自适应的SVM增量算法*
2019-05-07韩克平
何 丽,韩克平,刘 颖
天津财经大学 理工学院,天津 300222
1 引言
随着现代计算机和信息技术的发展,数字信息爆炸式增长。为了满足用户快速准确的信息查询需求,分类已经成为智能信息检索的关键技术之一,且在模式识别、图像处理和自然语言处理等领域得到了广泛应用。SVM(support vector machine)算法具有较高的分类准确率和较好的鲁棒性,被广泛应用于解决分类问题[1-2]。为了获得最佳的数据分布估计,传统SVM算法需要将全部待学习数据作为训练样本一起训练。但是,随着数据规模的指数级增长,实际应用中逐渐增加的数据会产生新的分类需求,传统SVM分类算法难以满足这些新的分类需求。增量学习方法是解决这些问题的有效方法之一。增量学习一方面可以根据增量样本的特征分布来动态调整分类决策函数,从而保持较高的分类准确率;另一方面,相较于重新训练一个系统的时间成本更低。
SVM训练的最终目的是根据训练集样本在特征空间的分布来确定最优超平面,确定最终超平面的样本被称为支持向量。在SVM增量学习过程中,最优超平面会随着训练集中样本特征空间分布的变化而被动态调整。因此,如何将最有可能成为新支持向量的样本加入到增量训练集中是SVM增量学习的关键。目前,大多数基于SVM的增量学习算法通过将更多对超平面划分有影响的样本加入到新训练集中的方法来改进SVM增量训练过程。Syed等人最早提出了基于SVM的增量学习算法[3],该算法仅保留支持向量样本,舍弃所有非支持向量的样本。当新样本加入训练时,将原支持向量集与新增样本集合并形成新的训练集。该算法充分考虑了新增样本对分类结果的影响,但是忽略了原训练集中的非支持向量与新增样本在特征空间分布上可能存在差异,在某些情况下会导致分类器最终性能下降。文献[4-5]通过判断KKT(Karush-Kuhn-Tucker)条件的方法调整训练集,在增量学习过程中仅使用不满足KKT条件的新样本,忽略了新样本加入时最优超平面的变化,可能会造成分类知识的丢失,导致分类准确率下降。文献[6-7]以入侵检测为背景,用环形区域选择法和half-partition选择法构建保留集来选择初始样本并进行增量训练,但是这种方法会使加入保留集的样本存在冗余或漏选的现象。李妍坊等人[8]在文献[6-7]的基础上,提出了基于缩放平移选择法构建保留集的方法,同时将部分新增样本加入到保留集中,该算法缩小了保留集的选取范围,但是仍未解决保留集冗余的问题。