创业板上市公司财务危机的识别与预警
2020-02-03吴庆贺唐晓华林宇
吴庆贺 唐晓华 林宇



【摘要】以我国创业板上市公司为研究对象,针对公司不同财务状况构成的非均衡样本特性,运用Twin-SVM来构建财务危机预警模型。实证结果表明:在Twin-SVM模型的构建过程中,RBF核函数展示出比Linear、Polynomial、Sigmoid、Wavelet核函数更为优异的预测性能;与改进的ODR-ADASYNSVM、BP神经网络、Bayes分类法和K近邻法相比,Twin-SVM不仅在预测精度上高于其他模型,而且在预测稳健性上也显著更为优越,在制造业与信息传输、软件和信息技术服务业两个分行业的泛化性能也显著优越于其余模型。
【关键词】财务危机预警;Twin-SVM;创业板;上市公司;非均衡样本
【中图分类号】F275【文献标识码】A【文章编号】1004-0994(2020)02-0056-9
【基金项目】国家自然科学基金项目(项目编号:71771032);四川省应用基础研究项目(项目编号:2017JY0158)
一、引言
上市公司作为实体经济的典型代表,一旦发生财务危机,不仅自身会遭受巨大损失,让投资者利益严重受损,甚至可能对整个平稳发展的经济社会造成巨大冲击[1,2]。只有科学地展开对我国上市公司财务危机识别和预警的研究,才能及时发现财务危机的诱因并采取有效的防范措施,避免造成不可挽回的损失。因此,探讨并建立一个合理有效的财务危机预警机制,无论是对我国经济还是对上市公司发展而言,都意义重大。
特别是对我国创业板上市公司而言,创业板是专门向高科技、高成长企业提供融资途径和成长空间的证券交易市场,但是由于我国创业板存在着上市门槛低、企业股本小、抵御风险能力弱等问题,加上创业板市场成立时间较短,相应的法律法规以及政策制度还不够完善,公司上市后业绩严重下滑的现象频频发生[3]。基于以上因素,我国创业板上市公司面临较大的财务风险且较易发生财务危机。为使我国创业板健康稳定地成长并有效地辅助公司经营者及监管层防范和化解风险与危机,建立科学的创业板上市公司财务危机预警模型,是一个值得关注的问题。
财务危机预警长期以来都是学术界关注的焦点与热点,相关文献比较多见。有学者运用单变量模型对财务危机预警展开研究[4],但一家企业的财务状况不是仅用一个指标就可以评判的,因此这类模型逐渐被其他模型所取代;其后有学者引入多元变量模型[5],但多元变量模型的前提条件过于严格,要求解释变量与被解释变量呈线性关系,各变量间相互独立,且要求残差服从正态分布;也有学者采用Logistic回归模型进行财务危机预警研究[6-8],但Logistic回归模型一般用于解决二分类问题,也要求解释变量与被解释变量存在线性关系;而后有学者采用人工神经网络模型进行财务危机预警研究[9],该类模型采用的是局部搜索的优化方法,容易造成局部极小的问题。令人欣慰的是,Vapnik[10]提出的支持向量机(Support Vector Machine,SVM)恰好具有解决以上模型存在问题的突出优势,具有更为优异的学习能力和泛化推广性能,其一经提出便受到学术界众多学者青睐并被广泛运用于风险预警等研究中[11,12]。
必须指出的是,无论是在医学领域、信息领域还是金融领域,样本集往往呈现偏态的特征,即两类样本数目往往是不等的。这种非均衡样本所训练出的模型得到的分类结果会具有明显的偏向性,即对多数类样本预测准确率高,对少数类样本预测准确率较低。而传统SVM的良好预测性能往往要求两类样本是均衡的[12,13],但是发生财务危机的上市公司毕竟只是少数,财务正常的上市公司占多数,这就必然导致两类样本不均衡,从而使得SVM所构建的分类超平面会偏向财务危机样本一边,进而导致模型的预测效果不尽人意。
