基于联合优化的强耦合孪生区域推荐网络的目标跟踪算法
2020-10-18石国强
石国强,赵 霞
(同济大学电子与信息工程学院,上海 201804)
(*通信作者电子邮箱xiazhao@tongji.edu.cn)
0 引言
目标跟踪是计算机视觉领域中一个非常重要且具有挑战性的研究课题,被广泛应用于自动驾驶、人机交互等领域[1]。尽管目标跟踪技术已经发展了几十年,由于被跟踪目标在运动过程中会出现形变、遮挡、快速移动、光照变化等情况,精准定位目标仍存在很大挑战。
相关学者将机器学习中的分类学习思想应用到跟踪领域,极大地促进了目标跟踪算法的发展。分类学习方法将目标跟踪任务看作一个区分前景和背景的二分类问题,通过在线或离线训练分类器,寻找分类值最大的区域,从而实现目标的跟踪。因此,设计一个高精度且速度快的分类器,有助于提升跟踪算法的鲁棒性以及实时性。在信号处理领域中,相关性用来描述两个信号之间的联系。Bolme 等[2]首次将相关操作用于跟踪任务,提出相关滤波器跟踪算法,并用快速傅里叶变换(Fast Fourier Transform,FFT)在频域内完成多个信号的相关操作,大幅提升了算法的计算效率。由于相关滤波器具有高效的计算性能,近年来许多研究者将其用于目标跟踪[3-5]。基于相关滤波器的算法属于分类学习方法,核心是训练一个滤波模板,即分类器,用于将目标从背景信息中分离出来。但基于相关滤波器的算法也存在不足,如在遇到目标发生较大形变或背景与目标高度相似等情况下不能很好地定位目标。此外,该算法需要频繁更新滤波模板,导致跟踪算法的速度变慢。
深度卷积神经网络的优秀特征提取能力,以及近几年硬件性能不断提升和可用于训练的标记数据逐渐增多,使得该类网络大量应用于计算机视觉处理任务中[6-8]。部分学者使用深度卷积特征替换传统手工特征,极大提高了基于相关滤波跟踪器的跟踪精度。但也存在不足,因为深度卷积特征的使用会进一步降低算法的运行效率。算法运行效率降低的原因有两方面:一是相较于传统手工特征,深度卷积特征的提取过程更加耗时;二是网络模型采用预训练模型参数,在线跟踪目标时,需要针对跟踪目标在线更新模型系数,造成跟踪速度慢这一问题。
由于孪生网络具有共享权值的特征,因此特别适用于处理输入“比较类似”的情况,这和目标跟踪的机制相吻合。通过离线训练的孪生网络模型便可进行很好的特征提取,因而无需在线更新模型参数,有效提升跟踪速度。目前,基于孪生网络的深度卷积神经网络被广泛应用于目标跟踪任务中。SINT(Siamese INstance search for Tracking)[9]最先使用孪生网络作为跟踪算法的主体框架,将跟踪问题转化为一个图像块匹配问题。该算法根据高斯分布采集多个不同大小及形状的图像块,并与目标模板图像块进行匹配,选择最佳匹配图像块作为跟踪结果。SiamFC(Fully-Convolutional Siamese networks for object tracking)[10]使用全卷积网络作为特征提取部分,将跟踪问题看成一个相似性学习问题,利用全卷积特征平移不变性来避免图像特征重复提取,提高了算法的运行效率。在线跟踪时,该算法直接对目标中心位置进行定位,目标形状大小由初始帧图像块形状和当前最大响应图像块尺度进行线性估计。基于孪生区域推荐候选网络的高性能单目标跟踪(SiamRPN)算法[11]将跟踪问题看成一个全局单步检测问题,在SiamFC 基础上,使用SSD(Single Shot multibox Detector)[12]中区域推荐网络(Region Proposal Network,RPN),根据得到的孪生网络特征,不需要进行尺度估计,直接预测目标中心位置及尺度。虽然SiamRPN 具有很好的跟踪能力,但其分类任务和边框回归任务没有联系,导致模型预测的最高分类分数与最佳预测边框结果不匹配,仅得到次优跟踪结果。
