基于自适应学习率优化的AdaNet改进
2020-10-18顾进广
刘 然,刘 宇*,顾进广
(1.武汉科技大学计算机科学与技术学院,武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉 430065;3.武汉科技大学大数据科学与工程研究院,武汉 430065;4.国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室(武汉科技大学),北京 100038)
(*通信作者电子邮箱liuyu@wust.edu.cn)
0 引言
人工神经网络的自适应结构学习(Adaptive structural learning of artificial neural Networks,AdaNet)是一种基于集成学习的神经结构搜索(Neural Architecture Search,NAS)框架,它不仅可以学习神经网络架构,还可以将最优的架构组合成一个高质量的集成模型。AdaNet 借鉴了Boosting 集成学习中提出的估计泛化误差上界的公式“泛化误差项<经验误差项+学习算法容量相关项”,并且在NAS 领域对“学习算法容量相关项”给出了具体的定义[1],这样AdaNet在训练的过程中就能够评估所得模型的泛化误差。
AdaNet是以神经网络作为个体学习器,也就是AdaNet子网,多个子网通过混合权重进行集成,最后得到AdaNet 都会评估AdaNet 集成体泛化误差上界,找到使得泛化误差最大限度减小的子网,并将其添加到AdaNet 集成体中,再根据所添加的这个子网来调整搜索空间。
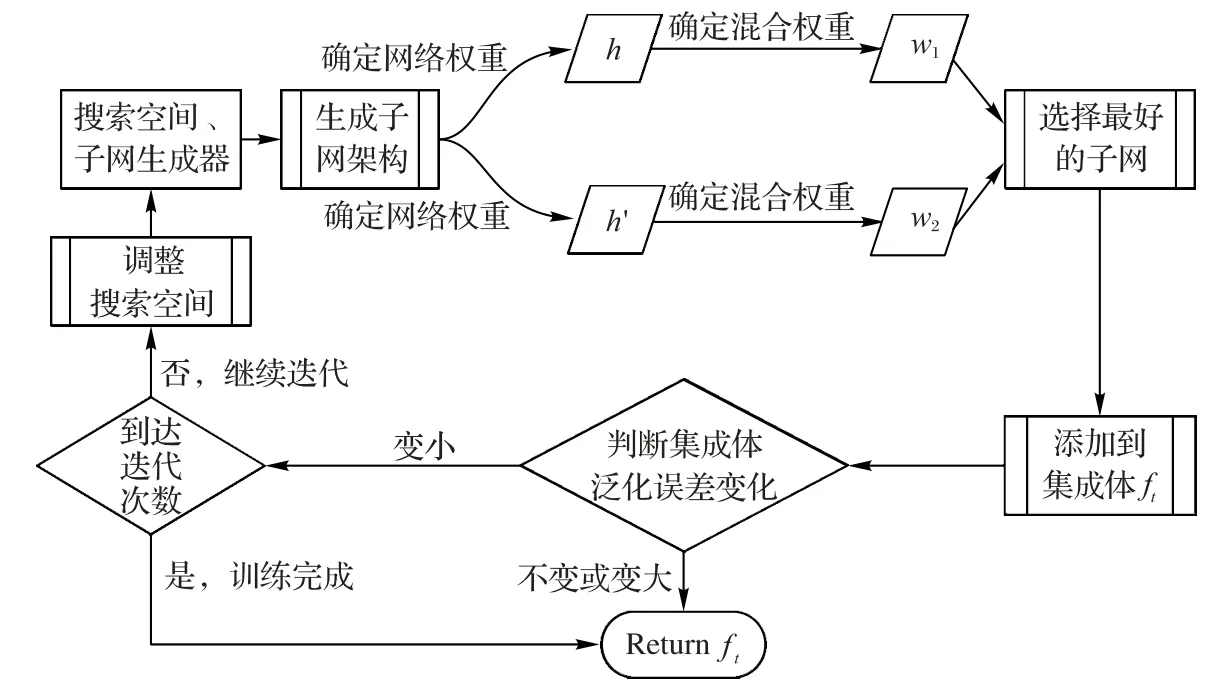
图1 AdaNet子网搜索过程Fig.1 AdaNet subnet search process
AdaNet 为了找到每轮迭代性能最好的子网,会使用Momentum 优化算法来得到子网的网络权重和子网集成时的混合权重。Momentum 优化算法是在随机梯度下降(Stochastic Gradient Descent,SGD)优化算法中引入了动量相关概念,并且在整个寻优过程中学习率是固定的。这类优化算法在损失函数为凸函数时,能够保证收敛到全局最优值,缺点是收敛的时间较长。同时,受初始学习率的影响很大,每个维度的学习率一样。因此,AdaNet 通过Momentum 优化算法得到的子网,虽然能够保证具有较好的性能,但是子网之间差异性并不大。
由于AdaNet 是基于集成学习的,而集成学习的关键是产生“好而不同”的子网,即子网之间需存在差异性,并在一定误差率限定下对子网进行集成。AdaNet 集成体的泛化误差,可通过的误差分歧分解式子[2]来进行表示:

其中:E表示AdaNet 集成体的泛化误差;表示所有子网泛化误差的均值;表示子网的加分分歧项,即所有子网的差异性度量最后取平均。该式子表明越小,并且越大,集成的效果越好。但是仅仅在集成体构造好后才能进行估计,所以不能够直接最小化。