于是,有学者从数据层面和算法层面对非均衡样本进行了研究。欠采样(Under-sampling)和过采样(Over-sampling)是常用的将非均衡样本处理为均衡样本的方法,但是欠采样方法在删除多数类样本时可能会将影响分类的有效信息误删,最终造成预测效果不理想。过采样则是通过增加少数类的样本使两类样本数目达到均衡,但增加的样本可能造成少数类样本的相互重叠,也未必能进一步提升模型预测结果的准确性[13]。而后有学者将处理非均衡样本的方法与SVM相结合进行研究,如衣柏衡等[14]提出了改进的SMOTE与SVM相结合的方法,在面對非均衡样本时,生成一定数量的少数类样本来进行平衡处理,但令人遗憾的是,利用SMOTE对少数类样本进行处理,无法消除多数类样本中的噪声信息,容易造成新生成样本重叠的问题[15]。林宇等[12]将自适应合成抽样方法(ADASYN)和逐级优化递减欠采样方法(ODR)与SVM相结合,构建ODRADASYN-SVM模型对极端金融风险进行了预警研究,但这种做法可能会破坏原始数据的结构且违背研究的可重复性原则,特别地,由于该方法的训练样本与原始数据有偏,其模型的解释性也容易受到质疑[16]。
令人惊喜的是,Twin-SVM[17]的提出从根本上解决了非均衡样本的问题,Twin-SVM不必增加或减少原始样本,而是为上市公司财务正常样本与财务危机样本分别构造一个分类超平面,使每个分类超平面离本类样本点尽可能近而离另一类样本点尽可能远,将一个大的分类问题转换成求解两个小的分类问题,从而约束条件数目将减少,模型训练时间缩短,Twin-SVM的分类灵活性及计算性能将大大提高,从而行之有效地克服了传统SVM的根本缺陷[11,18]。因此,本文引入Twin-SVM对创业板上市公司财务危机进行预警研究。
从目前所掌握的文献来看,对于Twin-SVM的研究主要集中在算法的优化改进、图像识别以及金融风险的预警等方面,并未发现将其应用于财务危机预警的实证研究;在Twin-SVM的核函数选择上,以往学者大多是选择RBF,而未对不同核函数下Twin-SVM模型的预测性能进行探讨;以往的文献在对创业板上市公司进行财务预测时,并没有针对创业板中的分行业进行模型的泛化性能探讨。
基于以上分析,本文以我国创业板上市公司为研究对象,基于扣除非经常性损益后的净利润和净资产增长率构建财务危机的识别方法,从而确定了财务正常和财务危机样本。对所选取的31个财务指标,运用显著性检验、相关性分析、共线性诊断和逐步回归提取出最具解释能力的财务指标作为模型的最终输入变量,以此避免维数灾难和过拟合的问题。首先,对不同核函数下的Twin-SVM模型进行预测性能对比来确定最优的核函数;然后采用分类准确率、几何平均正确率G、少数类的度量值F对在不同样本划分比例下的Twin-SVM、ODR-ADASYNSVM、BP神经网络、Bayes分类法以及K近邻法的预测精度及稳健性进行对比,运用配对样本T检验对各模型预测精度的差异性进行显著性检验;最后,对制造业与信息传输、软件和信息技术服务业两个分行业下不同预警模型的泛化性能进行对比研究。希望能为公司经营者以及监管层防范和化解风险与危机提供良好的借鉴,为投资者减小损失提供合适的操作工具。
二、研究方法
2.财务危机识别方法。构建财务危机预警模型的关键之一在于如何识别上市公司是否发生财务危机。从主板和中小板来看,Geng等[19]、Chu等[20]将被ST和非ST作为是否陷入财务危机的识别标志,但是创业板不同于主板和中小板存在“ST”和“ST”这样的过渡阶段,对于存在财务危机的企业直接作暂停上市处理。因此,在对创业板上市公司进行财务危机预警研究时,不能继续沿用以往的标准。从已有的研究创业板上市公司财务危机预警的文献来看,岑慧[21]以四种情况作为界定标准:一是净利润为负,二是净资产为负,三是审计报告为非标意见,四是营业利润增长率为负;宋宝珠[8]以两种情况作为界定标准:一是连续两个年度净利润为负,二是净资产在最近一个会计年度为负。
