K-means型多视图聚类中的初始化问题研究*
2019-05-07贾彩燕王晓阳
洪 敏,贾彩燕+,王晓阳
1.北京交通大学 计算机与信息技术学院,北京 100044
2.交通数据分析与挖掘北京市重点实验室,北京 100044
1 引言
由于不同测量方法的使用,多视图数据广泛存在于各种应用中[1-7]。例如由文本、图片、视频和超链接组成的网页,以及图像数据中SIFT(scale invariant feature transform)[8]、HOG(histogram of oriented gradient)[9]、LBP(local binary pattern)[10]、GIST[11]、CTM(color texture moment)[12]和CENTRIST[13]等不同的局部特征描述。也就是说,这些数据集上同一实例有多种不同的表示形式,这些表现形式常被称为视图。既然不同的视图从不同角度对数据进行了描述,并且具有不同的判别力,那么如何有效结合来源于多个视图的数据,并找到满足所有视图的最优划分是当前研究领域的一个热点。
K-means算法不仅可以用在传统的单视图学习中,还可以拓展到多视图场景下。本质上讲,K-means型多视图聚类算法不仅存在K-means算法初值敏感和类个数事先指定的问题,还由于综合考虑来自多个视图的数据而造成了数据规模不一的现象。目前,多视图聚类中常用的初始化方法是随机初始化和全局核K-means[14]初始化方法。前者因随机性使得聚类效果不稳定,后者结果虽具有确定性,但是在大规模数据中比较耗时。另外,这两种初始化方法都需要事先指定类数目。那么如何有效解决K-means型多视图聚类的初始化问题呢?本文基于单视图下的K-means初值敏感和类个数选择问题,研究了现存的多种经典初始化方法,如随机初始化、K-means++[15]、全局(核)K-means、基于蒙特卡洛取样(Markov chain Monte Carlo,MCMC)的初始化方法AFKMC2(assumption-freeK-MC2)[16]和密度峰值快速搜索方法(clustering by fast search and find of density peaks,DPC)[17],并将这些方法应用于K-means型多视图聚类算法的初始化中,研究不同的初始化方法对K-means型多视图聚类效果的影响。另外,还提出了一种基于采样的主动式初始中心选择方法(sampledclustering by fast search and find of density peaks,SDPC),进一步优化K-means型多视图聚类的初始中心和类个数的选择策略。多个多视图基准数据集的实验结果表明:不同的初始化方法可以改善K-means型多视图聚类的效果。与DPC相比,SDPC在聚类精度和效率上取得了较好的折衷。
2 相关工作
针对多视图学习研究者们进行了很多研究。目前,现存的大部分多视图聚类方法都是采用最小化不一致性的思想将单视图经典算法拓展到多视图场景下[18]。Bickel和Scheffer[18]提出两视图场景下的EM(expectation maximization)算法和K-means算法。另外,他们也研究了多于两个视图的混合模型估计问题[19]。de Sa[20]提出了一个二视图谱聚类方法。这种方法的主要思想是为视图创建一个二部图以描述两个视图中信息共现的情况。Blaschko、Lampert[21]和Chaudhuri、Kakade等人[22]从典型相关性分析考虑,他们认为可以先投影数据,再进行聚类。Zhou和Burges[23]提出一个面向多视图聚类中的正则割(normalized cut)框架。这个模型包含一个先验参数,用于决定每个视图的相对重要性。Kumar等人[24-25]使用来自一个视图的谱嵌入,进而在其他视图上进行聚类,目的是为了保持不同视图上聚类结果的一致性。Wang等人[26]也设计了一个多视图谱聚类方法。该方法是依赖Pareto优化寻找所有视图上最佳公共割。Nie和Li等人[27]提出一个新型的无参数自动加权的多图学习框架。这种方法可以用于多视图聚类中。Nie和Cai等人[28]从具有自适应性的近邻角度提出了一种新型的多视图聚类算法。以上方法都集中研究了不同视图之间的关系。
经典的K-means聚类是一种基于中心的聚类方法[29]。由于具有计算成本低、易于并行处理的特点,K-means聚类被广泛应用于大规模的数据聚类问题中。但是算法结果易受到初始聚类中心的影响。若选取的初始类中心比较好,根据Forgy方法将数据点指派到相应的初始类中心,最终会得到在全局上最优的聚类结果。但当初始中心选择不好时,容易产生空类,得到不好的划分结果。因此,学者们给出了多种不同的初始类中心选择方法,如K-means++和AFKMC2等。
面对多视图聚类问题,研究者们也提出了多种K-means型多视图聚类算法,如WMKC(weighted multi-viewK-means clustering)、MVKKM(kernel-based weighted multi-viewK-means clustering)[30],WMCFS(weighted multi-view clustering with feature selection)[31]和 RMKMC(robust multi-viewK-means clustering)[32]。其中,WMKC算法考虑了不同视图的重要性,MVKKM用于处理非线性可分的多视图聚类问题,WMCFS综合考虑数据视图和视图特征的贡献,进一步优化多视图聚类效果,RMKMC在目标函数ℓ2,1范式下考虑视图的重要性。值得关注的是,这些K-means型多视图聚类算法不可避免地存在K-means聚类中初始中心敏感和类个数事先指定的问题。因此,本文将单视图的各种初始化方法用于K-means型多视图聚类中,进一步研究对多视图聚类的效果。
3 K-means型多视图聚类算法和初始化算法
本章详细介绍几种经典的K-means型多视图聚类算法和K-means常用的初始化方法。
3.1 K-means型多视图聚类算法
(1)WMKC算法
当处理多视图数据时,直接的方法是将所有视图特征拼接起来执行K-means聚类算法。在所有视图中,每个数据都会被指派到同一个簇。但是这种方法平等看待每个视图,从而聚类结果也没有得到优化。因此通过对多视图数据的每一个视图增加权重参数,进而体现出不同视图的重要程度,将该方法简记为WMKC。相应的目标函数如式(1)所示:

ωv表示第v个视图的权重,满足。p1是根据先验知识选择的参数,用于控制视图权重ωv的分配。是在视图v中簇k的中心。由于不同视图下数据表示形式不一,从而同一个簇的簇中心也是不同的。
(2)MVKKM算法
Tzortzis和Likas[30]提出基于核的加权多视图K-means算法(MVKKM)。与上述普通带权多视图K-means算法(WMKC)相比,它可以处理非线性可分的簇。主要是通过预先定义的核函数将数据映射到一个高维特征空间中,并将其作为算法的输入。一般情况下,对于所有视图可采用线性核函数和高斯径向基核函数进行变换。相应的目标函数如式(2)所示:

(3)WMCFS算法
Xu和Wang等人[31]提出具有特征选择的加权多视图聚类算法(WMCFS)。该算法通过对视图和视图中的特征施加两种不同的加权模式,从而在聚类时选出最优视图和每个视图中最具代表性的特征。目标函数如式(3)所示:
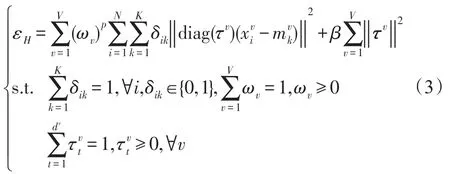
τv表示长度为dv的特征权重向量,表示在视图v中第t个特征的权重。是用于控制特征权重向量τv的稀疏性。
(4)RMKMC算法
利用G-正交非负矩阵分解等价于松弛性的K-means聚类[33],Cai和Nie等人[32]引入类指示矩阵重新设计了K-means聚类目标函数,如式(4)所示:

式中,X∈Rd×n是具有d维特征n个数据点的数据矩阵,F∈Rd×K是簇中心矩阵,G∈Rn×K是簇指示矩阵,每一行有且只有一个Gik=1。在此基础上,Cai等人[32]提出了一种具有鲁棒性的多视图K-means聚类算法(RMKMC)。目标函数如式(5)所示:

上式中含有共同的簇指示矩阵G,且目标函数上施加了结构性稀疏约束ℓ2,1-范式,从而对含有异常值的输入数据具有鲁棒性。
3.2 类初始化方法
目前,K-means型多视图聚类中常用的初始化方法有随机初始化和全局核K-means初始化方法。随机初始化结果具有不确定性,全局核K-means虽初始中心唯一,但是在大数据中耗时太长。另外,这两种方法都需要事先指定类个数。
针对单视图下K-means聚类中存在的初值敏感和类个数指定问题,学者们给出了多种初始类中心选择策略:如随机初始化、K-means++、AFKMC2和DPC初始化方法。
(1)随机初始化
随机初始化是聚类中最常用、最直接的类指派方法,即随机将每一个数据点指派到K个类之一。但是结果受随机影响大。
(2)K-means++初始化
Arthur和Vassilvitskii[15]提出用于为K-means聚类选择初始值(种子)的算法(K-means++)。核心思想是使所选取的K个种子之间尽可能得远。该方法首先随机选择一个点作为初始聚类中心;接着计算数据中每一个点x与所选最近类中心之间的距离D(x);当选择一个新的数据点作为下一个中心时,D(x)越大,越有可能被选为类中心,直到选出了K个类中心为止。但是这种种子选取策略需要计算所有点到类中心之间的距离。当数据量很大时,这种方法计算复杂性高。另外,这种方法也可能选到异常值或者处于密度低的区域点作为类中心,出现次优的聚类结果。
(3)基于蒙特卡洛取样MCMC的初始化方法
Bachem和Lucic等人[34]提出一种加速K-means++采样的方法(K-MC2)。该方法基于MCMC采样,首先随机选取第一个类中心,接着使用均匀分布下的Metropolis-Hasting算法[35]构建一个长度为m的马尔可夫链,选择下一个中心不再需要对所有数据点计算D(x),只需要计算链上m个点和所选类中心的距离。由于K-MC2在数据集服从特定分布时才能得到较好的效果,因此文献[16]又提出了一种新型的初始化方法 Assumption-freeK-MC2,简称 AFKMC2。其中,Metropolis-Hasting算法采用非均匀分布,服从任何分布下的数据均可应用该算法。
(4)全局核K-means算法
基于全局K-means[36]和核K-means[37]算法,Tzortzis和Likas[14]提出了具有增量确定性的全局核K-means算法。该算法使用K-means局部搜索策略对全局进行优化以克服初始中心敏感的问题。每执行一次核K-means得到一个最佳的簇中心,直至得到K个类中心。算法步骤如下:
算法1全局核K-means算法
输入:数据集X={x1,x2,…,xn}的核矩阵,类数目K。
输出:类划分(K个类中心)。
步骤1K=1执行核K-means算法找到类中心m1(1)。
步骤2K=2时,初始中心是(m1(1),xn)执行核K-means,重复执行n次,找到最佳类中心(m1(2),m2(2))且核K-means目标函数误差最小。其中,xn∈X。
步骤3依此类推,直到找到K个最佳的类中心。
这种方法的优势是具有确定性,聚类结果不受类初始化的影响。同时能够划分输入空间中非线性可分的簇。但该方法计算复杂度过高,不适于处理数据集较大的聚类问题。
(5)密度峰值快速搜索方法(DPC)
Rodriguez和Laio[17]提出一种基于密度的聚类算法。他们认为类中心需要满足两个条件:一是类中心是密度较大的点;同时,不同类中心之间具有相对较远的距离。在算法中使用ρi描述样本i的局部密度,δi描述类中心之间的距离。具体定义如式(6)和式(7)所示:

其中,dij是样本i和j之间的距离,dc是样本密度的邻域半径。当χ≺0时,χ(x)=1,否则χ(x)=0。

但若i是局部密度最大的样本,则令δi=maxjdij。
可见类中心是那些ρi和δi都比较大的点,因此该方法在决策图右上角选择K个点作为类中心,并将剩余数据指派到与其距离最近且密度比它大的数据样本所在的簇中。该方法利用主动式策略解决了类个数和类中心选择的问题,通过一次指派策略完成类划分。当样本间距离给定时具有较高的聚类效率,但当数据规模太大,且样本间距离未事先给定时,样本点对间距离计算时间复杂度高。
4 基于采样的主动式初始中心选择方法
目前,多视图学习常用的思想可分为两种:一是分别对每个视图聚类,再按照某个规则集成它们的结果;另一种是将来自不同视图中的信息融合到一个统一的表示空间中,然后在该空间下寻找最佳类划分。无论使用哪种方法,与传统的单视图聚类一样,多视图聚类效果也会受到初始类中心的影响。因此,可考虑将单视图下的初始化结果作为多视图聚类中的初始中心。但这种方式也有一定的问题:首先,由于事先无法确定多个视图间的重要性差异,这种初始化方法需要选择哪个视图用于初始化;其次,大部分初始化方法需要提前指定类个数,而类个数需要专家知识,不容易获得。虽然DPC初始化方法可以确定类个数和类中心,但是在多视图场景下,由于考虑了多个视图的数据使得数据规模较大,会造成DPC算法中距离计算复杂度过高的问题。
对于K-means型算法初始中心的选择并不一定要求是类中心,只要分散在各个类中即可。针对以上问题,提出一种基于采样的主动式初始中心选择方法(SDPC)。在SDPC中,首先对原始数据均匀采样,利用DPC算法在样本集上获得类中心和类个数,再将其作为多视图K-means的初始中心,最终得到类划分结果。对于多视图场景下的初始样本选取共有两种方法:选择其中的一个视图或将多个视图融合之后作为初始数据。SDPC算法的流程如算法2所示。
算法2基于采样的主动式初始中心选择算法(SDPC)
输入:Xv或者是X',采样比例ρ。其中,Xv∈{X1,X2,…,XV},X'表示融合视图。
输出:K-means型多视图聚类的类划分。
步骤1对Xv或X'按采样比ρ均匀采样,得到样本Xs。
步骤2在Xs上使用DPC算法获得初始类个数K和类中心InitCen。
步骤3以K和InitCen在X'上运行K-means算法。
步骤4得到多视图K-means的初始类划分。
其中,X'的融合方式有三种:一是不考虑视图重要性直接融合多个视图;二是核函数下的视图权值融合;三是视图权和特征权下的双权融合模式。
相比随机初始化、K-means++、全局核K-means初始化和AFKMC2初始化方法而言,本文所提出的基于采样的主动式初始中心选择方法(SDPC)通过主动式选择类中心和类个数解决了K-means型聚类算法在单视图和多视图场景中的初值敏感问题。另外,在中心选择方面,SDPC中采样策略和K-means再迭代策略的应用不仅加速了密度峰值快速搜索方法(DPC)的中心选择效率,还能进一步确定初始类划分,进而改善了聚类效果。
5 实验与结果
本章将基于采样的主动式初始中心选择方法(SDPC)和现有的其他五种初始化方法应用到K-means型多视图聚类算法中,并在标准数据集上进行实验。实验结果采用标准化互信息[38]和纯度[39]两个标准聚类评估指标。另外,计算了初始化所需时间衡量不同初始化方法在K-means型多视图聚类中的效率。
5.1 数据集描述
本次实验采用的数据集是Handwritten numerals(http://archive.ics.uci.edu/ml/datasets/Multiple+features)、Caltech101-7[40]、MSRC-v1[41]、COIL-20(http://www.cs.columbia.edu/CAVE/software/softlib/coil-20.php)和Pascal Visual Object Classes 2007(http://host.robots.ox.ac.uk/pascal/VOC/)。前4个数据集的多个视图之间是同质的,都利用不同特征描述同一图像,最后一个是由文本和图像构成的异质视图数据集,数据集总体情况如表1所示。

