Combining User-Driven Social Marketing with System-Driven Personalized Recommendation for Student Finding
2020-06-04ZHANGMingyu张明玉
ZHANG Mingyu(张明玉)
School of Management, Putian University, Putian 351100, China
Abstract: Student selection is of crucial importance for supervisors who are choosing students for postgraduate studies or research projects. Due to the challenge of asymmetric information, it is difficult for them to find suitable candidates. The existing methods do not work so well in the web 2.0 context which is inundated with vast online information. In order to overcome the deficiency, a research social network enhanced approach is proposed to provide decision support. It appeals to supervisors to adopt the proposed user-driven social marketing strategy. Meanwhile, this study mainly presents a system-driven personalized recommendation approach to support supervisors’ decisions of student selection. The proposed method distinguishes supervisors based on their co-author networks to extract their potential preferences of collaboration styles. Subsequently, corresponding recommendation strategies are employed to provide personalized student recommendation services for targeted supervisors. A prototype is implemented on ScholarMate which provides online communication channels for researchers. A user study is conducted to verify the effectiveness of the proposed approach. The results enlighten designers to consider the differences among different users when designing recommendation strategies.
Key words: student finding; user-driven social marketing; system-driven personalized recommendation; collaboration style; research analytics framework
Introduction
According to the statistical data in Ministry of Education of China(2017), there are 806 000 new students pursuing postgraduate studies and 400 000 supervisors who are eligible to accept students for postgradfuate studies. In the education field, students/supervisors should firstly select a suitable supervisor/student in order to start a student-supervisor relationship. Conventionally, a supervisor usually selects students among the ones who proactively contact him. Alternatively, a supervisor can show intentions to the students whom he prefers to after entrance interviews. Supervisors are suffering from the difficulty of finding suitable students due to the challenge of asymmetric information.
In extant research studies, various methods are employed to match students with supervisors, for example, multiple criteria decision methods[1-2]from Dattaetal.[3], generic algorithm based approaches from Mosharraf and Taghiyareh[4], analytic network process methods from Momenietal.[5], and analytic hierarchy process methods from Ray and Marakas[6]. However, current student selection approaches are passive for supervisors and they require supervisors to do a lot of comparison work among different criteria, in particularly, the proposed solutions from the studies of Ray and Marakas[6]and Momenietal.[5].
Hence, a research social network enhanced approach is presented to facilitate supervisors’ puzzles of student finding. It combines user-driven social marketing strategy with a system-driven personalized recommendation approach[7-9]for student selections. Registered users are encouraged to conduct self-promotion through updating their own dynamic profiles, adopting suggested search engine optimization (SEO) keywords from the system to represent their research expertise, joining recommended relevant groups by the system. It encourages users to be active to edit their profiles and interact with other researchers through social activities on the system, which can provide the system with more valuable information to conduct further recommendation services. The users are willing to do so when they know that they can receive more precise and personalized recommendation service[10]. Meanwhile, the system-driven personalized recommendation is an active function of the research social network. Their organic combination can help to facilitate the challenge of suitable student finding.
1 Related Works
1.1 Student-supervisor selection
In the existing literature, evidence shows that the “style war”[11]will occur when the compatibility between a supervisor and a student is poor. The match/mismatch plays a crucial role in students’ achievements[12-14], which is partially a reason to explain the high failure rates of research dissertations and dropout phenomenon, especially in the social science area[14].
Traditionally, higher education institutions make the decision of student-selection. Multiple tests are developed as admission tools to deal with it. For example, the United Kingdom Aptitude Test was developed for medical student selection in 2006[15]. When students are accepted by a university, they are usually evaluated by several parameters facilitating supervisors to make the decision. These common parameters are grade point averages (GPA), research interests, the qualities of undergraduate universities, specific skills, and passed courses[5]. Researchers find that supervisors tend to accept students who share high compatibility with them[4, 16]. Mosharrafetal.[16]developed an advisory agents modeling system in University of Tehran to enhance the decision-making of student-supervisor selection. Mosharraf and Taghiyareh[4]proposed an approach based on the genetic algorithm for student-supervisor assignment. There are some other methods used to facilitate the process of student-supervisor selection, such as a strategic approach adapted from multiple criteria decision methods[3], analytic network process methods[5], and analytic hierarchy process methods[6]. They are passive methods and require involved users to compare the importance of different criteria.