由此,本文发现以往学者在识别创业板上市公司财务危机时往往以净利润和净资产作为标准,但是仅将净利润为负作为界定标准,缺少一定合理性。因为一些企业虽然经营困难、陷入财务危机,但是因获得政府或者银行补助而得以继续生存,因此,本文将扣除非经常性损益后的净利润作为净利润的替代标准。最终本文将陷入财务危机的识别标准界定为:一是最近一个会计年度扣除非经常性损益的净利润为负;二是最近一个会计年度期末净资产增长率为负。
对于一家上市公司,一旦同时达到上述两个门槛,则被识别为财务危机样本;反之,则被识别为财务正常样本。
3.财务危机预警模型的性能评估方法。为了更全面地评估Twin-SVM财务危机预警模型的综合性能,不仅要评估模型的预测性能是否优越,还要对模型的稳健性进行研究,考察其在样本划分比例不同的情况下是否依然能保持优越的预测性能。本文首先运用传统的分类正确率对总体的分类准确率进行考察,再进一步借鉴相关文献[15],运用针对非均衡样本的评估指标对Twin-SVM财务危机预警模型进行预测精度的评估。分类正确率即总的预测正确的样本数占总体样本数的比例,针对非均衡样本分类的评估指标则是几何平均正确率Gmean和少数类的度量值Fmeasure(以下用G和F分别代替Gmean和Fmeasure)。G和F评估指标的构建过程具体阐述如下:
设TP和TN分别表示将财务危机样本和财务正常样本预测正确的数量,FN和FP分别表示将财务危机样本和财务正常样本预测错误的数量。混淆矩阵表示对测试集进行预测分类的结果(见表1)。
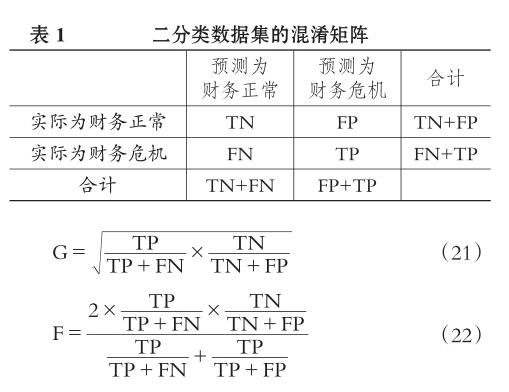
于是,通过计算式(20)、(21)和(22)中的分类准确率、几何平均正确率G及少数类的度量值F,本文就能对所构建的Twin-SVM模型的预测性能进行准确的评价。G值越大,表示对财务正常和财务危机两类样本的综合预测性能越优异;F值越大,表示对财务危机样本的预测精度越高,反之亦然。
三、实证结果与分析
1.样本选择及数据处理。由于本文在设计创业板上市公司财务危机预警模型时,选择滞后状态指标一个警度时差,且根据创业板股票上市规则,最近连续亏损三年的公司会被进行退市处理,因此早期的预测就能够保证企业在应对危机时抓住有利时机,采取有效措施,最大限度地减少相关损失。为保证对上市公司财务危机预警的前瞻性与时效性,本文對2018年前三年即2016 ~ 2018年的警度进行研究,从而应选择2015 ~ 2017年的数据。在剔除了数据存在缺失的样本后,共得到655家样本公司。从三年的数据样本中分别随机抽取等比例的数据组成训练集和测试集,经统计发现三年样本中财务正常样本和财务危机样本的比例超过10∶1,构成严重的非均衡样本。本文所有数据都来源于Wind数据库。
2.特征指标的筛选。对引发财务危机的特征指标进行准确提取,是构建财务危机预警模型的重要步骤。由于在对模型的输入变量即财务指标的选取上暂未得到定论[22],因此本文借鉴以往研究文献[19,23]并参考公司业绩综合评价指标体系,从盈利能力、现金流量、营运能力、成长能力和偿债能力五个方面挑选出31个财务指标(模型的特征指标见表2)。
为筛选出能显著区分危机状态的财务指标,本文借鉴相关文献[12,23,24],分别对符合正态分布和非正态分布的变量采用T检验和U检验,将未能通过显著性检验的指标(X12)予以剔除。进一步,为避免指标间的共线性问题对模型的拟合效果产生影响,本文借鉴相关研究[23,25],运用相关性分析和共线性诊断对30个留存变量进行分析,最终剔除了6个指标(X2、X3、X7、X8、X27和X28)。为更近一步提取出对状态指标变量有更强解释力的特征变量,借鉴以往学者的研究[22],采用逐步回归(Stepwise Regression)对数据进行进一步的处理,最终将24个特征指标约简为7个特征指标,分别为:X1(平均净资产收益率)、X11(全部资产现金回收率)、X16(非流动资产周转率)、X17(固定资产周转率)、X18(应收账款周转率)、X21(营业总收入)和X26(流动比率)。至此,已完成对创业板上市公司财务危机预警模型特征指标的筛选。
