基于sCARS-RF算法的高光谱估算土壤有机质含量
2019-08-20李冠稳高小红肖能文肖云飞
李冠稳,高小红,肖能文,肖云飞
(1.青海师范大学 地理科学学院,青海 西宁 810008;2.青海省自然地理与环境过程重点实验室,青海 西宁 810008;3.中国环境科学研究院,北京 100012)
1 引言
土壤有机质是土壤肥力和土壤质量的重要指标,是农业土壤最重要的参数之一[1]。快速、精准地掌握有机质含量的空间变化,是精准农业实施和农业可持续发展的重要内容[2]。使用传统化学方法测量土壤有机质含量,分析过程周期长、成本高、一次只能检测一个项目,且对环境有一定污染,很难大规模推广使用[3]。可见-近红外(Visible and near infrared,Vis-NIR)光谱分析技术能够快速、大范围地重复获取同一区域的土壤信息,逐渐成为土壤属性信息快速与长期监测的重要手段之一;且Vis-NIR光谱分辨率高、波段信息丰富,这使得可见-近红外光谱分析技术在土壤有机质的预测分析中表现出巨大的研究潜力[4-7]。但在实际应用中,NIR光谱区域是由含氢基团的倍频和合频吸收峰组成,光谱信息重叠严重,筛选出土壤有机质的光谱响应波段是简化模型和提高模型预测能力的关键。
特征波长选择是可见-近红外光谱研究的一个重要步骤,己经引起了越来越多学者的关注[8-9]。李艳坤等[10]基于集群策略和UVE技术,并进一步结合小波变换,得到了更为简约的模型,提高了PLS模型的预测稳定性能。刘珂等[11]通过一致性策略和连续投影算法结合从全谱波长中选出的一系列波长子集,然后分别基于这些波长子集建立模型,取得了较为满意的预测效果。林志丹等[12]应用SPA和GA进行波长优化,并建立土壤有机质Vis-NIR估算模型,结果显示,对原始光谱进行特征波长优选能够显著提高模型的精度。竞争性自适应重加权算法(Competitive adaptive reweighted sampling,CARS)是由梁逸曾团队开发的一种特征波长变量选择算法,以偏最小二乘模型中回归系数绝对值大小确定最优变量子集[13],而稳定竞争性自适应重加权算法(Stbility CARS,sCARS)以变量的稳定性为衡量指标,并延续CARS算法的变量筛选流程,被证明是一种较优的特征变量选择方法[14]。如刘国富等[15]基于sCARS策略挑选NIR光谱区域特征变量,变量选择的稳定性和准确性都得到了增强,提高了模型精度,预测均方根误差和相关系数分别为0.054 3和0.990 8。