1.2 Recommendation systems in similar situations
In the perspective of recommendation techniques, common methods used in recommendation system are content-based (CB) methods[17], collaborative filtering (CF) methods[18]and hybrid (HYB) methods[19]. The principle of the CB method is recommending items which are similar with the given item in the content information[17]. In contrast, the CF method which is regarded as a user-to-user correlation method, searches users who share similar tastes with the target user, and then items which similar users like are recommended to the given user[18]. the CF method can be divided into memory-based and model-based methods. Additionally, the HYB method is a combination of the CB method and the CF method[19].
Studies on recommendation systems can be divided into item recommendation and people recommendation. On the one hand, items can be movies, products, music, news[20]and so on. On the other hand, many researchers are attracted by the studies on people-to-people recommendation. There are various articles studied collaborator recommendation[21]and expert recommendation. Meanwhile, some studies put forward feasible approaches for similar scenarios such as recruitment[22], helper finding[23], and online dating[24].
In the prior studies, most of the studies offer all users with the same recommendation strategy, which neglects users’ differences in characteristics. Hongetal.[25]designed a job recommendation system which automatically provided different groups of users with different recommendation strategies. In this study, supervisors may prefer different kinds of recommendation strategies to provide student recommendation. A good recommendation system should consider users’ differences and select personalized one for each user.
1.3 Exploration and exploitation
The concepts of exploration and exploitation introduced by March[26]are the ambidexterity of organizational learning orientation, namely, exploration for new knowledge, skills and processes, while exploitation of existing ones[27]. Several studies demonstrate that the diversity of team members will influence firm performances. The members are classified into two different types: newcomers and old-timers. Newcomers are the ones who come with new knowledge and always figure out a problem in a novel perspective. Therefore, they can generate creative solutions and are tending to foster exploration. Old-timers are the persons who stick to completely refine the existing knowledge to deal with problems[28].
In the context of co-author networks, exploration behavior means preferring to collaborate with different researchers and exploitation refers to cooperate with same scholars. Apparently, some researchers prefer to broaden the perspectives by collaborating with different scholars, while some researchers prefer to deepen the common understanding with the same collectives. Lietal.[29]utilized a co-author diversity index to measure the preferred collaboration style from the historical co-author network of the target researcher.
Student-supervisor relationship is regarded as one special type of collaboration relationship. Hence, different preferences of collaboration styles should be paid attention to. However, it is overlooked in the existing recommendation approaches.
2 Proposed Method
2.1 Overview of the proposed method
In this study, a research social network enhanced approach is proposed for student finding. The brief framework is introduced in Fig. 1. It integrates the user-driven social marketing strategy and the system-driven personalized recommendation approach to conduct student finding for target supervisors. Users are encouraged to leverage the presented user-driven social marketing strategy to socially promote themselves. For example, a researcher can edit his/her profile to assure the up-to-date information, upload the full-text publications to guarantee the complete information, show research expertise by adopting the suggested SEO keywords which are hot ones and can be easily searched, and join relevant recommended groups to promote himself/herself. Previous studies indicate that users are willing to provide more information when they know that they will receive more accurate and personalized recommendation service if they can provide more correct information[5]. Meanwhile, the system provides every target supervisor with personalized student recommendation by adopting a cluster-based approach which is based on the subjective expected utility (SEU) theory[30].
In light of the SEU theory[30]shown in Fig. 2, it posits that people make decisions in uncertain circumstances based on the product of subjective value probabilityπiand utility. Individuals show differentπitowards different candidates. In the context of student-supervisor selection, the main factor which would be considered is knowledge background mainly including self-claimed research interests and acquired knowledge. Some supervisors prefer to choose the student whose knowledge background is consistent with their research expertise. Meanwhile, some supervisors do not pay so much attention to the factor of knowledge background and prefer to collaborate with the ones whose knowledge backgrounds are not completely consistent with their research expertise.