针对上述问题,本文在SiamRPN 算法基础上,提出一种基于联合优化的强耦合孪生区域推荐跟踪算法——SCSiamRPN(object tracking algorithm based on Strong-Coupled Siamese Region Proposal Network)。首先提出联合分类任务和边框回归任务的优化策略,设计了以交并比(Intersection-over-Union,IoU)为纽带的联合优化分类损失函数。该分类损失函数针对预测精度高的正样本,即IoU 高的正样本,提升其对总分类损失的贡献;针对低IoU 的正样本,降低其对总分类损失的贡献,使得最高分类分数与最佳预测边框结果相匹配。其次,将IoU 作为边框损失函数的权重,提升目标中心样本的比重,抑制边缘样本的比重,从而提高边框回归子网络的定位精度。最后,由于边框回归网络输出的是正则化值,在计算IoU 值时,传统方法需进行数值转换,过程繁琐,且计算量大。针对这一问题,本文采用改进的BoundedIoU 方法[13]进行计算,这种方法仅估计IoU 的上界,并直接采用正则化值作为输入,可以在不损失计算精度的同时,大大简化计算过程。
在OTB50[14]、OTB100[15]和VOT2016[16]等测试数据集上,本文算法SCSiamRPN 均取得了满意的实验结果。相较于SiamRPN 算法,本文算法在OTB 系列测试集上的距离精度(Distance Precision,DP)和成功率曲线图面积(Area Under the Curve,AUC)均有3%的提升,在VOT 等测试集上的DP 和AUC 提升了3%~7%;而且,本文算法的最高分类分数均与最佳边框相匹配。以上实验结果表明:以IoU 为纽带的联合优化方法有效提升了分类任务与边框回归任务间的耦合性,进而提高了目标跟踪任务的性能。
1 基于孪生网络的跟踪器
孪生网络是指具有两个共享权值分支网络的神经网络,基于孪生网络的跟踪算法使用两个共享权值分支网络分别提取目标和搜索图像的特征。该类算法一般分为离线训练和在线跟踪两个阶段。离线训练阶段利用带标签的视频数据集作为训练样本,采用梯度下降策略优化算法模型,通过训练学习得到通用的特征提取深度卷积网络模型。在线跟踪阶段,首先初始化孪生网络的一个分支,将被跟踪目标图像块作为其输入;然后逐帧提取搜索图像块作为孪生网路另一分支的输入,对两分支的输出特征进行相关操作,通过寻找相似性最大的匹配图像块完成对目标的跟踪。
本章首先介绍经典的基于孪生网络的目标跟踪算法SiamFC,用来预测目标的中心位置;其次介绍经典的采用RPN 的目标跟踪算法SiamRPN,该算法通过区域推荐网络预测目标的中心位置及大小。
1.1 SiamFC算法
SiamFC 算法的整体框架如图1 所示,图中孪生网络虚线框中上方支路表示目标分支,输入为z,下方支路表示搜索分支,输入为x,两条支路采用共享权值的全卷积网络AlexNet[17]作为特征提取网络(图1中“φ”)。
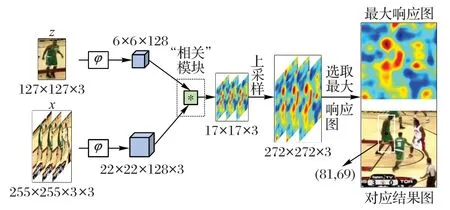
图1 SiamFC框架Fig.1 Architecture of SiamFC