丁泊洋等[16]采用sCARS算法挑选特征变量建立多元校正模型,预测相关系数RP为0.978 1,具有较好的预测能力。然而张晓羽等[14]、刘国富等[15]和胡静等[16]均是利用sCARS方法筛选特征变量,并建立线性的偏最小二乘回归(Partial Least Squares Regression,PLSR)模型,与非线性的随机森林(Random forest,RF)建模方法结合的并不多见。与PLSR模型相比,RF模型鲁棒性更好,对异常值和噪声的敏感度更低。
因此,本研究基于青海省湟水流域401个表层土壤的Vis-NIR光谱,应用sCARS方法进行特征波长变量筛选,建立较为简洁、稳定性更好的PLSR和RF模型,并与CARS、IRIV、SPA和GA方法的PLSR和RF模型结果进行比较,探索sCARS算法结合RF模型快速估测土壤有机质含量的可行性,为土地质量评价和高空间分辨率数字化土壤制图提供数据支持。
2 材料与方法
2.1 土壤光谱数据采集与预处理
我们于2015、2016年10—11月期间,采集青海省湟水流域表层土壤(0~20 cm)共428个土壤样品,土壤类型主要为栗钙土、黑钙土、灰钙土、山地草甸土、高山草甸土以及灰褐土;并于室内自然风干,研磨,过100目筛。有机质含量采用重铬酸钾-外加热法测定。使用美国ASD FieldSpec 4光谱仪采集土壤Vis-NIR光谱数据。于暗室内将过筛的土壤样品倒入涂黑的盛样器皿中,减少了外界杂散光的影响,提高光谱质量。盛样器皿直径为10 cm、高度为1.5 cm。光源为光谱仪配套的75 W卤素灯,天顶角为30°,距样品表面45 cm,光线几乎是平行入射到样品上,减少了由于土壤颗粒分布不均匀所造成的阴影影响。仪器光纤探头视场角为25°,垂直向下距样品表面10 cm处,探头接收土壤光谱的区域直径为5 cm,小于盛样器皿的直径,这样既能避免外界杂散光的影响,又能使光纤探头接收到的信号均为土壤样品的反射光谱信息。仪器预热30 min之后进行白板定标,每个土壤样品采集4个方向(间隔90°)共20条光谱曲线,为减少测量时土壤样品光谱各向异性的影响,取20条光谱曲线的算术平均值作为该土壤样品的实际反射光谱数据[17]。土壤样品最终光谱曲线如图1(a)所示。剔除原始光谱中噪声较大的波段(350~400 nm和2 401~2 500 nm),并联合使用多元散射校正(Multiplicative scatter correction,MSC)、中值滤波(Median filter,MF)和一阶微分(1st derivative)对原始光谱进行预处理。图1(b)为经MSC-MF-1st Der预处理后的光谱曲线,从图中可以看出,原始光谱经预处理后,不同有机质含量光谱曲线等级特征不再明显,有效地消除了基线漂移及其他背景的干扰,光谱曲线的细节特征更加突出。
