商业银行线上供应链金融信用风险实证分析
2020-07-04尹思源王范宇张洋
尹思源 王范宇 张洋

摘 要:以吉林省的汽车行业作为典型研究对象,检验线上供应链服务的信用风险评价指标体系。首先运用主成分因子分析方法提取主成分,然后运用二元 Logistic 回归模型进行估计,得出商业银行在进行线上供应链金融业务的贷款决策时评价中小企业信用风险的回归方程的因子系数。最后,完成对模型的检验。
关键词:商业银行;供应鏈金融;主成因子分析;Logistic模型分析
一、引言
随着商业银行线上供应链金融业务的开展,对于其风险的评估变得越来越重要。由于线上供应链金融业务的多样化和复杂性,其信用评价体系的构建需要从多方角度进行综合考量。本课题的前期研究构建了线上供应链金融信用风险评价指标体系,并应用该体系来构建Logistic信用风险评价模型,以检测中小企业是否值得商业银行开展线上供应链金融业务。
二、线上供应链金融信用风险评价指标体系
商业银行线上供应链金融业务信用风险评价指标体系由四个一级指标,8 个二级指标,16个三级指标构成,如表1所示:
三、数据的来源及处理
本文在商业银行视角下的信用风险的实证分析基于中小企业展开。但并不是所有的上市中小企业都参与线上供应链金融。因此,首先要找出我国供应链金融业务活跃行业,然后确定上下游企业,最后再进行财务数据的收集。
目前,供应链金融业务的服务对象主要集中在汽车、房地产、钢铁等板块,并以汽车行业为典型代表(李路洋,2016),故本课题确定以吉林省的汽车行业作为研究对象。样本筛选方法如下:以供应链核心企业为中心,搜索其上下游有关的中小企业,再通过企查查、东方财富等网站获得财务相关的五年面板数据。以10家中小企业作为样本,划分为三大行业:汽车零部件行业,生产装备行业,电子控制行业。其中,核心企业控股零部件2家,其他零部件4家,生产装备行业1家,电子控制行业3家。
自变量的选取,本文样本数据来自2014-2018年度 10家中小企业的5 年的财务数据。此外,由于我国金融信贷行业信息共享程度不高,特别中小企业的经营交易数据较难获得(张沛,2016)。因此本文对定性指标采取五级量表的方式的形式进行打分。划分标准为:1到 5分,其中最高分为5分。
在因变量的选取方面,需要衡量的因变量为中小企业发生信用风险的违约概率。本文根据《企业绩效评价标准值》中的“带息负债比率值”为标准来判断中小企业的是否存在信用风险。当期带息负债比率值高于行业标准值时,我们认为它有信用风险;反之则无。当其存在信用风险时值置 1;反之置 0。据此,将50组样本数据分为17组有风险数据和33组无风险数据。
四、模型的构建
我们在上文的信用风险评价指标体系的基础上,使用SPSS 24.0进行分析。首先,运用主成分因子分析方法提取主成分。其次,运用二元 Logistic 回归模型进行估计,得出商业银行在进行线上供应链金融业务的贷款决策时评价中小企业信用风险的回归方程的因子系数。最后,完成对模型的总体检验和系数检验。
1、描述统计分析