由于全卷积网络对输入图像块没有大小要求,该算法采用127×127的图像块作为目标图像输入、255×255的图像块为搜索图像输入。将两条分支网络的输出“6×6×128 目标图像特征和22×22×128 搜索图像特征”用相关操作处理(图中“*”),由于相关操作要求两图像大小相同,这里通过288 次平移,得到17×17 的相似性置信分数图。最后,通过二次差值法进行上采样,提升置信分数图的分辨率,得到大小为272×272的响应图,响应图中最大值的位置即为当前帧目标的中心位置。
在跟踪过程中,模型的输入为3 个不同大小的搜索图片(图1 中“x”处),根据响应值最大的输入图片确定当前目标的大小。
1.2 SiamRPN算法
从图1可以看出,SiamFC算法假设当前帧目标尺度不变,直接预测目标中心位置,当目标尺度有较大改变时,性能欠佳。SiamRPN 算法框架如图2 所示,该算法采用区域推荐网络(图2(b)部分)代替SiamFC 位置预测网络中的相关操作(图1 中“相关”模块),同时预测出目标的中心位置和尺度大小,相较于SiamFC,SiamRPN 的定位结果更准确。该算法同样也用孪生网络提取目标图像和搜索图像的特征,对提取的特征用k个不同尺度的预选框,通过区域推荐网络对预选框进行分类与回归,最终定位出目标。
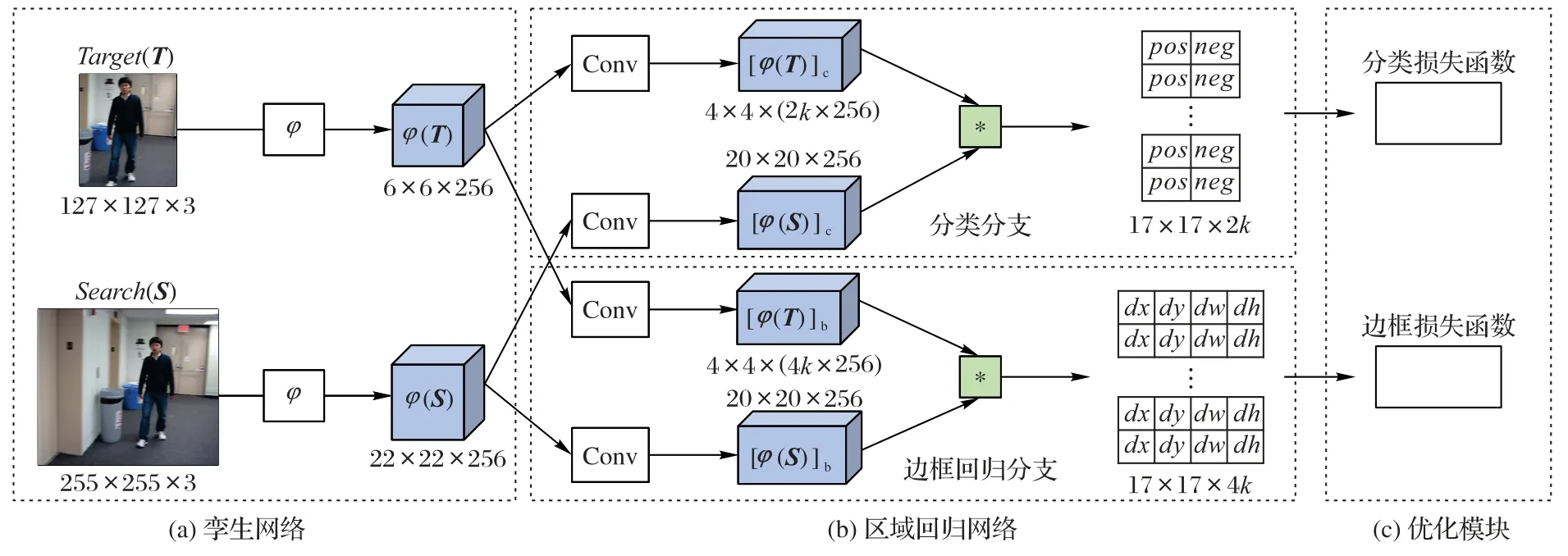
图2 SiamRPN框架Fig.2 Architecture of SiamRPN
由图1 可知,该算法包括孪生网络、区域推荐网络和优化模块三部分,其中优化模块仅在训练阶段有效。该模块根据各样本真实值与预测值,分别完成分类任务和边框回归任务的损失计算,最后根据损失值进行反向传播。
分类任务损失函数为:

其中:CE(pi,gi)为交叉熵损失函数,即单样本分类损失。对于真实标签为gi,预测值为pi的样本i,其交叉熵损失函数为:
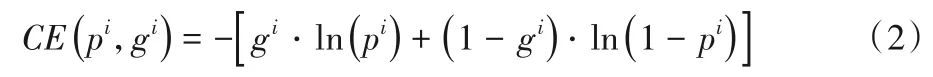
边框回归任务损失函数如下:
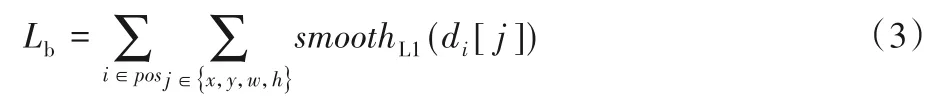
其中:smoothL1(di[j])为损失函数;d为样本i的某一边框预测值与正则化真实值之差(d包括边框的中心横纵坐标x和y、边框的宽w和高h,共四个元素,详细公式在2.3 节中给出);pos表示正样本。
损失函数smoothL1(di[j])如下:
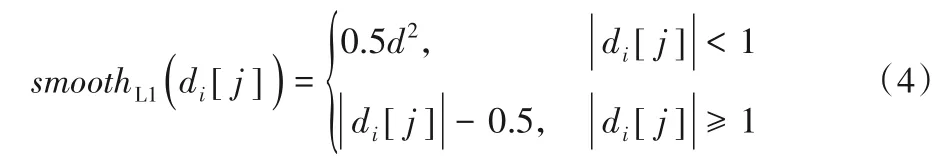
图2中T、S分别为目标图像和搜索图像;φ(T)、φ(S)表示孪生网络提取的目标图像特征和搜索图像特征。SiamRPN 假设有k个预选框(该算法的k为5),区域推荐网络通过两个单独的卷积,将φ(T)的通道数分别提升至2k和4k倍,得到用于分类任务的[φ(T)]c和用于边框回归任务的[φ(T)]b。φ(S)也通过两个卷积分成两个特征[φ(S)]c和[φ(S)]b,其输出特征通道数保持不变。最后通过式(5)得到分类结果和目标位置。
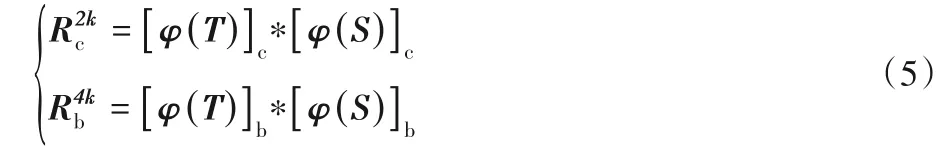
其中:Rc2k表示目标图像T和搜索图像S卷积操作后得到的分类结果;Rb4k表示搜索图像S预测的目标位置相较于k个预选框的正则化距离。在跟踪阶段,从Rc2k中选取前景分类分数最大的预选框作为此帧预测结果,则该预选框对应的边框预测值(ρx,ρy,ρw,ρh),为此帧目标的正则化值距离。假设x、y表示分类分数最大的预选框中心坐标;aw、ah表示该预选框的宽和高,则最后预测的目标位置如下:

以xpred、ypred为中心,裁剪大小为A的搜索图像,A的计算方式如式(7)所示:

其中:p=(w+h)/2;w、h分别为预测的宽wpred和高hpred。然后将搜索图像缩放到255×255。
