基于深度学习和迁移学习的领域自适应中文分词
2019-10-21成于思施云涛
成于思,施云涛
(1.东南大学 土木工程学院,江苏 南京 210096;2.中国移动通信集团 南京分公司网络部,江苏 南京 210019)
0 引言
中文分词是从信息处理需要出发,按照特定的规范,对汉语按分词单位进行划分的过程[1]。中文分词是其他中文信息处理应用的基础,其结果直接影响机器翻译、信息检索、信息抽取等信息处理技术的正确率[2]。近年来,中文分词技术发展迅速,但由于自然语言使用复杂,中文分词依然是信息处理的难点之一。
目前主要的分词方法可以分为两类: 基于词典匹配的方法和基于统计的方法。基于词典匹配的分词对未登录词的识别和切分歧义等问题无法很好地解决[3]。基于统计的分词方法常用的模型有隐马尔可夫模型[4](HMM)、条件随机场模型[3,5](CRF)、深度神经网络模型[6-9]等。与CRF模型相比,基于深度神经网络模型的分词方法在保证分词性能的基础上,无须设计特征模板,受到研究者的关注。
尽管基于统计的分词方法在分词性能方面有较大的提高,但是,当测试语料和训练语料领域不一致时,分词性能会大幅降低[2,10]。这意味着,对不同专业领域文本做分词时,需要提供相应领域的分词训练语料。同时,为了确保分词正确率,训练语料的规模一般较大,例如,SIGHAN CWS BACKOFF 2005提供的PKU训练语料包括19 056条句子。为每个专业领域标注大量分词训练语料,需要消耗大量人力。为了提高分词方法的领域自适应性,张梅山等[10]将领域词典信息以特征的方式融入CRF模型中,Zhang等[7]在深度神经网络中加入领域词典的相关特征,朱艳辉等[3]用领域词典对分词结果做进一步逆向最大匹配。然而,只加入领域词典,不考虑领域训练语料,可能导致分词特征缺失。许华婷等[11]选择专业领域文本中含有最多未标记过的小规模语料进行人工标注。邓丽萍等[2]提出半监督CRF模型,在训练的目标函数中引入未标注数据的条件熵,减少标注样本。
迁移学习是将一个任务环境中学到的东西用来提升在另一个任务环境中模型的泛化能力[12],被用于解决新领域中训练数据难以获取以及训练数据与测试数据分布不同等问题。迁移学习的方法分为: 基于实例的迁移,基于特征的迁移,基于参数的迁移和基于知识的迁移[13]。Yang等[14]针对序列标注问题,提出深度循环神经网络的迁移学习。Xing等[15]为了提高专业领域的分词性能,通过控制通用领域和专业领域两个模型的LSTM输出分布的距离,联合训练两个领域的分词模型。
本文在文献[14]的基础上,用相对少量的工程法律专业领域分词训练样本,对已在通用领域分词语料上训练好的深度循环神经网络进行微调,最后在工程法律专业领域语料上进行测试。测试结果显示: 本文提出的分词方法在工程法律领域的分词结果F1值提高了7.02%。本文提出的专业领域分词模型的领域自适应性主要体现在: 减少专业领域训练样本标注数量,降低通用领域及专业领域分词特征不一致对专业领域分词的影响。
本文组织结构为: 第一部分介绍深度循环神经网络分词模型;第二部分介绍深度循环神经网络模型在领域分词训练语料上的迁移学习;第三部分为实验部分;第四部分为结论及进一步工作。
1 深度循环神经网络分词模型
1.1 分词序列标注建模
中文分词问题可以看作为序列标注问题。任意一个中文句子可以表示为x=(x1,x2,…,xn),其中,xi,i∈{1,2,…,n}是一个字符,具体为中文、数字、字母、标点符号或者其他符号。xi在词语中的位置有四种: 词首(B)、词中(M)、词尾(E)和单字符词(S)。一个分词单位表现为BE、BME (M个数大于或等于1)或S三种形式。句子x的分词标注结果可以表示为y=(y1,y2,…,yn),其中,yi∈{B,M,E,S}是xi对应的词语位置。