Zheng等人[9]提出了一种基于学习原型和支持向量的在线增量SVM算法,该算法不仅支持样本增量学习,而且支持类别增量学习。刘国欣[10]通过将增量样本的边界向量与原样本的边界向量进行合并,形成增量学习的训练集,该算法在提取边界向量时重复计算不同类别样本之间的距离,导致时间复杂度较高。Li等人[11]提出了一种基于超平面距离的SVM增量学习算法,该算法根据支持向量的几何特征,利用超平面距离提取样本,选择最有可能成为支持向量的样本形成边界向量集,但是该算法没有考虑到新增样本和原始样本在增量学习训练中对模型影响的差异性。
上述这些SVM增量学习算法虽然获得了较好的分类性能,但是存在样本冗余和信息缺失等问题,可能造成分类器性能不稳定或者训练时间效率较低。本文根据SVM结构化风险最小的优化目标,提出了一种基于超平面几何距离的自适应SVM增量学习算法,该算法根据样本到超平面的几何距离,以不同的权重筛选出新增样本和原始样本集中包含分类知识的样本。该算法能够在保持较好分类准确率和鲁棒性的前提下,有效控制参与增量训练的样本规模,从而减少SVM增量学习的训练时间。
2 SVM理论基础
SVM分类器训练目标是在特征空间中找到一个最优超平面,使训练样本的分类间隔最大[1]。假设给定训练数据集为 {(xi,yi)},i=1,2,…,n,xi∈Rm,yi∈{+1,-1}。则设超平面方程为:

在实际问题中有些数据会存在噪声,出现离群点,为了降低离群点对分类模型的影响,引入“松弛变量”ξi≥0,用以表征样本点xi偏离函数间隔的程度。同时,为了最大化间隔同时保证误分点个数最少,引入一个常数C>0作为惩罚参数,可将优化问题描述为:
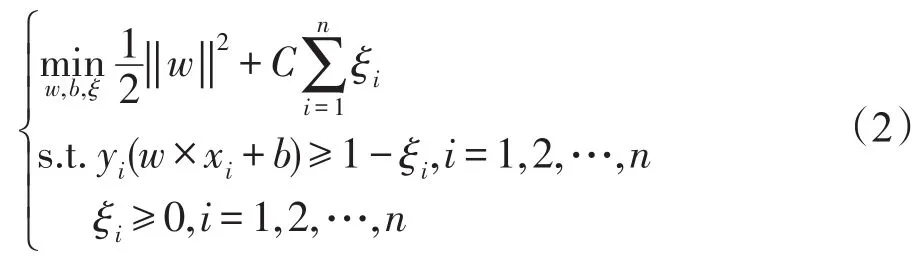
其对偶问题为:
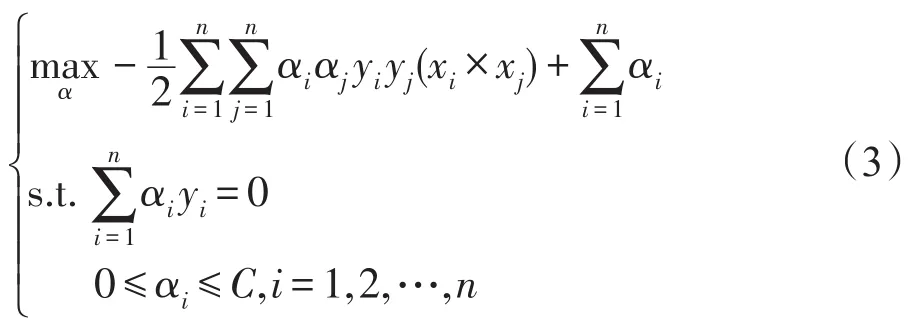
其中,αi为拉格朗日乘子。通过求对偶问题的最优解α=[α1α2…αn],使得每个样本都满足优化问题的KKT条件:
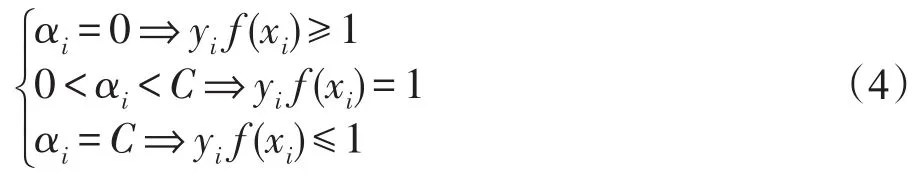
从KKT条件的定义可以看出,αi=0时,其样本对决策函数没有影响;αi>0时,对应的样本为支持向量。