现有的AdaNet 处理过程中,每次均从候选子网中选择了最好的子网,其实在训练的过程中已经对进行了限制,因此为了进一步提高AdaNet 集成体的效果,应从提升子网的差异性入手,也就是从增大入手。而AdaNet 使用Momentum 优化算法得到的集成模型,往往为了追求较小的,而导致较小,难以减小AdaNet集成体的泛化误差。
在另一方面,神经网络中存在着大量非线性变换,它的损失函数几乎都是非凸和高维度的,不可避免存在大量的局部最小值。在实际情况中,往往存在大量梯度为0 的点,导致无论用什么优化算法都很难找到唯一全局最小值。Li等[3]通过实验说明了神经网络的训练依赖于寻找高维度非凸损失函数的“较好”极小值能力,这些“较好的”局部极小值表现可能和全局最小值相差无几。同时,根据Kearns 等[4]提出的集成学习中“弱学习器等价于强学习器”理论,以及Schapire[5]对这一理论给出的构造性证明,Boosting类算法的个体学习器并不要求强学习器。
本文在多组实验中比较了不同的优化算法,实验结果表明,在AdaNet 中使用RMSProp、Adam、RAdam 这类自适应学习率算法来训练子网以及优化混合权重时,不仅因为自适应学习率,不容易跳出极值点,使得收敛变快,同时由于增大了子网差异性,最后得到AdaNet集成体的性能更佳。
1 相关工作
NAS 是自动机器学习(Automated Machine Learning,AutoML)领域热点之一,它可以针对特定的数据集从头开始设计性能良好的模型,在某些任务上甚至可以达到人类专家的设计水准,甚至有可能发现某些人类之前未曾提出的网络结构,所以国内外都对NAS进行了深入研究。
Zoph 等[7]将NAS 问题转化成了序列生成问题,并且将循环神经网络(Recurrent Neural Network,RNN)作为控制器来对序列进行求解,之后使用强化学习算法近端策略优化(Proximal Policy Optimization,PPO)学习控制器的参数。这种方法每一层的参数都是独立的,需要学习整个网络,参数搜索空间非常大,最终论文的实验动用了800 个GPU。之后,Zoph等[8]又根据经典卷积神经网络(Convolutional Neural Network,CNN)每层的网络结构都具有一定相似性,提出自动搜索的网络结构也可以是基于层的,可以针对某一层来设计一种特定的结构,然后将这种结构重复多次,来得到一个完整的网络结构,实验使用了500 个GPU 并行处理。后续研究中,Liu 等[9]根据启发式搜索,只训练有可能得到最优结果的网络结构,这样降低了需要完整训练的网络结构数量,但是搜索空间还是很大。
