基于循环实体网络的细粒度情感分析
2019-10-21贾川,方睿,浦东,康刚
贾 川,方 睿,浦 东,康 刚
(成都信息工程大学 计算机学院,四川 成都 610225)
0 引言
随着互联网上由用户生成的评论文本数据不断增多,此类数据的研究价值和商业价值也越来越明显,而情感分析或观点挖掘是针对此类文本数据的主要利用方式[1]。早期对于文本评论的情感分析是对整个评论文本进行情感分类,假设评论文本中已经包含且只包含感兴趣的评价对象,分类的关键在于从评论文本中手工构造或自动生成情感特征,而不考虑情感特征对应的评价对象信息[1-2]。常见的研究,如文档级情感分析和句子级情感分析[3-4]。一般的评论中往往包含多个评价对象,或未包含感兴趣的评价对象,且多个评价对象可能对应不同的情感倾向,因此将整个评论文本看作整体进行情感分类略显粗糙,限制了情感分析的作用。细粒度的情感分析任务,也叫作基于属性的情感分析任务,是针对评论文本中不同的评价属性,识别出各个属性对应的情感倾向。通常,一个评论文本中会出现针对多个对象表达的不同情感倾向,比如,对于评论“这家店的菜很好吃,但是老板态度有点差”,细粒度的情感分析需要识别出针对“菜”和“老板态度”两个不同方面的情感倾向,得出<菜,积极>和<老板态度,消极>的评价结果。因此,相比句子级或文档级情感分析任务,基于属性的细粒度情感分析可以从评论文本中获得更精准的用户评价信息,从而更有利于商家了解用户需求和改进产品及服务质量。
1 相关研究
目前已有研究中,存在将属性看作属性词和属性类别的两种不同处理方式[5]。基于属性词的细粒度情感分析将任务看作序列标注,属性词为出现在评论文本中的具体词,标注出属性词之后,再抽取针对每个属性词的情感特征。基于属性类别的细粒度情感分析将属性类别看作预定义的类别集合,属性类别词不一定出现在评论文本之中,对于每一个预定义的属性类别需要从文本中抽取对应的情感特征进行情感分类。
针对属性相关的细粒度情感分析,关键在于抽取与属性相关的情感特征。早期研究中使用的方法主要依赖于繁琐复杂的特征工程[6-7],通过人工定义规则来提取特征,或者将浅层词向量特征与情感词典等人工定义特征结合形成针对属性的情感特征[8],然后,利用机器学习方法进行情感分类,分类效果取决于人工特征以及领域专家的知识。近些年,随着神经网络理论和应用的不断发展,以及注意力机制[9]和外部扩展记忆[10]等网络计算机制的提出,针对属性的细粒度情感分析问题也涌现出不少使用神经网络的方法[11-13]。得益于循环神经网络的序列处理特性,研究[13-14]利用长短期记忆网络(Long short-term Memory Network, LSTM)或双向长短期记忆网络(bi-LSTM)抽取和识别文本中的情感特征。由于基于属性的情感分析需要提取对应于该属性的情感特征,Tang等[11]尝试在提取情感特征时将属性词与上下文词区别对待,提出TD-LSTM和TC-LSTM两种方式。其研究表明,在模型的序列处理每一个阶段都考虑属性特征的TC-LSTM可以取得当时最高的准确率。随后,Wang等[13]同样将属性表示与文本词序列表示拼接作为LSTM的输入,并在序列输出中结合属性特征表示来计算注意力权重,提出ATAE-LSTM模型。该模型还首次尝试用预定义的属性词嵌入矩阵对属性词进行嵌入表示,该方法在SemEval 2014 Task4(1)https://www.aclweb.org/portal/content/semeval-2014-task-4-aspect-based-sentiment-analysis任务上取得了较好的效果。
