基于L1范数线性回归的NIR光谱产地鉴别算法
2020-09-01但松健
但松健
(重庆第二师范学院继续教育学院,重庆 400067)
近红外光谱(Near infrared spectroscopy,NIR)分析技术作为一种快速、准确、便捷且非破坏性的分析技术,在农产品品质检测和产地鉴别方面得到了广泛应用,被认为是有望替代传统的化学分析的无损检测方法[1-2]。在以前的研究中,基于一般框架下的红外光谱处理方法,即针对高维光谱信息进行降维、关键波长提取和分类器构建,并利用不同的机器学习算法取得了一定的效果[3]。然而关键特征光谱的提取过程往往和学习分类器的过程分类开来,且针对不同的数据集,往往需要重新计算和提取关键特征;同时,虽然近红外光谱样本的收集相对其他检验方法更为容易,且具有低成本和不破坏样本的特性,然而收集大量的样本仍然需要耗费大量的时间。
针对以上问题,本文利用稀疏表示的理论框架,提出了一种基于L1范数线性回归的近红外光谱分析方法,该方法基于L1正则化的学习方法,将特征选择和分类器学习过程进行了有效的融合,并仅利用少量的样本对光谱进行重构分析,基于最小重构误差来进行柑橘产地判别。实验结果表明,相比传统的学习算法,本文提出的方法能较为有效地用于样本数较少时的NIR光谱产地鉴别中。
一、基于稀疏表示的特征选择和正则化学习方法
特征选择对于基于NIR的产地鉴别分析有着较为重要的作用,特别是对于NIR光谱特征维度较大(本文中为1500维),而大部分光谱信息均为冗余,只有少量的信息对于产地鉴别具有鉴别影响。因此近红外光谱(NIRS)是一种间接分析技术, 其应用往往需建立相应的校正模型。为了提高模型的解释能力、预测准确度和分类模型的效率,需要对NIRS进行波长选择, 优选最小化冗余信息[4]。目前传统的波长选择方法主要集中于从全光谱信息中选择特定子集的选择方法,包括:常见的前向、后向选择、基于信息熵的特征选择,以及近年来研究较多的基于启发式算法,例如上一章节中模拟生物基因进化规则的遗传算法、模拟蚁群觅食移动的蚁群算法[5]、基于逆跳马尔科夫蒙特卡洛模型维数与模型集群分析的随机青蛙算法[6]、源于鸟群捕食行为的粒子群优化算法[7]等。这些最优子集的选择算法虽然已证明在提高NIR分析模型的精度方面具有显著的效果,然而这些算法往往需要设置复杂的参数,对于不同的NIR光谱数据集不具备普适性,同时特征选择的过程往往与分类器的训练过程相互独立。
