基于深度学习与双目立体视觉的物体管理应用
2019-09-30邓虚睿贾蒙磊
邓虚睿 贾蒙磊


摘要:利用搭载双目摄像机与GPS设备,提出了一种基于深度学习与双目立体视觉的物体管理方案。首先用智能眼睛拍摄照片,并利用GPS获取智能眼睛所在的位置,然后利用卷积神经网络(CNN)中的FAST-RCNN对拍摄照片进行物体识别,获取照片中的物体,再利用双目立体视觉技术中的SGBM算法,获取照片中的物体相对与摄像机的坐标。利用拍摄者的GPS与物体相对拍摄者的坐标,就可以获取物体的坐标,从而获取物品的位置,实现管理物体的功能。
关键词:深度学习 FAST-RCNN;双目立体视觉技术;SGBM
中图分类号:P315.69 文献标识码:B
1 引言
在工业市场,常用RFID技术解决物体识别的难题[1]。
RFID是利用非接触的双向通信来达到识别效果并交换数据的通信技术[2]。RFID由标签、读取器、天线组成。标签标识物体,读取器读取标签信息,天线负责标签与读取器之间的数据转移[3]。然而,在物体管理方面却需要进行给物体嵌入RFID芯片,标识物体的位置信息,利用读写器对RFID内的信息进行查询与修改。嵌入芯片与修改芯片内的信息是一个十分繁杂的过程[4],中间产生了大量的人力成本。
信息爆炸时代如何对信息进行处理已经成为了时代难题。数据处理的需求与计算机硬件设备的改善,促进了人工智能的发展。随着人工智能的发展,大量的劳动力将会被人工智能取代。现在,计算机图形学与深度学习正在快速发展,然而这些技术在现实中的应用却十分有限,构建使用这些技术的系统能有效地解决一些难以解决的问题。基于RFID技术的物体管理系统,会产生巨大的人力开销。利用当下流行的深度学习技术与双目立体视觉技术能有效地模拟人类的视觉,同时结合GPS定位技术,会给物体识别带来全新的解决方案。
深度学习是机器学习研究的新领域。它的动机是建立模拟人脑学习数据的神经网络,比如图像、声音和文本[5]。本文将使用深度学习中的卷积神经网络算法(CNN)来解决物体管理中的物体识别问题。
双目立体视觉是计算机图形学的一个重要分支。它使用视差的原理利用两个相同的成像装置在不同位置拍摄相同的画面,并且通过计算点的位置偏差,来得到物体的三维坐标数据[6]。本文将采用双目立体视觉技术解决物体管理中的坐标问题。
利用物体识别来获取照片中的物体信息,再用双目立体视觉技术获取照片中物体相对与拍摄位置的坐标信息。根据拍摄位置的GPS信息与相对拍摄位置的坐标信息,即可获取照片中的物体的坐标。
本文将深度学习与双目立体视觉结合在一起,建立一个管理物品的模型,用于管理物体的坐标信息。
2 基于卷积神经网络的物体识别
2.1 卷积神经网络
在物体管理系统中,图像识别是个极其重要的部分,利用图像识别,能识别出摄像头、拍摄的物体的种类。同时,结合尺度不变特征变换算法,可以区分出拍摄图片中的不同的物体。利用这些技术,能实现对每个物体个体的标记。
卷积神经网络是深度学习中一个极具代表性的网络结构,它的应用十分广泛,尤其是在计算机视觉领域取得了很大的成功。CNN在图像识别中相较于其他算法的优点在于,避免了对前期图像复杂的预处理过程,CNN可以直接利用原始像素,用很少的预处理识别出物体的特性。
Krizhevsky等人在2012年提出了经典的CNN结构—AlexNet,该网络在图像识别任务上有着良好的表现[7]。AlexNet取得成功后,研究人员进一步提出了其他的神经网络结构ZFNet、VGGNet、GoogleNet和ResNet[8]。至此,卷积神经网络能很好地处理了物体识别的问题。
由于物体管理对物体识别的精确度要求较高,本文选用了卷积神经网络中物体识别效果较好的FAST-RCNN来进行图像识别。
2.2 FAST-RCNN的设计与实现
(1) FAST-RCNN结构
FAST-RCNN网络由卷积层、降采样层、ROIPooling层、全连接层与损失层组成[9],如图1所示。
(2) 训练样本
训练过程中每个mini-batch包含2张图和128个region proposal(即ROI),其中大约25%的ROI和ground truth的IOU大于0.5,只通过随机水平翻转进行数据增强。
在数据集上,选择了图片尽可能大的数据集,以确保物体识别的种类更广泛,同时选择了ImageNet作为数据集。
ImageNet是一个有超过1400万个图像覆盖了超过20,000种类的数据集,被广泛地应用于深度学习图像领域的研究[10]。
(3) 损失函数
