基于残差网络和多模Triplet Loss的素描人脸识别
2020-07-09蓝凌吴剑滨侯亮
蓝凌 吴剑滨 侯亮

摘 要:人脸素描识别是从一个大的人脸素描数据集识别人脸照片,它的主要挑战在于不同模态之间的差异,为了解决这个问题,提出一种基于残差网络多任务度量学习的素描人脸识别框架。首先,对于减少不同模式之间特征的差异性问题,设计了一个三通道神经网络来提取照片模态和草图模态的非线性特征,然后三个网络的参数共享;其次,设计了多模Triplet Loss来约束公共空间中的特征,使模型在扩大异类样本距离的同时,减少素描人脸的同类差异。
关键词:深度学习;残差网络;素描人脸识别;多模Triplet Loss
中图分类号:TP391 文献标识码:A 文章编号:2096-4706(2020)21-0071-05
Sketch Face Recognition Based on Residual Network and Multi-mode Triplet Loss
LAN Ling1,WU Jianbin2,HOU Liang3
(1.Guangdong Beijiang Middle School,Shaoguan 512026,China;2.Education Bureau of Wujiang District,Shaoguan City,Shaoguan 512029,China;3.Shaoguan Public Security Bureau,Shaoguan 512029,China)
Abstract:Face sketch recognition is to recognize face photos from a large face sketch data set,and its main challenge lies in the differences between different modes. In order to solve this problem,a sketch face recognition framework based on multi-task metric learning of residual network is proposed. First,for the problem of reducing the feature difference between different modes,the three-channel neural network is designed to extract the nonlinear characteristics of the photo mode and the sketch mode,and then the parameters of the three networks are shared. Secondly,a multi-mode Triplet Loss is designed to constrain the features in the public space,so that the model expands the distance of heterogeneous samples while reducing similar differences in sketch faces.
Keywords:deep learning;residual network;sketch face recognition;multi-mode Triplet Loss
0 引 言
人脸素描识别是指根据给定的人脸素描图像,从一个巨大的数据集匹配人脸照片,这项技术在罪犯案件侦破中有着广泛的应用。特别是犯罪嫌疑人照片不能直接在犯罪现场抓拍,执法人员必须制作手绘的面部草图或是通过软件获得的合成草图,当警察拿到这些草图后,他们可以迅速缩小犯罪嫌疑人的范围。然而,由于照片与人脸草图之间的有很大模态差距,基于草图的人脸识别仍然是学术界内[1]一个具有挑战性的话题[2],传统的同质人脸识别方法在人脸素描识别[3]中表现不佳,因此,需要一种自动人脸素描识别方法来准确、快速地检索执法人员的人脸数据集。传统的人脸素描识别方法主要三种策略来缓解交叉模态差异[4]:模态不变局部特征提取、照片生成和公共子空间投影。