候选框密度可变的YOLO网络国际音标字符识别方法
2019-08-27郑伊齐冬莲王震宇
郑伊 齐冬莲 王震宇


摘 要:针对传统方法对国际音标(IPA)的字符特征提取存在的识别精度低、实效性差等问题,提出了一种候选框密度可变的YOLO网络国际音标字符识别方法。首先,以YOLO网络为基础,结合国际音标字符图像X轴方向排列紧密、字符种类和形态多样的特点来改变YOLO网络中候选框的分布密度;然后,增加识别过程中候选框在X轴上的分布,同时减小Y轴方向上的密度,构成YOLO-IPA网络。对采集自《汉语方音字汇》的含有1360张、共72类国际音标图像的数据集进行检验,实验结果表明:所提方法对尺寸较大的字符识别率达到93.72%,对尺寸较小的字符识别率达到89.31%,较传统的字符识别算法,大幅提高了识别准确性;同时,在实验环境下检测速度小于1s,因而可满足实时应用的需求。
关键词:国际音标;字符检测与识别;YOLO网络;深度学习
中图分类号: TP391.1
文献标志码:A
Abstract: Aiming at the low recognition accuracy and poor practicability of the traditional character feature extraction methods to International Phonetic Alphabet (IPA), a You Only Look Once (YOLO) network character recognition method with variable candidate box density for IPA was proposed. Firstly, based on YOLO network and combined with three characteristics such as the characters of IPA are closely arranged on X-axis direction and have various types and forms, the distribution density of candidate box in YOLO network was changed. Then, with the distribution density of candidate box on the X-axis increased while the distribution density of candidate box on the Y-axis reduced, YOLO-IPA network was constructed. The proposed method was tested on the IPA dataset collected from Chinese Dialect Vocabulary with 1360 images of 72 categories. The experimental results show that, the proposed method has the recognition rate of 93.72% for large characters and 89.31% for small characters. Compared with the traditional character recognition algorithms, the proposed method greatly improves the recognition accuracy. Meanwhile, the detection speed was improved to less than 1s in the experimental environment. Therefore, the proposed method can meet the need of real-time application.