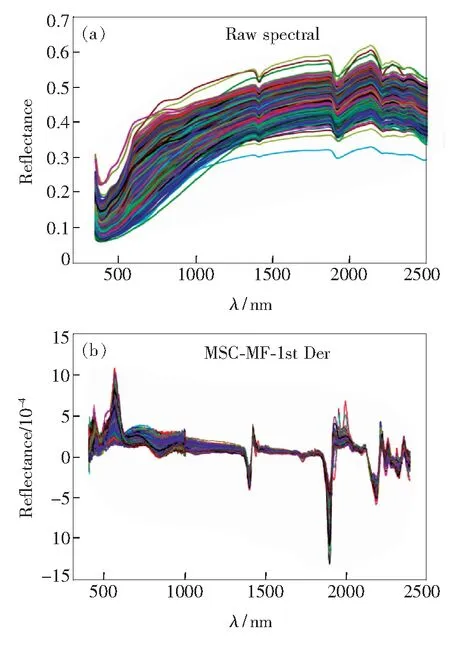
图1 土壤样品原始光谱(a)及预处理光谱(b)反射率曲线Fig.1 Raw(a)and pretreatment spectral(b)reflectance curve of soil samples
2.2 方 法
2.2.1 稳定竞争性自适应重加权采样算法(sCARS)
矩阵XN×P为所测样本光谱数据,N为样本数量,P为变量数。sCARS算法具体步骤为:
(1)计算每个波长变量的稳定性值cj,cj定义如公式(1):
(1)
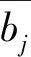
(2)使用强制波长选择和自适应性重加权采样方法(ARS)筛选出变量稳定性值较大的组成一个变量子集,筛选出的变量数占全波段的比率由指数衰减函数(Exponential decay function,EDF)计算。
(3)重复步骤(1)~(2)形成循环,最终得到K个变量子集,建立PLSR模型,然后采用十折交叉验证对这些变量子集进行评估,RMSECV值最小时对应的变量子集作为最后的特征变量子集,K为sCARS算法的循环次数。
2.2.2 随机森林(Random forest,RF)
RF模型是一种分层非参数方法,融合了随机特征选择和Bagging算法两大机器学习技术,与传统的分类器算法相比,不但能较好地容忍异常值和噪声,而且能同时处理连续型和离散型数据[18]。RF模型建模步骤如下:
(1)利用bootstrap重抽样技术从原始训练集N中有放回地重复随机抽取k个样本生成新的训练样本集合;
(3)每棵树最大限度地生长,使每个节点的不纯度达到最小,不做任何修剪;
(4)生成多棵树以形成随机森林,利用随机森林分类器对新的数据进行判别与分类,分类的结果是由树分类器的投票数决定的。
2.3 建模样本集划分
异常样本的存在会对模型的性能产生严重的干扰,因此在光谱建模分析之前有必要对异常样本进行识别与剔除[19]。采用主成分分析结合马氏距离法剔除异常样本,共剔除异常样本27个,最终用于分析的土壤样本共401个。