基于模态不变特征提取的方法旨在基于局部特征描述符,如局部二值模式(LBP)和定向梯度直方图(HOG)来表示人脸图像。Zhang等人[5]提出了一种基于局部描述符的人脸草图识别与耦合信息理论编码。Klare等人[6]提出了一种将尺度不变特征变换(SIFT)与多尺度LBP相结合的判别分析算法。Galoogahi等人[7]提出了一种改进的人脸特征描述符,称为平均定向梯度直方图(HAOG),以缩小模态间隙。Alex等人[8]提出了一种基于高斯二进制模(LDOGBP)局部差异的跨模态人臉识别方法。然而,大多数基于描述的局部特征方法在表示人脸图像时忽略了整体的空间结构,这对于人脸素描识别[9]很重要。
基于生成的方法通过照片-素描合成人脸图像的一种形态。最初Tang[10]等人提出了基于主成分分析(PCA)的线性特征变换的草图合成和识别方法。Liu等人[11]提出了一种基于局部线性嵌入(LLE)的草图合成方法,用分段线性映射来估计非线性映射。Li等人[12]提出的基于自适应表示的人脸草图合成,其中不同的面部区域由不同的特征表示。Wang等人[13]提出了离线随机抽样来合成人脸草图。
最近,深度学习也被应用于人脸素描合成中,如全卷积网络(FCN)[14]和生成对抗性网络(GAN)[15]。Jiao等人[16]修改了卷积神经网络(CNN),以便使用轻量级模型将人脸照片直接映射到人脸草图图像。Jiang等人[17]提出了一种基于联合字典和残差学习的草图综合方法。这些方法的主要局限性使人脸素描合成更具挑战性,因此,合成的素描图像可能会丢失原始面部照片中存在的某些面部结构信息。
常见的基于子空间的方法旨在将不同的模式转换为一个公共的子空间,以减少素描图像和照片图像的差异。Lin等人[18]提出了一种判别特征提取方法,将异构特征转换为相同的特征空间。Yi等人[19]利用典型相关分析进行跨模态匹配。Sharma等人[20]将偏最小二乘(PLS)方法应用于不同模式的线性映射图像到公共线性子空间。Meina等人[21]提出了一种多视点判别分析(MvDA)方法,通过优化视点间和视点内获得多视点的公共空间。Mignon等人[22]提出了一种跨模态度量学习(CMML)方法来学习判别潜在空间。然而,这些方法没有考虑样品的非线性分布。近年来,在计算机视觉领域提出了许多度量学习(ML)方法。然而,大多数传统的度量学习方法通常学习线性映射到项目样本再到一个新的特征空间,这受到不同模式的非线性关系的影响。因此,部分学者提出了深度度量学习(DML)方法来学习非线性特征[23-25]。Hu等人[23]提出了一种用于人脸验证的判别式深度度量学习方法。Cai等人[24]提出了一种利用深度独立子空间分析网络的深度非线性度量学习方法。Yi等人[25]提出了一種具有孪生深度神经网络的DML方法,直接从图像像素中学习相似性度量,用于人的再识别。在这些深度度量学习的启发下,本文提出了深度残差网络多任务度量学习。
1 基于残差网络和Triplet Loss的素描人脸识别
1.1 网络结构
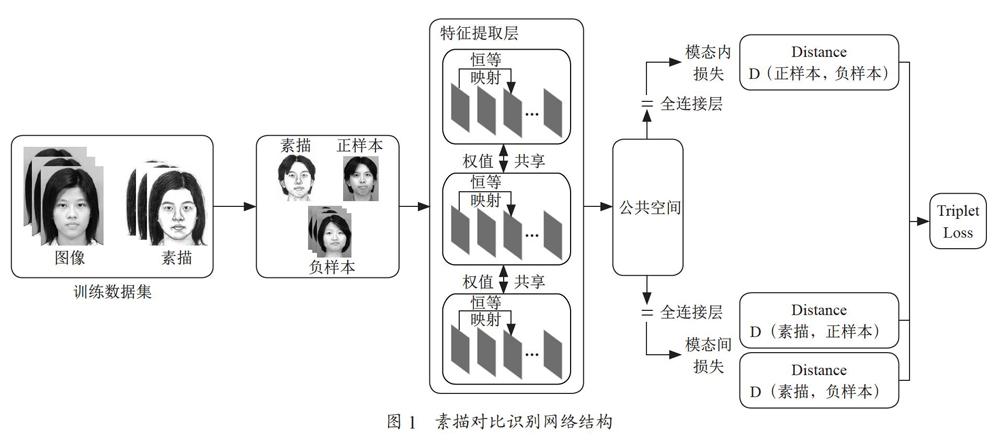
深度学习技术特别是卷积神经网络已越来越多地应用于计算机视觉任务,如目标检测、识别和分类[29]。利用层次结构,CNN可以学习输入图像的深层特征表示。然而,由于有限的素描照片数据集,基于CNN的监督方法在人脸素描识别中还没有得到广泛的应用。本文提出了一种基于深度学习的人脸素描识别方法,对传统Triplet Loss加入了模态内损失以提升模型对照片的区分能力。通过采用难分数据选择策略构造多个三元组样本来扩大数据集,充分利用样本的标签信息来挖掘样本非线性特征之间的关系,同时为了学习人脸素描识别的领域特征,我们使用迁移学习技术利用素描识别数据集对模型权重进行微调。整体结构如图1所示。
素描人脸识别定义为假设A={ai|i=1,2,…,k}和Z= {zi|i=1,2,…,k}是一组训练样本,其中A为素描数据样本,Z为照片数据样本,Z中包含正样本照片P和负样本照片N,k为训练样本的数目。ai和zj分别为A和Z中的第i个样本和第j个样本。我们对样本集中的每两个样本进行组合以获得所有样本的不同组合。每一对样本{ai,zj}包含草图模态和照片模态,P{ai,zj}是ai和zj为同一个人的概率,如果类别预测与真实标签相同,则输出为1,否则输出0。
1.2 网络模型