Key words: International Phonetic Alphabet (IPA); character detection and recognition; You Only Look Once (YOLO) network; deep learning
0 引言
國际语音字母表(International Phonetic Alphabet, IPA)是国际语音学会为世界各种语言提供的一套强大的语音标注系统,通过采用一种简单的图表方式对音标符号进行分类和命名,目前在国际语言学界以及语言教学领域得到广泛应用[1]。在我国各地方言和少数民族语言文字保护工作中,均需借助国际音标进行记录,可以说国际音标是记录和传承民族、地区文化最重要的载体。
目前,国际音标有103个单独字母,23个元音、72个辅音,已发展成为一种独立复杂的符号系统[2]。但是,现存的字符识别系统还不能对国际音标字符进行高效且准确的识别。
从语言学背景角度分析,其主要原因在于:首先,国际音标是一种专门化的符号系统,往往只有语言学家学习和使用,应用环境相对封闭[3];其次,涉及国际音标的著作较少,影响也小,所以缺乏专门的字符识别系统[4];再次,早期的国际音标符号以拉丁字母为基础,音标符号较少,借助已有的拉丁字母识别系统,可实现部分国际音标符号的识别[5]。然而,随着数字化技术的出现、图像设备的普及以及互联网的迅速发展,越来越多的图书文献以图像的形式出现,这其中也包括以国际音标为载体所记录的文献。为此,对于国际音标字符识别的研究也逐步引起学者的关注。
从技术应用角度分析,传统的字符识别被当作一个分类问题来解决,从字符图像的获取到结果的输出,必须经过5个步骤:图像的获取、字符图像的预处理、字符的特征提取、字符的识别分类和识别结果[6]。其中,字符图像的特征提取最为关键,决定着识别系统的准确率和识别速度。目前,已有研究大多基于统计特征和结构特征提取字符图像的信息,如四边码特征、粗网格特征、梯度角度直方图特征等[7]。但当使用此类特征提取方法时,会产生相似字符区分度差、抗笔画粘连干扰能力弱、局部字符特征描述不足等缺点,导致后续分类器的应用困难、识别准确性下降、模型训练速度减慢,严重制约了国际音标字符识别技术的应用和发展。
随着机器学习技术的发展,基于深度学习的目标检测与定位识别方法得到了广泛引用[8-10]。卷积神经网络(Convolution Neural Network, CNN)作為深度学习常用模型之一,在目标检测与识别方面发挥了举足轻重的作用。Krizhevsky 等[11]利用卷积神经网络对LSVRC-2010 (Large Scale Visual Recognition Challenge-2010)和LSVRC-2012 (Large Scale Visual Recognition Challenge-2012)数据集的1.2×106张图像进行1000种以上的分类,获得了当时最高的分类准确率。基于深度学习的目标检测方法大致可以分为两类:一类是基于区域提名(Region Proposal)的目标检测方法,如R-CNN(Region CNN)[12]、SPP-net(Spatial Pyramid Pooling net) [13]、Fast R-CNN(Fast R-CNN) [14]、Faster R-CNN(Faster R-CNN) [15]、R-FCN (Region-based Fully Convolutional Network) [16];另一类是无需区域提名,基于端到端(End-to-End)的目标检测方法,如YOLO (You Only Look Once) [17]、SSD(Single Shot multibox Detector)[18]等。基于区域提名的方法在精度上占据优势,但端到端的方法在速度上的优势更加明显。
