过滤的推荐器中,并发现了在稀疏数据条件下社会关系的显著有效性。用户的选择始终与其个人兴趣紧密相关,用户共享、上传和评论他们喜欢的内容非常受欢迎。因此,用户的个人兴趣可以通过它在社会评分网络中的历史评分记录来披露[21]。李琳等[22]研究了评论文本对推荐效果的影响。张宜浩等[23]研究了基于用户间情感关系的混合推荐。
大多数关于社会推荐的研究都集中在单一的社会关系上,很少有研究讨论复合社会网络在推荐中的复杂性和多样性。然而,近年来社交平台发展迅猛,用户之间的行为和关系也愈加多样化。例如,用户A 关注用户B 和用户C,用户B 信任用户C,用户B 和用户D 在一个兴趣小组,用户C 总是在用户D 的帖子下评论,用户A 和用户C 在个人资料上具有很高的相似性。这些用户之间的关联可以构成多层复合网络,多层社交网络迎来了新的挑战和机遇,不同的关系会不同程度地影响用户的偏好,进而影响用户的行为,因此通过融合多个社交网络是改善推荐的有效方法。虽然已有一些研究开始涉及多重社交网络推荐[24-25],但简单的线性叠加不能反映多重社交网络之间的耦合和非线性关联。文献[26]对多种社交网络进行了分析,采用概率模型对多种网络进行融合,构建多网络的联合概率分布,但训练时缺乏参数共享和非线性表示。本文基于此背景提出了一种多维社交关系下的图神经网络(Graph Neural Network with Multi-Social Recommendation,GNNMSR)推荐模型,通过对历史评价、各类社交网络构成不同维度的网络进行嵌入,实现不同社交网络对用户偏好的注意力集成,并在理论推导和实验验证中证明其有效性和可扩展性。
1 复合图神经网络的推荐模型
1.1 问题定义
本文实验数据的来源平台为Yelp 和豆瓣电影,这些社会化服务平台既提供内容服务,又提供社交功能。所有m个用户表示为(u1,u2,…,um),所有n个物品表示为(c1,c2,…,cn)。每个用户对每个物品的评分构成了m×n维实数评分矩阵R,Rij表示用户ui对物品cj的评分,如果Rij=0 表示用户ui没有对物品cj进行过评分或选择。在不同的推荐系统中,评分值的设定是不一样的,本文根据Yelp 和豆瓣的设置,将评分值设定为{1,2,3,4,5},评分越高表示越满意。本文提出的推荐系统所要达成的目标,是根据用户的历史评分记录和用户间的各类社交关系,预测每个用户ui对每个物品cj的可能评分,从而可以将预测评分最高的物品推荐给该用户。传统的方法主要是基于用户间单一的关系,例如关注、朋友等关系。然而在社交网络中,用户之间的社会关系具有多样性和复合性,这些关系体现了用户间不同的社交行为和影响程度,因此充分利用用户间的多维社会关系能提高推荐的准确性。
多重社交网络是指用户和用户之间的不同类型社交网络构成的复合图模型,假设用户间有N维的社交关系DIM={d1,d2,…,dN},那么多重社交网络模型可以表示为{Gs|s∈DIM},Gs=(V,Es)表示第s维的社交关系构成的图模型。其中顶点集合V表示了所有用户的集合,m×m大小的矩阵Es表示了第s维社交关系中用户和用户之间的关系集合,∈Es表示第s维社交关系中用户i对用户j的关系强度,Es中顶点到自身的边都用1 表示。针对不同类型的社交关系,主要有以下大类:
1)无符号关系。
2)有符号关系。
3)其他关系。
有一些用户关系无法通过实数进行表达或包含了额外的信息。例如用户之间的评论、私信、个人资料相似程度等,这种情况一般将标签数据通过语义计算转化为符号变量来构成一个有符号图或无符号图。
因此,本文所提出的多重社交网络下的推荐可以转化为机器学习问题:给定用户已有的评分矩阵R和多重社交网络图模型(其多维边为,计算用户的特征模型U和物品的特征模型C,使得用户特征符合多重社交网络的特点,并且根据特征可以计算每个用户对每个物品的预测评分,能准确地反映出用户对物品实际偏好程度。其中:U为k×m维的实数特征矩阵;Ui为矩阵U第i列构成的一个k维列向量,表示第i个用户的特征。C为k×n维的实数特征矩阵,Cj为矩阵第j列构成的一个k维列向量,表示第j个物品的特征,k表示特征的数量。
1.2 图神经网络
图神经网络是一种从卷积神经网络(Convolutional Neural Network,CNN)和图嵌入思想启发而来的新型拓展神经网络,可以在图领域对数据进行特征提取和表示,是一种高效、易扩展的新型神经网络,在处理图数据方面表现出了强大的功能。图神经网络通过对节点进行描述,并经过不断地更新节点状态,得到包含邻居节点信息和图形拓扑结构特点的状态,最终将这些节点通过特定方法进行输出,得到需要的结果。
基于卷积神经网络(CNN)和图形嵌入的图神经网络(Graph Neural Network,GNN)被用于对图形结构中的信息进行聚合。因此,它们可以对由元素组成的输入和/或输出及其依赖性进行建模,并且图神经网络可以用循环神经网络(Recurrent Neural Network,RNN)内核同时对图上的扩散过程进行建模。
在一个图中,每个节点由它的特征和相关的节点自然地定义。GNN 的目标是学习一个状态嵌入hu,包含每个节点的邻域信息,其中状态嵌入hu是节点u的z维实数向量,可用于产生节点标签的输出ou,表示节点u在某层网络输出的向量。设f为参数函数,称为局部转移函数,在所有节点间共享,并根据输入邻域更新节点状态。g是局部输出函数,它描述了输出是如何产生的。hu和ou定义如下:
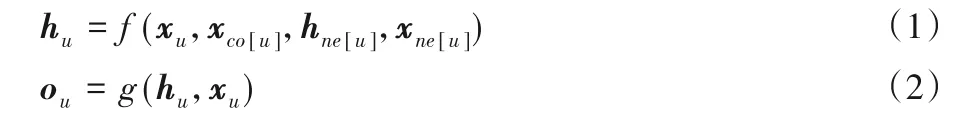
其中:xu、xco[u]、hne[u]、xne[u]分别是节点u的特征、其邻边的特征、其附近其他顶点的状态嵌入和特征。
GNN 通过网络层层迭代对参数进行训练,针对损失函数,学习f和g的参数,使得预测尽可能接近样本h,大量研究[27-28]表明,GNN是一个种强大的数据建模体系结构。