不断重复上述操作,即通过式(7)计算搜索图像的大小,并在下一帧中裁剪搜索图像,输入图2 所示Search 分支,通过式(5)和式(6)得到新一帧的预测结果。
2 基于联合优化的强耦合孪生区域推荐跟踪算法
为了提升跟踪器的跟踪精度,同时不影响在线跟踪的速度,本文提出一种基于联合优化的强耦合孪生区域推荐跟踪算法,在训练阶段对分类任务与边框回归任务施加约束,以增强分类任务和边框回归任务的耦合性,使得分类置信分数能够反映边框回归任务的精度,算法的整体框架如图3所示。
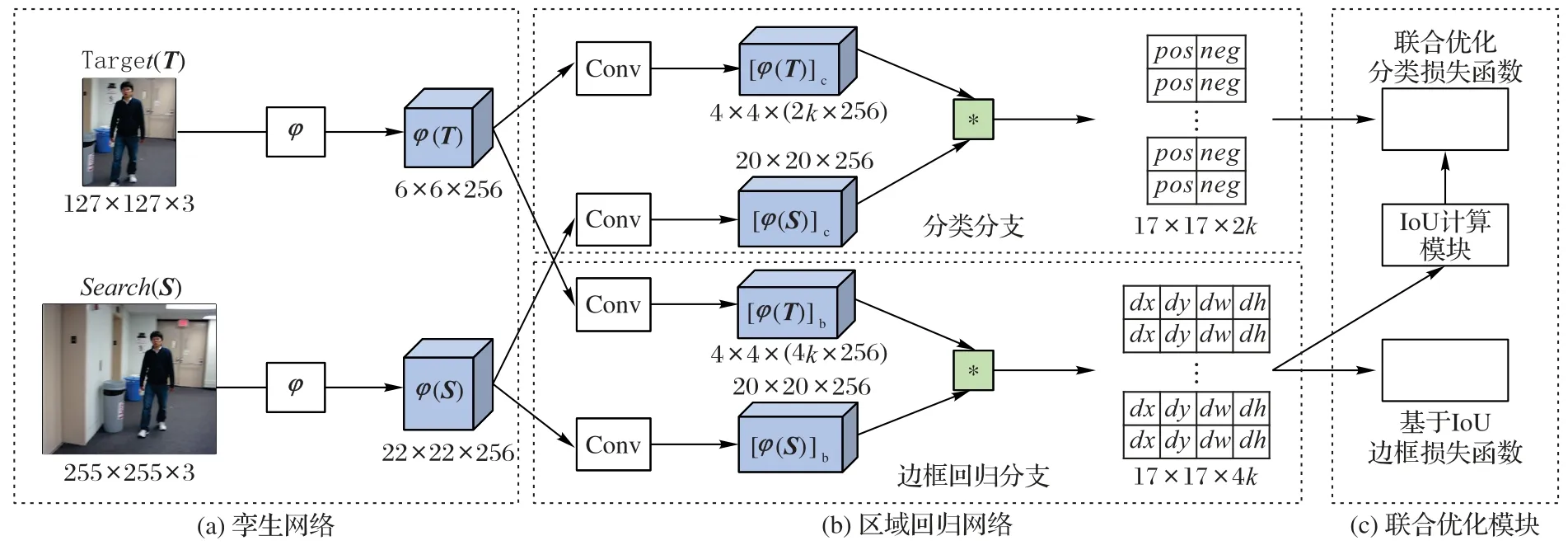
图3 SCSiamRPN框架Fig.3 Architecture of SCSiamRPN
由图3 可知,本文算法在SiamRPN 的基础上用联合优化模块替换原有的优化模块。
考虑到SiamRPN 中样本的正负标签是根据预选框与真实边框的IoU 确定的,本文以IoU 为纽带,重新设计SiamRPN的分类损失函数,增强分类任务和边框回归任务的耦合性,2.1 节介绍本文提出的联合优化分类损失函数;此外,本文也利用IoU 对边框损失函数进行改进,增加接近目标部分的权重,减小远离目标部分的权重,以提升边框回归网络的定位精度,改进的损失函数在2.2 节中介绍;最后,由于边框回归网络预测结果为正则化值,用传统IoU 函数计算时,正则化值需要先转换成平面坐标值再计算,将增大计算误差,导致模型训练不收敛,因此2.3 节介绍本文采用的IoU 计算方法,以提升网络的训练效率和保证网络的收敛性。
2.1 联合优化分类损失函数
采用RPN 的目标检测算法和目标跟踪算法,其分类任务都独立于边框回归任务。在测试阶段对所有正样本都会尽可能预测高的分类分数,而忽略该样本的边框定位精度,最终导致分类分数独立于边框定位精度。在线跟踪时,这一问题会对模型的跟踪性能产生影响。跟踪算法在预测目标位置时,根据最高分类分数确定目标的位置信息,而此时模型的最高分类分数可能对应着低精度的预测边框,从而对模型的定位产生影响,因此增强分类任务和边框回归任务的联系有益于提高定位精度。
由于跟踪算法的最终定位结果只与分类网络预测的前景(正样本)有关,故本文将通过正样本来增强分类任务与边框回归任务的耦合性。对于正样本,在SiamRPN 原有分类损失函数(式(1))的基础上添加与该样本IoU 有关的耦合因子,最终的分类损失函数为正样本分类损失与负样本分类损失之和,如式(8)所示:
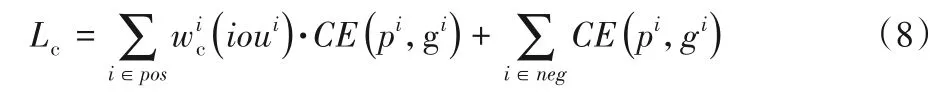
其中:pos表示正样本集合;neg表示负样本集合;ioui为第i个样本的预测边框和真实边框之间的IoU 值;wi(ioui)为以第i个样本IoU值为自变量的耦合因子。wi(ioui)的计算公式为:

其中:α表示超参;n表示正样本数量。为了保证总的正样本分类损失不变,对耦合因子进行了归一化处理。耦合因子表示为该样本IoU 值的α次幂,乘以正样本分类损失之和与以耦合因子为权重的正样本分类损失之和的比值。由式(9)可知,耦合因子与IoU 值成正比,在训练过程中,通过耦合因子改变各正样本的分类损失值,对于边框精度高的样本,即IoU 值大的正样本,增加其分类损失值;对于边框精度低的样本,即IoU 值小的正样本,降低其分类损失值,从而增强分类任务和边框回归任务的耦合性,使得分类分数与边框精度相匹配,达到联合优化的效果。
2.2 基于IoU的边框损失函数