本文将采用二元回归的Logistic模型对中小企业依托商业银行线上供应链贷款的违约概率进行计算,由于研究的主体是商业银行对中小企业进行信用评估,因此主要采用的指标大都是中小企业性质有关的。首先我们使用SPSS24.0对我们采集的指标进行描述统计分析,16个的描述统计结果如下表:
2、主成因子分析
为了避免已有的变量有较强的相关性以及同时降低本文的16个自变量中的引发的高难度的统计分析,我们将通过主成分因子分析对变量进行合成重组,用不相关的一组新的变量来进行替代处理,以免出现多重共线性的问题。
在主成分分析之前,先对样本数据进行了KMO和巴特利特检验,看是否可以进行主成分因子分析。使用SPSS 24.0我们得到的图如下所示,一般认为,KMO大于0.5可以进行主成分因子分析,0.6——0.8表示一般,0.8以上就非常合适,而低于0.5则不适合用主成分因子分析。本文得到的KMO值为0.645,表明可以进行。
接下来采用最大方差对成分矩阵进行旋转,设定以特征值大于1的为标准将主成分进行提取。得出的结果如下表所示:
从上表可以看出提取的因子总计有五个,这五个因子对方差解释度在72.878%,可以用这5个因子对其他变量进行解释并替代。下表为旋转后的成分矩阵:
从上表可以看出,销售利润率、净资产收益率2、资产增长率、利息保障倍数、应收账款周转率在因子1上有很高的载荷系数,记为F1;而销售净利率、净资产收益率2、速动比率1和信息化水平在因子2上有很高的载荷,记为F2,速动比率2和流动比率以及存货周转率在因子3上有很高的载荷记为F3;在因子4中,速动比率1和行业发展阶段以及信用水平载荷较高,记为F4;而销售增长率和信用水平、合作频率、信息化水平在因子5中载荷较高记为F5。
3、Logistic模型分析
Logistic模型作为现阶段衡量信用风险比较成熟的非线性评估模型,能够为企业风险评估提供相对准确的数据,以便于企业针对不同资产和业务做出正确及时的反应和调整。
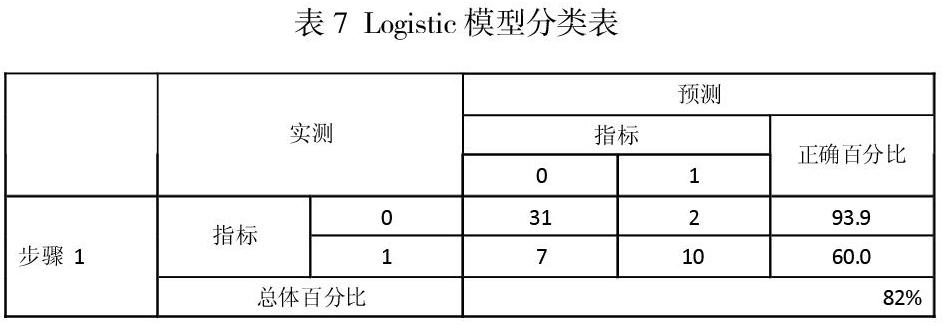
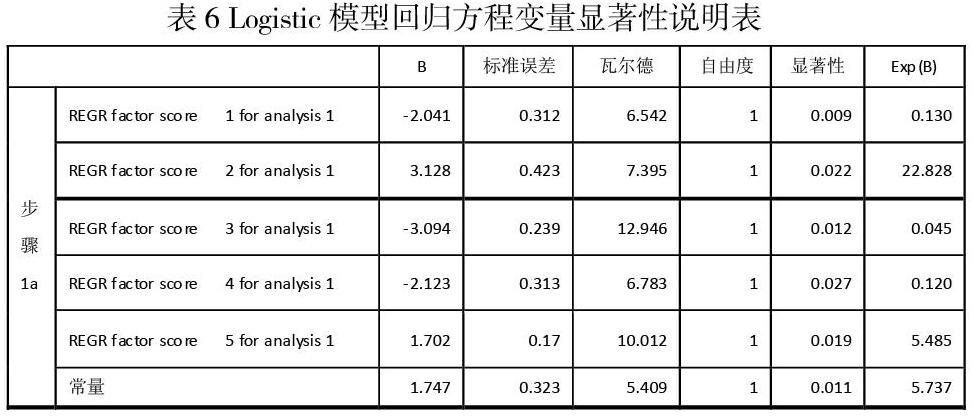
在本文的模型模拟中,我们将上文中主成分分析得出的五个因子作为自变量,将企业是否违约取值为0和1作为因变量建立Logistic模型,得出企业的违约概率P。P值等于0.5是中小企业是否存在违约信用风险的临界值,P值越接近0,说明违约的风险越小,企业的信用水平优秀,反之则企业越有可能违约。运用SPSS 24.0统计软件对主成分进行Logistic模型回归分析,结果如表6和表7所示:
根据Logistic模型的含义,由上表内容我们可以得出以下Logistic模型回归方程:
其中五个因子的回归系数分别为-2.041、3.128、-3.094、-2.123以及1.702,其绝对值大小体现因子对影响违约概率的贡献大小,其中系数数值为负的,代表其与公式中的违约概率P成负相关。