Fig. 1 Framework of the proposed solution
Therefore, a novel approach is proposed based on these considerations. Firstly, in order to extract a supervisor’s preference of collaboration styles, his historical co-author diversity is mined. Based on the degree, the target supervisor is distinguished with which cluster he should belong to. Exploitation groups are the ones who prefer to utilize their existing knowledge. They prefer students whose knowledge backgrounds are consistent with their expertise. The content-based method is employed to provide recommendations for this group. Exploration groups are the ones who prefer to utilize new knowledge to innovate. Hence, we apply the collaborative filtering method which does not mainly focus on the consistent knowledge background but pays enough attention on other factors. Finally, the hybrid method is leveraged for the moderation group.

Fig. 2 Theoretical support for the proposed method
The framework of the proposed personalized recommendation method is shown in Fig. 3. Firstly, the data are prepared and processed. A target supervisor’s co-author network is extracted from his historical publications. Secondly, the supervisors are measured by simple K-means algorithm[31]. They are classified into three different groups which are respectively named as exploration, exploitation and moderation groups. Thirdly, respective recommendation strategies are employed for different groups. Finally, top-nrecommendation results are generated. The satisfaction feedback of the respective results is compared in the end.
In conclusion, the hypotheses are summarized in Table 1 and they will be verified in the evaluation section.

Table 1 Summary of testable hypotheses
2.2 Clustering process
According to the target supervisor’s published articles, the information of his/her co-author network is extracted. As shown in Eq. (1), the collaboration diversity index CDI[29]is utilized to measure the supervisor’s preferred collaboration style. Based on the values, supervisors are grouped into different clusters by simple K-means algorithm.
(1)

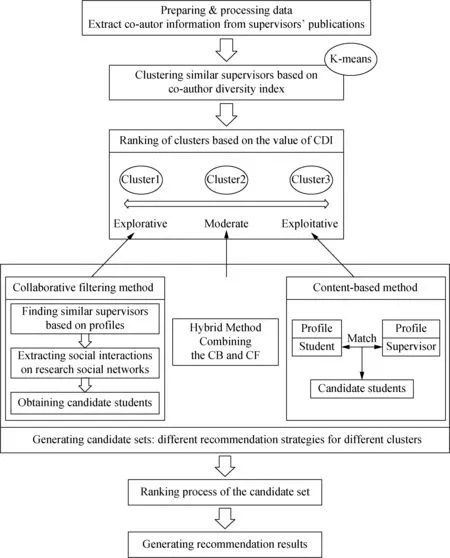
Fig. 3 Framework of the proposed personalized recommendation method
2.3 Recommendation strategies
Different recommendation strategies are employed in different groups. There are three recommendation approaches: the CB recommendation method, the CF recommendation method, and the HYB recommendation method.
2.3.1 CB recommendation method
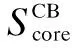
(2)
where,
(3)
(4)
(5)
Dt(j)represents the corresponding document of a supervisor; a query contains keywordsq1,q2, ...,qn;qkis thekthindividual keyword in the queryQs(i);nis the number of keywords;Wkis the weight of thekthquery and it is measured by inverse document frequency IDF(qk);Nis the total number of supervisors’ documents;n(qk) is the number of documents which contain the keywordqk; Dfkdenotes the frequency of the keyword occurred in the document; Qfkrepresents the frequency of the keyword occurred in the query; Dl is the length of the documentD; avgDl is the average document length;m1,m2andbare free parameters.
2.3.2 CF recommendation method
According to the main idea of the CF method, supervisors who are similar with the target supervisor are firstly found. Then, the students which the similar supervisors prefer are traced according to their interaction reflected by the social activities on research social networks.