将异常样本剔除后的401个土样按有机质含量从高到低排序,按2∶1的比例划分校正集和验证集样本。表1为校正集和验证集土壤有机质含量统计表。校正集中土壤有机质含量范围为4.86~148.74 g·kg-1,平均值为32.47 g·kg-1;验证集有机质含量范围为8.26~133.56 g·kg-1,平均值为32.16 g·kg-1。浓度梯度法所划分的校正集样本组分含量涵盖了预测集样本组分含量,避免了过多的“特殊”样本划分为建模集,这样建立的模型能够更好地预测未知样本。

表1 校正集和验证集土壤有机质含量统计表Tab.1 Soil organic matter content statistics of calibration sets and validation sets g·kg-1
2.4 模型精度评价
采用Chang等[20]给出的评判等级,当RPD小于1.4时,表明模型不具备估算能力;当RPD大于等于1.4小于2时,表明模型可对样本进行粗略估算,且可以通过改进模型方法提高模型的预测能力;当RPD大于等于2时,表明模型可以较好地对样本进行估算。
3 结果与讨论
3.1 特征变量选择
3.1.1 sCARS算法特征变量选择
sCARS算法以变量稳定性作为变量选择衡量指标,增强了变量选择的稳定性,并延续CARS算法变量筛选流程。图2为采用sCARS算法挑选特征变量过程图,从图2(a)中可以看出,随着sCARS算法迭代次数的增加,所保留的波长数量逐渐减少,且减少速度由快到慢,表明sCARS算法挑选特征波长变量过程中具有“粗选”和“精选”两个阶段,且“粗选”和“精选”两个阶段存在转折点。图2(b)为十折交叉验证RMSECV值变化趋势图,可以得知,随着运行次数的增加,RMSECV值呈先由大到小再由小到大的变化趋势。当运行次数为27次时,RMSECV值最小,表明在1~27次变量筛选运行过程中,剔除了与土壤有机质含量相关性较小的波长,对建模结果影响不大;而27次之后RMSECV值开始上升,可能是由于删除了与土壤有机质含量相关的变量导致RMSECV值增大,模型效果变差。结合图2(c)回归系数路径变化图可以发现,当运行次数为27次时,RMSECV值最小,即选择的特征波长子集最佳,共选择51个特征变量,仅占总变量数的2.55%。图3为sCARS算法挑选的51个特征变量在一条光谱曲线上的分布情况。
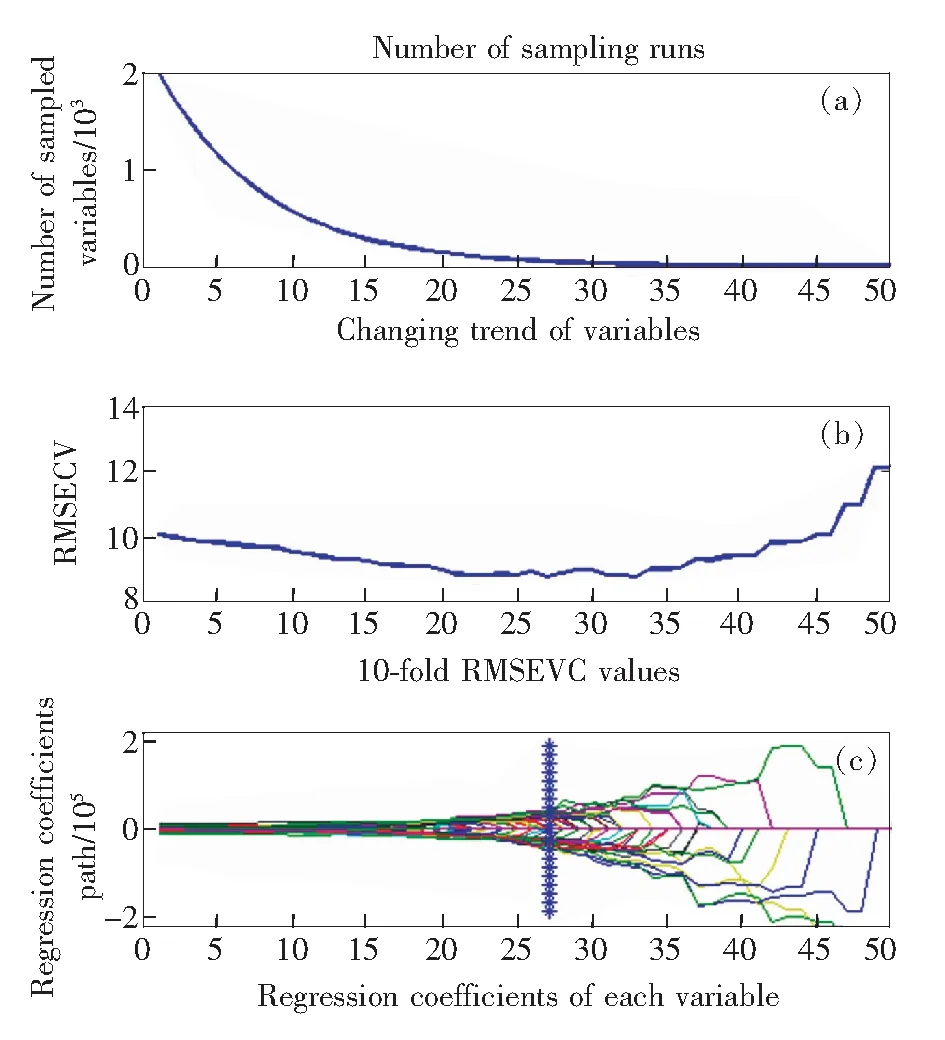
图2 sCARS算法变量筛选流程Fig.2 Variable selection process by sCARS method