3.不同核函数下Twin-SVM模型的预测性能对比。基于不同核函数的Twin-SVM财务危机预警模型具有不同的预测性能,倘若无法确定最优的核函数,就无法获得性能优越的预警模型。本文采用5折交叉验证法(Cross Validation,CV)下G值、F值以及分类准确率对Twin-SVM创业板上市公司财务危机预警模型的最优核函数进行确定。实验结果见表3。
從表3可看出,依次将5种核函数与Twin-SVM模型结合后,RBF核函数的G值(0.6681)和F值(0.3586)显著高于其余4种核函数。虽然RBF核函数的分类准确率(0.8616)略低于其余核函数,但是究其原因是其余核函数所构成的模型将大量财务危机样本错误预测为财务正常样本,财务危机样本仅占总体样本的一小部分。而把财务危机样本错误预测为财务正常样本所产生的危害是远大于把财务正常样本错误预测为财务危机样本的。因此,将RBF核函数与Twin-SVM结合后的预测性能是显著优于其余核函数的,本文采用RBF作为Twin-SVM的核函数。
同时,为了直观地展现在创业板上市公司财务危机预警研究中最优核函数RBF下Twin-SVM预警模型的参数效果图,本文在将RBF核参数设定为0.8的基础上,让Twin-SVM模型本身的参数c1在{0.001,0.01,0.1,1,10}区间取值、c2在{0.005,0.05,0.5,5,50}区间取值,来研究不同参数下预警模型的预测性能。实验结果如图1所示。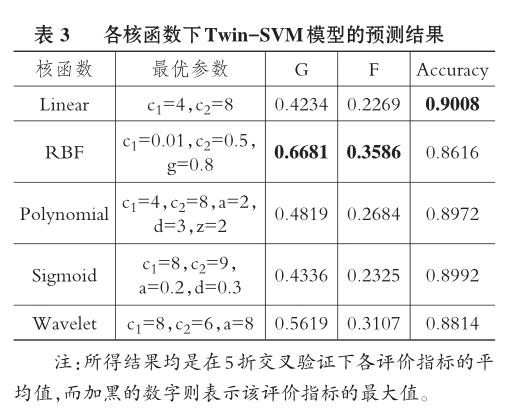
从图1中可看出,RBF核函数下Twin-SVM预警模型在不同的参数下取得了差异较大的预测效果。从更为综合的评价指标G值和F值来看,大多数情况下,Twin-SVM模型的预测效果随c1和c2的变动呈现同增或同减的变动趋势;而从分类准确率来看,大多数情况下,c1取值较小且c2取值较大时,整体的分类准确率都较低,这是因为当c1取值较小时,对财务危机样本进行预测的容错率较低,会将大量的财务正常样本错误划分,导致对财务危机样本预测准确率较高,而整体的分类准确率都较低。倘若c1取值较大而c2取值较小时,分类准确率提高,但是此时G值和F值较低,即将大量财务危机样本错误划分。因此,在参数选取上不仅要考虑财务危机样本的分类准确率,也要关注整体样本的分类准确率。进一步发现,在c1和c2分别取0.01和0.5时,无论是G值、F值还是分类准确率都取得了较好的效果。由此,本文所使用的RBF核函数下Twin-SVM模型的参数设置是准确且可靠的。
4.不同预警模型的预测性能对比。在确定了Twin-SVM预警模型的最优核函数以及模型参数之后,就要对模型的预测性能进行评估。为了避免数据的随机选取造成偶然性结果,也为了避免模型过拟合和欠拟合的问题,本文借鉴相关文献[19],采用不同划分比例(6∶4、7∶3、8∶2、9∶1)的训练集和测试集分别进行训练和预测。在将经筛选后的特征指标作为输入指标后,首先对Twin-SVM预警模型的分类准确率进行计算,进一步计算在最优参数下Twin-SVM预警模型的几何平均正确率G和少数类的度量值F。为了展示Twin-SVM模型优越的预测性能,将其与改进的ODR-ADASYN-SVM模型、BP神经网络、Bayes分类法(Bayes模型)和K近邻法(KNN模型)进行比较,结果如表4所示。