Similarities among supervisors are calculated based on the information of their departments, taught courses, self-claimed research fields, and publications. The calculation process is similar with Eqs. (2)- (5), and the similarity score is shown as
(6)
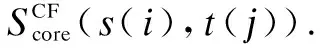
(7)
where,m=1, 2, 3 (1 means endorse, 2 means share, and 3 means like);Ss(i)orSt(j)shows social activities of the student or the supervisor;nm(s(i),t(j)) is the number of social activitymoccurred between supervisort(j) and students(i).
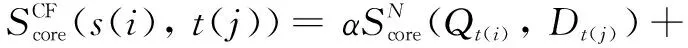
(8)
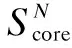
2.3.3 HYB recommendation method
The HYB method is a combination of the CB method and the CF method. Two candidate sets are generated according to the CB method and the CF method respectively. Subsequently, CombMNZ[33], a score-based fusion method, is utilized to aggregate the two lists.
(9)
where,L1(i) orL2(i) is the recommended candidate list by the CB method or the CF method. Ifs(i) is on bothL1(i) andL2(i),τequals 2; ifs(i) is only on one list,τequals 1; otherwise,τequals 0.
2.4 Ranking process
The filtering step generates the candidate students with a final score from the filtering process. The final ranking score will be calculated at this stage. Research productivities are measured by the quality and the quantity of published papers which a student produces[34]. It is admitted that few of new students publish papers. Therefore, the initial value is set as 1 to facilitate the calculation process. Furthermore, the weight of SCI/SSCI journal papers is set higher than the other kinds of papers. It is shown as
(10)
ri(Pub)=1+λxpi+ypi,
(11)
where,ypiorxpiis the number of publications published on SSCI/SCI journals or non-SSCI/SCI journals;λis the relative weight of papers published on SSCI/SCI journals.
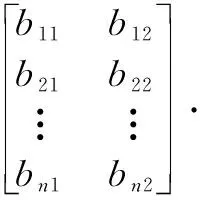
At the ranking stage, the candidate students are ranked by the well-known entropy method[35]. We get a decision matrix (12) representing respective scores from two aspects of every candidate student andnrepresents the number of candidates.
(12)
Firstly, the data is normalized (so that each column is sum-to-one), and matrix (13) is obtained.
(13)
Subsequently, the entropy value is calculated by expression (14).
(14)
Then, letdj=1-Ej(1≤j≤m) wheremmeans the number of criteria (here,m=2). The normalized weight of thejthattribute is obtained through Eq. (15). The final ranking scoreFiis calculated by Eq. (16).

(15)
(16)
3 Evaluation
3.1 Experiment design
An offline study is conducted to evaluate the performance of our proposed method. The performances of different recommendation strategies are compared based on supervisors’ satisfactions towards the top-nrecommended results. It is discussed that whether the CB method is mostly suitable for the exploitation group, the CF method is mostly suitable for the exploration group, and the HYB method is mostly suitable for the moderation group.
An offline experiment is conducted in a university in China. There are two sections in the user study: one section of data collection and candidate recommendation, and the other section of feedback collection and satisfaction analysis.
Firstly, the data of students and supervisors are collected from their homepages on ScholarMate. A student’s information includes undergraduate major, courses taken during undergraduate study, research interests represented by standard keywords, publications if applicable, and preferred references. Simultaneously, the information of target supervisors are collected as well. The information of their publications are collected from ScholarMate and are supplemented by the SCOPUS database manually. Furthermore, the information of their social interactions on ScholarMate are obtained from website backend of ScholarMate.
Then, three candidates are generated for every target supervisors by each recommendation strategy. There are 90 supervisors and 148 students participated in the study. In the section of feedback collection and satisfaction analysis, the recommended results are rearranged before sending to supervisors for collecting satisfactions. They are asked to show their satisfactions by 1-5 Likert scale, where 1 represents the lowest degree of satisfaction and 5 represents the highest degree. In the end, 46 valid users’ satisfaction feedbacks are collected and the respond rate is 51%.
