结合动静态分析实现架构恢复的方法*
2019-05-07任武
任 武
上海立信会计金融学院,上海 201620
1 引言
软件架构是系统设计、维护以及程序理解活动的一项重要制品。对于大型遗留软件系统而言,由于不断的功能变迁和版本演化,原有的架构文档经常缺乏必要的更新而变得过时。通过源代码分析获取系统的功能结构成为程序理解的一种可靠来源[1-3]。在这种情况下,维护人员通常采用聚类的方法将系统划分为更小和更易于控制的子系统,使得同一子系统中的对象比在不同子系统中的对象有更高的相似性,这种利用软件聚类将程序元素作为组件结合在一起,是从底层源代码中获取高层结构视图的一项重要技术[4-6]。
传统的聚类在软件维护方面主要采用静态分析技术。静态技术使用的两种主要信息类型是结构(程序元素间依赖和继承关系)和语义(代码的注释和标识符)。使用静态源代码进行软件聚类的优点是自动化程度高,但局限性之一是静态方法通常只使用程序元素的相似类型估算待聚类的程序元素之间的距离[7]。例如,仅使用从代码注释和标识符提取的文本(词法)的聚类方法[8-9]或者仅使用文件/类名称[10-11],或基于控制和数据流图的依赖特征[12-14],条件是需要足够的输入来处理,且系统遵循“高内聚、低耦合”的基本原则进行良好设计[4],以及代码标识符命名具有良好的质量和规范等。另一方面,面向对象系统由于存在多态和动态绑定等因素,使得在功能架构的恢复中,需要考虑系统的运行时特性。
为了理解行为系统属性,动态信息更具有相关性[15]。一些信息恢复方法使用单独的动态信息[16-17],动态分析通过执行特征获取系统的运行时事件。功能特征是构成实现其组件实体的自然聚类,根据系统的不同的特征,将各个系统组件聚合在一起实现各自的特定功能,反映了软件系统构件化组装的思想,因此基于特征的聚类恢复架构方法是可行的。而实现基于特征的聚类,首先需要建立特征和代码实体的对应关系,动态分析成为解决这个问题的一种可靠方式。但动态分析也有其局限性:第一,动态执行迹通常所含事件数量巨大。第二,动态架构恢复需要功能全面且平衡的测试用例或场景集来支持。因此,动态和静态分析各有其优缺点。作为解决这个问题的一种方法,Pollet等人[12]强调需要使用多个输入源来实现架构恢复。Scanniello等人[13]使用词法和结构如依赖和继承信息来解决源代码中的概念定位问题。Mancoridis等人[14]使用结构和词法文本特征来提取应用程序的分层体系结构。Greevy等人[18]介绍了一个基于动态分析的特征驱动的方法,通过提取跟踪来获取特征和软件实体的明确映射关系。Eisenbarth等人[19]表明确定代码对应关系的可靠的方式是通过运行相关的特征和分析收集的事件执行迹。由于动态分析的前提是设置与特征有关的用例并运行,因此动态分析收集的事件概念容易与特征建立起关联。在动态分析方面,已经有大量的研究工作[15,20-26],但多集中在特征定位和软件模式[27-28]方面,将动态分析应用到聚类的架构恢复方面的研究目前还比较欠缺。
在上述研究的基础上,本文提出将静态和动态分析结合起来的分阶段聚类方法,以软件特征作为聚类标准来构建系统的框架划分。为提高动态分析的效率,利用语义信息在数据处理方面的优势,将动态获取的“实体-特征”矩阵作为“词项-文档”矩阵处理。通过TF-IDF(term frequency-inverse document frequency)方式设置关键词项权重值,创建潜在语义索引(latent semantic indexing,LSI)空间,计算SVD(singular value decomposition)近似值以替换完整的“词项-文档”矩阵。结合动态跟踪与静态结构分析,使用系统依赖信息进行软件聚类。虽然现有多种聚类方法[4-5]是半自动的或自动化的,但仍需要与维护人员相互作用的改进反馈过程才能达到令人满意的最终结果[15,22,29]。为此,利用代码的静态依赖图,以及动态调用图,构建完整的类依赖关系,反馈到特征和场景设计步骤,补充完善已建立的框架,以达到结构恢复的目的。
2 相关工作
软件聚类和系统结构的恢复作为软件领域的研究热点,已经有大量的研究工作:Mancoridis等人[4]提出一种优化目标函数的图聚类方法,其目标是找到高内聚和低耦合模块化聚类。Corazza等人[30]在源代码中定义了类名称、属性名称、方法名称、参数名称、注释等不同区域,然后利用区域的权重计算源代码类之间的相似关系并聚类。该方法主要是通过语义词汇建立实体的关联。Kuhn等人[8]描述了一种基于潜在语义索引的方法。该方法是独立于语言的,并对具有相似术语的源代码实体进行分组。但没有考虑建立代码实体之间的对应关系。Dugerdil[31]提出使用执行迹作为抽样数据的依据进行逆向架构的恢复过程,这与本文动态分析方法相类似,但抽样数量对实验结果影响较大,且缺乏较高层的抽象概念如特征或模式等作为聚类标准。Tzerpos等人[32]提出一种增量聚类算法模拟工程构建子系统的模式,与本文基于特征实现方法不同,该算法是基于模式的抽象概念来构建框架,在实现上依赖于前期初始条件的输入。
3 基于特征的聚类方法
本文的结构恢复方法的流程如图1所示。主要分为两个阶段:第一阶段,执行特征场景获取动态事件执行迹,利用k-means聚类建立系统的核心架构;第二阶段,根据收集到的执行迹,分析特征执行迹中的各个实体间的动态依赖关系。将与特征相关的未执行的代码实体(如类或方法等),比较语义相似度,确定是否需要归类到对应的簇中。通过迭代补充场景和特征的方式,逐步恢复已建立的框架结构。