文献[18]指出,即使模型在训练过程中是收敛的,当边缘样本的梯度较大时,边框回归网络损失的梯度主要由边缘样本主导,导致模型在训练过程中更多注重对边缘样本的优化,而忽略对小梯度中心样本的优化。由于目标跟踪任务每次只需得到一个最佳定位结果,该结果越精准越好,但上述问题的存在限制了模型精度的提升。
针对这一问题,文献[18]指出,减小边缘样本的梯度,可以提升对中心样本的优化。基于上述思想,本文提出基于IoU值的边框损失函数,提升目标中心附近样本对边框回归网络损失的贡献。IoU值可以反映边框预测的精度,对于仅含有部分目标的预选框区域,其预测精度劣于含有全部目标的预设区域,本文根据区域推荐网络中预测边框的IoU 值微调其边框损失值。
在SiamRPN 的边框回归损失函数(式(3))的基础上,为所有正样本的边框损失添加与该样本IoU 有关的权重因子,最终边框损失函数如式(10)所示:
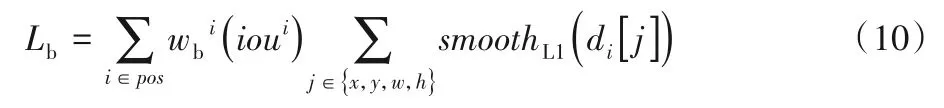
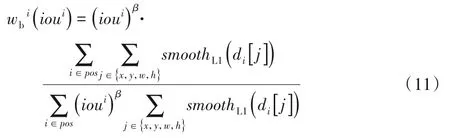
其中:β为超参。同理也对权重因子进行了归一化处理。权重因子为该样本IoU 值的β次幂,乘以正样本边框损失之和与以权重因子为权重的正样本边框损失之和的比值。由式(11)可知权重因子与IoU 值成正比,因此在训练阶段,可通过权重因子改变各样本的边框损失值。如图4 所示,对于边框精度低的样本,即边缘样本,降低其边框损失值,从而降低其对整个网络的梯度贡献;对于边框精度高的样本,即目标中心附近的样本,提升其边框损失值及对整个网络的梯度贡献。
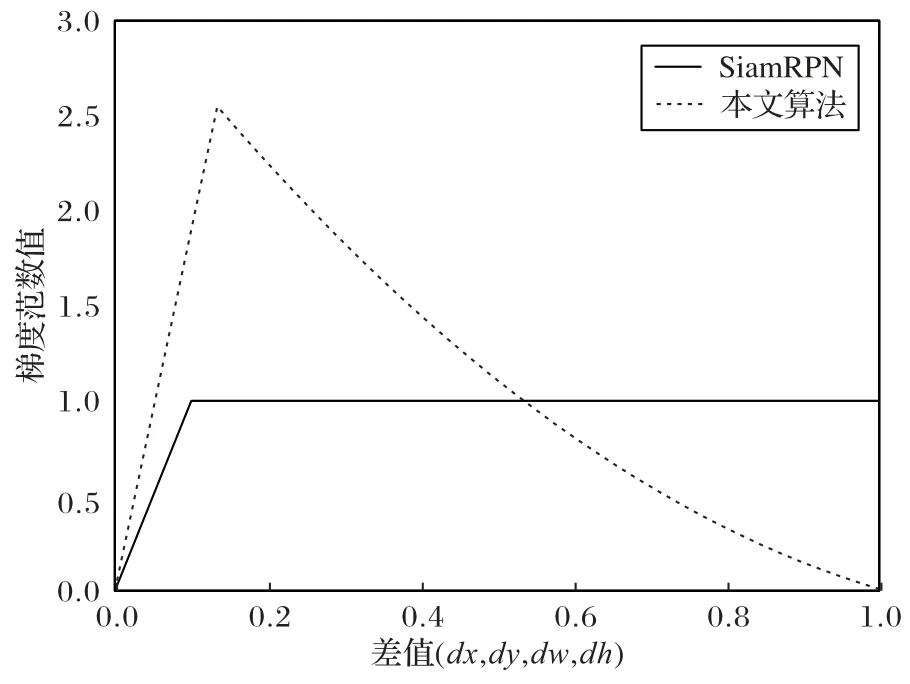
图4 梯度范数可视化Fig.4 Visualization of gradient norm
联合式(8)与式(10)后,即增强分类任务与边框回归任务的耦合性后,提升边框回归精度与提升边框的分类分数形成正反馈迭代关系,最终提升跟踪算法的跟踪性能。
2.3 IoU计算函数
在本文算法中,IoU作为增强分类任务与边框回归任务耦合性的纽带,其计算的高效性和收敛性是关键因素。传统的IoU 函数只能针对平面坐标值计算相应的IoU,而本文算法边框回归网络的边框输出值为正则化后的值。此时如按传统方法计算,需要将正则化值先转化为平面坐标值后,再计算预测边框与真实边框的交集与并集的比值。
针对这一问题,本文采用文献[13]中提出的Bounded IoU方法,并添加近似约束,通过计算IoU 值的上界,无需将正则化值先转化为平面坐标值,大幅大简化了IoU值的计算过程。
下面给出一些变量及正则化的定义,假设第i个样本的预选框ai=(ax,ay,aw,ah),真实边框gi=(gx,gy,gw,gh)和预测边框pi=(px,py,pw,ph),以上变量均为平面坐标值;网络输出的预测值ρi=(ρx,ρy,ρw,ρh)为正则化值,真实边框进行正则化后为δi=(δx,δy,δw,δh),样本i的预测值与真实值正则化差值为di=(dx,dy,dw,dh),即dx=ρx-σx,其他变量同理,其中:x、y表示边框中心坐标;w、h表示边框的宽和高。
模型的预测值均为正则化距离,因而需要对真实边框进行正则化处理,具体如下:

Bounded IoU 的计算方法将IoU 分解为如下4 个独立的部分:
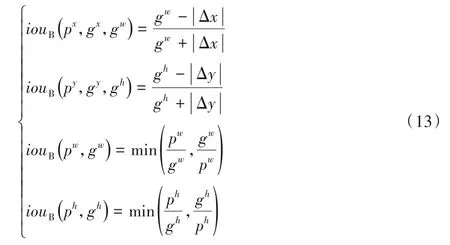
其中:Δx=px-gx,Δy=py-gy。计算iouB(px,gx,gw)值时,假设py=gy,pw=gw,ph=gh,其他部分IoU 值计算类似。根据式(12)和dx、dw差值关系,可得dx=Δx/aw,dw=ln(pw/gw),对于dy、dh也有相似关系。将其代入式(13):