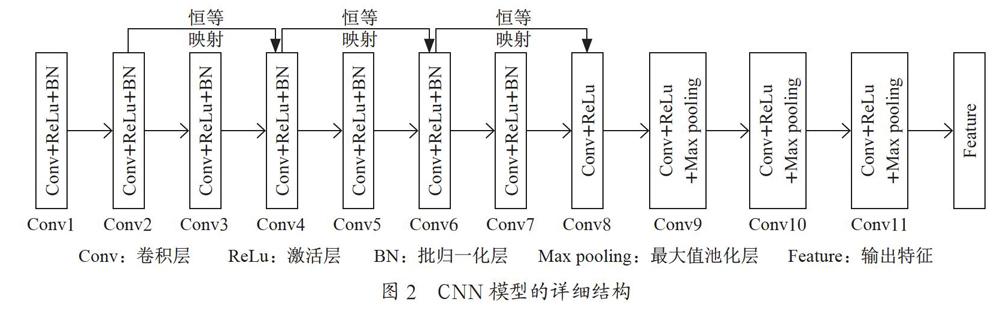
网络模型由11个基本层组成,较深的层可以提取更多的判别特征。为了保持网络性能适合素描人脸识别,我们切割了最后三层卷积层,并保留了预训练模型的其余层。同时,我们建立了一个新的模型,在网络模型之后增加了人脸特征提取层,而在特征提取层我们采取了恒等映射的结构以最大保留图像细节信息。当人脸素描照片数据较大时,每一张图像都需要提取特征,会耗费极长的时间,因此在人脸特征提取层后添加了池化层以减少特征数量,同时可保留重要特征避免冗余特征的干扰。设计的CNN模型的详细结构如图2所示。
另外,为了学习多模态的面部特征信息,使受试者之间的差异更大,受试者内部的间隙更小,我们设计了具有三元组损失的三通道CNN架构。这三个通道,每个通道的网络模型均共享相同的权重。在人脸特征提取层后,三通道的输出与Triplet Loss相连接。通过Triplet Loss可学习多领域的不变特征。
1.3 Triplet Loss
Triplet Loss[25]的目的是促进类内紧凑性和类间可分离性,即给出同一个人的素描图像和照片,这两张图像间的特征距离很小,而与不同人的图像特征距离则很大。但是该损失仅能提取模态间的特征,而没有考虑模态内数据间的差距,因此通过多模Triplet Loss引入模态内损失,从而提升模型对同类型数据间的判别能力。Triplet Loss的输入包括人脸素描图A、正样本照片P(即与素描图为同一人的照片)和负样本照片N(即与素描图不是同一个人的其他照片)。模型优化的目标是使A图提取到的特征与P图特征之间的距离d(A,P)小于锚草图嵌入到负照片之间的距离d(A,N),Triplet Loss可表达为:
L(A,P,N)=max(d(A,P)+d(A,N)+d(P,N),0)
对于输入ai和zj,f(ai)和f(zj)是通过神经网络的相应输出。样本ai和zj在公共空间中的距离可以用f(ai)和f(zj)之间的欧氏距离来测量:
d(f(ai)),f(zj))=‖f(ai)-f(zj)‖2
通过最小化多模Triplet Loss,d(A,P)会无限接近于0,d(A,N)和d(P,N)会大于d(A,P)。最终,同一个人的不同模态数据的距离会变小,而不同人的距离则变大。
其中模内损失函数d(P,N)定义为:
其中,D={(i,j)}为不同对的索引,?为阈值,而不同对的特征距离d(f(zi)),f(zj))通过优化会大于阈值?以增加不同对数据间的可分离性。
模态间损失函数的目标是通过最小化类内距离和最大化类间距离来促进类内相关性和类间分离性。为此,我们定义模态间损失函数:
其中,h(t)=max(0,t),S={(i,j)}为相同对的索引。由于相同对的数量比不同对小,通过引入权重值θ以解决这一不平衡问题。
1.4 难样本选择策略
对于一组训练数据,在L(A,P,N)损失足够小接近零的情况下,是不会帮助模型收敛的,然而随机产生的训练数据组是很容易出现此情况的。为了更好地学习人脸素描识别的判别特征,我们提出了难分样本选择策略,它可以增加有效训练数据,加速损失收敛。当用难分样本选择策略对预训练深度模型进行微调时,将更多地关注预训练模型难以区分的数据。因此,难分样本选择策略可以调整模型使其提升对难分人脸图像的鉴别能力。
由于人脸照片与素描图像有差异,为了选择难分样本,我们将所有训练照片和草图图像由预训练的网络提取高级特征,从而计算特征间的欧氏距离,根据距离值进行排序,将不是同一个人的数据组中距离最近的数据作为优先选择的训练数据。同时为了增加训练样本的大小,我们为每个素描图组成了多个训练数据组。例如,如果训练数据中有1 000对素描、照片对,为每个锚草图选择了5个难分样本,那么我们就可以组成5 000个训练三元组样本,该方法可对数据量进行一定的扩增。
深度神经网络模型需要大量的训练数据,数据越多,模型效果会更好一些。然而在实际中我们并不需要通过大量数据认出某个人。利用结构化的三通道CNN体系结构、共享的通道权重和三元组训练数据集,可以从少量的数据中训练出高效的深度模型。在训练过程中,我们优化目标是最后的特征提取层权重,减少了需优化权重量,这样也可减少对数据量的要求。
2 实验
实验基于Ubuntu 18.04操作系统,网络搭建基于开源深度学习框架PyTorch。GPU(图形处理单元)为GTX1060Ti,CPU型号为i7-8750H,频率为2.10 GHz,内存为8 GB。