Table 1 Datasets summary表1 数据集情况
HW(handwritten numerals):由2 000个0~9数字类组成的手写体数据。该数据共有6个特征:76 FOU(Fourier coefficients of the character shapes)、216 FAC(profile correlations)、64 KAR(Karhunen-Love coefficients)、240 PIX(pixel averages in 2×3 windows)、47 ZER(Zernike moments)、6 MOR(morphological features)。实验中仅使用前5个具有代表性的视图。
Caltech101-7:是一个由101类组成的对象识别数据集。实验中仅选取广泛使用的7个类,即Face、Motorbike、DollaBill、Garfield、Snoopy、Stop-Sign、Windsor-Chair,共1 474张图片。由图片的48维Gabor feature,40维 Wavelet Moments,254维 CENTRIST feature,1 984维HOG feature,512维GIST feature,928维LBP feature形成多个视图。
MSRC-v1:是一个含有8个类240张图片的场景识别数据集。选择7个类,即tree、building、airplane、cow、face、car、bicycle。每个类有30张图片,把每张图片的4个可视化特征(24维CM(colour moment),512维 GIST,254维 CENTRIST,256维 LBP(local binary pattern))作为不同视图。
COIL-20:是一个含有1 440张、20个类的哥伦比亚图像数据集,且每个类含有72张图片。由图片的1 024维密度、3 304维LBP和6 750维Gabor特征构成3个视图。
Pascal Visual Object Classes 2007(VOC 2007):该数据集是有关自然图像的数据。采用其中的20个类aeroplane、bicycle、bird、boat、bottle、Bus、car、cat、chair、cow、dining table、dog、horse、motorbike、person、potted plant、sheep、Sofa、train、tv/monitor,并选取5 649张图片用于实验。由图片的512维GIST特征和图片标注的 TF-IDF(term frequency-inverse document frequency)值组成两个不同的视图。
5.2 聚类评价指标
为了评价各种初始化方法在不同多视图算法上的聚类效果,文中使用标准化互信息(normalized mutual information,NMI)[38]和纯度(Purity)[39]。
(1)标准化互信息(NMI)
该衡量预测类标与真实类标的相近程度。计算公式如下:

式中,C是真实的类标,C'是计算得到的类标,K是真实类数目,K'是算法中的类个数,表示真实类i中节点的数量,表示计算出的类j中节点的数量,nij表示将类i的节点分配到计算后j中节点的数量。
(2)纯度(Purity)
纯度是另一个评价聚类质量的指标。纯度越高,聚类效果越好。计算公式如下:

式中,Ω=(ω1,ω2,…,ωK)表示算法中的聚类结果,C=(c1,c2,…,cj)表示实际类别集合,N是数据总数。
5.3 结果比较
本节具体展示不同初始化方法下K-means型多视图聚类算法在多个基准多视图数据集上的实验结果。对于AFKMC2,由于m=200时表现出较好性能,选用链长m=200。对于SDPC,选择性能稳定且较优的采样比例。在Handwritten numerals、Caltech101-7和COIL-20数据集上选取20%的采样率,MSRC-v1和Pascal Visual Object Classes 2007选取50%的采样比率。表2~表5展示了5个基准数据集的多视图算法在不同初始化方法上NMI、Purity和初始化用时。其中HW数据集在WMKC、MVKKM和RMKMC算法上参数值分别为p1=10,p2=3和r=2,WMCFS参数值分别为p=10和β=0.1;Caltech101-7数据集在WMKC、MVKKM和RMKMC算法上参数值分别是p1=15,p2=5和r=16,WMCFS参数值分别为p=5和β=0.000 5;MSRC-v1数据集在WMKC、MVKKM和RMKMC算法上参数值分别为p1=25,p2=5和r=10,WMCFS参数值分别为p=14和β=0.000 1;COIL-20数据集在WMKC、MVKKM和RMKMC算法上参数值分别为p1=10,p2=8和r=8,WMCFS参数值分别为p=5和β=0.5;VOC2007数据集在WMKC和MVKKM参数值分别为p1=30和p2=15,WMCFS参数值取p=20和β=0.000 5。VOC2007在RMKMC算法中全局K-means初始化在24 h没有得到实验结果,使用其他五种初始化方法时目标函数无法收敛,表中使用“*”表示。另外,最好结果加粗表示,次优结果用斜体加线表示。“—”表示24 h内该算法在数据集上没有得到实验结果。

