基于联合学习的跨领域法律文书中文分词方法
2019-10-21江明奇李寿山
江明奇,严 倩,李寿山
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
中文分词作为中文信息处理的基础任务,其准确性直接影响其它中文信息处理任务的性能[1]。基于机器学习的方法在中文分词领域上有优异的结果。例如,最大熵(maximum entropy)模型[2]、条件随机场(conditional random field,CRF)模型[3-5]以及长短期记忆(long short-term memory,LSTM)神经网络[6]。然而,传统的方法需要大规模的分词语料以训练性能优异的分词器,分词语料的获得需要大量人工参与,所耗费的成本太高。因此,传统的方法在法律文书上不能取得较好的中文分词性能[7]。
由于法律文书中各领域的语料匮乏,学者们使用跨领域的方法进行分词性能的提升。然而,不同领域的样本有一定的差异性,因此在跨领域任务上难以直接使用不同领域的样本提升分词性能。其主要原因在于各领域的词语分布不同,当使用源领域的分词器对目标领域进行分词时,未登录词(out of vocabulary,OOV)的数目快速增加,因此该分词器在目标领域上进行中文分词时无法获得较好的性能。除此之外,法律文书中的专有名词的构词规则和通用领域不同,同一个字符在不同领域中具有不同的标签分布。例如,在法律文书中,“一审”和“二审”为常用词。其中,“审”为词尾,其标签为“E”。但该字在通用领域中情况有所不同,“审”通常以词首的形式出现,如“审稿”,其标签为“B”。
鉴于获得法律文书的各个领域的少量已标注语料的难度较小,各领域拥有相同的标注规则,本文提出了一种基于联合学习的跨领域中文分词方法。该方法通过使用法律文书某一领域(源领域)数据辅助另一领域(目标领域)的方式可以提高相应的分词性能。此外,本文并没有采用直接混合源领域的样本和目标领域的样本的方法,而是采用联合学习的方法,在模型中存在主任务(目标领域的分词)和辅助任务(源领域的分词),辅助任务对主任务有一定的辅助作用。具体而言,首先,使用共享LSTM层得到两个任务的辅助表示,让主任务和辅助任务共同参与分词结果的评判;其次,将该辅助表示与主任务的表示进行融合;最后,利用LSTM对主任务的结果进行预测。本文创建了法律文书的分词语料库,并针对法律文书的特点把本文的方法应用到法律文书的分词当中。
本文的组织结构如下: 第1节介绍本文相关的一些工作;第2节详细介绍基于联合学习的跨领域中文分词方法;第3节对中文分词结果进行分析;第4节对本文做出总结,并对下一步工作进行展望。
1 相关工作
1.1 中文分词
近些年来,随着神经网络的广泛应用,越来越多的研究人员把神经网络使用到分词系统中。
Zheng等首次在中文分词任务中使用深度学习模型,同时提出了一种感知器方法用来加速训练过程[8]。Chen等将改进的长短期记忆神经网络运用到中文分词任务中,该模型是一种可以学习到长期依赖关系的循环神经网络(recurrent neural network,RNN)[9]。实验结果表明,该模型与传统模型在中文分词任务上性能相当。Yao等提出使用双向LSTM层进行中文分词任务,并在实验中对比了含有不同数目的双向LSTM层的实验结果[10]。Xu和Sun提出了基于长短期记忆神经网络的中文分词方法,在其中采集局部特征,并通过门控递归神经网络生成具有长距离依赖性的局部特征[11]。金等提出了一种双向LSTM模型,并把它用在了分词任务上[12]。Kamper等通过声音的词的嵌入进行无监督的中文分词任务[13]。
1.2 跨领域的中文分词
邓等将基于通用领域标注文本的有指导训练和基于目标领域无标记文本的无指导训练相结合,即在全监督CRF中加入最小熵正则化框架,提出了半监督的CRF模型,提高了中文分词上的F1值[14]。佟等提出了一种称为上下文变量(context variables)的数据来衡量某个候选词在篇章内的上下文信息,并使用语义资源,用其同义词的节点代价作为自己的代价,提高了未登录词的召回率[15]。许等针对目标领域分词语料的匮乏问题, 提出主动学习(active learning)算法与 N-gram统计特征相结合的领域自适应方法,用主动学习算法训练的分词系统各项指标上均有提高[16]。
2 基于联合学习的跨领域中文分词方法
2.1 基于LSTM模型的中文分词方法
RNN模型是Rumelhart等提出的具有循环结构的网络结构[17]。为了解决RNN中的长期依赖问题,Hochreiter和Schmidhuber[18]提出了一种新网络,称为长短期记忆(long short-term memory,LSTM)神经网络,该网络适用于处理和序列中长间隔的事件。LSTM神经网络在每个时间步包含一个更新历史信息的神经单元。Graves[19]对LSTM模型进行了相应的优化,此后LSTM广泛应用于语音等领域。
如图1所示,LSTM单元设置了记忆单元ct用于保存历史信息。LSTM的t时刻的神经单元计算如式(1)~式(6)所示。