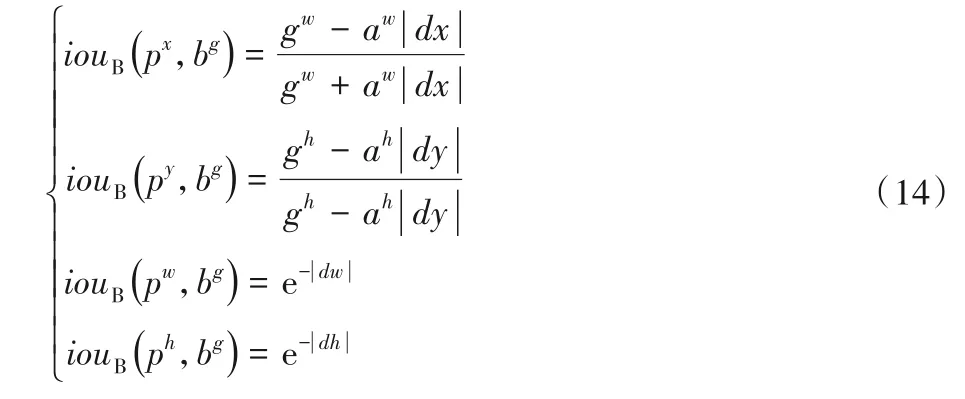
此时,可以直接采用正则化值计算IoU。由于仅计算正样本的IoU 值,而正样本的IoU>0.7,意味着gw和aw、gh和ah的值比较相近,可以假设gw≈aw,gh≈ah,进一步简化式(14)中的前两式,简化后如式(15)所示:
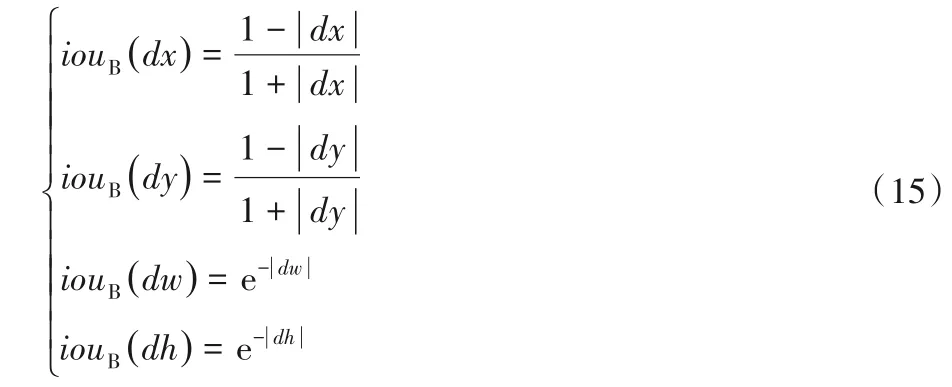
最终的IoU计算公式为:
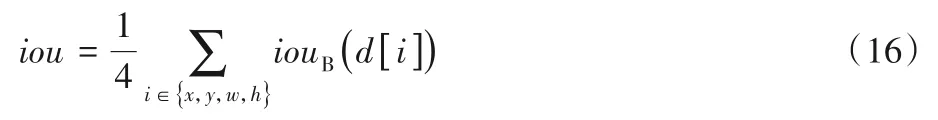
3 实验与结果分析
3.1 实验环境及参数设置
实验的硬件环境为英特尔CPU i7,NVIDIA 1080Ti GPU,32 GB 内存,操作系统为Ubuntu 16.04,深度学习框架为Pytorch 1.0.0[19],编程语言及版本为Python 3.6.5。
本文算法在ILSVRC(the ImageNet Large Scale Visual Recognition Challenge)[20]和Youtube-BoundingBoxes[21]数据集上进行离线训练。其中ILSVRC 是用于目标检测的视频序列,包含了超过4 000 个视频序列;Youtube-BoundingBoxes 是谷歌开源的最大手工注释的视频数据集,包含了超过17 万个视频序列。模型的训练共进行了30 次迭代,对于联合优化损失函数中的超参设为α=1.2,β=1。测试视频使用当前目标跟踪领域常用的OTB50 和OTB100 数据集,OTB 系列数据集包含现实场景中常见的挑战,如快速运动、光照变化、尺度变化、遮挡变化、运动模糊等,可以很好地模拟现实场景中的跟踪;为衡量联合优化对SiamRPN 算法性能的提升,在VOT2016、VOT2018[22]、TC128[23]等数据集进行更全面的实验对比,其中VOT2016 视频集包含60 个测试视频,以短时间视频为主;VOT2018视频集在VOT2016的基础上,更换10个难度更大的测试视频,同时还对所有视频进行重新标注,使得标注边框更加精确;TC128包含128个测试视频,且所有视频均为彩色,更接近人类观察的现实场景。
3.2 定量实验结果对比
性能评估本文采用文献[14]中提出的一次性评估(One-Pass Evaluation,OPE)策略,利用距离精度(DP)、成功率曲线图面积(AUC)两个评价指标。OPE 是指仅用真实边框中目标的位置初始化第一帧,然后运行跟踪算法,根据预测结果计算平均精度和成功率的评价方法,这种方法广泛用于跟踪器的性能评估;DP为预测目标边框中心与真实目标边框中心误差小于某一阈值的帧数占该视频总帧数的比例,其中阈值一般取20 个像素;AUC 为成功率曲线与坐标轴围成的面积,成功率是指真实边框与预测边框的IoU 在不同阈值下视频帧数的总占比。
3.2.1 OTB测试集实验结果
本文选取5个具有代表性的跟踪算法在OTB 系列数据集上进行对比实验,包括高效卷积操作跟踪算法ECO(Efficient Convolution Operators for tracking)[24]、多特征融合目标跟踪算法Staple(Sum of Template And Pixel-wise LEarners)[25]、空间正则判别相关滤波器(Spatially Regularized Discriminative Correlation Filters,SRDCF)跟踪算法[26]、基于全卷积孪生网络目标跟踪算法(SiamFC)和基于孪生区域推荐网络的高性能单目标跟踪算法(SiamRPN)。其中ECO 是目前基于相关滤波的最优秀跟踪算法。由于SiamFC 算法和SiamRPN 算法都需要进行离线训练,为了保证对比的公平性,SiamFC、SiamRPN算法以及本文算法都在相同实验环境下进行离线训练;在测试阶段,所有算法的超参设置均采用原文献中提供的默认参数,最大化还原算法的性能。