但是上述几种方法都有着巨大的搜索空间,导致整个搜索过程计算量非常大,必须要有大量的GPU 支撑。AdaNet 是一种基于强化学习和集成学习的方法,优势在于子网基本架构是可以自定义的,后面产生的子网都是在这个基本架构上演化来的,因此需要完整训练的子网个数并不多。AdaNet 通过简单的人工干预,就大幅度减小了NAS 搜索空间。同时AdaNet 在搜索过程中估计泛化误差上界的机制,也导致了AdaNet中验证子网泛化误差的环节并不复杂。
优化算法在深度学习领域的应用很广泛,最早出现的优化算法是随机梯度下降(Stochastic Gradient Descent,SGD)。也就是随机抽取一批样本,并且以此为根据来更新参数。SGD 优化算法的优点是容易得到全局最优解,但是缺点也很明显:一是受初始学习率的影响很大,存在不收敛的可能;二是每个维度的学习率一样,很难学习到稀疏数据上的有用信息;三是学习曲线有时会产生剧烈震荡。
对于SGD 优化算法中的学习曲线震荡和鞍点停滞问题,Momentum 优化算法[10]可以比较好地缓解这个问题。与SGD优化算法相比,Momentum 优化算法收敛更快,收敛曲线也更加稳定,但是Momentum 优化算法还是存在每个维度学习率一样的问题。
在实际应用中,更新频率低的参数应该拥有较大的学习率,而更新频率高的参数应该拥有较小的学习率。Adagrad优化算法[11]采用“历史梯度累计平方和的平方根”(常用r表示)来衡量不同参数梯度的稀疏性,并且将r作为学习率的分母,某参数的r越小,则表明该参数越稀疏,该参数的学习率也就越大。
RMSProp优化算法[12]将Adagrad优化算法中的“历史梯度累计平方和的平方根”改为了“历史梯度平均平方和的平方根”,避免了分母随着时间单调递增,解决了训练提前结束的问题。RMSProp 优化算法虽然解决了训练过早结束的问题,但是同样容易陷入到局部最优解。
Adam 优化算法[13]集成了Momentum 优化算法训练比较稳定的优点,以及RMSProp 优化算法学习率随着迭代次数发生变化的优点,可以认为是带有动量项的RMSProp。Adam 算法通过记录梯度一阶矩,保证了梯度之间不会相差太大,即梯度平滑、稳定地过渡,这样可以适应不稳定的目标函数。同时通过记录梯度二阶矩,保证了环境感知能力,为不同参数产生自适应的学习率。Adam 优化算法可以实现快速收敛,但是它对初始学习率不够鲁棒,也会存在收敛到局部最优解的问题。并且Adam 优化算法在最初几次迭代,常常需要用很小的学习率,也就是“预热”,否则可能会陷入糟糕的开始,使得训练曲线出现过度跳跃,变得更长、更困难。
近期,最优化算法领域也有许多新的研究成果,来自UIUC(University of Illinois at Urbana-Champaign)的Liu 等[14]提出了一个新的优化算法RAdam,它在保证收敛较快的前提下,建立了一个“整流器(rectifier)项”来进行自动预热,在大部分预热长度和学习率的情况下都优于手动预热。RAdam提供了更好的训练稳定性,省去了手动预热的过程,在大部分人工智能(Artificial Intelligence,AI)领域都有较好的通用性。