YOLO是由Redmon等[17]于2016年提出的一种全新的端到端检测算法,虽然YOLO也属于CNN,但在检测过程中模糊了候选区域生成、候选区域特征提取、特征输入分类器验证的区别,直接快速地完成了检测任务,可满足实时性检测的需求。国际音标图像排列紧密,且字符的种类、形态多样,综合考虑检测准确性与检测速度,本文提出了一种候选区域密度可变的YOLO国际音标字符识别方法YOLO-IPA,结合国际音标图像特点,合理分布候选框密度,提高检测的准确性,为音标记录文献提供一种稳定、高效、可实时应用的字符识别方法。
1.1 目标检测
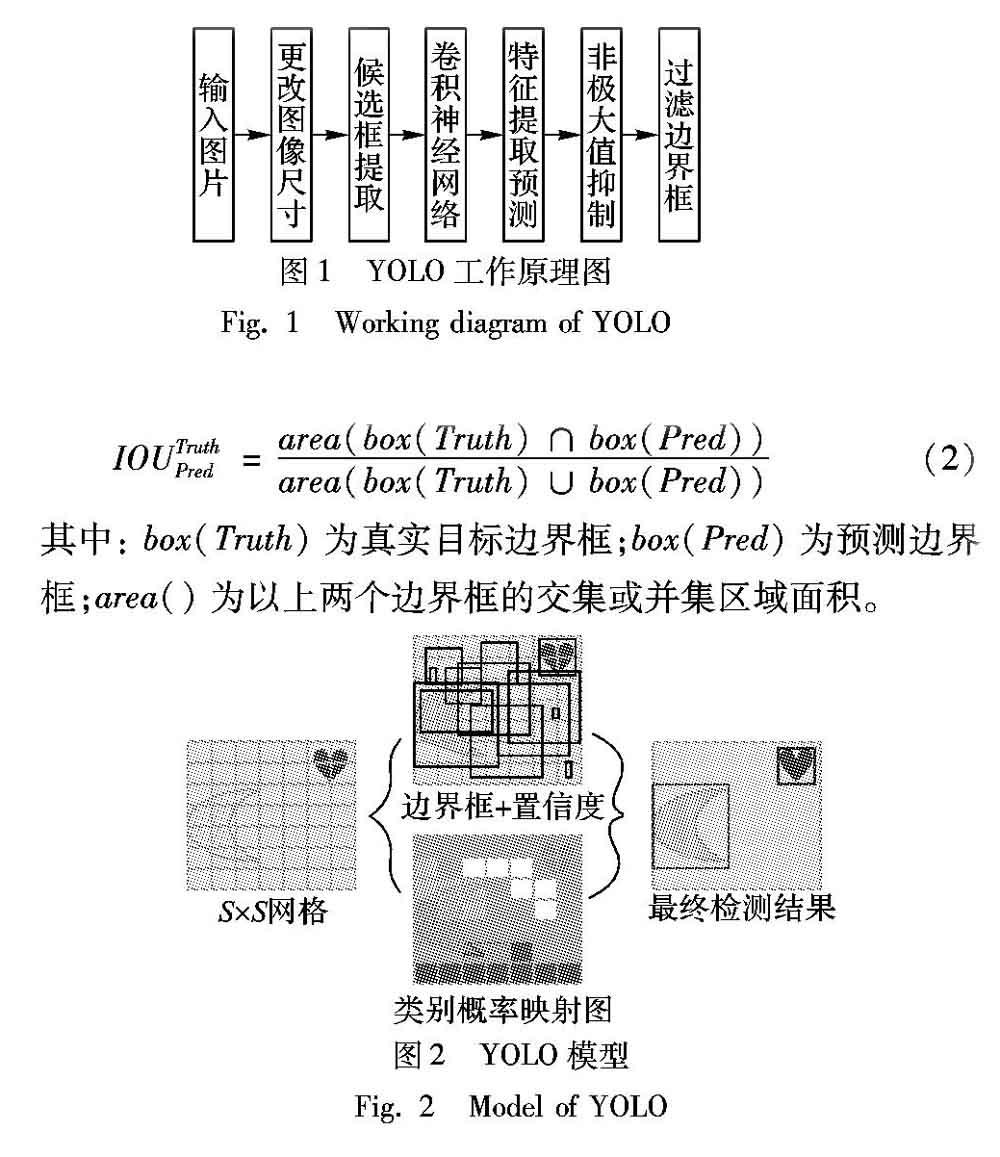
YOLO通过使用来自整个图像的特征预测每个边界框,同时可预测所有类的边界框。如图2所示,YOLO首先将输入图像划分为S×S网格。如果目标的中心落入网格单元,那么网格单元就负责检测该目标。每个网格要预测B个边界框,而每个边界框除了要回归自身的位置之外,还要附带预测所存在目标的置信度,如式(1)所示:
1.2 目标识别定位
每个边界框均要预测(X,Y,W,H)和置信度等5个值,其中,X、Y为预测框中心相对于单元格边界的偏移,W、H为预测框宽高相对于整幅图像之比。同时,每个网络将预测C个类别概率,即Pr(Classi|Object) ,该概率表示第i类物体中心落入该网格的概率。因此,对于输入的每幅照片,最终网络的输出为S×S×(5×B+C)的一个向量。
2 YOLO-IPA网络架构
针对国际音标字符的结构特点,YOLO-IPA首先以YOLO网络结构为基础,采用目标区域网络(Region Proposal Network, RPN)并去除全连接层,使用锚箱来预测目标框;通过在所有卷积层上添加批量归一化处理,改善收敛效果,构成YOLOv2网络[19]。其次,针对国际音标图像中,音标在X轴上排列较为密集的情况,如图3所示,增加识别过程中候选框在X轴上的分布密度,同时减少Y轴方向上的数量,最终构成YOLO-IPA网络,如图4所示。
2.1 RPN
YOLO包含有全连接层,可直接预测边界框的坐标值,但Faster R-CNN仅用卷积层与RPN来预测锚箱的偏移值与置信度,而不是直接预测坐标值。实际应用中,通过预测偏移量而不是坐标值更能够简化问题,降低神经网络的学习难度。因此,本文将使用RPN代替YOLO的全连接层,使用锚箱来预测边界框。虽然使用锚箱会让精确度有所下降,但可同时实现对不低于一千个框的预测,且大大提高了召回率。
2.2 批量归一化
批量归一化可以显著改善收敛性能,而不需要其他形式的正则化。通过在YOLO所有卷积层中添加批量归一化,mAP(mean Average Precision)可获得超过2%的改进效果,同时也有助于规范模型,而不会出现过度拟合[19]。因此,本文在YOLO网络的基础上增加了批量归一化的方法。
2.3 X轴方向候选框扩展
YOLO网络首先将输入图像分成S×S网格,候选框将在X和Y轴上同等密度分布。对国际音标字符进行检测时,如图3所示,音标字符在图像中呈现出在X轴上紧密排列分布、Y轴上分布稀疏的特点,原有的候选框分布规则将难以适用。针对这一问题,本文在此前建立网络上增加AddBoxes层,增加候选框在X轴方向的密度,同时减小Y轴方向候选框密度,构成YOLO-IPA网络。
3 实验结果及分析