由此可知,只有训练集中的支持向量对分类超平面有影响,因此,在训练集不变的情况下,支持向量集和训练集是等价的。但是,新增样本加入时,可能会导致这种等价关系的破裂。根据文献[12]的研究结果,当新增样本全部满足KKT条件时,新增样本的加入不会影响当前的支持向量集,分类器的决策函数不会发生改变;若存在不满足KKT条件的新增样本时,支持向量集会发生改变,当前分类器的决策函数也会随之发生变化。文献[13]也提出,当新增样本中存在违背当前分类器KKT条件的样本时,原始样本集中的非支持向量有可能在增量训练中转化为支持向量。
图1中用S0表示原始训练集,S1表示新增样本集,原样本集中靠近超平面1/3处的样本用黑色圆圈标出,用与分类超平面平行的红色直线划出距离超平面1/3处样本与超平面之间的样本。其中,(a)表示新增样本集与原始样本集分布基本一致时的分类超平面的变化,(b)表示新样本集与原始样本集的数据分布变化较大时的分类超平面的变化情况。从图中可以看出,新增样本的数据分布对原模型的分类超平面有直接影响。
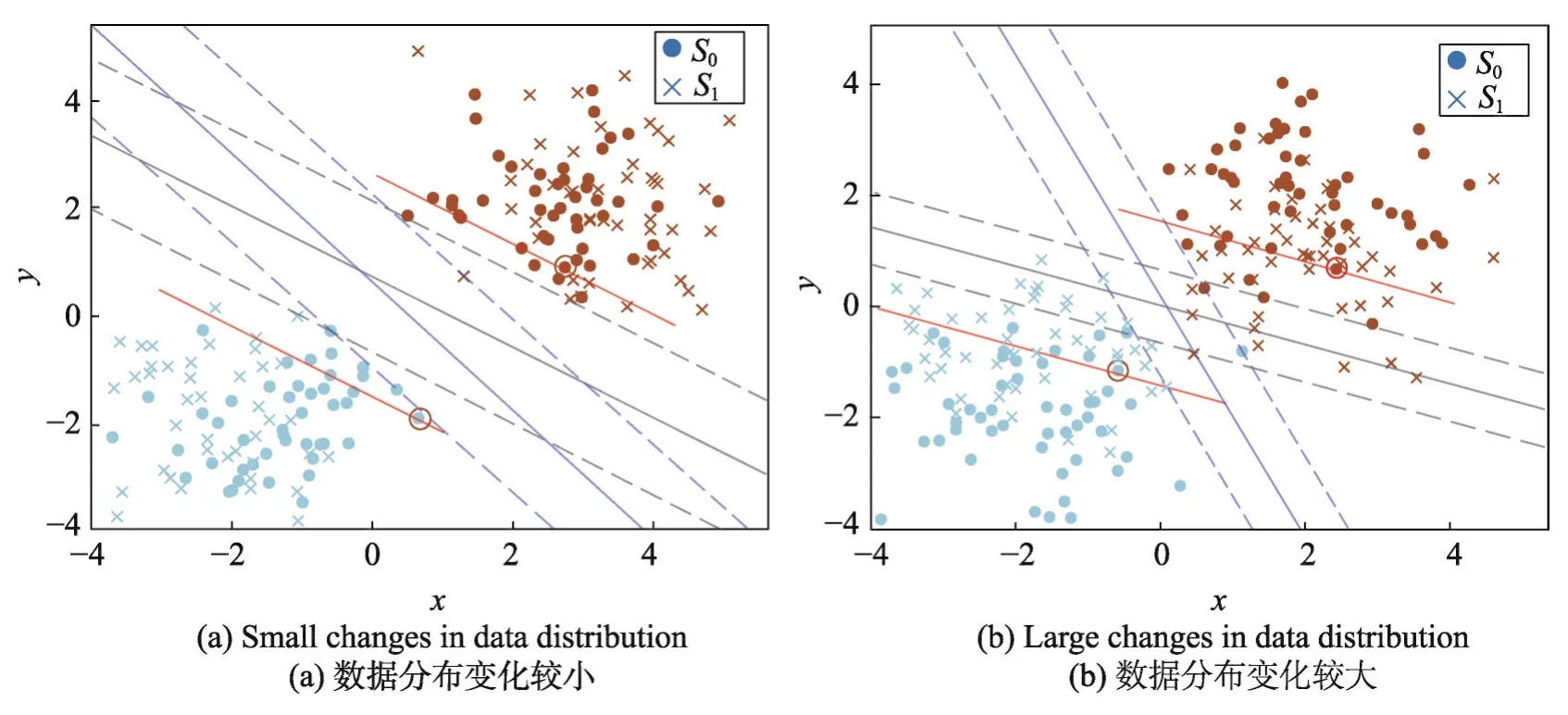
Fig.1 New samples influence on SVM classification图1 新增样本对SVM分类面的影响
在图(a)中,由于新样本集中不满足原模型KKT条件的样本较少,因此在新样本集S1加入后,分类超平面的偏转较小,并且,原模型训练集S0中距离超平面较近的部分非支持向量变成了支持向量。
在图(b)中,新样本集S1加入后,由于新样本集的数据分布变化较大,使得分类超平面的偏转较大。并且,从图中可以看出,新样本集中满足原模型KKT条件的部分样本也变成了新模型的支持向量。
同时,从图1中可以看出,在增量过程中,样本成为新支持向量的可能性与其到超平面的几何距离有关。在超平面发生偏转后,原模型非支持向量集中转化为新模型支持向量的样本,大都位于原样本集中靠近超平面1/3处的样本与分类超平面之间。
3 自适应的SVM增量学习算法
根据样本的空间分布特征以及支持向量集的变化规律,本文提出了一种自适应的SVM增量学习算法(self-adaptive incremental support vector machine,SD-ISVM)。该算法以增量样本和新增样本空间分布的相似性为调整系数,分别为原训练集和增量样本集设置不同的筛选阈值,并根据样本到超平面的几何距离确定边界向量。
定义1(几何距离) 给定样本集D={(xi,yi),i=1,2,…,n},xi∈Rm,yi∈{+1,-1}和超平面 (w,b),样本点 (xi,yi)到超平面(w,b)的几何距离γi的计算方法如式(5)。

3.1 原模型保留集构建方法