2 AdaNet算法
2.1 AdaNet集成体
AdaNet 的首要对象是集成体,每次搜索得到的子网,都会作为集成体的一部分。集成体由一个或多个子网组成,这些子网的输出通过集成器进行组合。
AdaNet中的集成模型e可以表示为:

其中:集成模型e是所有子模型的加权和;l是集成体中的子网个数;wk代表第k个子网的混合权重;hk代表第k个子网。
2.2 AdaNet目标函数和子网搜索过程
AdaNet 在搜索与训练的过程中,需要有一个指标来评价整个集成模型的好坏,通过最小化这个指标,来寻找子网进行集成时的最优混合权重。AdaNet 使用如下目标函数作为指标:
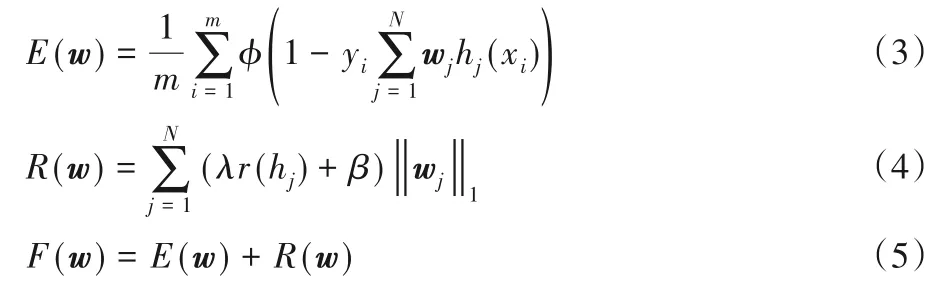
其中:λ≥0,β≥0,均为常数;m是训练集的样本个数;N是集成体中子网的个数;hj是序号为j的子网;wj是序号为j的子网的混合权重;φ是子网训练时所用的损失函数(在AdaNet中常常使用指数损失函数,即φ(x)=ex);r(hj)是序号为j的子网的Rademacher复杂度。
F(w)借鉴了Boosting 算法中估计泛化误差的方式,它是E(w)和R(w)两者的和,E(w)为AdaNet 集成体的训练误差项,R(w)为AdaNet集成体的复杂度惩罚项,F(w)则是AdaNet集成体泛化误差上界的估计。上述标准可用于判定候选子网能否添加至AdaNet 集成体中:当尝试添加某个候选子网后,训练误差项的减小幅度大于复杂度惩罚项的增大幅度,即F(w)减小时,该候选子网会被正式添加到AdaNet集成体。
假设在t-1 轮迭代之后得到的AdaNet 模型为et-1,当前混合权重向量为wt-1,集成模型的深度为lt-1。对于第t轮迭代,子网生成器会得到两个子网h、h′,其中h是深度为lt-1的子网,h′是深度为lt-1+1 的子网,子网的具体形式由自定义的子网搜索空间指定。
此时,将第t轮迭代的子网添加到集成体的问题,可以转化为在候选子网u∈{h,h′},并且候选子网u的混合权重w∈R 的条件下,最小化第t-1 轮迭代的目标函数Ft(w,u)的问题,Ft(w,u)的具体公式如下:
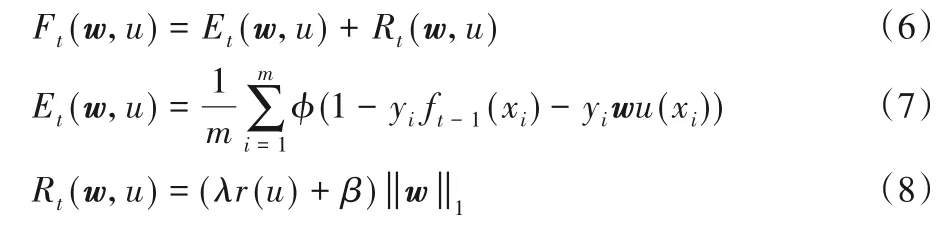
而在使用Ft(w,u)之前,需要先对子网进行局部的训练,即得到子网u内部的网络权重wu,这样的子网u才可以添加到集成体中,此时需要最小化子网u的目标函数Ft(w,u),具体公式如下:
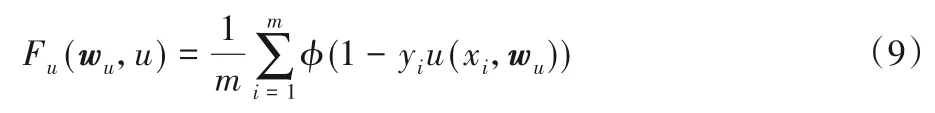
F(w)用来比较前后两次迭代的集成体性能,判断集成体是否需要添加当前子网。Ft(w,u)用来代入优化算法中,最小化Ft(w,u)的过程就是确定当前子网混合权重w的过程。Fu(wu,u)用来对子网进行局部的训练,最小化Fu(wu,u)的过程就是确定当前子网内部网络权重wu的过程(最小化Ft(w,u)和Fu(wu,u)之前需要先确定u为某个固定的候选子网h或h′)。根据式(5)、(6)、(9),AdaNet 子网搜索流程可以具体表述为:

第1)行:初始化AdaNet 集成体子网搜索空间、子网生成器,子网搜索空间定义了生成子网的基本类型,子网生成器用来生成具体的子网,并且对子网进行训练(本文主要讨论子网为基本CNN架构的情况)。
第3)行:子网生成器生成两个候选子网h、h′的网络架构,将u=h、u=h′分别代入到Fu(wu,u)中,之后用优化算法来得到h、h′内部的网络权重,用MINIMIZE()来指代某种优化算法,每种优化算法的具体步骤将在后文介绍。
第4)~5)行:将u=h、u=h′分别代入到Ft(w,u)中,并且用优化算法MINIMIZE()得到h、h′的最佳混合权重w1、w2。
第6)~9)行:比较Ft(w1,h)、Ft(w2,h′),h、h′中使得Ft(w,u)更小的子网表示为ht,对应的混合权重称为w*。
第10)~14)行:比较F(wt-1+w*)、F(wt-1),如果F(wt-1+w*)<F(wt-1),则认为引入子网ht后集成模型训练误差的减小程度要优于复杂度的增大程度,也就是说引入子网ht能够减小集成体的泛化误差上界。此时上一次迭代的集成体et-1应该包含这个子网ht,剥离子网ht的softmax 层以暴露最后一个隐藏层,然后通过混合权重w*将ht最后一个隐藏层连接到集成体的输出,得到新的集成体et,并且根据当前迭代获得的反馈信息调整子网搜索空间。如果F(wt-1+w*)≥F(wt-1),则认为继续引入子网对于减小集成体的泛化误差上界没有帮助,此时直接返回上一次迭代的集成体et-1。
第15)行:完整进行T轮迭代后得到集成体eT,最后返回它。
2.3 AdaNet的权重优化算法
AdaNet 子网搜索流程中第3)行的使用优化算法最小化Fu(wu,u)得到子网内部的网络权重wu,以及第4)~5)行的使用优化算法最小化Ft(w,u)得到子网集成时的混合权重w,在AdaNet 中都是使用同一种优化算法来求解的。在AdaNet 中为了得到全局最优的子网,常常都会使用Momentum 优化算法来对上述两步进行求解,也就是在u设置为定值的情况下,分别将Fu(wu,u)、Ft(w,u)作为Momentum 优化算法目标函数ft(w),分别对wu、w进行寻优,Momentum 优化算法的具体流程如下。

但是Momentum 优化算法收敛较慢,导致AdaNet 的整个子网搜索过程较慢;同时使用Momentum 优化算法时,由于在整个训练过程中学习率都是固定的,所以每个维度的学习率都是一样的,难以学习到稀疏数据上的有用信息;并且Momentum 优化算法得到的AdaNet 集成体中子网的差异性较小,这样不利于AdaNet集成体泛化误差的减小。
3 自适应学习率的优化算法