为了验证本文所设计网络结构在国际音标字符检测与识别中的有效性,在PC上进行了实验。PC的基本配置如下:CPU双核2.8GHz,GPU采用单块TitanX,12GB显存,32GB内存,Ubuntu 14.04操作系统。深度学习采用Caffe框架训练,训练时间共18h。
3.1 国际音标字符训练集
本文使用的国际音标字符样本来自《汉语方音字汇》。该文献收录了20个汉语方言点的字音材料,基本上可以代表汉语的各大方言:北京、济南、西安、太原、武汉、成都、合肥、扬州(以上官话),苏州、温州(以上吴语),长沙、双峰(以上湘语),南昌(赣语),梅县(客家话),广州、阳江(以上粤语),厦门、潮州、福州、建瓯(以上闽语)。全书共收入3000个字目,按普通话音序排列,用国际音标标写方言读音,该书是汉语语音研究的重要参考书。将全书扫描,按书中表格截出音标字符,国际音标字符如图3所示。
3.2 实验步骤
实验步骤如下:
1)训练算法。使用基于随机梯度下降(SGD)法衍生的批量归一化方法来训练数据。每次随机读取10幅图像进行训练,动量项为0.9,学习率为10-4,偏置学习率为2×10-4,权值衰减系数为5×10-4。前20层卷积层使用原YOLO网络的参数,卷积层转化为RPN的卷积核参数用0来初始化,原网络结构中的dropout操作被保留在原来的位置。
2)微调。通过反向传播算法微调所有层的参数,在原YOLO网络的基础上对RPN进行微调,并遵循Fast R-CNN 中“image-centric”采样策略进行训练。
3)训练数据。收集了1360张、共72类国际音标字符图像,并人工标定了训练与测试用的数据集。训练前没有对字符图像进行任何处理,字符图像的分辨率为300万~2000万像素。
3.3 结果分析
为验证本文提出的增加X轴方向候选框数量以提高检测器性能的有效性,比较了YOLO-IPA与利用选择性搜索(Selective Search,SS)和EB(Edge Boxes)两种不同方法进行可能性目标区域定位,然后分别对可能性目标区域进行方向梯度直方图(Histogram of Oriented Gradient, HOG)、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)特征提取,最后使用K-近邻(K-Nearest Neighbors, KNN)、支持向量机(Support Vector Machine, SVM)、逻辑回归Softmax分类器分别进行实现识别的仿真结果。如表1所示,本文以、、s、k、五种字符为例给出了不同算法的识别精度对比,并以图5为例给出了不同字符的识别结果。
从表1可知,6种方法中,YOLO-IPA均实现了最高精度,YOLOv2次之,而基于传统特征提取的识别算法明显差于深度学习方法。同时,由表1实验结果可以看出,YOLO-IPA方法识别精度与字符大小相关,例如对于尺寸较大的字符(识别精度为93.72%)相比其他较小的字符,如s字符(识别精度为89.31%),具有更高的识别精度,但相比其他算法的识别精度已经有了大幅提升。
4 结语
当前卷积神经网络已经广泛应用在目标识别与检测的研究中,本文采用一种改进的YOLO目标检测架构对国际音标进行定位和状态识别。与传统方法相比,该方法可以有效地对国际音标字符进行识别,但对较小尺寸的目标识别准确率还有待进一步提高,这也是下一步的研究工作。
参考文献 (References)
[1] 燕海雄,江荻.国际音标符号的分类、名称、功能与Unicode编码 [J].语言科学,2007,6(6):82-91.(YAN H X, JIANG D. The classifications, functions, Chinese names of IPA symbols and their unicode [J]. Linguistic Sciences, 2007, 6(6): 82-91.)