OTB50 测试集上的距离精度和成功率实验结果如图5 所示,结果表明本文算法在DP 和AUC 性能指标上均优于SiamRPN 算法,分别提升了3%,也优于现阶段最优秀的基于相关滤波器的算法——ECO,在DP和AUC性能指标上分别提升1%,均优于对比结果中其他算法。
OTB100 测试集上的距离精度和成功率实验结果如图6所示,结果表明本文算法在DP 和AUC 性能指标上均优于SiamRPN 算法,DP 和AUC 分别达到0.86 和0.64,与SiamRPN算法相比均提升了3%。本文算法具有和ECO 同样优秀的跟踪性能,均优于其他对比算法。
3.2.2 与SiamRPN算法对比实验结果
为进一步验证本文算法的有效性,选取VOT2016、VOT2018 和TC128 测试视频集进行实验,给出一次性评估曲线(OPE),如图7~9所示。
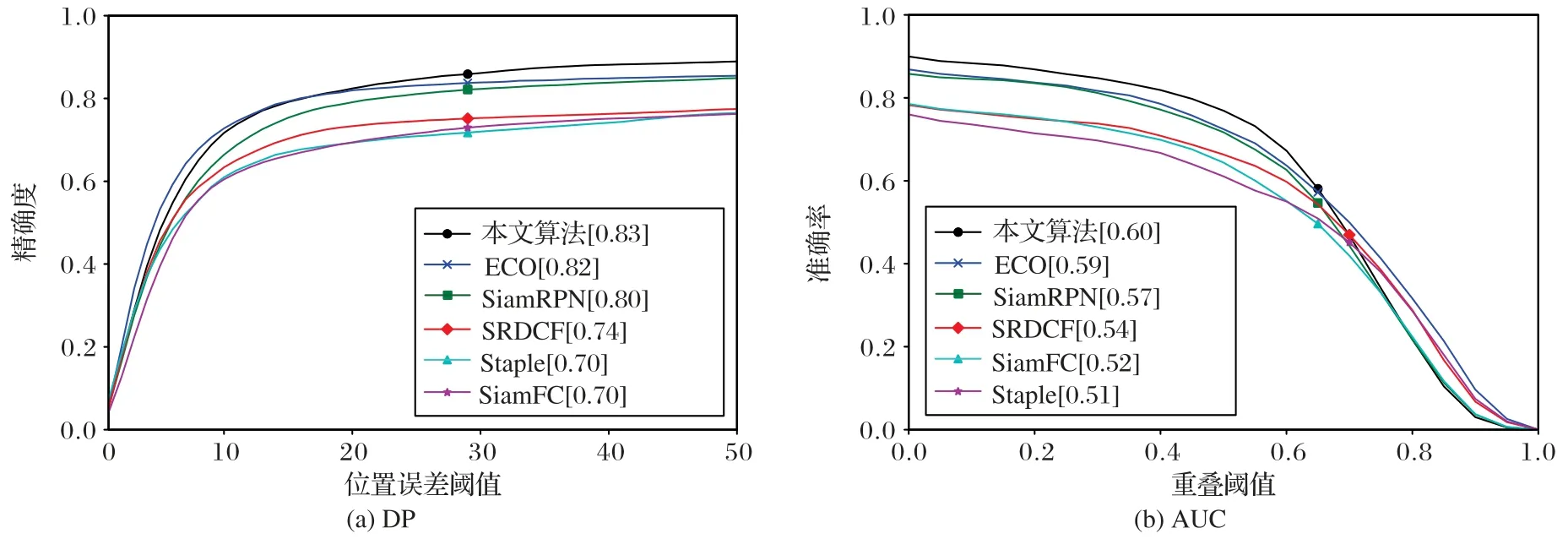
图5 OTB50测试集上的OPE结果曲线Fig.5 OPE curves on OTB50 test set
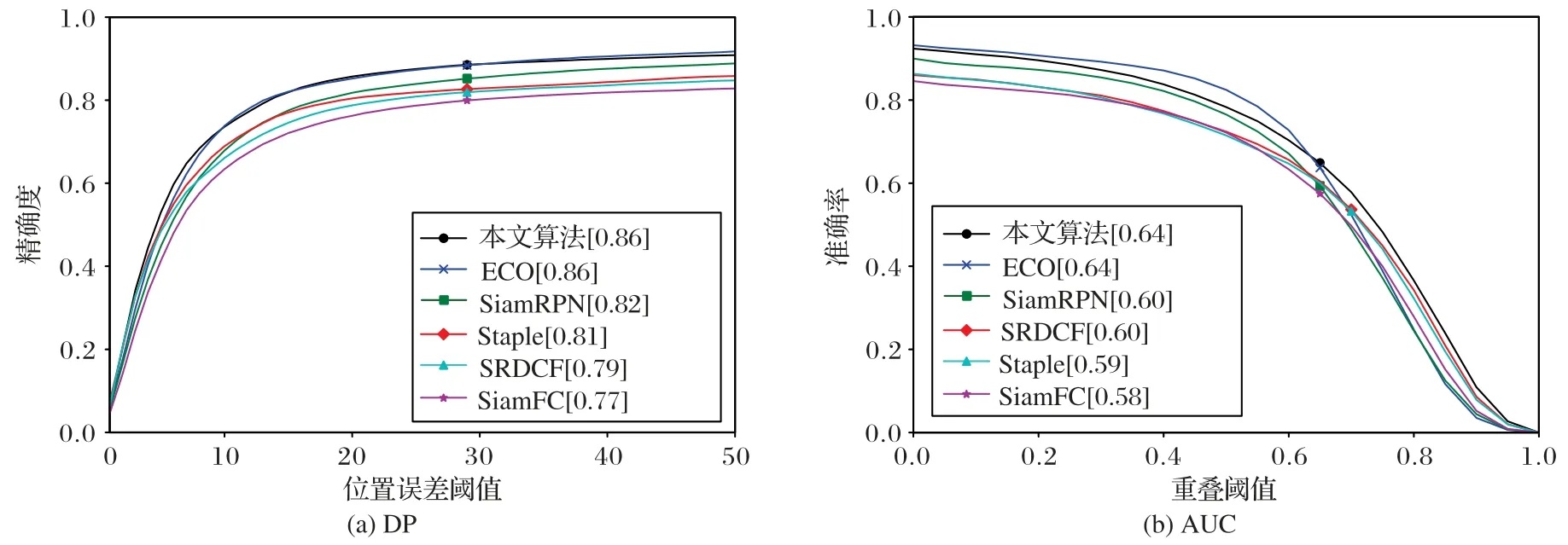
图6 OTB100测试集上的OPE结果曲线Fig.6 OPE curves on OTB100 test set
图7~9是本文算法和SiamRPN 算法在各个视频测试集的OPE 对比结果。在VOT2016 测试视频集中(图7),本文算法的DP 和AUC 分别为0.69 和0.51,比SiamRPN 的DP 有7%的提升,AUC 有5%的提升;在VOT2018 测试视频集中(图8),本文算法比SiamRPN 在DP 和AUC 上均有3%的提升;在TC128 测试视频集中(图9),本文算法比SiamRPN 在DP 和AUC 上均有4%的提升。综合以上各个视频测试集的对比结果可以看出,相较于SiamRPN 算法,本文算法在性能指标上有明显的提升,说明联合优化的方式可以增强分类网络与边框回归网络间的耦合性,使得模型预测的最高分类分数与最佳IoU 边框指向同一预测边框,从而保证算法每次选择最佳预测边框,提升跟踪算法的鲁棒性。
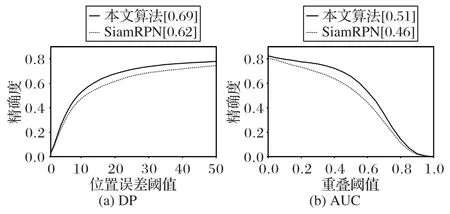
图7 VOT2016测试集上的OPE结果曲线Fig.7 OPE curves on VOT2016 test set
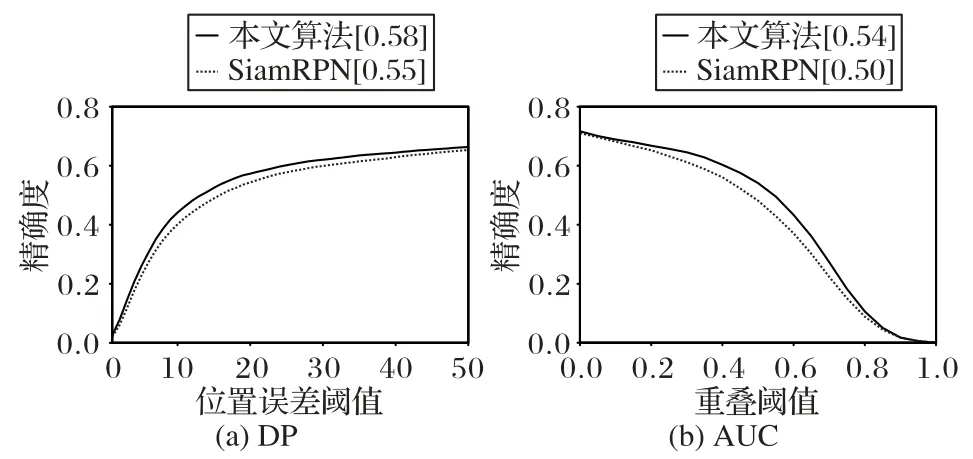
图8 VOT2018测试集上的OPE结果曲线Fig.8 OPE curves on VOT2018 dataset
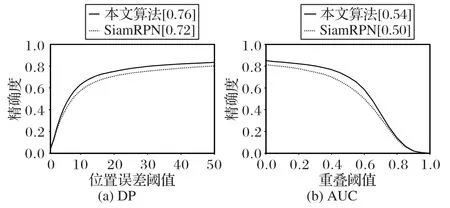
图9 TC128测试集上的OPE结果曲线Fig.9 OPE curves on TC128 test set
3.3 定性分析
本文算法在离线训练阶段联合优化分类网络和边框回归网络,使得分类置信分数最高的边框对应的边框精度也是最高的。为了验证联合优化能够提升最终算法的跟踪性能,从OTB100 数据集中选取3 个具有各种跟踪难点的视频序列,展示本文算法与SiamRPN 算法的预测结果,每种算法选取分类分数前三的预测边框进行展示。图10~12中,IoU 表示预测边框与真实边框的交并比,其值越大表示边框预测越准确,实线矩形框表示分类分数最大的预测框,虚线矩形框表示分类分数次大的预测框,点线矩形框表示分类分数第三大的预测框。