在推荐系统中,用户和用户之间的社交关系构成了图,用户和物品之间的评分选择行为也构成了图,因此GNN 对于推荐系统的图结构具有良好的适应性。然而,推荐系统中用户和物品的关系更加复杂,用户和用户的社交关系也存在多重特性,因此需要对网络进行优化和调整,才能更好地应对推荐中的各类问题。本文提出的推荐模型通过GNN 对用户偏好、物品偏好和多重社交网络进行融合,通过各个节点的本地领域采样和聚集特征生成嵌入,构成整个网络。下面分别来介绍各个部分的模型。
1.3 用户偏好模型
用户偏好模型是根据用户的历史评分记录来计算用户在偏好上的特征模型,可表示为k×m的矩阵UA,用户i的偏好特征向量为UAi(UAi为矩阵UA第i列构成的一个k维列向量)。本文提供一种基于用户偏好聚合的图神经网络来学习用户在偏好上的特征向量UAi,通过网络训练这个用户和其他用户在所有物品偏好上的特征,其特征向量可以表示为:
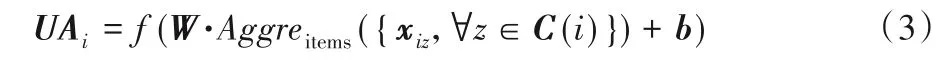
其中:C(i)是用户i的历史评价(选择)物品的集合;向量xiz是用户ui和物品cz之间的偏好特征表示;Aggreitems是物品聚合函数;f表示非线性激活函数(即修正的线性单位);W和b是神经网络的权重和偏差。针对本文实验中的特点,评分值为Rij∈{1,2,3,4,5},因此用户ui对物品cz的偏好特征向量xiz可以通过多层感知机(Multi-Layer Perceptron,MLP)对物品嵌入向量itemz和偏好嵌入向量rater进行合并来得到。itemz和rater作为多层感知机的输入,输出用户ui和物品cz的偏好特征向量,网络训练过程可以表示为:

其中⊕表示两个向量之间的级联运算。itemz和rater是物品向量和偏好向量在GNN 上的图嵌入。图嵌入是一种将高维稠密的向量矩阵图数据映射为低维稠密向量的过程,能够很好地解决图数据难以高效输入机器学习算法的问题。例如itemz表达的是m个用户是否选择物品a的向量,原始向量为长度为m、各元素为0 或1 的向量,嵌入后变成一个低维的向量。rater表达的是m个用户对物品a的评分的向量,原始向量为长度为m且各元素取值为0~5 的某个整数(包括0 和5)的向量,嵌入后也变成一个低维向量。
本文物品聚集函数采用主流的均值算子,即对xiz向量进行逐元素求均值。这种均值聚集函数是一种线性近似的局部频谱卷积,因此,函数可以转化为:
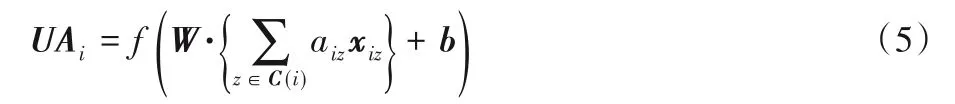
其中:aiz表示cz对用户ui在物品潜在特征上的贡献所体现的注意力权重。特别地,物品注意力aiz通过两层神经网络求参数的结构也可以称为注意力网络。这个网络的输入是用户偏好向量xiz和用户ui的嵌入向量useri。所以,这个注意力网络训练公式可以表示为:
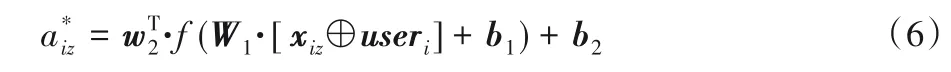
最终的注意力权重是通过softmax 函数对上述注意力得分进行归一化获得的,交互对用户ui的物品潜在因子的贡献可以表示为:

通过网络训练完成对aiz的计算,从而计算得到用户的特征表示UAi,整个网络的结构可以如图1所示。
1.4 用户社交关系模型