[2] 吕佳,江荻.国际音标扩展表的分类、命名与功能[J].听力学及言语疾病杂志,2013,21(6):665-668.(LYU J, JIANG D. The classification, nomenclature and function of extensions to the international phonetic alphabet [J]. Journal of Audiology and Speech Pathology, 2013, 21(6): 665-668.)
[3] 曹雨生,徐昂.微机国际音标系统[J].民族语文,1990(1):74-79.(CAO Y S, XU A. The international phonetic alphabet system in microcomputer [J]. Minority Languages of China, 1990(1): 74-79.)
[4] 潘曉声.国际音标符号名称的简称[J].民族语文,2012(5):56-61.(PAN X S. The name abbreviation of international phonetic alphabet symbols [J]. Minority Languages of China, 2012 (5): 56-61.)
[5] PADEFOGED H,石在.国际音标的一些主要特征[J].齐齐哈尔师范学院学报(哲学社会科学版),1995(2):150-153.(PADEFOGED H, SHI Z. Some major features of the international phonetic alphabet [J]. Journal of Qiqihar University (Philosophy & Social Science Edition), 1995(2): 150-153.)
[6] 邱立松.国际音标字符识别算法的研究[D].上海师范大学,2015:2-3.(QIU L S. Study on the recognition algorithm of international phonetic alphabet characters [D]. Shanghai: Shanghai Normal University, 2015: 2-3.)
[7] 张玉叶,姜彬,李开端,等.一种结合结构和统计特征的脱机数字识别方法[J].微型电脑应用,2016,32(8):76-79.(ZHANG Y Y, JIANG B, LI K D, et al. An off-line handwritten numeral recognition method combined with the statistical characteristics and structural features [J]. Microcomputer Applications, 2016, 32(8): 76-79.)
[8] 陳东杰,张文生,杨阳.基于深度学习的高铁接触网定位器检测与识别[J].中国科学技术大学学报,2017,47(4):320-327.(CHEN D J, ZHANG W S, YANG Y. Detection and recognition of high-speed railway catenary locator based on deep learning [J]. Journal of University of Science and Technology of China, 2017, 47(4): 320-327.)
[9] 白翔,杨明锟,石葆光,等.基于深度学习的场景文字检测与识别[J].中国科学:信息科学,2018,48(5):531-544.(BAI X, YANG M K, SHI B G, et al. Deep learning for scene text detection and recognition [J]. SCIENTIA SINICA Informationis, 2018, 48(5): 531-544.)
[10] 钟冲,徐光柱.结合前景检测和深度学习的运动行人检测方法[J].计算机与数字工程,2016,44(12):2396-2399.(ZHONG C, XU G Z. Movement pedestrian detection method combined with foreground subtraction and deep learning [J]. Computer & Digital Engineering, 2016, 44(12): 2396-2399.)
[11] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// NIPS 2012: Proceedings of the 25th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2012: 1097-1105.
[12] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2014: 580-587.
[13] HE K M, ZHANG X Y, REN S Q, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8691. Cham: Springer, 2014: 346-361.
[14] GIRSHICK R. Fast R-CNN [C] // ICCV 2015: Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 1440-1448.
[15] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[16] DAI J F, LI Y, HE K M, et al. R-FCN: object detection via region-based fully convolutional networks [C] // NIPS 2016: Proceedings of the 30th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2016: 379-387.
[17] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2016: 779-788.
[18] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// ECCV 2016: Proceedings of the 2016 European Conference on Computer Vision, LNCS 9905. Cham: Springer, 2016: 21-37.
[19] REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2017: 6517-6525.