图10 是Boy 视频序列截图,图中男子在走廊中边跳边变换肢体动作,整个运动过程中这名男子的人体姿态变化较大。由图可以看出,本文算法和SiamRPN 都可以较好地预测当前目标的边框信息。SiamRPN 预测结果中最高分类分数和最佳IoU 不是同一个位置上的预测边框,在第244帧图像上最高分类分数指向实线矩形框,而最佳IoU 指向虚线矩形框;本文算法预测结果中最高分类分数和最佳IoU 均指向实线矩形框,同时本文算法最佳IoU 值为0.78,比SiamRPN 的0.74 大。与SiamRPN 相比,本文算法不仅能够保持分类任务与边框回归任务的一致性,对人体姿态变化也更加鲁棒。

图10 Boy视频序列上的结果Fig.10 Results on Boy video sequence
图11是Coke视频序列上的实验结果,图中人手持可乐罐在台灯下和绿植中来回穿梭,在第6 帧和第253 帧时发生遮挡,其中第253帧的遮挡情况更严重。由图11可以看出,本文算法和SiamRPN 估计的目标中心与真实的目标中心均有较大的误差,但在发生大面积遮挡情况时,SiamRPN 只能在可见的区域预测出可乐罐的边框信息,而本文算法会根据可乐罐的部分边缘信息预测出整体的边框信息。与SiamRPN 相比,本文算法在第253 帧时最大分类分数对应着实线矩形框,预测出可乐罐的整体边框,更加准确,而SiamRPN 对应虚线矩形框,同时IoU 值为0.59,也比SiamRPN 的0.44 大。因此,当目标被部分遮挡时,本文算法因联合优化可以保证最大分类分数和最佳IoU 边框的同一性,同时也能提升算法对目标被遮挡时的鲁棒性。
图12 为SUV(Sport Utility Vehicle)视频序列上截图,图中有一辆SUV 在复杂环境下行驶,在第47帧时SUV 部分车身在视线之外和第774帧时SUV 部分车身被遮挡。当SUV 部分车身不可见时,本文算法和SiamRPN 均只能在可见区域预测出SUV 的边框信息。对于第774 帧中SUV 被遮挡这一情况,SianRPN 预测的虚线和实线矩形框的IoU 值差不多,但是该算法对于较小IoU 值边框的预测分类分数为0.99,最佳边框对应的分类分数为0.96,导致分类结果与边框回归结果不一致。本文算法预测最大分类分数和最佳边框IoU 都为实线矩形框,预测分数为0.99,最大IoU 为0.74,优于SiamRPN 的0.71。目标部分区域出视线或者被遮挡会造成目标的不完整性,影响提取的特征,本文算法仍可以输出具有强联系的分类分数和边框,使得最大分类分数和最佳边框指向同一预测区域。

图11 Coke视频序列上的结果Fig.11 Results on Coke video sequence
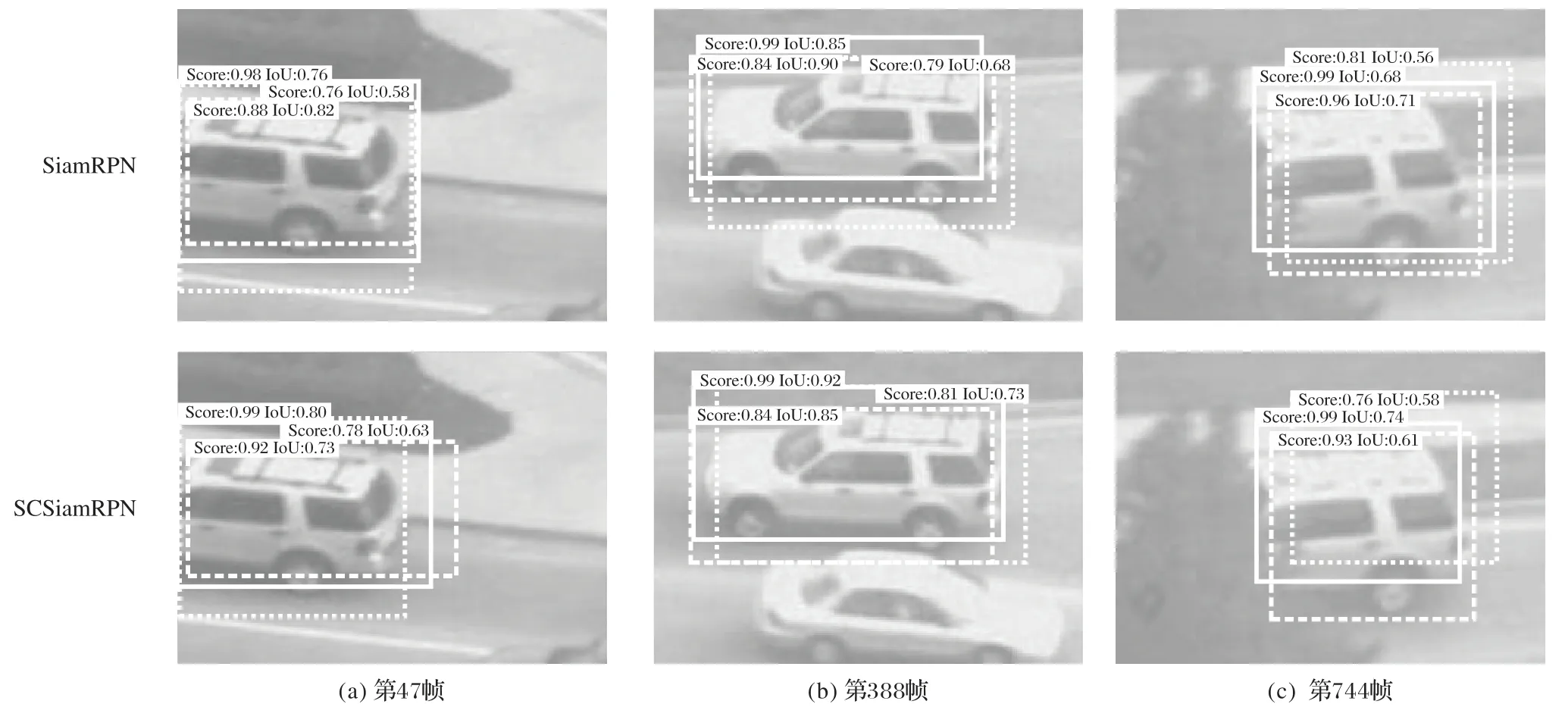
图12 SUV视频序列上的结果Fig.12 Results on SUV video sequence
4 结语
本文对SiamRPN 算法的分类任务和边框回归任务进行深入分析,在此基础上提出联合优化的方法,对分类网络和边框回归网络进行联合优化。本文提出的联合优化方法能在不损失在线跟踪速度的情况下,提升算法的边框预测精度。实验结果表明,本文算法的性能达到或优于其他对比算法。由于基于孪生网络跟踪算法仅使用初始帧目标特征,无法及时捕捉目标的外观变化,在后续的研究工作中,会考虑结合在线更新策略,进一步提升算法的跟踪性能。