从表4中可以看出,无论是在6∶4、7∶3、8∶2还是9∶1的数据划分比例下,Twin-SVM模型的分类准确率都略低于BP神经网络和K近邻法,但是略高于改进的ODR-ADASYN-SVM模型且显著高于Bayes分类法。究其原因,是BP神经网络和K近邻法没有考虑到财务正常和财务危机公司构成的严重非均衡样本的特性,将大量财务危机公司错误预判为财务正常公司,而财务正常样本的数量仅占总体样本很小的比例,所以最后导致BP神经网络和K近邻法的总体分类准确率会略高于Twin-SVM模型。而ODR-ADASYN-SVM和Bayes分类法的分类准确率较低的原因可能在于,这两个模型对两类样本的拟合效果和预测性能不及Twin-SVM模型优异。

值得注意的是,将财务危机公司预测为财务正常公司所带来的危害是远远大于将财务正常公司预测为财务危机公司的。因此,为了进一步体现TwinSVM模型对少数类的财务危机样本的优越预测性能,将针对非均衡样本的评价指标几何平均正确率G和少数类的度量值F进一步用于Twin-SVM与其他模型的对比研究。为更直观地展现预测结果,将结果绘制在折线图中,见图2。
由图2可直观看出,从几何平均正确率G来看,四种数据划分比例下Twin-SVM模型的G值都在0.7上下波动,显著大于ODR-ADASYN-SVM模型(0.6左右)、BP神经网络(0.3左右)、Baye分类法(0.5左右)和K近邻法(0.3左右)。表明无论是对财务正常还是财务危机样本,ODR-ADASYN-SVM模型、BP神经网络、Bayes分类法和K近邻法的预测效果都不如Twin-SVM模型;从少数类的度量值F来看,ODR-ADASYN-SVM模型(0.3左右)、BP神经网络(0.15左右)、Bayes分类法(0.18左右)和K近邻法(0.2左右)也是远小于Twin-SVM模型(0.38左右),表明非均衡样本数据集对其他四种模型的预测能力都有较为严重的影响。进一步从不同数据划分比例下预测精度的G值或者F值的标准差来看,除Twin-SVM模型预测精度G值和F值的标准差(0.0218,0.0112)大于Bayes分类法(0.0215,0.006)以外,Twin-SVM模型预测精度G值和F值的标准差均小于其余模型。由此,综合来看,Twin-SVM模型的预测性能和稳健性都是显著优于ODRADASYN-SVM模型、BP神经网络、Baye分类法和K近邻法的。
进一步地,如果仅将结论建立在评价指标数值上,则缺少了类似数理统计上的严谨性与可靠性。因此,为增强所得结果的科学性与客观性,本文继续采用配对样本T检验对预测结果进行显著性检验以判断不同模型的预测性能是否存在显著性差异。检验结果如表5所示。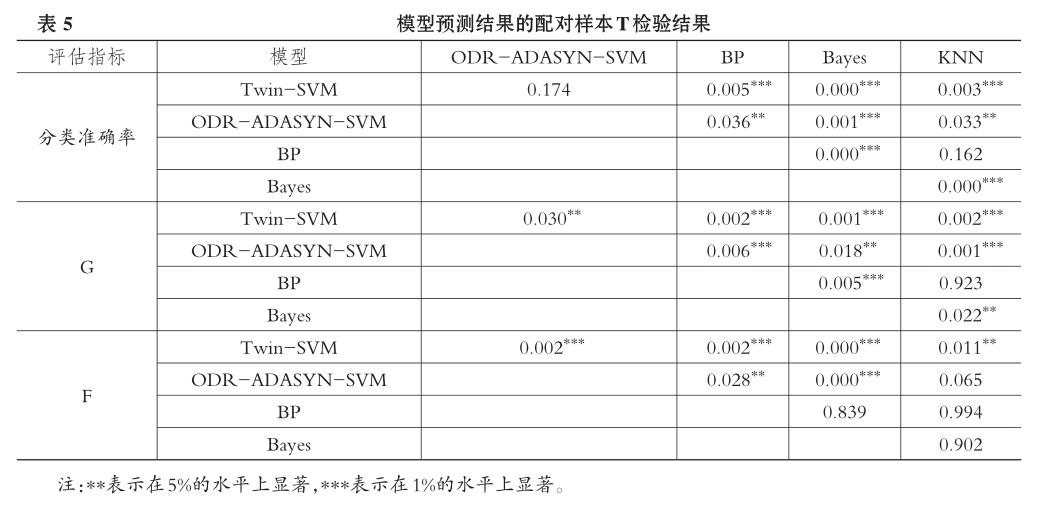
从表5可以看出,Twin-SVM模型与BP神经网络、Bayes分类法和K近邻法在分类準确率上的配对样本T检验统计量在1%的显著性水平上拒绝零假设(null hypothesis),即Twin-SVM模型与其他三个模型的预测效果有显著性差异,Twin-SVM模型在分类准确率上显著优于Bayes分类法,但略低于BP神经网络和K近邻法,这与前文的结论一致。进一步地,从更为综合的针对非均衡样本的评价指标几何平均正确率G及少数类的度量值F来看,在5%的显著性水平上,Twin-SVM模型与ODR-ADASYNSVM模型、BP神经网络、Bayes分类法和K近邻法的G值和F值有显著性差异。由此,从预测精度上来看,Twin-SVM模型是显著优越于其他四个模型的。
5.分行业下Twin-SVM预警模型的预测结果。评价模型的预测性能不仅要基于整体行业进行实证研究,而且应在不同行业不同特点下论证模型的泛化性能。本文在实验过程中发现创业板发生财务危机的公司大多数集中在制造业与信息传输、软件和信息技术服务业两个行业,2015年发生财务危机的公司共15家,其中12家属于制造业与信息传输、软件和信息技术服务业;2016年发生财务危机的公司共38家,其中30家集中在上述两个行业;2017年发生财务危机的公司共98家,其中81家集中在上述两个行业。而制造业是创业板板块中规模最大的行业,也是我国经济社会发展的支柱性产业。在当今信息高速发展以及大数据时代下,信息传输、软件和信息技术服务业对于国家经济发展的重要性不言而喻。由此,本文进一步在这两大行业中对Twin-SVM模型与其余模型展开预测精度对比,以考察该模型的泛化性能。实验结果见表6。