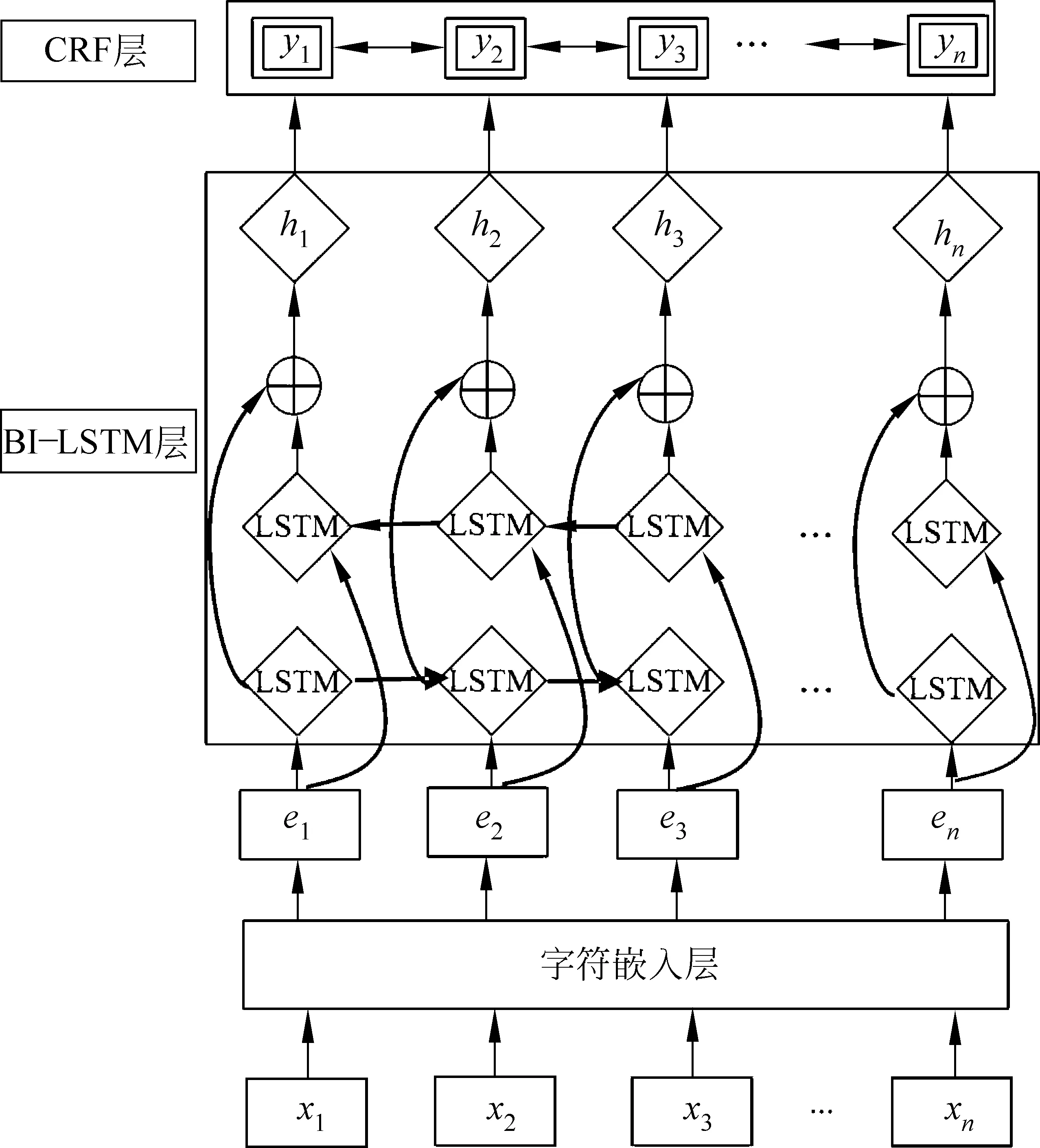
图1 BI-LSTM-CRF模型结构
1.2 带词典的BI-LSTM-CRF分词序列标注
Huang等[16]最早提出用BI-LSTM-CRF模型解决序列标注问题,后来被扩展应用到中文分词领域。BI-LSTM-CRF分词模型由三部分组成: 字符嵌入层,BI-LSTM层和CRF层,具体结构如图1所示。
1.2.1 字符嵌入层
字符嵌入层将句子中的字符xi转换成向量形式ei,输入BI-LSTM层。首先,用Word2Vec算法[17]在中文维基百科语料库中训练,获得d维字符向量,形成d×N的字符矩阵,其中N表示训练语料库中有效的字符个数。其次,对于句子中的每个字符xi,设置长度为l=5(l的值可调)的窗口,提取xi的上下文字符序列(xi-2,xi-1,xi,xi+1,xi+2)。 对窗口中的每个字符,从字符矩阵中查找得到相应的向量。最后,为当前字符xi构建字符嵌入向量,向量ei∈R(2l-1)×d由窗口中的字符向量以及bigram特征向量拼接而成,其中,bigram特征向量是窗口中连续的字符向量取平均。在ei中加入上下文向量和bigram特征向量可以提高分词性能[18]。
1.2.2 BI-LSTM层
长短期记忆(LSTM)网络[19]属于循环神经网络(RNN),针对RNN训练过程中的梯度消散问题做了改进。LSTM网络由LSTM单元构成,一个LSTM单元由输入门、遗忘门、输出门和细胞状态构成,如图2所示。输入门控制细胞状态加入新的信息量,遗忘门控制前一时刻细胞状态被丢弃的信息,输出门控制细胞状态的输出。et∈Rd是时刻t的输入向量,ht-1∈RK是LSTM单元的时刻t-1的输出,ct-1∈RK是时刻t-1的细胞状态。时刻t的LSTM的工作流程可以表示为如式(1)~式(6)所示。