在实验中,根据难分数据选择策略生成数据对。CUFS数据库用于研究人脸素描合成和人脸识别,共包含606张人脸。CUFSF数据库共包含1 194人,对于每张人脸照均包含由画家绘制的素描图片。我们将数据集统一缩放到了125×100像素的大小,并且在训练时对图像做了归一化处理。图3给出了两个数据库的一些示例。
由于人脸区域占图像整体区域的比例在两个数据集上存在差异,为了避免该差异对模型的识别效果产生影响,在实验中对CUHK数据集进行了人脸区域识别及背景区域裁剪的预处理,通过该方法可统一人脸区域占比,避免背景区域的影响,其效果如图4所示,其中第一行为原图,第二行为预处理后的图像。
训练模型采用带动量的随机梯度下降算法,动量设置为0.85,初始学习率设置为0.001,对输入的人脸图像及其对应的素描图像做随机的裁剪、平移、翻转等处理以增加数据量,提高模型的泛化能力。实验迭代步数为4 000步,模型训练过程中的损失变化图、准确率变化图如图5所示。
图5(a)、图5(b)为训练过程中的准確率变化图,图5(c)、图5(d)为损失变化图,图5(a)、图5(c)为本文所提网络结构并结合多模Triplet Loss,图5(b)、图5(d)为传统卷积神经网络方法,网络结构选择VGG网络,Loss选择Triplet Loss。图中虚线为验证集结果,实线为训练集结果。在损失方面,两个网络相差不大,本文所提网络最终收敛值接近0.018,传统卷积神经网络收敛值接近0.025,本文所提网络略有提升,且收敛速度方面,本文所提网络由于难分数据选择策略,收敛速度更快。最终实验结果如表1所示。
由表1可知,本文所提素描图像识别方法相较于HOG特征与SIFT特征等传统算法提升明显,相较于VGG网络Loss有0.007的降低,在准确率上有0.035的提升,提升幅度较小。但是本文所提网络由于特征的多层池化提取,在运算速度上有较大提升,由此可见本文所提网络再加入本文提出的Trilplet Loss后,对素描图像对比识别效果有较大提升。
3 结 论
本文提出了一种新的基于残差网络多任务度量学习的素描人脸识别框架。该方法通过多通道的神经网络来提取素描与照片的多模态特征,其特征提取能力要强于VGG网络;同时利用多模态Triplet Loss来进一步提升异类样本间距离提高素描人脸识别的效果,与传统Triplet Loss相比,该方法也有一定效果提升,实验结果证明了该方法的有效性和优越性。
参考文献:
[1] TANG X O,WANG X G. Face sketch recognition [J].IEEE Transactions on Circuits and Systems for Video Technology,2004,14(1):50-57.
[2] TANG X O,WANG X G. Face Photo-Sketch synthesis and Recognition [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(11):1955-1967.
[3] SAMMA H,SUANDI S A,MOHAMAD-SALEH J. Face sketchrecognition using a hybrid optimization model [J].Neural Computing and Applications,2019,31(10):6493-6508.
[4] LIU D C,LI J,WANG N N,et al. Composite components-based face sketch recognition [J].Neurocomputing,2018,302:46-54.
[5] ZHANG W,WANG X G,TANG X O. Coupled information-theoretic encoding for face photo-sketch recognition [C]//Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition.Washington:IEEE Computer Society,2011:513-520.