在现有的增量SVM算法中,许多学者在进行增量学习时,都会考虑到原模型中非支持向量样本,但是大部分算法没有考虑增量情况的不同,而且保留方法比较复杂,从而造成算法效率偏低。实际上,当原始样本集与新增样本集的分布相似时,原样本集中的边界向量在新模型支持向量中占比较高;反之,原始样本集中的边界向量在新模型支持向量中占比较低。在增量过程中,原模型中非支持向量成为新模型支持向量的可能性与其到超平面的几何距离的大小有关,并且从图1的支持向量变化情况分析可知,原始样本集中的边界向量大都在距离超平面几何距离1/3处的样本与原模型的分类超平面之间。为此,本文选择样本到超平面的几何距离作为筛选条件来构建原模型保留集。在设定原模型保留集的筛选阈值时,根据原样本集和新增样本集的分布变化情况,使用sim函数来实现阈值的动态变化,以减少原样本保留集的冗余。
为方便表达,令原始样本集中正例样本到超平面几何距离的集合为,原样本集中负例样本到超平面几何距离的集合为,且集合中样本按γi的升序排列,D0为的并集。同样地,新增样本集中正例样本到超平面几何距离的集合为,新增样本集中负例样本到超平面几何距离的集合为,且集合中样本均按γi值升序排列,D1为的并集,m和n分别为集合中样本的总数,。为了适应样本空间分布的变化,引入了自适应阈值θold,计算方法如式(6)。
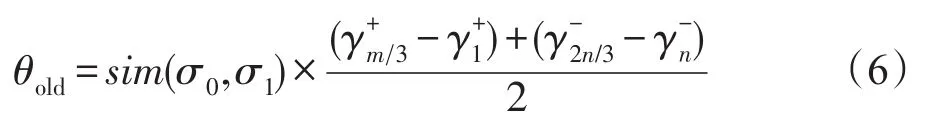
其中,σ0和σ1分别为D0和D1上的样本总体方差;sim()是新旧样本在特征空间分布的相似度计算函数,定义如下:
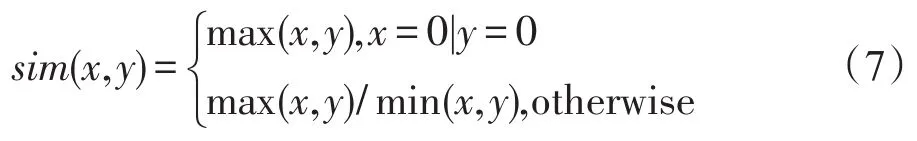
当增量样本中出现不满足KKT条件的样本时,从原模型的非支持向量集中保留距离超平面几何距离小于等于θold的样本,加入到原模型的保留集中。
当筛选阈值设定的距离过大时,会造成保留集中样本冗余,而设定的距离过小时,则可能丢失有用的分类知识。根据前面的分析,这里分别使用集合中靠近超平面1/3处的样本与对应集合中最靠近超平面的样本之间差值的平均来计算θold。其中,sim函数根据特征空间分布相似性来控制θold。为保持分类器的稳定性,当sim函数的值越大时,需要从原模型中保留的样本数量就会越多;反之,当原样本和新样本在特征空间的相似度越高,即sim函数的值越小时,需要保留的样本数量就会减少。
3.2 新增样本保留集构建