图2 LSTM结构
1.2.3 CRF层


其中,Yx表示句子x的所有可能的标注序列集合。
深度神经网络训练时,损失函数如式(9)所示。
其中,x和y分别是训练数据中的句子和对应的标注序列,Ω(θ)是为了防止神经网络的过拟合而添加的正则项。
1.2.4 领域词典特征


(10)

(11)

(12)

(13)
领域词典可以在分词模型的预测阶段使用,或者在训练阶段就加入。在预测阶段加入领域词典,不需要改变训练得到的分词模型,有更好的领域自适应性[10]。而本文提出的分词模型在领域训练语料上做迁移学习,提取领域的分词特征,进而提高分词准确率。在领域训练语料上训练时,加入领域词典特征可以改善分词性能[10]。因此,本文模型采取在训练阶段加入领域词典的方式。这两种分词方式对分词性能的影响见3.4节。领域词典的完备性影响领域分词性能。本文采用文献[20]中的方法,构建工程法律领域词典。

图3 带领域词典特征的超网络构架
2 分词的迁移学习
给定通用领域的训练数据DS={(xSi,ySi)|xSi∈X,ySi∈Y,i=1,2…,nS}以及训练得到分词模型fS(·)(包括模型参数θS),迁移学习通过利用通用领域的DS和fS(·),提高专业领域DT的分词模型fT(·)的性能。本文将在通用领域内训练好的BI-LSTM-CRF[7]的参数θS作为要训练的BI-LSTM-CRF模型的初始化参数,在专业领域的分词训练数据上进行训练,同时,调整训练的学习率lr,以及在损失函数中加入适应项,提高专业领域上的分词模型对通用领域的适应性。具体的结构框架如图4所示。