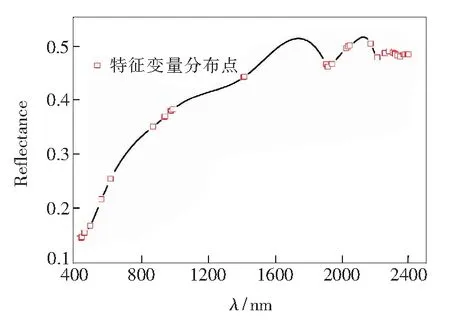
图3 sCARS方法挑选的特征变量分布图Fig.3 Distribution map of characteristic variables selected by sCARS method
3.1.2 CARS、IRIV、SPA、GA算法特征变量选择
CARS算法利用指数衰减函数和自适应重加权技术优选出偏最小二乘模型中回归系数绝对值大的变量点,去除权重值较小的点,再基于十折交叉验证,选出均方根误差最小的变量子集,确定为最优变量组合。本研究基于CARS算法共选择59个特征变量,占全部变量数的2.95%。CARS算法的优点是速度快,最终选出的特征变量的化学意义也比较容易解释,但其选择的特征变量不稳定。
IRIV算法是由中南大学梁逸曾教授课题组提出的一种基于模型集群分析策略的波长选择算法[21],将信息变量分为强信息变量、弱信息变量、干扰变量和无信息变量。IRIV由随机子集生成、子集模型建立、模型参数分析三个环节构成,相对于一般的波长选择算法,IRIV算法具有在波长选择时呈现出软收缩的特点,因此一般能更为稳妥地保留有效波长,但其缺点是计算量较大,因此应用受到限制[22]。本研究基于IRIV算法保留的强信息和弱信息变量数为63个,占全部变量的3.15%。
SPA算法是一种新兴的波长选择算法[23],其原理为基于连续投影策略选择与某一点波长线性相关最小的波长构成一个波长子集,重复上述操作,直至全部波长点选择完毕;然后基于这些波长子集建立模型,根据模型精度进而挑选出最优的波长子集。本研究采用SPA算法共选择出5个最优特征变量,占全部变量的0.25%,分别为1 361,1 758,1 909,2 049,2 213 nm。SPA算法可以尽可能地消除波长变量间共线性的影响,提高特征变量的选择能力,但其缺点是在挑选特征变量过程中倾向于选择共线性较小的变量点而不是有效变量点,因此该算法选择特征变量也不稳定。
GA算法是一种通过模拟自然进化过程搜索最优解的方法[24]。借鉴生物的自然选择和遗传机理,遗传算法主要通过编码、种群初始化、适应度函数、遗传操作和终止条件等步骤优化选择。GA算法具有全局最优、易实现等特点,成为目前最为常用的一种波长选择算法。但同时由于随机选择初始种群,选择、交叉和变异都具有很强的随机性,因此不能保证每个波长选择结果的一致性,故本研究拟采用多次(10次)运行GA算法,选取特征变量筛选结果中出现频率较高的波长,最终作为特征波长用于构建模型,按该方法从原始光谱中共选取186个特征波长变量,占全部变量的9.3%。