与上述传统的特征选择算法不同,基于稀疏表示的分类器构建同时考虑特征选择过程和学习器训练过程并将其进行有机的融合,即两者在统一的优化框架下同时完成,对于分类器的样本学习过程也进行了最优的特征表达学习。而这一过程的完成往往借助于正则化约束条件来实现。

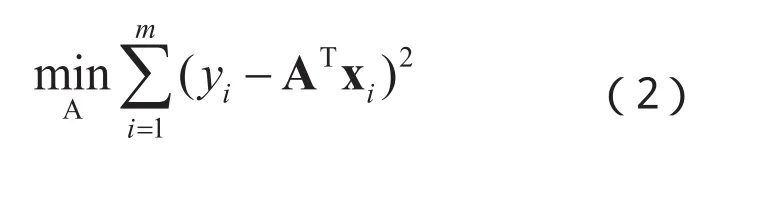
在NIR光谱分析中,由于光谱特征n往往远远大于样本数m,因此对应的方程组为欠定的,即对于式(1)的解有无穷多个,在机器学习中,这种训练不足的结果往往得到的是过拟合的分类器。然而,如在式(2)中引入正则化约束,则可以有效降低过拟合的风险,其表达式为:
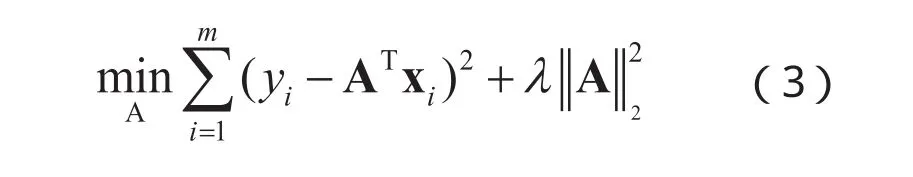
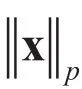
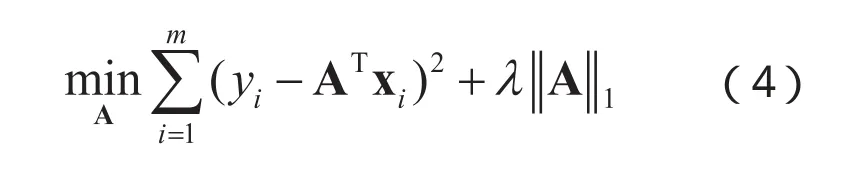
虽然式(3)和式(4)在表达形式上大致相同,然而L1范数的求解将得到更为“稀疏”的解,即能够使得求得的 A含有更少的非零分量。这种 A取得稀疏解的特性意味着初始的n个特征中仅对应少量 A的非零分量出现在最终的分类模型中,也就是说求解L1范数正则化的结果使得模型自动地选择最有代表性的特征向量来表达原始的特征,从而使得分类器的训练过程和特征选择的过程在统一的框架下完成,同时正则化的约束下对于仅有少量样本的训练情况下,模型仍然能够得到最佳泛化性能的解。因此上述思想对于NIR光谱分析中的关键波段选择和样本不足的问题的解决提供了理论基础。
二、基于L1范数的线性回归产地鉴别模型
(一) L1-LRC产地鉴别算法
线性回归分类器(Linear Regression Classification,LRC)[9]由Naseem等人提出,其基于一个基本的假设:某一类别的模式存在于由同一类别样本张成的一个特定的线性子空间,因此对于分类模式可以表达为该类别的训练样本的线性组合。对于一个待测试的样本,将对每一个测试类别都进行线性组合重构,并利用最小重构残差进行判断。