從表7中的结果可以得知,在50个样本中,对于实际中观测中33个信用良好的指标值(不同年份的不同企业),本文的模型模拟预测结果为31个无风险,准确率为93.9%;对于实际观测中风险较大的17个指标值,本文的模型模拟预测结果为10个有风险,准确率为60%;综合整体的正确百分比为82%。
五、模型检验
为了验证本文模型的正确性和合理性,模型的检验主要分为两方面。
首先是对主成分因子的显著性进行检验,本文中直接使用Wald值以及显著性来体现五个主成分因子是否合理,从表6中可以直观地看出,五个因子的显著性都明显的低于0.05,并且Wald值较高,充分说明各因子在对因变量,即违约指标的构建过程中起到十分重要的作用。
然后我们进行Logistic回归方程的显著性检验,如表8所示:
从表8中可以看出,显著性均落在非常小的数值上,远远小于0.05,证明在本文的Logistic模型在很大程度上可以代表现实中风险发生的真实情况。
六、实证结果分析结论
本文运用SPSS24.0中的二元Logistic回归模型对商业银行线上供应链金融业务进行了实证分析,得出以下主要结论:
1、本文所构建的二元Logistic模型可以稳健的评价商业银行线上供应链金融业务里中小企业发生信用违约的可能性。本文所构建四个一级指标:宏观环境、核心企业、中小企业、线上供应链金融业务都对企业的信用风险有显著的影响,五个主成分析法所提取的主成分也均可以有效衡量线上供应链金融业务中存在的违约可能性。
2、因子F1和信用风险发生的概率成负相关关系。F1中,销售利润率、净资产收益率、资产增长率、利息保障倍数、应收账款周转率符号为正,即与F1成正相关关系,与信用风险发生的概率成负相关关系。这些指标的取值越大,则中小企业发生信用风险的概率越小,该企业信用水平越高。
3、因子F2和信用风险发生的概率成正相关。F2中,销售净利率、净资产收益率、速动比率和信息化水平符号为负,和信用风险发生的概率成负相关关系。这些指标的取值越大,则中小企业发生信用风险的概率越小,该企业信用水平越高。F2中所提取的大部分指标都反映了核心企业在构建信用评价体系中的重要性。
4、因子F3和信用风险发生的概率成负相关关系。F3中,速动比率和流动比率以及存货周转率的符号为正。这些指标的取值越大,则中小企业发生信用风险的概率越小,该企业信用水平越高。F3中的指标均反映了偿债能力与信用风险有很大的关联。
5、因子F4和信用风险发生的概率成负相关关系。F4中,速动比率和行业发展阶段以及信用水平符号为正。这些指标的取值越大,则中小企业发生信用风险的概率越小,该企业信用水平越高。F4中的指标大部分反映了宏观经济环境和中小企业信用水平对于信用风险的影响。
6、因子F5和信用风险发生的概率成正相关关系。F5中,销售增长率和信用水平、合作频率、信息化水平符号为负。这些指标的取值越大,则中小企业发生信用风险的概率越小,该企业信用水平越高。F5中的指标大部分衡量了线上供应链金融业务指标对于信用风险所带来的的影响。
参考文献:
[1]李路洋.线上供应链金融信用风险评价研究[D].天津:天津财经大学,2016:55-57.
[2]张沛.线上供应链金融平台合并对融资效率的影响[D].上海:东华大学,2016.