图4为CARS、IRIV、SPA、GA算法挑选的特征变量在一条光谱曲线上的分布。从图3和图4中可以看出,5种变量筛选方法挑选的特征波长变量主要分布在1 900~2 400 nm的近红外光谱区域,其中sCARS、CARS、IRIV、GA法筛选的特征变量在可见-近红外光谱区域均有分布,而SPA算法挑选的特征变量较分散地分布于近红外光谱区域内,可见光区域均未被选择。
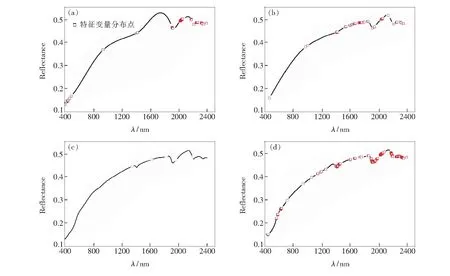
图4 CARS(a)、IRIV(b)、SPA(c)和GA(d)算法筛选特征变量分布图。Fig.4 Distribution map of characteristic variables selected by CARS(a),IRIV(b),SPA(c)and GA(d)method.
3.3 PLSR建模

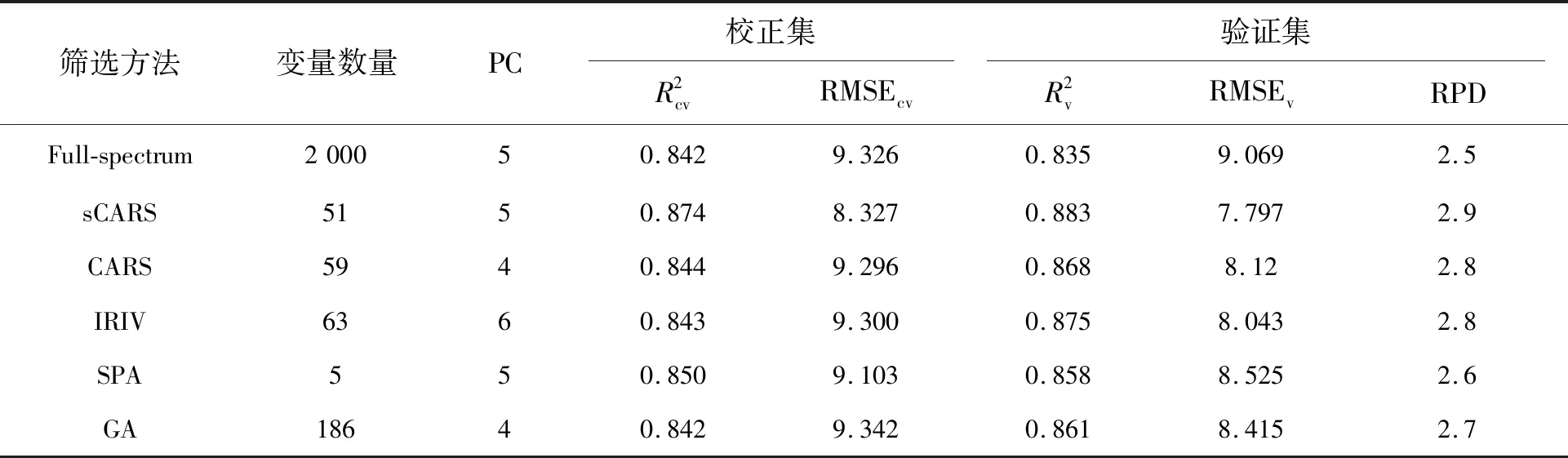
表2 不同变量筛选方法PLSR建模精度Tab.2 Accuracies of PLSR modeling with different variable selection methods
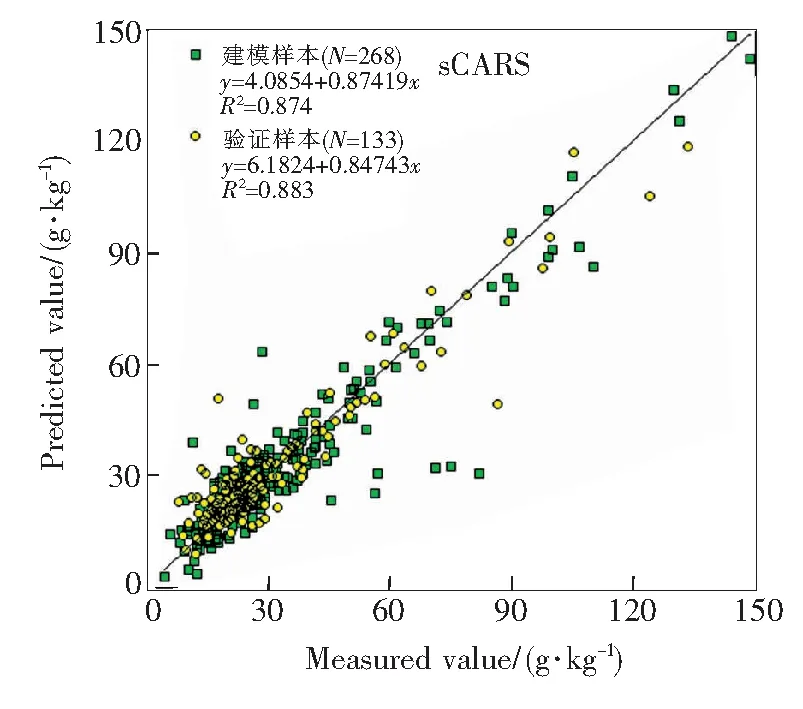
图5 sCARS-PLSR模型预测值和实测值散点图Fig.5 Scatter diagram of predicted and measured values for the sCARS-PLSR model
3.4 RF建模
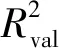
图6为sCARS-RF模型校准集和验证集样本实测值和预测值的散点图。从图中可以看出,sCARS-RF模型校正集和验证集数据点均较为均匀地分布在1∶1直线的两侧,达到了较高的预测水平,这与上述分析一致。
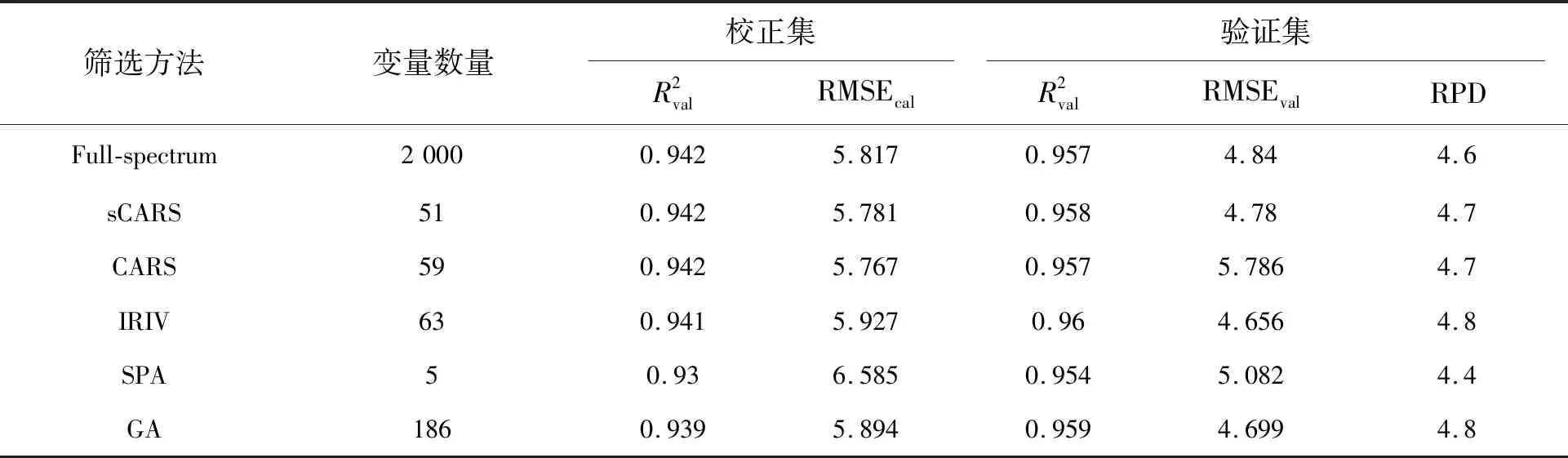
表3 不同变量筛选方法RF建模精度Tab.3 Accuracies of RF modeling with different variable selection methods
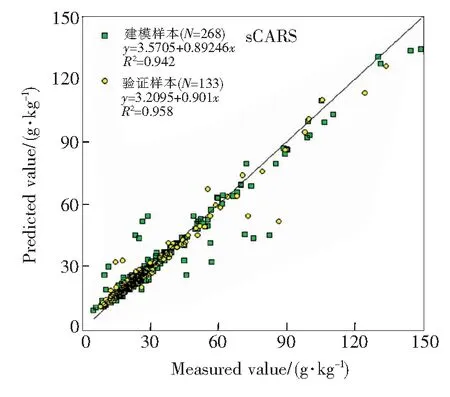