LRC算法最早被应用于人脸图像识别中,人脸图像可看成是一个二维离散信号分析问题,相似于NIR光谱分析,人脸识别同样存着在特征维度较高并需要提取关键特征的问题[10]。LRC应用于人脸识别中,特别是在一定光照和遮挡等一定噪声影响下的人脸图像识别中取得了较为出色的结果。然而作为一种最近邻子空间算法,在样本较少的情况时,原始的LRC算法由于少量样本对于子空间不够充分,特别是存在训练样本偏移情况时往往造成重构的误差较大,使得训练样本张成的线性空间并不是对于该类别模式的无偏估计。在本文中,基于上述问题,提出了基于L1范数的LRC算法并将其应用于NIR光谱的柑橘产地鉴别模型中,该算法通过利用上节中的正则化方式对求解的LRC模型进行稀疏约束来对其进行有效的改进。
设给定C类产地的柑橘NIR光谱样本,每个样本共有m维光谱信息,Ai为表示训练集中属于第i类产地的样本集合:
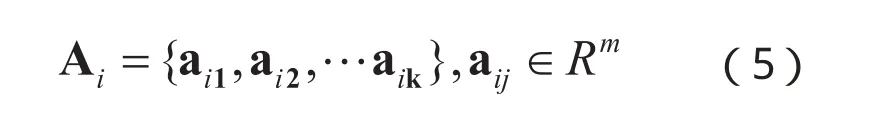
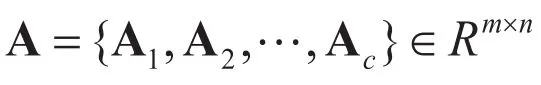
(2)对于每一类产地类别计算其相应的线性回归系数 xi;
(3)利用线性回归系数来对每一类的光谱模式进行重构得到预测结果,并计算其与测试样本y的重构误差:
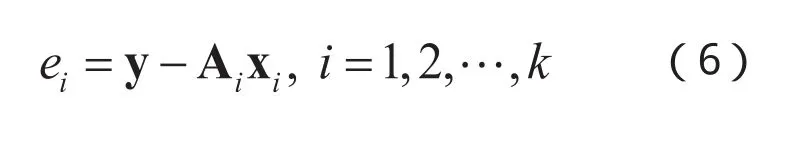
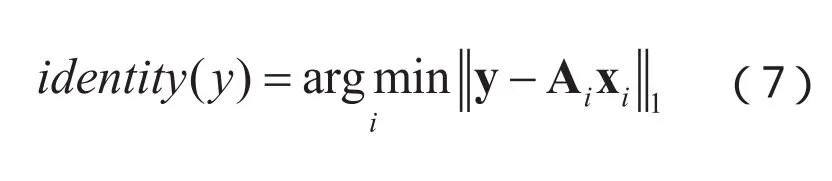
图1给出了基于16个产地鉴别的NIR光谱模式重构误差示意图,其中测试样本属于第1类的产地。从图中可以看出,与其他的产地类别相比,测试样本与第1类的重构误差最小(用红色线条标出),即线性分类模型给出了正确的分类。
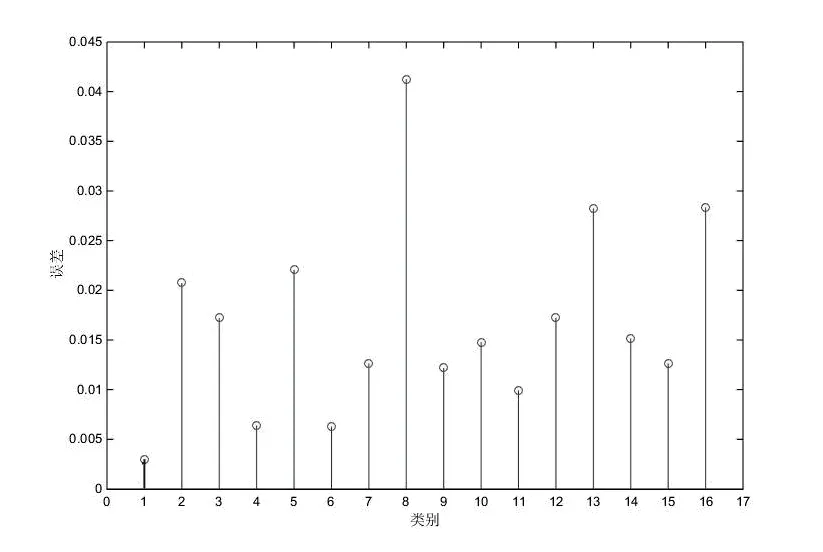
图1 L1-LRC算法的重构误差示例图
(二) L1-LRC产地鉴别模型求解
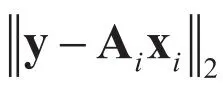
对于公式(7)的求解,可以转换为以下的凸优化问题:
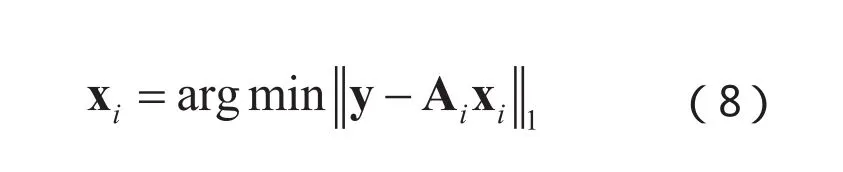
其中,L1范数求解可通过求解以下线性规划问题得到:
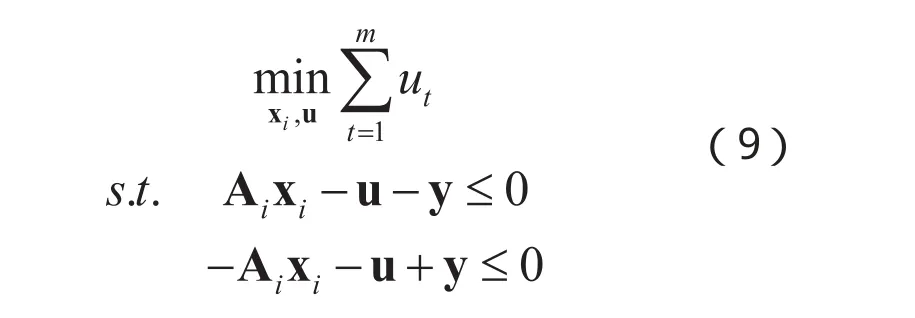