3.2 Evaluation metrics
When measuring the performance of the proposed methods, on the one hand, the satisfaction points is paid attention to. On the other hand, we are eager to know whether the methods can preferentially recommend the candidate students with higher satisfaction points for the target supervisors. Therefore, we utilize the normalized discounted cumulative gain nDCG which not only considers users’ satisfaction points but also takes the recommendation orders into account[36]. The details of nDCG are shown as
(17)
where,
nis the number of recommended students, andn=3 here; |U| shows the total number of supervisors who finally participate in our user study;sj(i) is the value given by thejthsupervisor for recommended studenti; max DCGj@nis the DCGjwhen the recommended items are in an ideal positions. For example, the recommended students for a target supervisor are (s1,s2,s3) ranking in order, while the corresponding satisfactions are (3, 6, 5). Therefore, the ideal rank should be (s2,s3,s1) in order.
3.3 Data analyses
Firstly, the target supervisors are measured by CDI which is reflected by their own co-author networks. Secondly, they are automatically divided into three groups based on the simple K-means according to CDI, which are shown in Fig. 4. In detail, 13 supervisors are distributed into the exploitation group, 25 ones are distributed into the moderation group, and 8 ones are distributed into the exploration group.
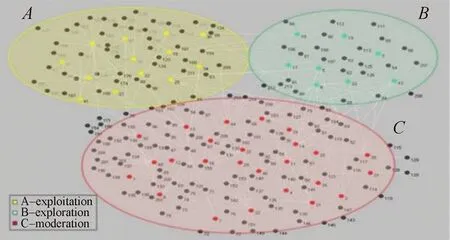
Fig. 4 Grouping the target users based on CDI
Then, we compare user satisfactions of the results from three different methods when the target supervisors are not grouped. Additionally, user satisfactions of the results from the different methods are compared in the three different groups. The final results are illustrated in Fig. 5.
When the target supervisors are not divided into groups, it shows that they prefer the CB method and the HYB method based on their satisfactions on the recommended candidates. There are no differences between the user satisfactions of the CB method and those of the HYB method. Moreover, the CF method is not as good as the other two methods, especially when recommending one or two candidates. In the exploitation group, nDCG@1, nDCG@2 and nDCG@3 of the CB method are 0.52, 0.68, and 0.84 respectively. The results show that the target users prefer the CB method than the other two ones. In the moderation group, it shows that the results from the HYB method satisfy the target users much better than those from the other two methods. For example, the values of the CB method, the CF method and the HYB method are 0.74, 0.64, and 0.86 respectively when measuring nDCG@3. In the exploration group, the results of the three methods are not significantly divergent, especially when measuring nDCG@3. nDCG@3 of the CF method is 0.78, and those of the HYB method and the CB method are 0.74 and 0.71 respectively, which are not significantly different.
Fig. 5 Contrastive results of the different methods in different circumstances of: (a) all users;(b) the exploitation group; (c) the moderation group; (d) the exploration group
Additionally, we measure whether there are significant differences between every two methods by paired t-test with the help of SPSS 20 software. Thep-values in Table 2 indicate that most of them are statistically significant. In detail, the CB method and the CF method are statistically different when the user satisfactions are measured without grouping. Thep-value between the CF method and the HYB method is also statistically significant. However, thep-value is not significant when measuring the difference between the CB method and the HYB method.
Subsequently, we respectively do the paired t-test for the methods applied in different groups. In the exploitation group, the results of the CB method and the CF method are statistically different, and those of the CB method and the HYB method are also significantly different. But, it shows that the results of the HYB method and the CF method are not significantly different as thep-value is not statistically significant. In the moderation group, the results of three methods are all pairwise different because all thep-values are statistically significant. In the exploration group, there is merely onep-value is significant. It represents that they are different between the results from the CB method and those from the CF method. There are no differences between the results from the CB method and these from the HYB method. The results of the CF method are not significantly different with those of the HYB method as well.