图4 迁移学习的BI-LSTM-CRF模型结构
BI-LSTM-CRF分词模型的字符嵌入层将句子中的字符转换成向量形式,由于专业领域和通用领域用字的差别,会出现一些专业领域的字被归为未知字符类,影响分词效果。为了解决这个问题,对字符嵌入层进行改进,为了保证通用和专业领域的网络架构一致,对通用领域分词网络重新训练。步骤如下: 首先统计专业领域字符及频数,与通用领域相同的字符依然使用字符矩阵中对应的向量作为初始的字符向量,对于不在字符矩阵中的字符,随机化对应的字符矩阵。调整后的字符矩阵取代通用领域原本的字符矩阵,重新训练通用领域分词模型。

其中,g(·)可以是L2范数,也可以是KL散度(Kullback-Leibler divergence)[15]。本文选用KL散度,JAdap进一步表示为式(15)所示。
其中,i表示BI-LSTM层输出向量的第i项。
3 实验
3.1 工程法律领域分词标注准则及分词正确性判别准则
现阶段的分词规范,如《信息处理用现代汉语分词规范》[1]和北京大学中文分词规范[21],并未对专业领域的词汇做出明确详细的分词标注标准。本文参考分词规范的相关规定(表1),制定面向工程法律领域专业词汇的中文分词标注准则,包括:
(1) 领域内使用稳定或结合紧密的二字词,包括“形+名”“动+名”等,成为一个切分单位,例如,“热风”“高层”“大孔”“打桩”“举证”“抹灰”等;
(2) 领域内“名+名”和“动+名”组成的三字名词成为切分单位,“动+名”组成的述宾结构一般应切分开,“形+名”和“区别词+名词”组成的三字名词如果切开后意义改变或使用稳定,可以成为一个切分单位,否则应切开,例如,“人工费”“证明信”“施工方”“调/结构”“刮/腻子”“吊装/梁”“新/特性”“白水泥”“高/转速”等;
(3) 领域内四字及以上的词一般切分开,除非切开后意义改变,例如,“国有/独资/公司”“合成/树脂”“举证/责任/倒置”“自攻螺丝”等;
(4) 领域内“前接成分+单字”为切分单位,“前接成分+二字及二字以上词”若与前接成分有逻辑联系的词语是与其相邻的,则构成一个切分单位,否则切分,前接成分有[22]超、非、可、类、亚、不、无、反、自、泛、准、软、硬、多、大、性、双、单、半、耐、抗、防、跨等,如“耐候”“抗腐蚀”“软启动”“非/国家/工作/人员”等;
(5) “单字+后接成分”为切分单位,“二字及二字以上词+后接成分”,若与后接成分有逻辑联系的词语是与其相邻的,则构成一个切分单位,否则切分,后接成分有[22]者、率、化、界、性、家、员、生、长、机、族、式、型、度、体等,如“板式”“标准化”“热加工性”“设计/开发/者”等;
(6) “前接成分+词+后接成分”是切分单位,若长度大于等于5字,则切分,例如,“耐腐蚀性”“可预见性”“抗/根系/渗透/性”“非/经常/参与/性”等。