[6] KLARE B F,LI Z F,JAIN A K. Matching Forensic Sketches to Mug Shot Photos [J].IEEE transactions on pattern analysis and machine intelligence,2011,33(3):639-646.
[7] GALOOGAHI H K,SIM T. Inter-modality Face Sketch Recognition [C]//Proceedings of the 2012 IEEE International Conference on Multimedia and Expo.Washington:IEEE Computer Society,2012:224-229.
[8] ALEX A T,ASARI V K,MATHEW A. Local Difference of Gaussian Binary Pattern:Robust Features for Face Sketch Recognition [C]//Proceedings of the 2013 IEEE International Conference on Systems,Man,and Cybernetics.Washington:IEEE Computer Society,2013:1211-1216.
[9] KLARE B F,JAIN A K. Heterogeneous face recognition using kernel prototype similarities [J].IEEE transactions on pattern analysis and machine intelligence,2013,35(6):1410-1422.
[10] TANG X O,WANG X G. Face Photo-Sketch synthesis and Recognition [C]//Proceedings Ninth IEEE International Conference on Computer Vision.IEEE,2003:687-694.
[11] LIU Q S,TANG X O,JIN H L,et al. A Nonlinear Approach for Face Sketch Synthesis and Recognition [C]//Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Washington:IEEE Computer Society,2005:1005-1010.
[12] LI J,YU X Y,PENG C L,et al. Adaptive representation-based face sketch-photo synthesis [J].Neurocomputing,2017,269(20):152-159.
[13] WANG N N,GAO X B,LI J. Random sampling for fast facesketch synthesis [J].Pattern Recognit,2018,76:215-227.
[14] ZHANG L L,LIN L,WU X,et al. End-to-endphoto-sketch generation via fully convolutional representationlearning [C]//Proceedings of the 5th ACM on International Conference on Multimedia Retrieval.New York:Association for Computing Machinery,2015:627-634.
[15] WANG N N,ZHA W J,LI J,et al. Back projection:An effective postprocessing method for GAN-based face sketch synthesis [J].Pattern Recognition Letters,2018,107(1):59-65.
[16] JIAO L C,ZHANG S B,LI L L,et al. A modified convolutional neural network for face sketch synthesis [J].Pattern Recognition,2018,76:125-136.
[17] JIANG J J,YU Y,WANG Z,et al. Graph-Regularized Locality-Constrained Joint Dictionary and Residual Learning for Face Sketch Synthesis [J].IEEE Transactions on Image Processing,2019,28(2):628-641.
[18] LIN D H,TANG X O. Inter-modality face recognition [C]//ECCV 2006:Computer Vision-ECCV.Springer,2006:13-26.
[19] YI D,LIU R,CHU R F,et al. Face matching between near infrared and visible lightimages.International [C]//Proceedings of the 2007 international conference on Advances in Biometrics.Springer-Verlag,2017:523-530.
[20] SHARMA A,JACOBS D W. Bypassing synthesis:PLS for facerecognition with pose low-resolution and sketch [C]//Conference on Computer Vision and Pattern Recognition(CVPR).IEEE,2011:593-600.
[21] MEINA K,SHAN S G,ZHANG H H,et al. Multi-view discriminant analysis [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(1):188-194.
[22] MIGNON A,JURIE F. CMML:A new metric learning approach forcross modal matching:Asian Conference on Computer Vision [EB/OL].(2019-02-07)https://www.hal.inserm.fr/GREYC/hal-00806082v1.
[23] HU J L,LU J W,TAN Y P. Discriminative Deep Metric Learning for Face Verification in the Wild [C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.Washington:IEEE Computer Society,2014:1875-1882.
[24] CAI X Y,WANG C H,XIAO B H,et al. Deep nonlinear metric learning with independent subspace analysis for face verification [C]//Proceedings of the 20th ACM international conference on Multimedia.New York:Association for Computing Machinery,2012:749-752.
[25] YI D,LEI Z,LIAO S C,et al. Deep metric learning for person re-identification [C]//Proceedings of the 2014 22nd International Conference on Pattern Recognition.Washington:IEEE Computer Society,2014:34-39.
作者簡介:蓝凌(1978—),男,畲族,广东南雄人,高中信息技术高级教师,本科,研究方向:人工智能、机器人教育;吴剑滨(1979—),男,汉族,广东英德人,高中信息技术高级教师(中级),本科,研究方向:高考、中考考务管理,信息化教学装备,信息化教学应用;侯亮(1977—),男,汉族,广东韶关人,工程师,本科,研究方向:信息技术应用、视频安防。