本文为了增大不同子网内部的网络权重之间的差异性,改用自适应学习率的优化算法来对上述两步进行求解,具体使用了Adagrad、RMSProp、Adam、RAdam 这4 种优化算法,下面给出了它们的完整流程。
3.1 Adagrad优化算法
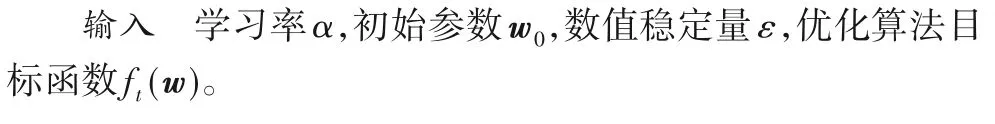

3.2 RMSProp优化算法

3.3 Adam优化算法

3.4 RAdam优化算法


4 实验与评估
本文使用了上述几种方法,在AdaNet 的子网搜索空间设置为基本CNN 的前提下,优化子网内部的网络权重和子网集成时的混合权重,并且在标准测评数据集上测试了上述方法建立AdaNet 集成模型的性能,以说明使用RMSProp、Adam、RAdam 这类优化算法时,相较于AdaNet 常用的Momentum 优化算法,AdaNet 的整个训练过程不仅能够快速收敛,并且得到的AdaNet集成模型效果也更好。
4.1 数据集
MNIST是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60 000 个训练集样本以及10 000 个测试集样本,样本是28×28的图片,共有10个类别。这个数据集较为简单,AdaNet 原始CNN 模型就能获得较好效果,对于这个数据集的分类,目的是为了检验本文观点,即能否让AdaNet集成体学习到一些比较难学到的内容。
Fashion-MNIST 是一个替代MNIST 手写数字集的图像数据集。Fashion-MNIST 的格式、大小和训练集/测试集划分与MNIST 完全一致,主要是增加了分类的难度。对这个数据集的分类更加具有挑战,目的是为了检验本文观点在更复杂的分类问题上是否同样有效。
为了检验通过本文方法所得到的AdaNet 集成体,能否保持集成学习类算法能避免噪声的特性。本文又在添加了高斯噪声后的Fashion-MNIST 上进行了对比实验,具体添加方法为:源数据在分批训练时,随机选取20 批次的数据,为这些数据中的所有图像都引入高斯噪声。
4.2 输入参数设置
对于不同的优化算法,需要给定对应的输入参数。首先是全部优化算法共有的两个输入参数,即初始参数w0和学习率α。初始参数w0决定了在梯度下降过程中出现梯度消失或者梯度爆炸的可能性大小,本文使用He initialization[15]这种初始化方法来给定,这种方法不仅尽可能保持输入和输出服从相同分布,避免出现激活函数输出值趋向于0 的情况,而且它还能很好适应ReLU(Rectified Linear Unit)这种非线性激活函数。学习率α决定了权重更新比率,它需要根据训练集的大小来选择,一般训练集数据量越大,α就应该设在更小的值上[16]。如果α设得太小,训练速度会很慢,但可能将目标函数值降到最低,如果α设得太大,训练速度会很快,但可能会导致学习震荡,甚至可能无法收敛[17]。本文尝试了α为1、0.5、0.1、0.05、0.01、0.005、0.001、0.000 5 这些情况,经过前期测试,当α为0.005时,既能够保证训练速度,又能够得到一个很低的目标函数值。