表1 相关分词规定
由于中文分词规范具有一定的弹性,在评价分词结果正确性时采用以下准则:
(1)域内使用稳定或结合紧密的二字词,或者切分后意义改变的,如果被切开,则认为分词错误,例如,“防水”“冷拔”“根系”“举证”等;
(2) 三字复合词名词的切分弹性偏大,若切分后意义不变,则切分与不切分都认为正确,若切分后意义改变,则切分被认为错误,其余三字复合词遵守切分准则,例如,“中标价”被切分为“中标/价”或不切分,都认为正确,若被切分为“中/标价”则切分错误;
(3) 三字以上词若切分后意义改变,则认为分词错误,例如,“教育费附加”,如果被切分为“教育费/附加”则错误。
3.2 实验环境与实验数据
本文的实验环境如下。处理器: Inter (R) Core (TM) i7-6850k CPU @ 3.6GHz;图形加速卡: NVIDIA GeForce GTX 1080ti 11 GB;内存: 16GB;操作系统: Ubuntu 16.04 LTS(64bit);Google开源深度学习框架TensorFlow 0.12;通用领域深度学习神经网络模型: Zhang等[7]提出的超LSTM网络(1)https://github.com/fudannlp16/CWS_Dict。
通用领域分词模型在SIGHAN CWS BAKEOFF 2005提供的PKU训练语料上训练,语料大小为7 548KB,词典特征使用结巴分词词典。
待分词的专业领域是建设工程法律领域。专业领域训练语料分为两部分,一部分取自百度百科中专业领域词条浏览页面内容,另一部分取自中国裁判文书网(2)http://wenshu.court.gov.cn/的建设工程施工合同纠纷文书。专业领域词条来自中国知网工具书库(3)http://mall.cnki.net/reference/index.aspx的法律术语词典和土木工程领域词典。利用第3.1节制定的专业领域分词标注准则进行人工分词标注,最后得到 1 536KB 的专业领域训练语料。
专业领域词典是将中国知网工具书库的法律术语词典和土木工程领域词典的词条抽取出来,在百度百科进行相关词扩展,最后规格化处理,并且保留3字以内词条后得到的,词典收录领域词条40 420条。领域词典在专业领域分词训练时加入到模型中。
分词性能评估采用准确率P、召回率R和综合指标F1,以F1为主要参考指标。
3.3 参数设置
神经网络的超参数取值影响神经网络的性能。以Zhang等[7]的LSTM网络模型在通用领域语料(PKU语料)上训练得到的网络参数为初始值。在通用语料上训练时,超参数取值见表2。

表2 通用领域分词模型超参数
训练时,选择90%的句子作为训练集,剩下10%作为验证集。当迭代次数在42次时,验证集上的F1值为97.07%。选择此时的网络参数为初始值。
专业领域训练语料随机选择90%作为训练集,剩下10%作为验证集。字向量长度为100维,专业领域新出现的字对应的字符矩阵随机化初始值,在随后的训练中调整。
在专业领域训练语料上训练时,考虑超参数的影响。首先分析学习率(lr),并确定合适的lr。 设置Dropout丢弃率为50%,正则项系数α为0.001,KL散度系数为0,lr分别取10-3、10-4和10-5时,对比验证集在每次迭代后F1的变化情况,以及训练集的损失函数值的变化情况,分别如图5(a)和图5(b)所示。从图中可见,lr取值为10-3时,在前几个迭代次数里,F1的性能较好,损失函数值下降较快,之后,神经网络处于过拟合状态,性能下降。lr取值为10-5时,F1和损失函数的性能提高比较慢,属于学习率取值偏低。lr取值为10-4时,10个迭代次数后,性能与10-3趋于一致。因此,本文模型的学习率lr设置为10-3。

图5 学习率对分词模型的影响
与一般的神经网络模型相比,本文模型在较少的迭代次数下达到最优,主要是由于网络参数初始值是在通用领域语料训练好的,使得在专业领域语料训练时,网络性能迅速达到最好。其次,确定合适的Dropout丢弃率以及正则项系数α。 设学习率lr为10-3,正则项系数α为0.001,KL散度系数为0,分析不使用Dropout丢弃率、丢弃率为20%和丢弃率为50%时对验证集F1值的影响。对比结果如图6所示。从图6可知,三种丢弃率的性能差别不大。设置学习率lr为10-3,丢弃率为50%,KL散度系数为0,分析α取0.001、0.002、0.005和0.01时,对验证集F1值的影响。对比结果如图7所示。从图7可知,随着α的增加,F1值下降。选取α为0.001。

图6 lr=10-3,α=0.001时,Dropout的影响

图7 lr=0.001,Dropout为50%时, α的影响
最后,分析KL散度系数λ对模型性能的影响,设置学习率lr为10-3,正则项系数α为0.001,Dropout丢弃率为50%, KL散度系数λ分别取0、0.2、0.4和0.6,验证集F1值见图8。从图中可知,不同KL散度系数的验证集上F1值差别不大。在3.4节将会对λ做进一步分析和讨论。