图6 sCARS-RF模型预测值和实测值散点图Fig.6 Scatter diagram of predicted and measured values for the sCARS-RF model
4 讨论
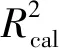
PLRS模型中,sCARS算法模型精度高于CARS、IRIV、GA、SPA和全波段;RF模型中,基于5种变量选择算法模型精度与全波段模型精度相差不大,但其构建模型的变量数却显著减少,大大提高了建模效率。对原始光谱进行特征变量筛选,在保证模型精度的同时大大降低了模型的复杂度。基于CARS、GA和SPA算法挑选的特征变量建模,虽能简化模型,但变量选择的稳定性较差,挑选的特征变量不总是能反映属性信息。IRIV算法虽能较稳妥地保留有效波长,但其缺点是计算量较大,因此应用受到限制。sCARS算法以变量的稳定性作为衡量指标,变量选择分“粗选”和“精选”两个阶段,既提高了变量选择效率,又增加了变量选择的稳定性和准确性。但需注意的是,RF模型的精度并没有像PLSR模型通过应用sCARS算法挑选特征变量而大大增加,且sCARS-PLSR模型精度仍然不如全谱RF模型,这可能是由于RF模型在Vis-NIR光谱数据分析中考虑到大量非线性关系,在PLSR模型与变量选择方法的任何组合中都没有观察到这个特征,这一结果也支持了上述的讨论,对土壤有机质含量的Vis-NIR光谱分析应该采用非线性校准方法以获得最佳预测效果。sCARS算法挑选的特征变量包含了土壤有机质含量最有效的信息,可以代替RF模型的全部原始光谱。
5 结论
以青海省湟水流域401个土壤样本的有机质含量为研究对象,应用sCARS、CARS、IRIV、SPA和GA算法从全波段光谱数据中筛选特征变量,分别建立基于特征波段和全波段的PLSR和RF预测模型,取得了较好的预测效果。主要研究结论如下:
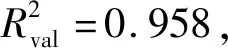
(2)RF模型的预测效果优于PLSR模型。与采用全波段建模相比,使用特征变量建立PLSR模型,模型精度均有提高;采用特征变量构建RF模型对模型预测精度提高帮助不明显,但其构建模型的变量数却显著减少,大大提高了建模效率。对全波段进行特征变量筛选,在保证模型精度的同时大大降低了模型的复杂度。
(3)sCARS算法以变量稳定性作为变量选择衡量指标,有效克服了CARS、IRIV、SPA和GA算法的不足,既增强了变量选择的稳定性和准确性,又提高了变量选择效率,与RF模型结合可实现土壤有机质含量快速、无损、精准估测。