通过表6可看出,在制造业与信息传输、软件和信息技术服务业两个分行业中Twin-SVM模型均获得了最为优异的预测效果。在制造业中,TwinSVM模型明显优于BP神经网络和K近邻法,虽然ODR-ADASYN-SVM模型和Bayes分类法的G值略大于Twin-SVM模型,但是综合分类准确率和F值来看,ODR-ADASYN-SVM模型和Bayes分类法总体分类准确率较低,且对财务危机样本的预测精度也低,因此在制造业的预测中,Twin-SVM模型是优于其他模型的。而从信息传输、软件和信息技术服务业来看,Twin-SVM模型的G值(0.6298)和F值(0.2920)明显大于其他模型,表明Twin-SVM模型无论是对财务正常样本还是财务危机样本都有着优越的预测能力。
综合以上分析,无论是从预测精度来说,还是从预测稳健性来说,就整个创业板来看,Twin-SVM模型都是显著优越于其他预警模型的。而在制造业与信息传输、软件和信息技术服务业两个分行业中,Twin-SVM模型也具有更为优异的学习能力和推广泛化能力。因此,Twin-SVM模型有着更为优越的综合性能,能有效地识别并预测我国创业板上市公司的财务危机,为公司经营者和监管层防范与化解风险、投资者减少投资损失提供合适的操作工具。
四、结论
本文将筛选后的我国创业板655家上市公司作为研究样本,基于扣除非经常性损益后的净利润和净资产增长率构建财务危机的识别方法,从而确定了财务正常和财务危机样本。在Twin-SVM模型的构建过程中,运用5折交叉验证法下的三个评价指标即分类准确率、几何平均正确率G和少数类的度量值F来确定最优的Twin-SVM核函数。然后对在不同样本划分比例下的Twin-SVM模型与ODRADASYN-SVM模型、BP神经网络、Bayes分类法以及K近邻法的预测精度和稳健性进行对比,运用配对T检验对各模型预测精度的差异性进行显著性检验。最后在制造业与信息传输、软件和信息技术服务业两个分行业中对Twin-SVM模型与其余模型的泛化性能进行了对比。
实证结果表明:在Twin-SVM模型的构建过程中,RBF核函数展示出比Linear、Polynomial、Sigmoid、Wavelet核函数更为优异的预测性能;与改进的ODR-ADASYN-SVM模型、BP神经网络、Bayes分类法和K近邻法相比,Twin-SVM模型不仅在预测精度上高于其他模型,而且在预测稳健性上显著更为优越,在制造业与信息传输、软件和信息技术服务业两个分行业的泛化性能也显著优越于其余几个模型。
根据以上实证研究结果,基于Twin-SVM的财务危机预警模型能够有效地识别并预测我国创业板上市公司是否会发生财务危机。对政府管理决策部门而言,能根据预测结果及时准确地评估上市公司发生财务危机的可能性,并制定和实施相应的措施,避免对经济社会的平稳运行产生大的影响;对公司经营者来说,可审时度势,及时调整经营战略,积极防范和化解风险与危机;对投资者而言,可及时掌握上市公司的经营状况和盈利状况,进而调整投资策略,优化投资组合,减少相关投资损失。
【主要参考文献】
[1]John Nkwoma Inekwe,Yi Jin,Ma. Rebecca Valenzuela. The effects of financial distress:Evidence from US GDP growth[J].Economic Modelling,2018(72):8~21.