在社交关系模型中,考虑到多重社交关系对用户行为的影响,本文引入关注影响机制,在每个维度的社交网络中选择具有代表性的朋友来表征用户的社交信息。对于第d维的社交网络,每个用户ui的潜在因子是聚集了他在这个网络中的所有朋友(邻居)N(i)的潜在因子,因此可以表示为:
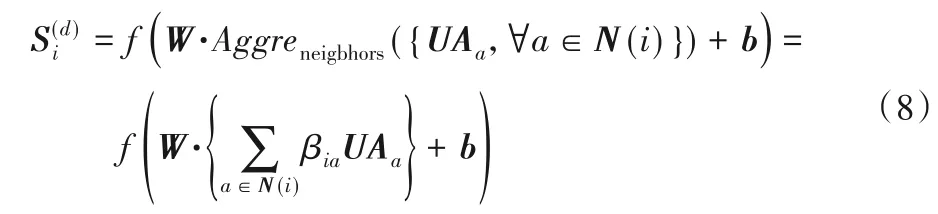
其中:Aggreneigbhors表示用户的邻居的聚集,同样采用加权平均函数来构造该网络;UΑa表示第a个用户根据用户偏好模型计算出来的偏好特征向量;βia表示用户a对用户i的兴趣影响,由于用户之间的影响有强有弱,混合在一起能更广泛地识别用户的兴趣,因此通过两层神经网络来构造用户的注意力机制。βia的学习过程可以表示为:
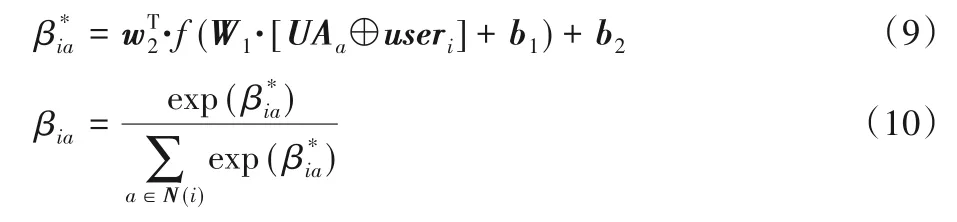
以上表示了单社交网络中用户社交特征表征,对于多维社交网络,则需要将用户通过网络进行嵌入,本文构造一个标准的q层MLP网络,结构如下:
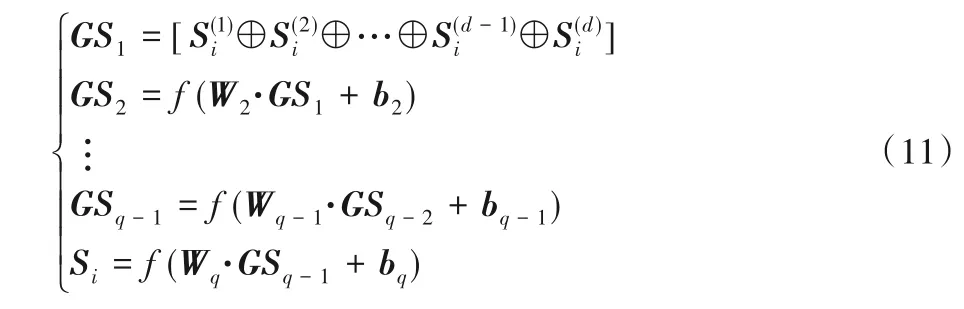
其中:GSt表示第t层网络的参数向量;Si表示用户i在多维社交网络叠加嵌入后的特征向量。整个社交网络模型的图神经网络结构如图2所示。
1.5 用户特征模型融合
根据用户偏好模型和多重的用户社交关系模型,建立一个标准MLP 模型将用户偏好计算的特征参数和各个社交网络计算出来的特征参数在网络中融合训练,以得到最终的用户特征编码,网络结构如下:
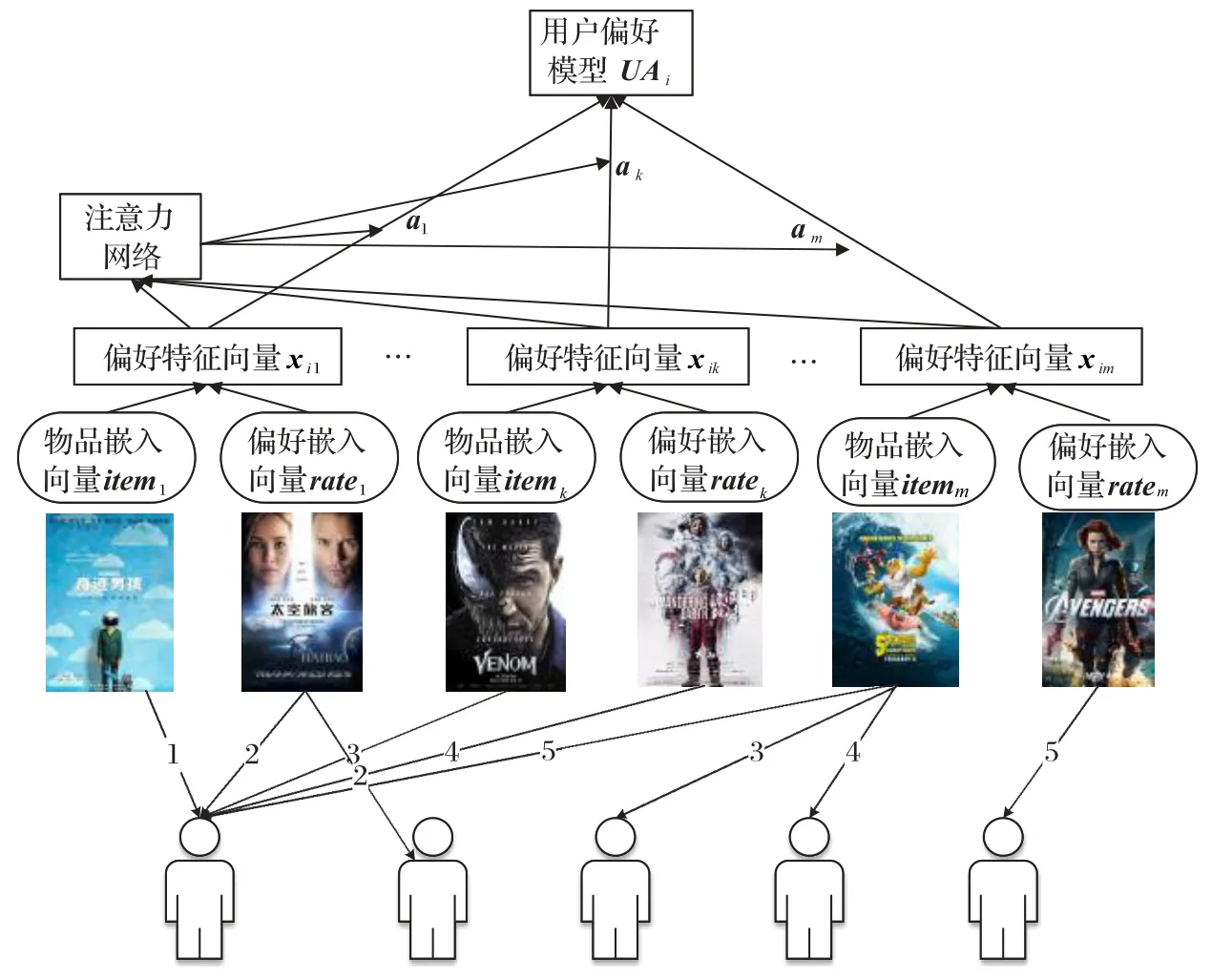
图1 用户偏好特征模型网络结构Fig.1 Network structure of user preference feature model
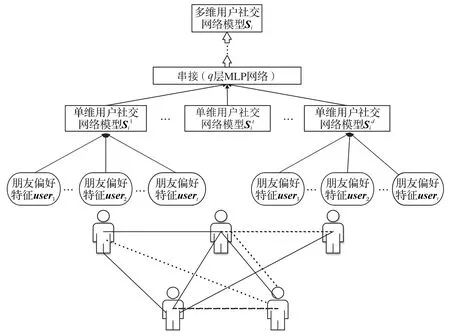
图2 用户社交关系模型网络结构Fig.2 Network structure of user social relationship model
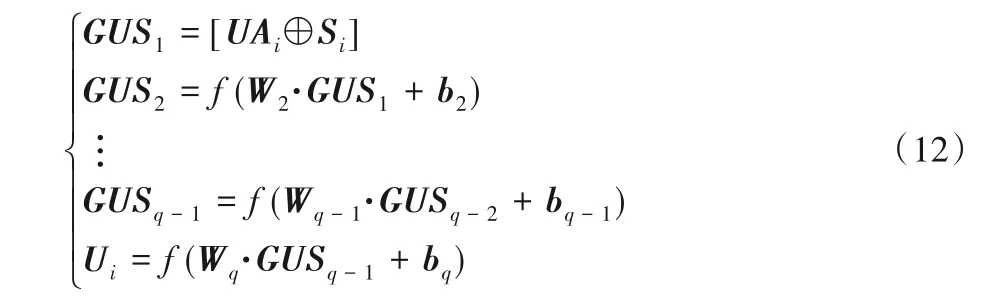
其中:GUSt表示第t层网络的参数向量;UAi表示用户i在用户偏好模型上嵌入的特征向量;Si表示用户i在多维社交网络叠加嵌入后的特征向量。U表示最终学习到的用户特性模型。
1.6 物品特征模型
物品特征模型通过用户聚集来生成每个物品cj的潜在因子向量Cj,物品受用户的评分从而构成了物品-用户的关联网络,对于每一个物品cj,将所有对该物品进行评分的其他用户定义为集合UC(j)。因此,构造一个意见感知交互的MLP 网络,通过物品用户嵌入编码usert和用户偏好嵌入编码rater作为输入,输出用户交互特征yjt,该网络可以表示为:

为了训练每个物品的潜在因子Cj,将该物品所有评价过的用户集合UC(j)的所有用户的意识感知交互进行聚集,聚集函数Aggreusers通过均值聚集来实现,将物品中每个用户的特征嵌入进行聚集,函数可以表示为:
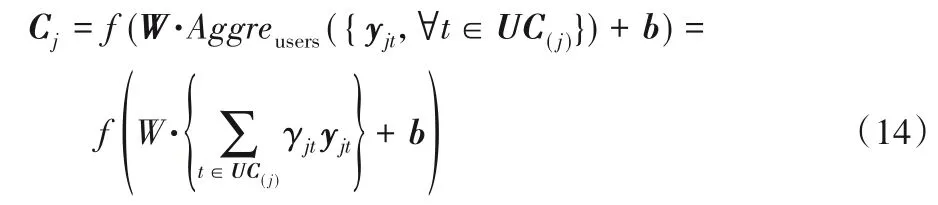
将这种偏好通过注意力机制来表示,因此γjt通过yit和itemj作为输入,构建两层注意力神经网络来反馈计算用户的重要性权重。γjt可以准确描述用户和物品交互对于学习物品的潜在因子的异质影响。γjt训练的网络结构可以表示为:
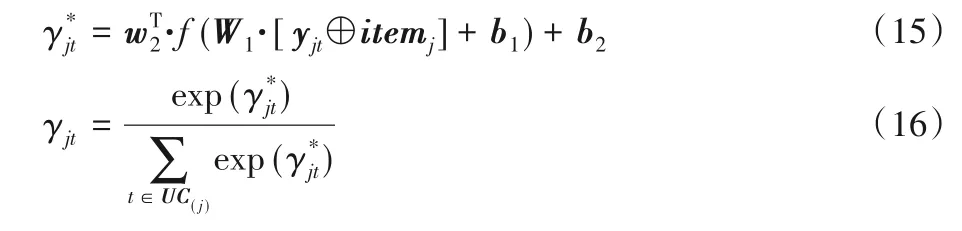
通过网络训练完成对γjt的计算,从而计算得到物品的特征表示Cj,网络的结构可以如图3所示。
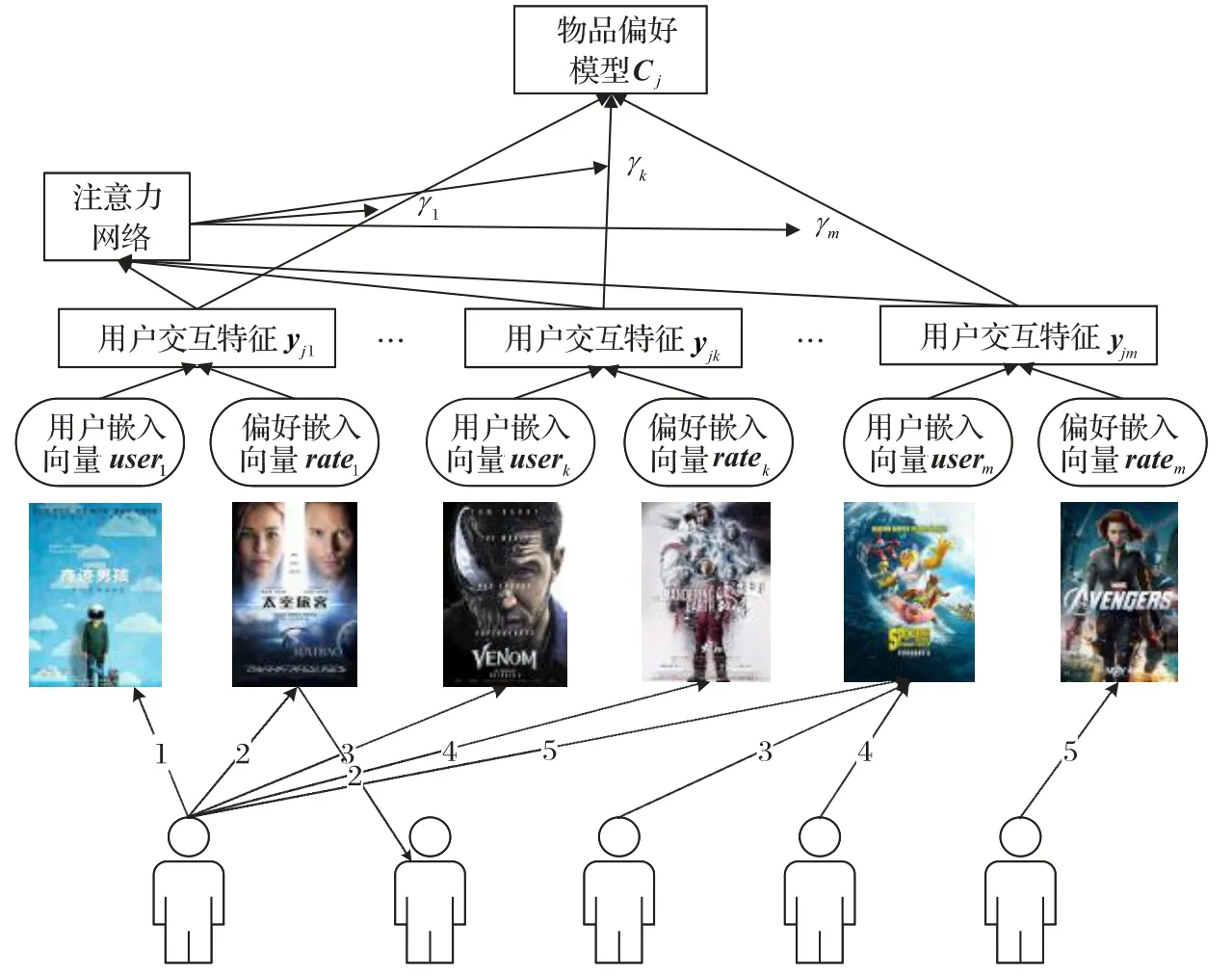
图3 物品偏好特征模型网络结构Fig.3 Network structure of item preference feature model
1.7 网络整合及训练
用户偏好模型、用户社交关系模型和物品偏好模型构成了整个复杂的图神经网络,整个网络的结构如图4 所示。其中最关键的任务就是要对网络参数进行训练,因此针对本文的评分问题,损失函数定义为:
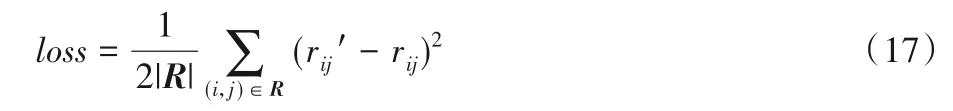
其中:|R|表示评分矩阵中存在有用户i对物品j评分的评分记录对的数量;rij表示用户i对物品j的评分值;rij′表示用户i对物品j的评分预测值。本文采用RMSProp(Root Mean Square Prop)[29]作为目标函数的优化器,该优化器会随机选择一个训练实例,并朝其负梯度的方向更新每个模型参数。该优化器可以表示为:
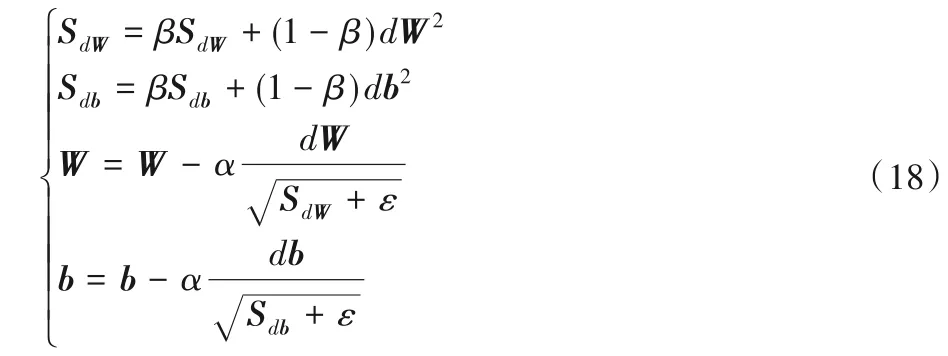
RMSProp 算法在对权重W和偏置b进行梯度更新时,采用微分平方加权平均数和作为学习率。其中:SdW和Sdb分别是损失函数在前t-1轮迭代过程中累积的梯度动量;α是动态学习率;β是梯度累积的一个指数,一般取值为0.9;ε是为了避免根号中为0而设置的极小值,一般为10-8。该方法有利于消除摆动幅度大的数据,修正摆动幅度,使各维度的摆动幅度都较小;另一方面也使得网络函数收敛更快。
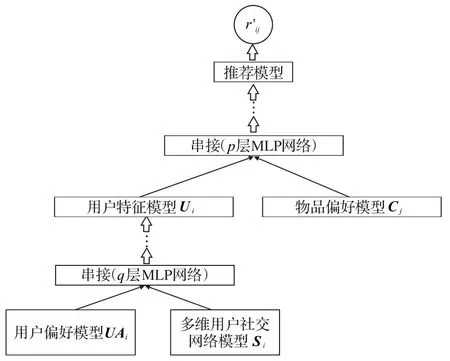
图4 整体图神经网络模型结构Fig.4 Overall graph neural network model structure
本文涉及到3 类模型的嵌入:用户偏好模型、物品偏好模型和多重用户社交模型。通过对它们进行随机初始化,在训练阶段共同学习参数。由于原始特征非常大,且特征稀疏,因此不能简单地使用一维向量来表示每个用户和每个物品,而是将高维稀疏特征嵌入到低维潜在空间中,从而更好地训练模型。其中偏好嵌入矩阵取决于评分范围,在本文的5 星评分实验背景中,偏好嵌入矩阵由5 个不同的嵌入向量组成,分别表示在1~5分上的得分特征。另外,针对过拟合问题,本模型采用了dropout 策略,在训练过程中随机丢弃一些神经元,在更新参数时仅有一部分会被更新,而在预测时不使用dropout,可以实现对整个网络的预测。