目前流行的增量SVM算法在增量训练时大多选择舍弃新增样本中满足KKT条件的样本,但是,从图1的分析可知,当新增样本中存在不满足原模型KKT条件的样本时,当前的SVM决策超平面和支持向量集都会受到影响,新增样本中满足原模型KKT条件的样本也可能会成为新模型的支持向量。文献[6]虽然考虑了这部分样本的保留问题,但是没有根据新增样本满足原模型KKT条件的具体情况进行讨论,并且这些文献中大都使用固定阈值进行样本筛选,这样可能会造成新增样本保留集的过度冗余,从而影响模型的泛化性能和效率。同时,当新增样本中满足原模型KKT条件的比例不同时,分类超平面的偏转情况也是不同的。针对这一情况,本文在确定新样本保留集时,设置了动态的新样本筛选阈值θinc,以适应不同增量特征分布的变化情况,θinc的计算方法如式(8)。
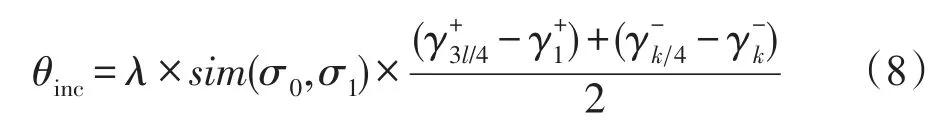
其中,σ0和σ1分别为D0和D1上的样本总体方差;λ为基于当前模型分类准确率的调整系数,定义为:

式中,r为增量样本中符合原模型KKT条件的样本数占增量样本总数的比例,表示增量样本被正确分类的比例,l和k分别为集合中样本的总数,。
考虑到新增样本是首次参与SVM训练,相比于原模型样本保留集的构造,对新增样本保留集的构建,分别使用集合中靠近超平面3/4处的样本与对应集合中最靠近超平面的样本之间差值的平均来计算θinc。
当增量样本中出现不满足KKT条件的样本时,保留增量样本集中满足KKT条件且超平面几何距离小于等于阈值θinc的样本。
由图1可以看出,增量样本中满足KKT条件的样本越多,即r越大,新模型的分类超平面发生的偏转越小,增量样本中包含新分类知识的样本就越少,因此,需要保留的样本就越少;反之,增量样本中满足KKT条件的样本越少,即r越小,新模型的分类超平面发生的偏转越大,增量样本中包含新分类知识的样本就越多,最后需要保留的样本就越多。为适应r的变化,这里使用λ动态调整筛选阈值θinc,当r变大时,λ减小,θinc也随之减小,使得保留的样本数减少;反之,增大λ,使保留的样本数增加。
3.3 自适应的SVM增量学习算法
本文根据特征空间分布的相似性和样本到超平面的距离,同时保留原样本集和新增样本集中满足KKT条件的样本蕴含的分类知识,提出了一种新的SVM增量学习算法SD-ISVM。SD-ISVM的算法描述如下:
输入:原样本集X0,新增样本X1,当前原分类模型Ω0。
输出:增量学习后的模型Ω。

4 实验
4.1 实验设计