图8 KL散度系数λ的影响
3.4 不同分词方法性能对比
通过实验对比分析本文模型中超参数的影响,最终专业领域上的超参数设置如下: 学习率lr为10-3,正则项系数α为0.001,Dropout丢弃率为50%。在建设工程法律领域文本中选取300个句子组成测试集,对比本文提出的模型与其他分词模型在测试集上的性能。表3列出了本文模型(KL散度系数为0,训练时带领域词典)、NLPIR分词方法(4)http://ictclas.nlpir.org/、BI-LSTM-CRF模型[7]、预测时带领域词典的BI-LSTM-CRF模型[7]、本文模型(KL散度系数为0,不带领域词典)、本文模型(KL散度系数为0.2,不带领域词典)在测试集上的准确率P、召回率R和综合指标F1。其中,BI-LSTM-CRF模型是直接使用文献[7]中,在通用领域语料上训练好的模型。对比分析表3中的分词结果,可以得到如下结论。
(1) BI-LSTM-CRF模型的F1值比NLPIR的F1值提升了4.27%;BI-LSTM-CRF在预测时加入领域词典后,F1值提升了2.8%,领域词典有效提高了BI-LSTM-CRF模型的自适应性;本文提出的训练时带领域词典的迁移学习模型比BI-LSTM-CRF在预测时加入领域词典的F1值提升4.22%,但是,后者的领域自适应性高于前者。
(2) 在本文提出的迁移学习模型中,加入领域词典比不加入领域词典的F1值提升了0.6%,未作迁移学习时,在预测时加入领域词典比不加入领域词典的F1值提升了2.8%。这主要是因为专业领域的训练样本为领域分词提供了有效特征。
(3) KL散度系数是用通用领域分词信息约束专业领域模型参数的训练,防止过拟合,然而,观察领域文本组成测试集上的分词结果发现,加入KL散度系数的分词结果中出现与NLPIR和BI-LSTM-CRF模型一样的错误的分词结果,导致F1值比起不加KL散度系数降低了1.86%。这主要因为专业领域的训练集中分词特征分布与通用领域差异性较大,而KL散度系数使得分词模型学习到了通用领域特征,导致测试集的分词结果出现错误。
(4) 专业领域测试集的分词结果F1值比专业领域验证集的低,这主要是因为验证集数据与训练集数据往往来自同一篇文章(参见3.3节,专业领域训练语料随机选择90%作为训练集,剩下10%作为验证集),数据分布比较接近,而测试集数据选自不同文章。分别统计专业领域训练集、专业领域验证集和专业领域测试集的N-gram分布,采用KL散度计算验证集与训练集,以及测试集与训练集的数据分布距离。具体计算如式(16)所示。
其中,L∈{验证集,测试集},U代表训练集,Χn代表L和U中的n-gram集合,P(x|L,n)表示Χn中x在L中出现的概率,P(x|U,n)表示Χn中x在U中出现的概率,wn表示不同n-gram的重要性权重,设wn=1/3。 通过计算可得,D(验证集‖训练集)=1.55,D(测试集‖训练集)=3.09。 因此,验证集和训练集的数据分布比测试集和训练集更加接近。

表3 不同分词结果对比
4 总结
本文针对专业领域分词性能下降的问题,提出了深度学习的中文分词模型,同时,利用迁移学习原理,结合大规模通用领域分词语料、小规模专业领域训练语料以及领域词典,提高领域分词性能,实现领域自适应分词。以工程法律领域分词任务为例,提出领域专业术语的分词准则,进行小规模人工标注,并且设计分词实验,对比各分词模型的性能,结果表明,本文提出的分词模型能有效改善跨领域分词系统性能。
本文提出的方法还存在进一步改进的空间。领域文本中常出现较长的数字、字母以及符号的组合,领域术语中会出现字母和汉字的组合,影响分词正确率,可以考虑做多层分词。现有的文本特征只考虑了字和周围字,以及词典信息,在后续工作中,可以考虑加入字的边界特征。