图1 LSTM单元


图2 基于LSTM模型的法律文书中文分词方法的基本框架
2.1.1 LSTM层
我们将所有关于当前字符的特征拼接得到的向量作为LSTM的输入。例如,若当前字符为chi,我们将前一个字符chi-1、当前字符chi以及chi+1的一元和二元字的信息进行拼接,形成输入向量。输入向量通过LSTM层得到隐层向量。
2.1.2 全连接层
全连接层用于接收LSTM层的输出,我们在全连接层中加入激活函数,如式(7)所示。
其中,h为LSTM层的输出,φ为非线性激活函数,本文使用中“ReLU”作为全连接层的激活函数。
2.1.3 Dropout层
Dropout为当前深度学习中主流方法之一,能有效避免深度神经网络中的过拟合问题,提高基于深度学习模型的性能[20],Dropout层在训练时屏蔽某些神经元,从而避免过拟合问题,Dropout操作的过程如式(8)所示。
其中,D为dropout操作符,p为可调超参(神经元以该超参的概率决定是否被屏蔽)。
2.1.4 Softmax层
Softmax层用于接收Dropout层的输出,并输出最终结果,如式(9)所示。
其中,p表示预测标签的概率集,Wd为相应的权重向量,bd为偏置。
2.2 基于联合学习的跨领域中文分词方法
法律文书的特点在于其中存在许多专业词汇,各领域的差异性体现在各领域存在不同的专业词汇。然而,各领域含有共通的专业词汇和相似的专业词汇分词规则。对于未登录词,由于目标领域的已标注样本数目不足,不能较好地识别未登录词,因此我们使用将源领域的大量样本加入辅助任务的方法来提升未登录词识别的性能,该方法的提升体现在以下两点。(1)源领域可能含有目标领域中的某些未登录词(如“诉讼”“原告”),辅助任务能够学习该未登录词中字对于分词任务的表示。在共享中间表示的情况下,这些表示能够帮助任务学习。(2)在辅助任务(源领域)和主任务(目标领域)都是未登录词的情况下,由于目标领域的训练样本规模有限,识别未登录词的性能有限,因此加入大量源领域的样本,可能提升识别未登录词的性能。例如,在各领域的法律文书中,某些字(如“为”)常常出现在词的开头位置(如“为由”),加入大量样本有利于提升识别这些字开头的未登录词的能力。针对法律文书的上述问题,本文提出了一种基于联合学习的跨领域中文分词方法,有效利用源领域数据辅助目标领域。
图3给出了基于联合学习的跨领域中文分词模型的基本框架。其中,目标领域的预测为主任务,源领域的预测为辅助任务,使用辅助LSTM层得到两个任务的辅助表示,主任务利用该辅助表示进行预测。模型分为主任务、辅助任务以及联合学习,其介绍如下。
2.2.1 主任务
首先,使用主LSTM层(Main LSTM Layer)和辅助LSTM层(Auxiliary LSTM Layer)分别生成目标领域的隐层表示hmain1和hmain2,如式(10)、式(11)所示。


图3 基于联合学习的跨领域中文分词方法框架

2.2.2 辅助任务
首先,源领域的数据通过辅助LSTM层获得相应的表示,辅助LSTM层连接了目标领域和源领域,使主任务和辅助任务对分词同时参与评判,辅助LSTM层对于不同领域的数据有相同的权重,如式(15)所示。
其中,haux是共享的LSTM层对源领域进行编码生成的表示。
其次,haux通过辅助任务的隐藏层获得新的表示,辅助任务的隐藏层与主任务中的相同,如式(16)所示。
2.2.3 联合学习
使用Softmax层(Softmax Layer)对主任务中的表示进行预测,并使用另一个Softmax层对辅助任务中的表示进行预测,如式(17)、式(18)所示。

(17)

(18)

最后,基于联合学习的中文分词模型的损失函数为主任务的损失函数和辅助任务的损失函数的加权线性损失之和,如式(19)所示。

3 实验设计与分析
本节将给出本文提出的基于联合学习的中文分词模型的结果,同时对各个方法进行详细分析。
3.1 实验设置
(1) 数据设置: 本文的实验数据集的来源为中国裁判文书网(1)http://wenshu.court.gov.cn/,我们对其中的婚姻领域和合同领域进行数据的收集和分词的标注。在实验时,本文在两个领域中分别随机选取100篇作为实验样本,据统计,在这100个样本中,合同领域共存在66 755个词,婚姻领域共存在46 425个词。主任务的训练数据分别为目标领域数据的10%、20%、30%和40%样本,验证集为目标领域数据的10%,测试集为目标领域的20%,辅助任务的训练集为源领域相同数量的样本,测试集与主任务中的样本一致。
(2) 文本表示: 本文使用Word2Vec方法对样本中字的一元特征和二元特征进行训练,得到字对应的向量。我们将上下文窗口的长度设置为2。
(3) 参数设置: 本文使用LSTM模型进行中文分词实验,模型中的具体超参数如表1所示。