Table 2 Paired t-test for different methods in respective circumstances
Note: * means thatp-value is significant at α≤0.05, ** means thatp-value is significant at α≤0.01, and *** means thatp-value is significant atα≤0.001.
When the supervisors are not grouped, it shows that the results of the CB method and the HYB method are better than these of the CF method in Fig. 5. But we cannot find the extreme differences of the result of the CB method and that of the HYB method from Fig. 5. Furthermore, we find that the results of these two methods are not significantly different according to Table 2. In the exploitation group, thep-value is not statistically significant when measuring the differences between the results of the HYB method and those of the CF method. We can see that the results of the CB method are different with those of the other two from Table 2 and they are much better than those of the other two from Fig. 5. In Table 2, it shows that the results of the every two methods are different in the moderation group. In the exploration group, only the results of the CB method and those of the CF method are different, which is consistent with the findings from Fig. 5.
In Table 3, we summarize the testing results of our mentioned hypotheses. Most of them are verified and the hypothesis 3 is partially proved.

Table 3 Evaluation results of the hypotheses
Note: *means thatp-value is significant at α≤0.05, ** means thatp-value is significant atα≤0.01, and *** means thatp-value is significant atα≤0.001.
3.4 System implementation
The research social network is utilized and an intelligent approach is proposed to facilitate the student-supervisor selection. It aims to bridge the gap between students and supervisors as shown in Fig. 6. Currently, the proposed approach is implemented on ScholarMate. As shown in Fig. 6, the system guarantees the authenticity of all online publications which are typical to profile researchers. Firstly, it assures the authenticity of all confirmed publications by checking authors’ names, research fields, registered emails and so on. Simultaneously, users can self-claim their research fields by selecting relevant keywords among suggested standard ones. Secondly, each user on the website has a structured and personalized profile. Thirdly, users can interactively communicate with each other through several social activities, such as liking others’ works, endorsing their research fields, and sharing articles. Finally, it facilitates the communication between students and supervisors and aims to enhance the process of student-supervisor selection. Figure 7 shows the interface of the student-supervisor recommendation service on ScholarMate.

Fig. 6 Research social networks bridge the gap between students and supervisors
Fig. 7 Interface of student-supervisor recommendation service
4 Conclusions
In conclusion, a research social network enhanced approach is put forward to provide student recommendation service for supervisors. The presented approach combines the user-driven social marketing strategy and the system-driven personalized recommendation method. The former marketing strategy encourages users to promote themselves on the research social network. The later recommendation method is intelligently provided by the system for each supervisor who needs the student recommendation service.
According to the user-driven social marketing strategy, users should edit their profiles to keep the up-to-date information, adopt the suggested popular SEO keywords, and join recommended relevant groups to establish the social relationships and so on. Meanwhile, in terms of the system-driven personalized recommendation method, a target supervisor’s preference of collaboration style is mined from the diversity of his historical co-authors at the initial stage. Therefore, he is classified into the exploration group, the exploitation group, or the moderation group. Then, different strategies are applied to do recommendation for different groups. The CB method is employed for the exploitation group. The CF method is utilized for the exploration group. The HYB method is applied into the moderation group. In the user study, most of the hypotheses are verified. Therefore, designers should consider the differences among different users when designing recommendation strategies. Finally, it utilizes the information of social interactions reflected by social activities on research social networks which is a novel communication channel for researchers.
杂志排行

Journal of Donghua University(English Edition)的其它文章
- Acoustic Performance of Green Composites for Chinese Traditional Percussion Drums
- Fabrication and Characterization of Polypyrrole/Polyurethane/Polyamide/Polyamide Yarn-Based Strain Sensor
- Friction and Wear Behaviors of C/C-SiC Composites under Water Lubricated Conditions
- Performance Analysis of Cushioned Sport Soles with Plantar Pressure Test
- Existence Criterion of Three-Dimensional Regular Copper-1, 3, 5-Phenyltricarboxylate (Cu-BTC) Microparticles
- Generative Adversarial Network with Separate Learning Rule for Image Generation