为了验证本文提出算法的可行性和有效性,使用了4个不同领域的开放数据集:APS、Mushroom、Bank和KDD Cup。实验中将每个训练集随机分为10份,将其中的1份作为原始训练集,其余作为新增样本集1~9进行增量,并对每一次增量训练产生的分类模型在测试集上进行测试。各数据集的训练样本、测试样本个数和特征维度、正负样本比例和各增量数据集与训练数据集正、负类特征中心距离的均值如表1所示。
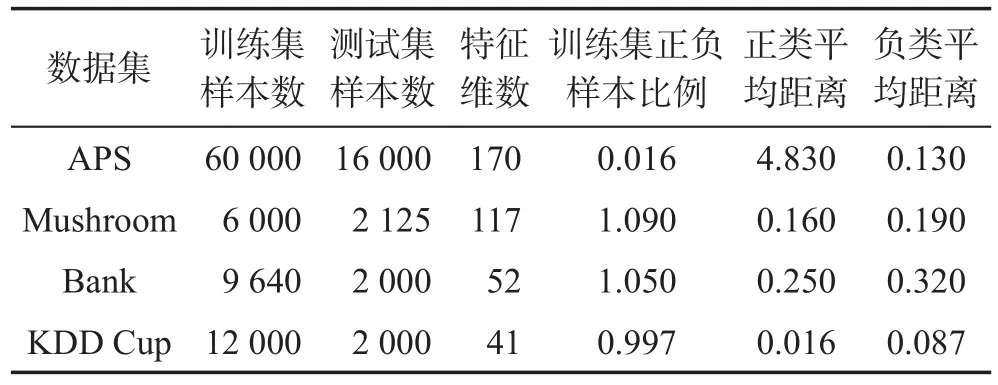
Table 1 Experimental datasets表1 实验数据集
由表1可知,各个数据集上,新增样本集与训练数据集的特征分布存在一定的差异,尤其是APS的正、负类样本比例与特征空间分布都表现出明显的不平衡性,且正类增量样本在特征分布上的变化较大。为验证SD-ISVM算法的有效性和泛化性能,本文使用上述几种不同特性的数据集进行了实验,同时使用KKT-ISVM(Karush Kuhn Tucher-incremental support vector machine)[4]、CRS-ISVM(combined reserved set-incremental support vector machine)[8]、HD-ISVM(hyperplane distance-incremental support vector machine)[11]算法作为对比实验项。实验环境为24 GHz的Xeon e5-2630处理器,16 GB内存,软件环境采用python 2.7.13。
4.2 性能评估
分类器的性能度量是对分类器的分类性能和泛化能力的评估,常用的评价指标主要包括:正确率、召回率、敏感性、特异性等。AUC(area under curve)是一种结合敏感性和特异性的性能评价指标。PACBayes(probably approximately correct learning-Bayes)边界是分类器上最紧的泛化边界,能够用来评价学习算法的泛化性能[14-18]。本文使用PAC-Bayes边界和AUC对SVM增量学习过程中产生的分类器泛化性能进行验证和分析。
4.2.1 准确率和AUC
准确率表示被正确分类的样本占总样本的百分比。准确率越高,分类器的性能越好。正确率评价指标ACC的计算方法如式(10)。

其中,TP、FP、TN和FN分别表示真阳性、假阳性、真阴性和假阴性的样本数量。