本文采用多融合损失(融合回归损失和分类损失),分类的Loss采用Log Loss(即对真实分类的概率取负Log,输出K+1维),回归的Loss使用与RCNN一致的SmoothL1Loss。
总的损失函数如下:
分类损失函数如下:
回归损失函数如下:
其中有:
(4) ROIPooling
由于region proposal的尺度不同,同时需要使提取出來的特征向量维度相同,于是需要一种特殊的方法来解决。ROIPooling就是用来解决这个问题的。思路如下:
将region proposal划分为H X W大小的网络;
对每个网络做MAXPooling可能;
将所有的输出结合起来形成大小为HXW的特征映射。
(5) 全连接层
卷积层计算一整张的图片,而全连接层需要对每个region proposal作用一次,所以全连接层的计算量会非常大,使用奇异值分解(SVD)进行数据降维,来简化全连接层计算。
3 基于双目立体视觉的坐标定位
3.1 双目立体视觉
双目立体视觉是基于人眼视差原理的计算机图形学的一个分支。它把在双摄像头上获取的图像经过各种处理,以获得照片中的点相对于双目摄像机的三维几何信息[11]。
对于空间物体表面的一点,如果从双目摄像头同时观察P,并能确定在左摄像头图像中的点pl与右摄像机图像上的点pr是空间同一点p的图像点,在得知左右摄像头的三维坐标后,P的三维坐标可以被计算出来。双目立体视觉系统包括相机标定、立体校正、立体匹配和三维重建四个过程。
相机标定利用空间中的点的三维位置和它在图像中的对应点的相互关系,建立了相机成像的几何模型,从而获取该双目摄相机的几何模型参数。
立体矫正能将左右图像去除畸变,将两幅图像极线对齐,以方便后续操作。
立体匹配可以找到在不同视点图像中匹配到的对应点,由此获得视差图。
在获取了视差图后,就可以用三维重建技术可以确定物体在图像中的位置信息,同时能确定物体的种类,从而得到相片中的物体相对于相机的三维坐标。
本文使用Semi-Global Block Matching算法进行立体匹配过程。
3.2 Semi-Global Block Matching 算法的实现
(1) Semi-Global Block Matching介绍
Semi-Global Block Matching是一种被广泛应用于计算视差的算法。
SGMB通过选取每个点的视差,组成一个视差图,同时根据视差图,设置一个和该图相关的能量函数,使能量函数最小化到收敛,从而求解出每个像素最优的视差[12]。
(2) 能量函数的设置
E[D]表示视差图D的能量函数;p,q代表图像中的像素;Nq表示q的相邻像素。
C(p,Dp)指当p像素点视差值为Dp时,该像素点的Cost。P1、P2是惩罚系数,相差为1的像素用P1,视差值相差大于1的像素用P2。
I[.]函数中的参数,如果是真则I[.]值为1;如果为假,则I[.]值为0。
(3) 算法优化
使用上述函数来查找二维图像的最优解是NP-hard问题时,耗时巨大,所以将问题分解成多个一维问题,以减少复杂度。与此同时,使用动态规划来解决每个一维问题。一个像素具有8个相邻的元件,因此它可以被分解成8个一维问题。
(4) 算法实现
每个像素p的视差只与像素p左边的像素相关,因此得出了下面的公式:
其中,r为p左边的相邻像素,r的方向为p的方向;Lr(p,d)表示沿着r的方向,像素p的视差为d时,最小的Cost值。
这个Cost为下列四种Cost值中的最小值:
1) 左边像素的视差为d时,Cost的最小值;
2) 左边像素的视差为d-1时,Cost的最小值与惩罚系数P1之和;
3) 左边像素的视差为d+1時,Cost的最小值与惩罚系数P1之和;
4) 左边像素的视差为其他时,Cost的最小值与惩罚系数P2之和。
另外,由于Lr(p, d)是随像素的右移不停地增长,故像素p的Cost值需要减去前一个像素不同视差值时最小的Cost。这能防止Lr(p, d)数值溢出,让它维持在一个较小的数值。
C(p, d)的计算很简单,由两个公式计算:
定义p移动d个像素之后的像素为q。p和q之间,经过半个像素插值后,C(p, d)的值为两个像素点灰度差值的最小值或两个像素RGB差值的最小值。
上面的计算仅仅表示从左到右的最小Cost值,然而这样的Cost值不够全面。因为一个像素有8个邻域,要从8个方向分别计算Cost值。
然后把8个方向上的Cost值累加,累加值最小的视差值则作为最终视差值。视差图即为每个像素都进行该操作后的结果,具体公式表达如下:
4 实验结果分析与讨论
4.1 Fast-RCNN的物体识别结果和分析
(1)训练结果
将ImageNet数据集训练完成后,将被测样品输入到训练好的FAST-RCNN神经网络模型中,得到预测结果,具体的结果如表1所示。
由表1可知,Fast-RCNN模型在识别物体的效果上,表现得良好。在生活中常见的物品中,识别率能达到80%左右的效果。
(2)迭代次数对实验误差的影响
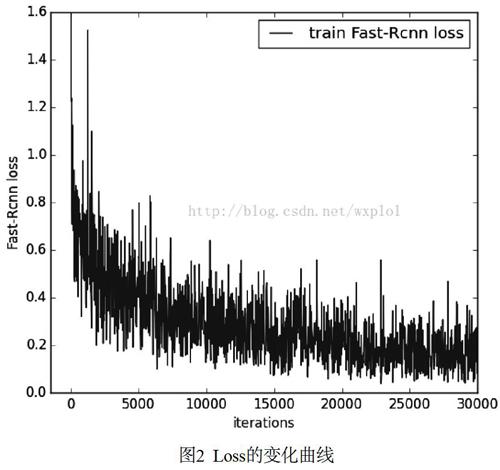
选用之前介绍的方法计算Loss,在训练的过程中调整迭代次数,防止迭代次数过多导致过拟合与迭代次数过少而产生的欠拟合,其中的Loss变化如图2所示。
可以看出随着迭代次数的增加,FAST-RCNN的Loss一直在减小,直到趋于稳定。随着Loss的减少,模型的准确度也在不断的提高,当迭代次数到30000之后,Loss几乎没有明显变化,说明此时的神经网络权值与阈值已经稳定。接下来的实验可以将迭代次数设置为30000次,以进行后续的实验。
(3)mAP性能评估指标
物体识别模型要想应用在实际环境中,必须要拥有良好的性能。现在常用均值平均精度(mAP),来衡量模型的性能,mAP值越高,模型的性能越好[13]。
Mean Average Precision,即平均AP值,是对多个验证集个体求平均AP值。AP值为Average Precision,即对Precision取平均。
[5] 胡越,罗东阳,花奎,等.关于深度学习的综述与讨论[J].智能系统学报,2019,14(1):1-19.
[6] 黄鹏程,江剑宇,杨波.双目立体视觉的研究现状及进展[J].光学仪器,2018,40(4):81-86.
[7] Gu S, Lu D, Yue Y, et al. A new deep learning method based on AlexNet model and SSD model for tennis ball recognition[C].IEEE International Workshop on Computational Intelligence & Applications. 2017.
[8] 杨真真,匡楠,范露,等.基于卷积神经网络的图像分类算法综述[J].信号处理,2018,34(12):1474-1489.
[9] Girshick R. Fast R-CNN[C].IEEE International Conference on Computer Vision. 2015.
[10] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C].International Conference on Neural Information Processing Systems. 2012.
[11] 陈小华,袁卫.基于双目立体视觉的目标定位[J].自动化技术与应用,2017,36(12):102-105.
[12] Humenberger M, Engelke T, Kubinger W. A census-based stereo vision algorithm using modified Semi-Global Matching and plane fitting to improve matching quality[C].IEEE Computer Society Conference on Computer Vision & Pattern Recognition-workshops. 2010.
[13] Yue Y, Finley T, Radlinski F, etal. A support vector method for optimizing average precision[C].International Acm Sigir Conference on Research & Development in Information Retrieval. 2007.
[14] 朱小美,張官进,朱楠.基于MATLAB的布尔莎模型七参数解算实现[J].北京测绘,2015,(5):61-65.
[15] Yan T W, Garcia-Molina H. SIFT: a tool for wide-area information dissemination[C].Usenix Technical Conference. 1995.