常见的LSTM网络或门控循环网络(Gated Recurrent Unit Network, GRU)网络的内部隐状态通常为一个向量,使模型内部能够保存的信息有限。因此,Weston等[10]提出使用可读写的记忆网络来扩展模型学到的知识,用于问答任务中的知识推理。同时,受多个计算层能够识别高层抽象特征[15]的思想启发,Sukhbaatar等[16]对记忆网络进行多层扩展,发现具有多层计算的记忆网络在问答和语言建模等多个任务上均取得很好的效果。随后,相关研究[17-18]将外部记忆的思想应用于针对属性词的细粒度情感分析,通过多层注意力从外部记忆中抽取针对属性的情感特征。但是以上方法在多个注意力层计算中,对记忆模块中的每一部分通过注意力层独立计算权重,舍弃了循环网络的序列处理步骤,而近期的研究表明,对文本输入的序列处理有利于提高整体性能[19-20]。因此,Liu等[21]提出一种带延迟更新单元的循环实体网络,应用于属性情感分析,其方法主要受Henaff等[20]提出的循环实体网络的启发,在LSTM中嵌入属性依赖的实体信息,通过扩大的内部记忆链,在序列处理输入文本的每一步都动态更新所有的内部记忆链。目前,Liu等[21]的方法在Sentihood[22]数据集上取得了最好的效果。本文提出的方法也受Liu[21]和Henaff[20]研究的启发,利用扩大内部记忆链的LSTM网络对评论文本进行序列处理,在给定属性类别的情况下进行属性情感特征抽取,但是不同于Liu[21]的方法,本文在循环实体网络单元中嵌入预定义的属性类别信息,使得在保持模型扩展性的同时更有利于提取属性类别相关的情感特征。实验表明,本文提出的方法在Sentihood数据集上取得了更高的准确率。
2 研究方法
上述研究中,基于属性词的细粒度情感分析[8,11-12, 23],要求用于训练和预测的评论文本数据中的属性词已经进行了标注识别,或者将属性词识别作为一个子任务[24],然后再对识别出的属性词抽取情感特征进行分类。基于属性类别的细粒度情感分析[5,13,21]省略了对属性词进行识别的需要,只需针对预定义的属性类别抽取与属性类别相关的情感特征。比如,针对上文提到的评论“这家店的菜很好吃,但是老板态度有点差”,基于属性类别的细粒度情感分析可以得到<味道,积极>和<服务, 消极>的评价结果。本文认为在诸如电商平台、大众服务等领域,识别针对属性类别的情感倾向可以方便商家从整体上了解产品和服务质量,更具有实用价值。因此本文将基于属性类别的细粒度情感分析作为研究任务。
基于属性类别的细粒度情感分析,需要模型准确地识别并抽取与属性类别相关的情感特征。本文以Henaff等[20]提出的循环实体网络为基础,以预训练词向量为输入,在循环实体网络中嵌入预定义的属性类别,并通过双向循环实体网络和注意力机制抽取属性情感特征,最后进行softmax分类。模型的总体结构如图1所示。