AUC表示“受试者工程特征”(receiver operating characteristic,ROC)曲线下方的面积。AUC的值越大,分类器的性能越好。假定ROC曲线是由坐标为{(x1,y1),(x2,y2),…,(xm,ym)}的点按序连接而形成的(x1=0,xm=1),则AUC计算方法如式(11)。
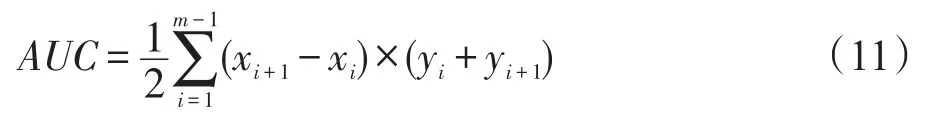
4.2.2 泛化误差边界
PAC-Bayes理论融合了Bayes定理和随机分类器的优势,能够为各种学习算法提供最紧的泛化误差边界[14]。根据文献[14]的PAC-Bayes定理,PAC-Bayes边界越低,分类器的真实误差越小,分类器的泛化性能会越好。因此,本文使用PAC-Bayes边界来衡量SVM增量学习模型的泛化风险边界。
4.3 实验结果及分析
4.3.1 稳定性对比
图2描述了不同算法在不断加入增量样本后AUC的变化情况,曲线的波动越大,表示算法的性能越不稳定;反之,说明稳定性越好。从图2中可以看出,相比于其他3个数据集的AUC值能够快速稳定在较好的水平,APS数据集在前4次增量训练过程中出现了明显波动。造成这种波动的原因是,APS数据集中的正负样本比例和增量样本特征空间分布均处于极不平衡状态。即使在这种极不平衡的情况下,本文提出的SD-ISVM算法仍然能得到一个稳定且分类性能良好的超平面,这是其他几种对比算法不能达到的。
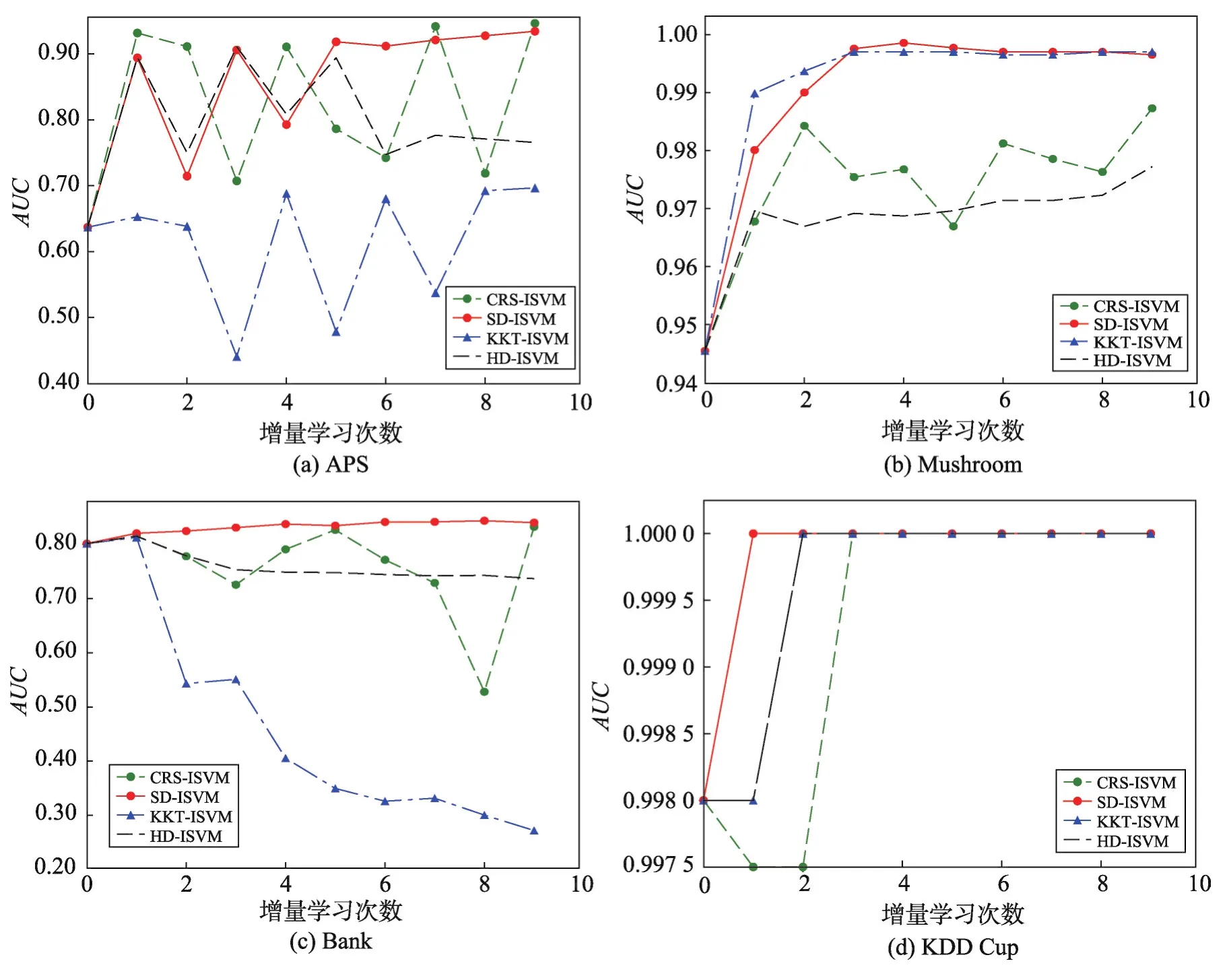
Fig.2 Contrast ofAUC图2 AUC对比
对比各种算法在4个数据集上的AUC曲线可以发现,SD-ISVM算法在每个数据集上的AUC值总体上表现最好。分析原因主要是因为SD-ISVM算法在样本保留的过程中,使用了支持向量的空间特征和增量过程中超平面的变化情况,尽可能地保留了新旧样本中对分类决策函数有贡献的样本,弥补了其他算法在增量过程中分类知识丢失的问题,从而获得了较好的稳定性。这说明本文提出的SD-ISVM算法具有更好的分类性能。
4.3.2 泛化能力对比
表2为各种算法在不同数据集上增量学习得到的模型PAC-Bayes最优边界值和分类准确率,PBB(PAC-Bayes bound)表示PAC-Bayes最优边界。分类准确率和PAC-Bayes边界有很高的负相关性,即分类准确率越高,PAC-Bayes边界会越低。对SVM算法来说,PAC-Bayes边界越低,算法的分类边界会越紧,分类器的泛化性能越好。分类准确率与PACBayes边界的和越接近1,模型的分类效果越好。从表2中可以看出,在大部分数据集上,各算法的分类准确率与PBB之和均接近于1。在分类准确率相同时,CRS-ISVM、KKT-ISVM和HD-ISVM算法的PACBayes最优边界都稍大于SD-ISVM算法。以上说明,SD-ISVM算法的模型泛化性能与其他算法基本保持一致,甚至会在某些数据集上高于其他算法。