Table 2 NMI,Purity and Time comparison results on different initialization methods of WMKC表2 WMKC中各初始化方法的NMI、Purity和Time结果

Table 3 NMI,Purity and Time comparison results on different initialization methods of MVKKM表3 MVKKM中各初始化方法的NMI、Purity和Time结果

Table 4 NMI,Purity and Time comparison results on different initialization methods of WMCFS表4 WMCFS中各初始化方法的NMI、Purity和Time结果

Table 5 NMI,Purity and Time comparison results on different initialization methods of RMKMC表5 RMKMC中各初始化方法的NMI、Purity和Time结果
总体上看,不同的初始化方法在K-means型多视图聚类算法中表现出不同的性能,本文所提出的基于采样的主动式选择初始中心的方法(SDPC)较密度峰值搜索算法(DPC)在精度和效率上取得了较好的折衷。从表2~表5可看出:全局(核)K-means初始化方法效率较低,不适于实际中较大规模数据的聚类。AFKMC2较K-means++而言,采样速度明显加快,但聚类精度有时略有损失,如表2和表3所示。SDPC可以主动式选择类数目和类中心,加上均匀采样策略和K-means再迭代策略的选择,不但在效率上优于DPC,在精度上也常优于DPC的直接指派策略。
同时,还对比了单视图下的SDPC初始化方法在多视图聚类方法中的效果。以HW数据集的WMKC聚类方法为例,展示了采样比例为20%的聚类结果,见表6。
由表6可见,相比在融合空间进行SDPC初始化,mfeat_fou视图使用采样比是20%的SDPC初始化方法在WMKC多视图聚类效果是最好的。但是由于事先未能知道该视图的重要性,存在着初始化视图选择问题,因此在实验中选用多个视图融合之后再进行初始化的策略以对比各初始化方法的优劣。

Table 6 Results on HW of different views表6 HW中不同视图下的结果
另外,由于SDPC的聚类效果受采样比例的影响,选取了有代表性的同质视图数据集HW(见图1)和异质视图数据集VOC2007(见图2)验证不同采样比例对各K-means型多视图聚类算法性能的影响。
由图1可看出,总体上数据集HW上受SDPC数据集采样比例的影响较小,在一定程度上可以改善聚类效果。另外,WMCFS由于自身算法的特点,不同采样比例下的SDPC聚类效果是最优的。总体上看,当采样率是20%时,多视图聚类算法的NMI值相对理想,可推测出该方法下所获得的初始中心是分散在每个类中的。

Fig.1 NMI of SDPC on HW in different sampling ratios图1 不同采样比下SDPC在HW上NMI变化情况

Fig.2 NMI of SDPC onVOC2007 in different sampling ratios图2 不同采样比下SDPC在VOC2007上NMI变化情况
由于在VOC2007数据集上使用RMKMC聚类方法没有得到聚类结果,因此图2中仅展示了其他三种多视图聚类方法上的NMI值。可以看到:该数据集下NMI值对SDPC的采样比例是敏感的。初始的采样量较少时,聚类效果比较差。可推测是因为该数据集上视图间是异质的。当采样比例达到50%及以上时,三种方法的NMI值有了明显的提升。
6 总结
本文在K-means型多视图聚类算法中应用了单视图下现有的不同初始化方法,并提出了一种基于采样的主动式初始中心选择方法(SDPC),研究不同初始化方法对多视图聚类效果的影响。实验结果显示:全局(核)K-means虽类划分具有确定性,但是效率较低。AFKMC2通过加速K-means++采样方法,在大规模数据中效率有明显的提升。DPC从密度角度考虑,可以自适应地选择类中心和类个数,但是计算复杂性还可进一步改善。所提出的SDPC方法不仅避免了多视图初始化时的单视图选择问题,还在一定程度上克服了DPC时间花费高和内存开销大的缺点。同时,SDPC方法中的K-means再迭代策略进一步优化了初始中心选择策略。总体来说,不同的初始化方法在K-means型多视图聚类算法中表现出不同的性能,SDPC较DPC在精度和效率上取得了较好的折衷。