同时,由于Momentum 优化算法在整个寻优过程中都使用唯一的α,如果α选择不当可能出现非常差的情况。而Adagrad 等自适应学习率优化算法每次迭代都对α进行不同程度的缩放,前期距离寻优目标远,对α进行放大,能够更有效率地进行探索,后期距离寻优目标近,对α进行缩小,保证能够收敛到一个较好的结果,所以Adagrad 等自适应学习率优化算法对α的要求比Momentum 优化算法更低。由于本文3 组对比实验的训练集数据量大致相同,所以本文所有实验都基于相同的w0和α来进行。
然后是每个优化算法特有的输入参数,本文根据Ruder[18]以及仝卫国等[19]的研究进行相关设置。对于Momentum 优化算法,动量衰减参数γ取0.9,它类似物理中的摩擦系数,用来抑制动量,在接近寻优目标后能快速收敛。对于Adagrad优化算法,数值稳定量ε取10-8,ε用一个极小的正数,防止计算过程出现除以0,其他3 种自适应学习率优化算法RMSProp、Adam、RAdam中的ε也取相同值。对于RMSProp优化算法,衰减速率ρ取0.9,它用来实现只累积近期梯度信息,用平均平方梯度替换累计平方梯度,避免梯度累计量过大。对于Adam 优化算法和RAdam 优化算法,梯度一阶矩衰减系数β1取0.9,梯度二阶矩衰减系数β2取0.999,梯度一阶矩是历史梯度与当前梯度的平均,它借鉴于Momentum 用来保持惯性,实现梯度平滑、稳定的过渡,梯度二阶矩是历史梯度平方与当前梯度平方的平均,它借鉴于RMSProp 用来环境感知,保留能为不同维度参数自适应地缩放学习率的优点。
4.3 评价标准
在对比实验中,本文采用在测试集上的正确率(precision)、召回率(recall)、F1 值(F1_score)作为集成模型性能的评价指标,定义如下:

而对于子网之间的差异性,由于AdaNet 中各个子网架构都是相同的,主要差别在于子网内部的网络权重。本文先计算了每个子网网络权重均值,并将两子网网络权重均值之差取平方作为它们之间的“差异性距离”,之后让AdaNet 集成体中所有子网两两组合,对所有组合结果的“差异性距离”求和,最后对这个和取均值作为子网分歧项。具体定义如下:
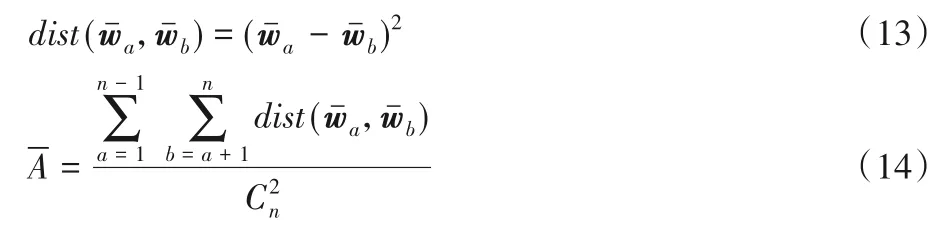
同时为了比较AdaNet 在使用不同优化算法时的网络架构搜索速度,本文对所有实验的训练过程所用时间进行了统计(本文在8 块NVIDIA Tesla V100-SXM2-16GB 的GPU 分布式计算环境中进行实验,并且用TensorBoard 对整个训练过程进行了监控)。
4.4 实验分析
表1 展示了5 种优化算法在MNIST 数据集上的结果,可以看到F1 值最高的是RAdam,同时它有着最大的子网分歧项。在这个较简单数据集上RMSProp、Adam、RAdam 这3 种优化算法效果普遍更好,即它们能让AdaNet 集成体学习到一部分难以学到的内容。