上式可转换为原-对偶内点问题并基于牛顿迭代法进行求解[12],设变量fu1,fu2为:,设权重向量,则第t次迭代有:
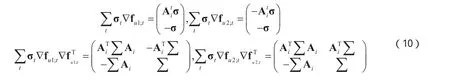
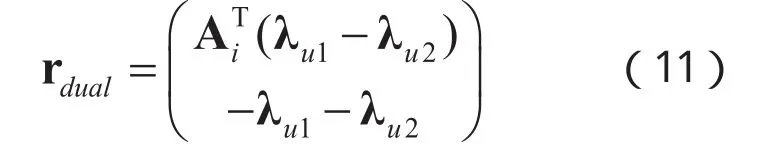
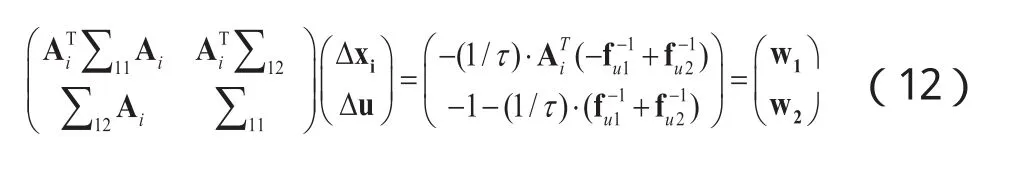
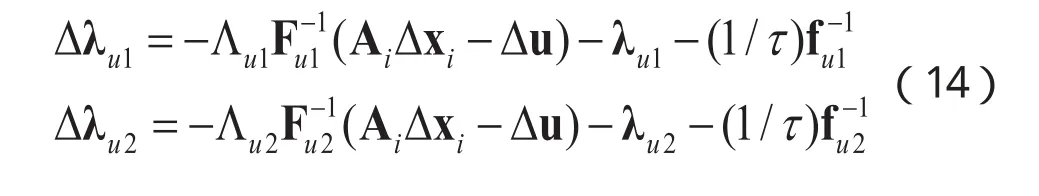
通过以上原-对偶内点法计算得到系数向量xi后,通过计算公式(7)即可得到待测试样本 y的产地类别。
三、实验结果和分析
本文将基于L1范数LRC 算法(L1-LRC),利用柑橘的NIR光谱进行产地鉴别分析实验。为进行对比,本文在实验中针对原始的LRC算法,决策树(DT)、最近邻分类器(KNN)、朴素贝叶斯(NB)和支持向量机(SVM)模型对同一数据集进行预测。其中原始NIR数据进行了SG(Savitzky Golay)平滑,DT、KNN和NB以及SVM进行了PCA(Principal Component Analysis)操作后,基于信息熵的特征选择算法提取了最优的主成分作为特征输入进行训练和测试。而L1-LRC 和LRC算法则直接采用平滑后的1500维特征进行训练和测试。本文进行了5×10次的交叉验证,取最后的平均识别准确率作为判别性能的依据。
表1和图2给出了不同的机器学习算法在使用不同的训练样本数量时(使用10%-50%的样本进行训练),针对16个地区的NIR光谱产地鉴别的平均正确率结果。
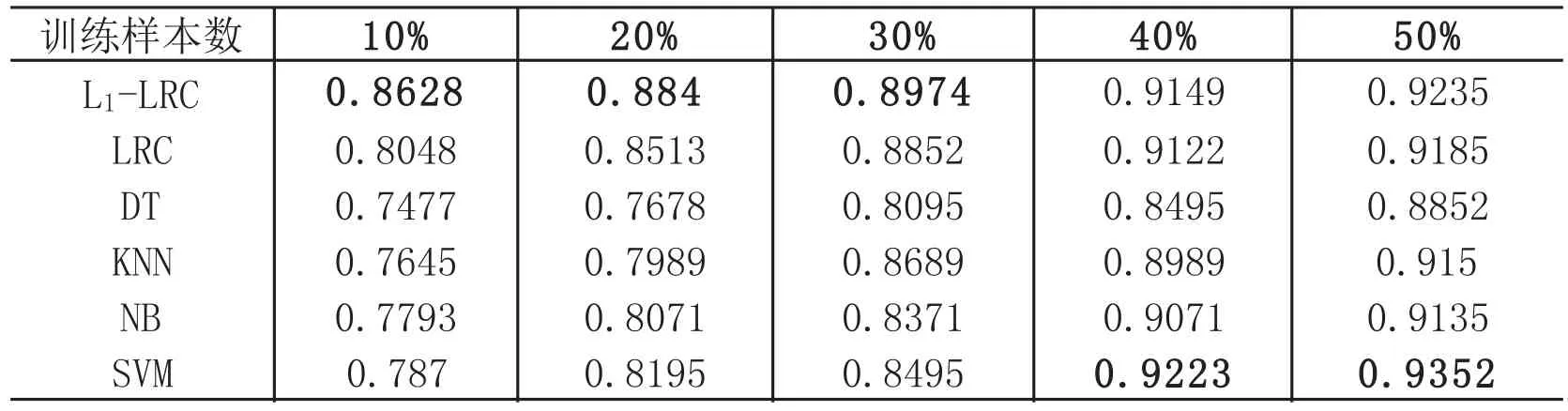
表1 不同的分类器在使用不同比例的训练样本时的平均识别率
从图2和表1中的实验结果可以看出,L1-LRC和LRC在样本较少时,特别是在仅利用10%-30%的样本时,具有明显优于其他分类器的识别效果,其原因在于分别利用了L1和L2正则化的方式来获取对于样本子空间的稀疏表示,从而避免了样本过少时分类器的过拟合现象。同时L1-LRC相比采用欧氏距离(L2范数)的LRC更能够描述样本子空间中的结构分布特性,因此获得了相比原始LRC模型更优的识别结果,其中仅利用10%的样本就能够对86.28%的柑橘进行有效的产地鉴别;值得注意的是,L1-LRC对于样本的增加其正确率变化并不明显,相反,LRC在样本增加后其正确率得到了有效的提高,这是因为原始的LRC算法采用的是最小二乘拟合,训练样本数的增加在一定程度上减少了训练样本过少时噪声带来的分类器拟合误差。