图1 模型总体结构
在对输入评论文本转换为词嵌入序列后,使用双向循环实体网络抽取情感特征,循环实体网络结构如图2所示。

图2 循环实体网络


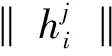
对于给定的属性类别,通过一个注意力层,计算给定属性类别a和所属实体e的情感特征u。 然后,类似于Henaff[20]在输出模块将u转换并进行softmax情感分类。如式(7~10)所示。

3 实验分析
本文实验所采用的数据集为Sentihood[22],该数据集是针对不同地区的不同属性类别的情感评价,其中,每一个样本都标注了评价属性类别、所属地区和情感极性。属性类别包括价格、交通、安全、生活等12个方面,所属地区包含2个,情感类别包含积极或消极,数据集共包含5 215条样本,其中,3 862条样本是针对一个地区的不同方面评价。为方便对比,本文和之前的研究[20]一样,采用数据集中最常见的4个属性类别(general, price, transit-location, safety)进行方法验证,在评论文本中未提及的属性类别的情感类别判断为空,按照7∶1∶2的比例划分训练集、验证集和测试集,并将每条样本拆分成对单个属性类别和所属实体的情感类别标注。最终数据量分布如表1所示。

表1 数据样本分布
模型输入采用预训练的Glove词向量[25](300-D,42B个词)来初始化文本嵌入矩阵。对于包含多个词的属性类别,用多个词的词向量平均来表示属性类别。单个隐藏层记忆链的维度设为300,参数矩阵H、U、V、W维度大小为300×300,延迟更新信息权重v∈300,情感分类层权重R∈300×3,批量大小为64,学习率为0.05,未使用学习率衰减,正则化参数为0.002,最终,属性相关情感特征进行dropout,保留比例0.8,模型迭代训练500次。对于未表达情感极性的属性类别预测其情感标签为未提及,为了避免未提及情感类别的样本数过多而导致的数据分布不平衡问题,在训练过程中按照未提及的类别数量对其他类进行降采样。
3.1 横向对比实验
对比实验阶段,本文与其他在Senthood数据集上进行属性级别细粒度情感分析的方法做了横向对比,主要包含: (1)Saeidi等[22]在Sentihood数据集上提出的基线模型LR、LSTM-Final以及LSTM-Loc,LR为包含n元特征和词性特征的逻辑回归分类器,LSTM-Final为双向LSTM的最终隐状态拼接,LSTM-Loc为考虑地区实体在文本中所处位置的双向LSTM的最终隐状态拼接,隐状态为一维;(2)Ma等[26]提出的引入常识信息的模型Sentic-LSTM;隐状态为一维;(3)Tang等[12]提出的基于记忆网络的模型TDLSTM,使用文本嵌入作为外部记忆矩阵;(4)Liu等[21]提出的嵌入实体信息的循环实体网络EntNet,隐状态为扩大的记忆链,但未明显针对多个属性类别。验证指标采用情感分类的准确率和AUC值。对比实验结果如表2所示,其中“—”表示未报告的实验指标,“*”表示平均5轮实验结果。

表2 验证集上不同模型的指标对比
对比实验表明,通过扩大记忆链的方式,本文的方法和Liu[21]的方法都取得了比较高的指标。而Tang等[12]将文本嵌入矩阵作为外部记忆的方法也是希望模型能够记住更多信息,用于识别不同属性对应的情感特征,但是,在给定评论文本后,不同属性类别的情感特征应该是固定的,各属性类别之间的情感特征不应有太多交集。通过扩大记忆链的方式,相当于给每一个预定义的属性类别分配一条记忆通道,从而在模型训练过程中可以针对不同的属性类别更新相对应的内部记忆,相对常见的循环神经网络而言,扩大了内部记忆的容量,而Tang等[12]的方法在更新记忆的过程中针对不同属性类别的更新并不明显。由此,本文提出的方法和Liu等[21]提出的方法证明,使用扩大记忆链的方式可以取得更好的效果。
相对Liu在EntNet中只考虑了属性所属的实体,本文将预定义的属性类别嵌入到模型中,使网络在循环处理文本序列时能够更好地识别针对不同属性类别的情感特征,提高了网络的特征表示能力,从而取得了更高的准确率和AUC值。
3.2 纵向对比实验
为进一步验证嵌入属性类别信息对抽取属性相关情感特征的影响是否稳定,本文在实验数据集上根据属性类别对应的样本个数,由多到少选择了多个属性类别,分别将不同数量的属性类别嵌入模型中进行了纵向对比实验。实验结果如表3所示。

表3 嵌入不同数量属性类别的模型指标
从表3可看出,随着属性类别嵌入的增多,对更多的属性类别进行细粒度情感分析的准确率指标和AUC指标并没有明显降低,这说明通过嵌入属性类别来增强模型对属性相关情感特征的抽取是确实有效的。而且,当针对不同任务存在不同数量的预定义属性类别个数时,该方法可以有很好的扩展能力。

图3 分别嵌入实体和属性后模型的收敛速度
另一方面,与Liu的方法相比,在循环实体网络中嵌入预定义的属性类别信息使得模型在训练中收敛速度上更快。如图3所示,横坐标表示训练次数,纵坐标表示平均损失。其原因在于,嵌入属性类别信息后,网络可以直接考虑到与属性类别相关的情感特征,因此在特征表示和损失计算时,模型对属性情感特征更敏感,从而有利于加快训练更新。
4 总结
本文提出了一种嵌入属性类别的循环实体网络来进行针对属性类别的细粒度情感分析, 使得序列处理文本数据时, 可以更好地针对不同属性类别抽取特定的情感特征,该方法在Sentihood数据集上取得了当前最高的准确率。后期会在此基础上探索如何将外部知识库与循环实体网络结合,以进一步提高模型的知识推理和特征表示能力。