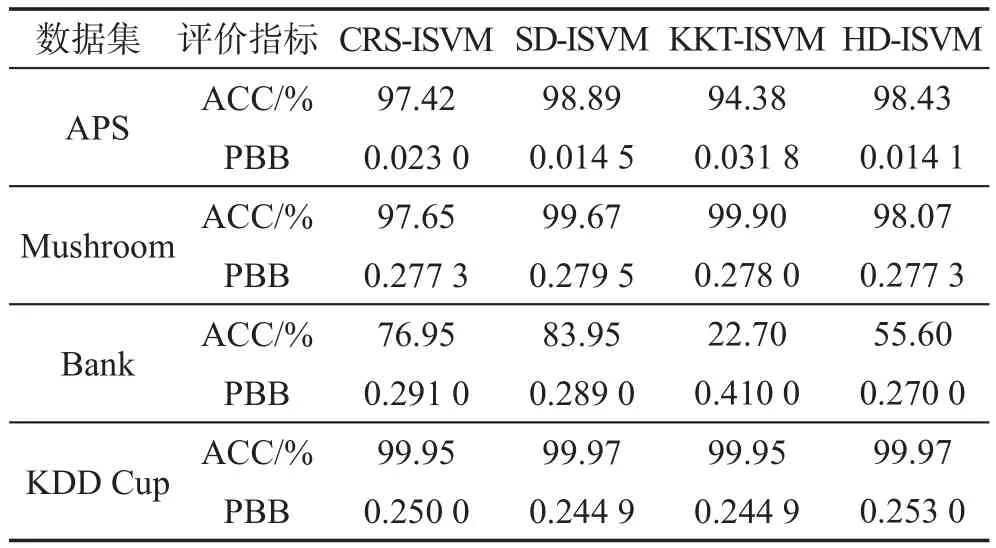
Table 2 Contrast of classification accuracy and PBB表2 分类准确率和PBB对比
4.3.3 训练时间对比
图3描述不同算法在各个数据集上增量训练时间对比情况。从图中可以看出,在APS和Bank数据集上分类时间最长的算法是KKT-ISVM,这是由于KKT-ISVM算法在进行增量时需要多次训练分类器;在Mushroom和KDD Cup数据集上CRS-ISVM算法分类耗时最多,是其他算法的2~3倍,这是因为CRSISVM算法计算保留集的时间复杂度不会随着数据集的复杂度降低而减少。同时可以看出,在大多数数据集上,本文提出的SD-ISVM算法都获得了较好的结果。SD-ISVM在增量学习训练集构建时,可以根据新旧数据集在特征空间分布的相似度变化自动调整新旧样本的筛选阈值,适应增量样本在特征空间分布的变化,从而有效地控制增量学习训练的规模,提高分类器训练的速度。
从上述的实验结果对比可以看出,在所有实验数据集上,相比于其他三种典型的SVM增量学习算法,本文提出的SD-ISVM算法在模型的稳定性、泛化能力和训练时间上总体上保持了较明显的优势。相比于其他几种算法,SD-ISVM算法不仅解决了有贡献样本丢失问题,还有效减少了样本冗余,加快了增量学习的速度。
5 总结
针对现有的SVM增量学习算法在增量过程中分类知识丢失以及时间效率偏低的问题,提出了一种基于特征空间分布的SD-ISVM算法,该算法不仅保留了原始样本集和增量样本集中满足KKT条件的边界样本,还根据新旧样本在特征空间分布的变化情况,从新旧样本集中筛选出满足KKT条件但可能在增量学习过程中转变为支持向量的样本参与训练,以减少新增样本加入时分类知识的丢失,并控制参与增量学习的边界样本数量,来提高分类速度。实验结果表明,本文提出的SD-ISVM算法能够在保持较好分类准确率的前提下,获得更好的稳定性和SVM增量学习的训练速度。
Fig.3 Contrast of training time图3 训练时间对比