1.8 评分预测
通过用户偏好模型、用户社交关系模型和物品偏好模型,可以对一个未知的用户和物品进行评分预测或偏好预测。通过用户和物品的潜在因素,先对其进行串联,然后输入到p层MLP进行评分预测。
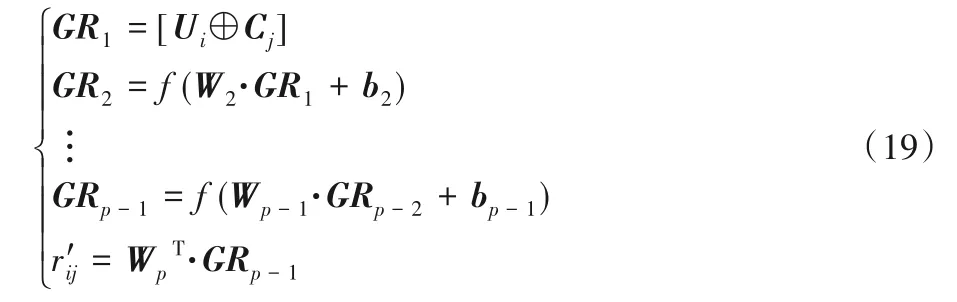
式(19)描述了图4 上半部分的网络训练过程,通过对训练集中的评分进行反向传播,最终训练得到特征矩阵U和C,使得误差最小。通过U和C快速计算出预测的评分,从而可以选择评分最高的物品进行推荐。
2 实验与结果分析
2.1 数据集
为了评估建议的方法,本文使用两个数据集进行实验,即Yelp 和豆瓣电影(Douban Movie),数据源来自于相关的研究[26]。对于每个数据集,重复的评分仅保留最新的评分。数据集的统计信息如表1所示。

表1 数据集统计Tab.1 Dataset statistics
下面简单介绍数据集中每种记录类型的主要字段,以便于理解方法和实验:
用户:〈用户ID,用户名〉。
物品:〈物品ID,物品名称,物品类别〉。
评分:〈用户ID,商品ID,评分时间,评分得分〉。豆瓣和Yelp的得分均为{1,2,3,4,5}。
朋友关系:〈用户1,用户2〉。对于豆瓣数据集,用户1 表示关注者的编号,用户2 表示关注者的编号。豆瓣数据集的朋友关系是单向的。对于Yelp 数据集,用户1 和用户2 之间的关系是等价的,因此Yelp 数据集的朋友关系是对称的社会关系。
组:〈组ID,组名称,创建时间,创建者用户ID〉。在豆瓣中,组由对某些主题具有相同兴趣的用户组成。在Yelp 中组的表示是事件,这意味着组是从特定事件派生的。例如,“谁参加”和“听起来很酷”都是一个组的成员。
组用户:〈组ID,用户ID〉。
主题:〈主题ID,主题标题,主题文本,创建时间,创建者用户ID〉。在豆瓣中,主题是指帖子、日记或讨论,可以由其他用户评论。在Yelp 中,主题是指谈话(对话),其他用户也可以评论。
主题评论:〈主题ID,评论ID,评论文本,创建时间,创建者用户ID〉。每个评论是用户对主题的回复。
在本文中,基于数据,构造一个5 维社交网络,分别为朋友关系、群组关系、评论关系、主题相似性关系和行为相似性关系,关系强度反映是否好友、群组重叠、评论倾向、文本主题语义偏好及行为时间周期趋同等程度。
对于Douban 和Yelp 而言,评分数据非常稀疏,可以通过计算评分密度,表示评分矩阵R中为非零的值的比重。
对于每个数据集,本文分别随机选择30%、50%、80%作为训练集,其余70%、50%、20%作为测试集。
2.2 评价指标
平均指标采用被广泛应用的2 个指标:均方根误差(Root Mean Square Error,RMSE)和绝对均值误差(Mean Absolute Error,MAE),计算公式如下:
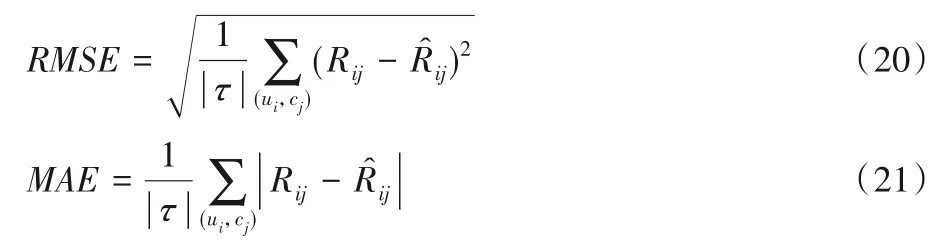