[2]Geng R.,Bose I.,Chen X. Prediction of financial distress:An empirical study of listed Chinese companies using data mining[J].European Journal of Operational Research,2015(1):236~247.
[3]逯东,万丽梅,杨丹.创业板公司上市后为何业绩变脸?[J].经济研究,2015(2):132~144.
[4]William H. Beaver. Financial ratios as predictors of failure[J].Journal of Accounting Research,1964(1):71~111.
[5]Edward I. Altman. Financial ratios,discriminant analysis and the prediction of corporate bankruptcy[J].Journal of Finance,1968(4):189~209.
[6]Hanmei Sun,Thuan Nguyen,Yihui Luan,et al. Classified mixed logistic model prediction[J].Journal of Multivariate Analysis,2018(168):63~74.
[7]James A. Ohlson. Financial ratios and the probabilistic prediction of bankruptcy[J].Journal of Accounting Research,1980(1):109~131.
[8]宋寶珠.创业板上市公司财务预警模型研究[D].北京:首都经济贸易大学,2014.
[9]Le H. H.,Viviani J. L. Predicting bank failure:An improvement by implementing machine learning approach on classical financial ratios[J]. Post-Print,2017(44):16~25.
[10]Vapnik V. N. The nature of Statistical Learning Theory[M].New York:Springer-Verlag,1995:100~200.
[11]Huang H.,Wei X.,Zhou Y. Twin support vector machines:A survey[J].Neurocomputing,2018(300):34~43.
[12]林宇,黄迅,淳伟德等.基于ODR-ADASYN-SVM的极端金融风险预警研究[J].管理科学学报,2016(5):87~101.
[13]Jian C.,Gao J.,Ao Y. A new sampling method for classifying imbalanced data based on support vector machine ensemble[J].Neurocomputing,2016(193):115~122.
[14]衣柏衡,朱建军,李杰.基于改进SMOTE的小额贷款公司客户信用风险非均衡SVM分类[J].中国管理科学,2016(3):24~30.
[15]Beyan C.,Fisher R. Classifying imbalanced data sets using similarity based hierarchical decomposition[J].Pattern Recognition,2015(5):1653~1672.
[16]李扬,李竟翔,马双鸽.不平衡数据的企业财务预警模型研究[J].数理统计与管理,2016(5):893~906.
[17]R. K. Javadeva,R. Khemchandani,S. Chandra. Twin support vector machine for pattern classification[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2007(5):905~910.
[18]王鹏,黄迅.基于Twin-SVM的多分形金融市场风险的智能预警研究[J].统计研究,2018(2):3~13.
[19]Geng R.,Bose I.,Chen X. Prediction of financial distress:An empirical study of listed Chinese companies using data mining[J].European Journal of Operational Research,2015(1):236~247.
[20]Chu Y.,Wang G.,Chen G. A new random subspace method incorporating sentiment and textual information for financial distress prediction[J].Electronic Commerce Research & Applications,2018(29):30~49.
[21]岑慧.创业板上市公司财务危机预警模型研究[D].厦门:集美大学,2018.
[22]Liang D.,Tsai C. F.,Wu H. T. The effect of feature selection on financial distress prediction[J].Knowledge-Based Systems,2014(1):289
~297.
[23]Mselmi N.,Lahiani A.,Hamza T. Financial distress prediction:The case of French small and medium-sized firms[J].International Review of Financial Analysis,2017(50):67~80.
[24]Hosaka T. Bankruptcy prediction using imaged financial ratios and convolutional neural networks[J].Expert Systems with Applications,2019(117):287~299.
[25]Binh P. V. N.,Trung D. T.,Duc V. H. Financial distress and bankruptcy prediction:An appropriate model for listed firms in Vietnam[J]. Economic Systems,2018(42):616~624.