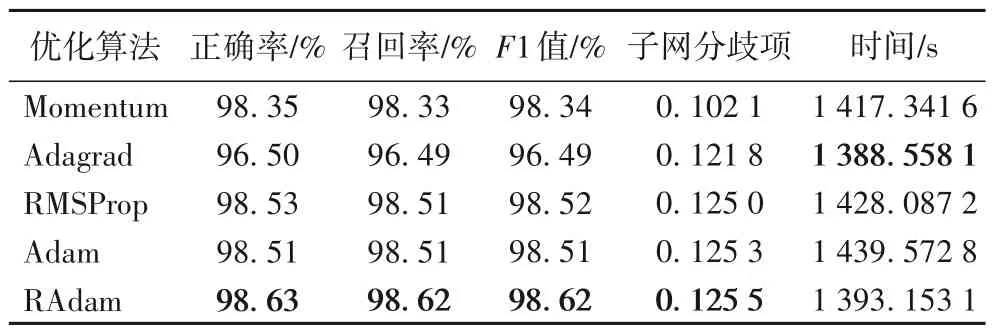
表1 在MNIST数据集上不同优化算法的结果Tab.1 Results of different optimization algorithms on MNIST dataset
表2 则展示了在Fashion-MNIST 数据集上的结果,可以看到F1值最高的是RAdam,它同样有着最大的子网分歧项。在Fashion-MNIST 数据集上RMSProp、Adam、RAdam 这3 种优化算法也得到了更好的效果,即它们在使用AdaNet 处理更复杂的分类任务时也是有帮助的。
表3 则展示了在添加高斯噪声的Fashion-MNIST 数据集上的结果,F1值最高的都是Adam,它同样有着最大的子网分歧项。可以看到RMSProp、Adam、RAdam 在数据集中添加了噪声后,损失函数均值和F1 值的影响比较小,即它们能够帮助AdaNet集成体在一定程度上避免噪声。
3 组对比实验所用数据集的复杂程度是依次递增的,它们对应的损失函数曲面复杂程度也是依次递增的。可以看到损失函数曲面越复杂,“较好的”局部极小值点越多,不同优化算法得到的子网分歧项差别越大,即对于复杂问题,本文的改进方法可以获得更好的效果。
在收敛方面,本文的3 组实验都是Adagrad 优化算法收敛最快,但是Adagrad优化算法所得到结果的F1值普遍不高,这是因为Adagrad 流程中式子的分母随着时间单调递增。当分母积累值过大后,收敛变得很小,导致训练后期变化幅度很小。对于SGD 和Momentum,随机的特性导致了其收敛本身就不快,它们所得F1 值也不高。对于RMSProp、Adam、RAdam 则可以在保证较快收敛的前提下,同时得到较高的F1值。
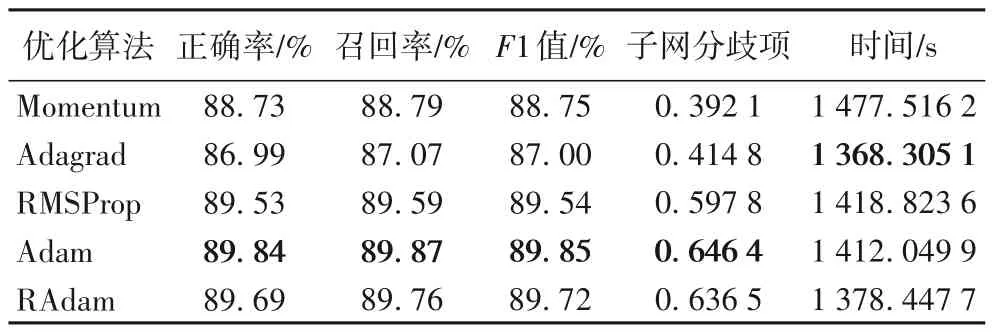
表3 在添加了高斯噪声的Fashion-MNIST数据集上不同优化算法的结果Tab.3 Results of different optimization algorithms on Fashion-MNIST dataset with Gaussian noise
5 结语
本文基于AdaNet 这种NAS 方法,引入RMSProp、Adam、RAdam 等自适应学习率优化算法来得到子网内部的网络权重和子网集成时的混合权重。实验结果表明,相对于现有的Momentum 优化算法,本文方法在保证收敛较快,也就是网络搜索效率较高的前提下,还能够通过提高子网之间的差异性,使得AdaNet 集成模型拥有更高的准确率,在越复杂的分类任务中优化效果越明显。
本文的方法在AdaNet子网为简单CNN 架构时效果较好,在未来的工作中,将探讨AdaNet子网为各种复杂CNN 架构以及RNN架构时,如何将它们组合为更好的AdaNet集成模型。