表1 模型中的参数值
在实验中,采用F1值作为衡量分词效果的标准。F1值具体的计算方法如式(20)所示。
其中,P表示分词准确率,R表示分词召回率,β为平衡因子。β大于1时,准确率比召回率更重要;β小于1时,召回率比准确率更重要;β等于1时,二者同等重要。在本文的实验中,β取1。
3.2 实验结果
本节中,我们将介绍几种中文分词方法,对所有方法进行结果统计和实验结果进行分析。
(1) 面向源领域的中文分词方法(Source_LSTM): 该方法仅使用LSTM模型对源领域数据进行训练。
(2) 面向目标领域的中文分词方法(Target_LSTM): 该方法仅使用LSTM模型对目标领域数据进行训练。
(3) 面向混合领域的中文分词方法(Mix_LSTM): 该方法将目标领域数据与源领域数据一起作为训练样本,并使用LSTM模型对所有训练样本进行训练。
(4) 基于特征增强的中文分词方法(Feature_Augmentation): 该方法由Daumé III[21]通过扩展不同领域中数据的特征提升领域适应性,在跨领域任务中可以有效改善性能。本节将源领域和目标领域混合后的样本进行特征的扩展,并使用LSTM模型对其训练。
(5) 基于联合学习的跨领域中文分词(Multi_LSTM): 该方法为本文提出的分词方法。在实验中,我们将λ设为0.7、0.8和0.9,表2和表3展示了λ值为0.7、0.8和0.9在验证集中的实验结果。
从表2和表3得知,λ为0.8时,在各个规模的样本下均取得了最优结果,源领域的样本产生的噪声最小,因此本文联合学习模型中的入定为0.8。
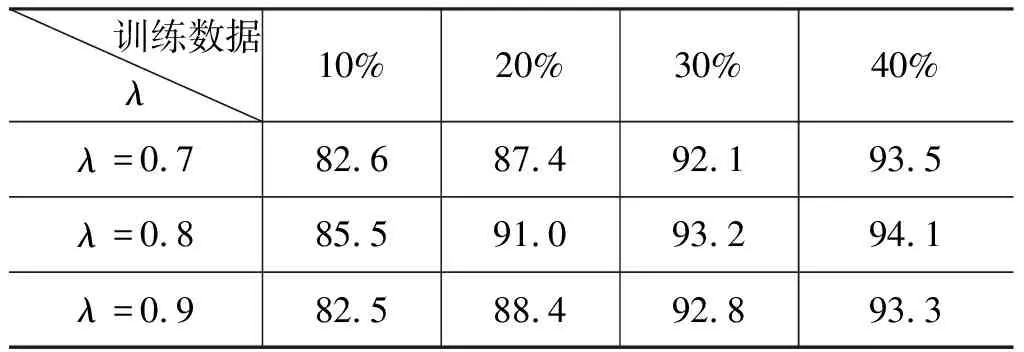
表2 基于不同参数的跨领域联合学习F值(%)

表3 基于不同参数的跨领域联合学习F值(%)
表4和表5给出了所有方法的结果,从表中可以得出以下4点。
(1) 面向目标领域的法律文书中文分词方法在训练样本规模相同时分词性能明显优于面向源领域的法律文书中文分词方法。原因在于跨领域训练具有领域适应性问题。具体而言,针对源领域训练获得的分词器不能有效适应目标领域的数据,因此获得了较差的性能。
(2) 在样本较少时,Target_LSTM方法的性能远不及其余的跨领域的方法(Mix_LSTM、 Feature_Augmentation和Multi_LSTM)。因此,单任务的中文分词方法难以适应目标领域语料匮乏的情况。
(3) Mix_LSTM方法直接混合源领域和目标领域的样本,增加了训练样本数目,因此其分词性能优于基线方法。
(4) 本文的Multi_LSTM方法分词结果优于所有基线方法。在语料匮乏的情况下提升更为显著。该方法的有效性体现在可以快速地加入法律专业词汇(如“裁定书”“判决书”“纠纷”“诉讼”等),其他方法则不能在缺乏语料的情况下快速识别。因此,本文的方法能够有效地降低人工标注数据的成本,并在此基础上拥有优异的分词性能。

表4 法律文书上各方法的F值(%)

表5 法律文书上各方法的F值(%)
4 结语
针对法律文书,本文提出了一种基于联合学习的跨领域中文分词方法。该方法通过联合学习结合源领域和目标领域的少量已标注样本,使其更加准确地识别目标领域中的词语。具体而言,首先,本文将目标领域的预测作为主任务,将源领域的预测作为辅助任务;其次,使用共享LSTM层得到两个任务的辅助表示,让主任务和辅助任务共同参与分词结果的评判;再次,将该辅助表示与主任务的表示进行融合;最后,利用LSTM对主任务的结果进行预测。实验结果表明,本文的方法在目标领域拥有较少的训练样本条件下可以获得较好的分词性能。
下一步的工作,我们将使用目标领域中的未标注样本进行半监督的分词任务。此外,我们想收集更多相关领域法律文书,并对本文提出的方法进行有效性检验,希望解决跨领域的中文分词中的领域适应性问题。