其中:τ是测试集中的评分数据集合;|τ|表示测试集中存在评分的用户物品对的数量;是根据本文方法对τ中的用户物品评分预测。RMSE和MAE越小,预测性能越好。
2.3 比较方法
为了验证本文提出的多重社交网络的深度学习方法对推荐性能的改善,本实验比较了GNNMSR 和现有主流社会化推荐方法的结果,主要比较方法包括以下几种:
1)概率矩阵分解(Probabilistic Matrix Factorization,PMF)。它是一种基本推荐方法[16],仅使用用户物品矩阵进行推荐。
2)上下文矩阵分解(Context Matrix Factorization,Context MF)方法[15]。该方法超越了传统的概率矩阵分解,在PMF 的后验分布中增加了项-用户项发送方矩阵、用户-用户偏好相似度矩阵、项-内容相似度矩阵。
3)基于社会信任集成的协同主题回归(Collaborative Topic Regression with Social Trust Ensemble,CTRSTE)[30]。该方法提出了与社会信任集合的协作主题回归,即通过外联朋友关系来改善后验分布,并在PMF 中结合了隐狄利克雷分配(Latent Dirichlet Allocation,LDA)模型。
4)社交网络正则(Social Regularization,SoReg)[31]。它定义了正则化规范来捕获社交关系,它结合了用户-物品矩阵,用户-用户相似度矩阵和外链朋友关系(友谊关系矩阵)。
5)基于信任的奇异值分解方法(Trust Singular Value Decomposition,TrustSVD)[30]。该方法结合了用户项矩阵和信任链接(信任关系矩阵)进行推荐。本文通过用户之间的友好度和相似度来计算显式信任关系,并将其添加到融合隐式参数的奇异值分解(Singular Value Decomposition++,SVD++)模型中。
6)用户评分行为分析方法(Exploring Users’Rating Behaviors,EURB)[24]。该方法捕获了三个基于用户-用户关系的SVD++模型:第一个关系是兴趣相似度;第二个关系是行为相似度,表示评分和天数的距离;第三个关系是人际评价行为的扩散。社会关系正规化术语使用三个关系的平均值。
7)符号社交网络推荐(Recommendations in Signed Social Network,RecSSN)[31]。该方法在矩阵分解框架下捕获签名社交网络的本地和全局信息。朋友圈和敌对圈在社会正规化术语中都用不同的符号表示。
2.4 参数调优分析
本实验使用Pytorch 作为开发平台,涉及到的参数有特征维度k,多社交网络融合MLP 网络的层数q1,用户总特征融合MLP 网络的层数q2,用户物品评分模型MLP 网络层数p,以及其他的网络参数。