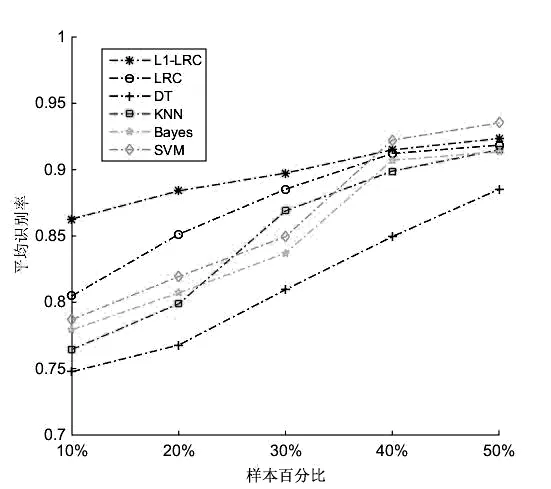
图2 不同的分类器在使用不同比例的训练样本时的平均识别率
同时,其它传统的分类模型在仅有少量样本时,往往难以获取较为满意的效果,其中10%样本时SVM仅获得了78.7%的正确率。然而在随着样本的增加,传统分类模型的正确率也得到了显著的提高,在使用40%的样本时,各个分类模型获得了较为接近的效果,而在50%样本时,SVM获取了最佳的93.52%的分类结果,略优于L1-LRC的92.35%的正确率,这是因为SVM采用了非线性的核映射方法,因此在处理NIR光谱中非线性的噪声影响且在样本充足的情况下,获得了更优于其它基于线性分类器的识别结果。然而传统的分类模型包括SVM等都需要进行降维、特征选择等一系列复杂的提取特定关键波长特征的操作,而L1-LRC和LRC算法可直接在原始维度的NIR光谱特征基础上建立具有较高识别率的模型,因此具有更好的适应性。
综上,本文提出的基于L1-LRC的NIR光谱产地鉴别算法,仅利用少量的样本就能够获取较高的识别率,同时由于采用L1正则化的学习方法将特征选择和模型训练进行了有机融合,避免了关键波长提取等复杂操作,从而为快速进行基于NIR的产地鉴别操作提供了一个新的可行解决方案。
四 、结语
本文提出了一种新的基于L1范数的线性回归(L1-LRC)的NIR光谱分析算法,该算法基于L1正则化学习方法将关键波长提取和模型训练过程进行了有机的融合,提高了模型在不同数据集中的适应度;同时L1范数能够有效揭示数据的内在分布结构,增强了分类模型在样本有限条件下的泛化性能。
在本文收集的柑橘NIR样本基础上,采用L1-LRC算法进行了产地鉴别实验,并与原始的LRC和传统的机器学习模型包括DT、KNN、NB、SVM分类器进行了比较。实验结果表明,基于L1-LRC的NIR分析方法仅利用少量的样本就能够达到较高的识别精度,且获得了明显优于其它对比模型的结果,因此提出的算法为快速高效的NIR光谱产地鉴别提供了一个新的思路。