通过实验比较了k=5,10,15,20时在GNNMSR 上的精度,选择的平均最优的10 和20 作为主要参数与其他方法进行比较。通过比较不同层数下的精度,选择q1=q2=10、p=15 作为最终的网络层数。嵌入的维度(embedding size)分别选择8、16、32、64、128、256 进行实验,选择了64 作为最终的维度。其他的参数也通过实验进行比较,batch size 取64,学习率取0.001,激活函数采用线性整流线性单元(Rectified Linear Unit,ReLU)能取得最优的效果。
2.5 比较结果
本文评估每种算法的精度的标准为MAE和RMSE。通过选择不同规模的训练集(30%,50%,80%)和不同的潜在因子维数k(k=10,20)进行了多次实验,比较结果如表2~3所示。
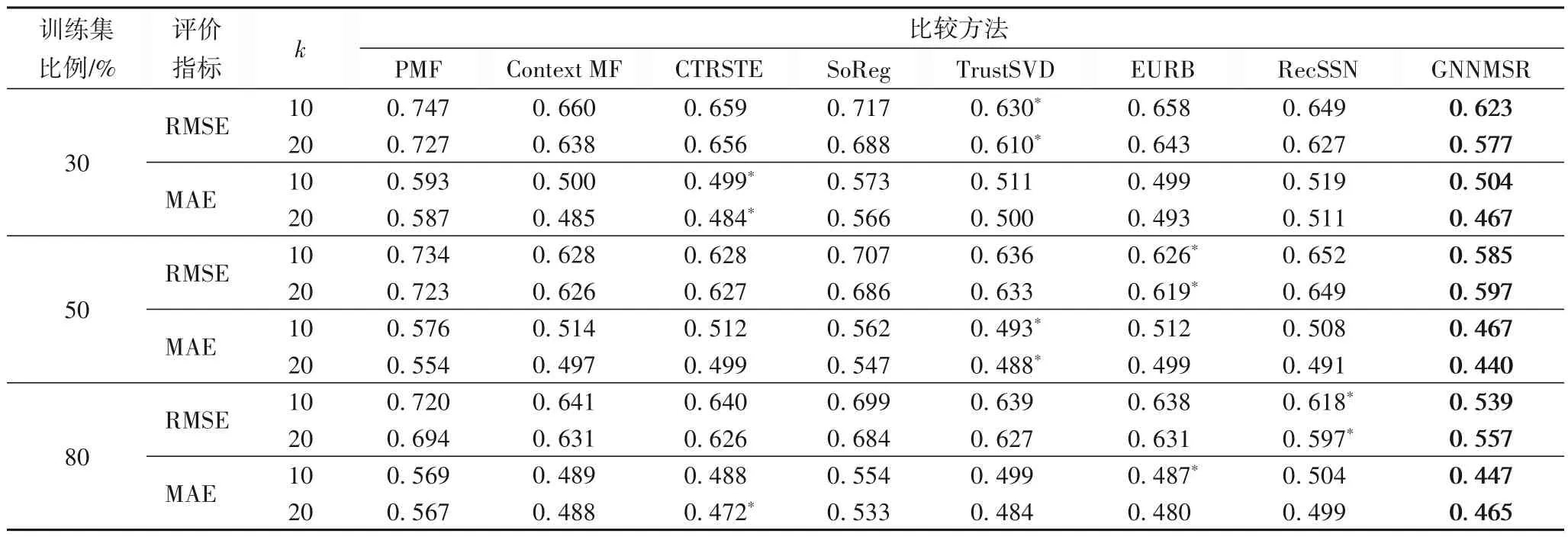
表2 豆瓣电影测试数据上的性能比较Tab.2 Performance comparison on Douban Movie test data
根据实验结果分析发现,利用社交网络信息进行推荐在RMSE 和MAE 方面改善显著。例如,与基本PMF 相比,任何一种方法都可以提高较多的准确率;并且,社会关系的应用越丰富,算法的性能往往越好。这就是为什么TrustSVD、EURB、RcSSN在大多数情况下胜过PMF、CTRSTE、SoReg的原因。
本文提出的GNNMSR 方法比其他对比方法获得更好的效果。与其他对比方法中表现最佳的结果相比,豆瓣电影和Yelp 中GNNMSR 分别平均降低了0.03 和0.1 的绝对MAE 指标值,主要原因是GNNMSR 利用社交信息的多样性来改进推荐。
Yelp 数据集的性能明显弱于豆瓣电影,这是因为Yelp 数据集中物品得分的平均方差大于豆瓣电影,这导致得分预测值的高斯分布更加平缓。因此,RMSE 和MAE 指标很大程度上取决于数据集本身。
训练集越大,预测效果越好。值得注意的是,当训练集的比例等于50%时,GNNMSR 达到了最佳性能。实验结果表明,GNNMSR 可以通过利用多个社交网络来减少对评级先验的依赖。此外,当特征维度k变大时,精度并没有明显的提升,尤其是训练样本比例较大时,部分MAE 和RMSE 指标反而在高维度k下较差,这说明特征维度并非越大越好,k=10已经能取得较好的效果。
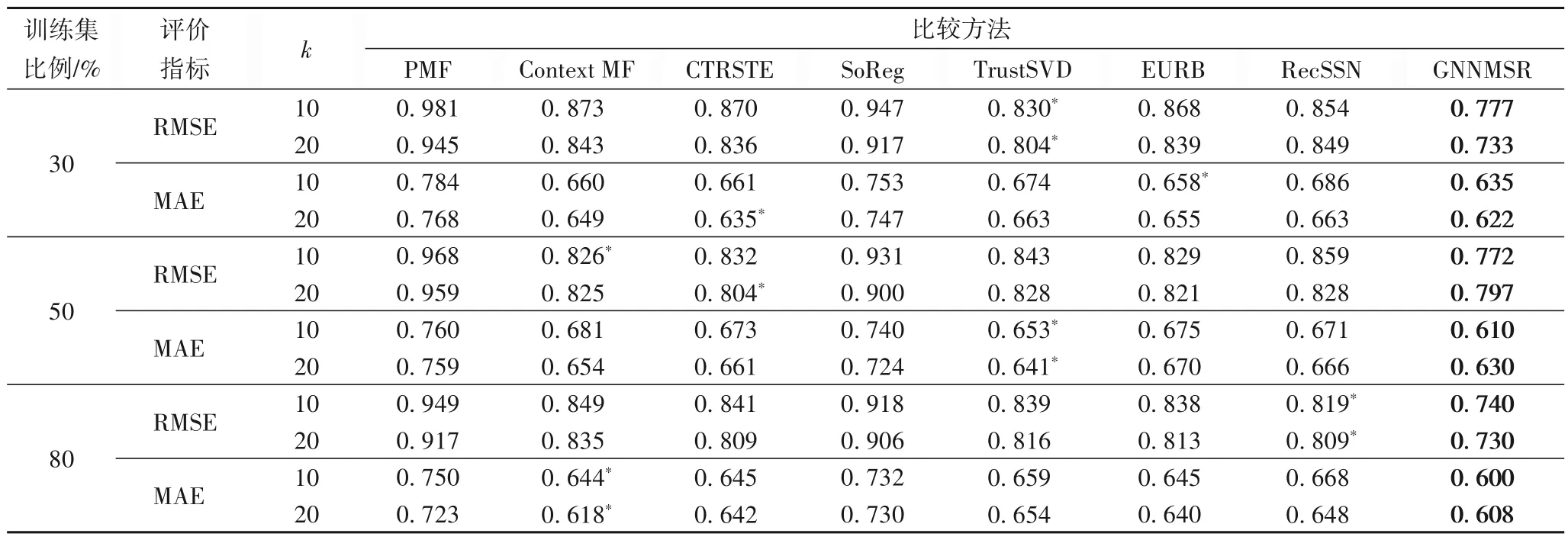
表3 Yelp测试数据上的性能比较Tab.3 Performance comparison on Yelp test data
3 结语
图神经网络(GNN)可以通过节点、边及对应的拓扑结构直接反映推荐系统中实体及其相互间的关系,计算复杂度低,适用归纳学习任务的特性,因此受到学术界和产业界的广泛关注。本文将图神经网络和多重网络进行嵌入,能充分利用历史评价数据和用户之间的多重关联信息,有效地提升了推荐效果,说明了多重社交网络对推荐精度的叠加效应。然而,本文主要还是针对静态数据的推荐,而实际上用户关系、用户评分数据都是在实时变化的,所对应的特征矩阵U和C也应随之变化,如何通过图神经网络进行动态社会化推荐将是下一步研究的重点。