Fig.1 Structure recovery approach图1 结构恢复方法
3.1 生成特征-实体矩阵
通过分析系统的源代码结构、系统的需求文档和在线帮助,调查相关应用领域中的类似系统等方式,可以确定软件系统的特征。选择具有软件特征的任务执行方案的场景描述称为特征的特定场景。通过执行特定场景,可以快速地获取特征和代码的映射关系。例如,有一项任务,需要修改应用程序的“print”功能,但是对于许多软件系统来说,依靠研究源代码很难发现所有与“print”特征相关的代码部分,因为实现一个特征可能涉及多个类或模块。而通过设置程序的代码插装并执行该特征,就可以分析执行迹确定出代码的哪些部分由该特征执行,从而降低了定位任务的复杂性。在特征执行时,会产生一系列运行事件称为执行迹,事件包括对象的建立和删除、方法的调用等。执行迹中的实体,可以选择不同的粒度来表示(如方法或类)。本文选择类实体作为分析的对象,因为类的粒度较大,通常一个类用一个源文件表示,类的行为特征通过类中各方法的调用和依赖等关系表现出来。
通过设置标记插装代码和收集调用实体来获取特征执行迹,会产生一系列方法调用的entry/exit列表,为了使生成的大量的跟踪数据易于分析,在预处理步骤中,通常移除由程序循环引起的所有冗余调用。对于在执行迹中大量的与特征无关的公共实体,使用类似TF/IDF的方法对收集的实体设置权重值加以区别[33]。其中,词项(term)用于对应执行迹中的调用实体,词频(frequency)是该实体调用的次数,文档(document)对应每条执行迹,预处理用于获取“词项-文档”矩阵和词频率-逆文档频率,每对(词项,文档)值设置如下的相关的权重:

3.2 构建基本框架
通常使用聚类的非极端分布(non-extreme distribution,NED)值作为评价一个聚类算法质量的指标。一般评价认为当聚类数小于5或大于20属于极端值,都是不合理的。NED值越大,表示非极端的聚类分布越好。

式(2)中,c是划分C中的一个簇,|c|表示c的基数,N是所分析系统的软件实体的数量,NED的值大小介于(0,1)之间,越接近于1表示聚类的实体分布越合理。根据NED的聚类分布要求,输入是动态产生的特征-实体文档集,输出是按NED最大的实体集划分。
算法1划分算法(partitioning algorithm)

在算法1中,第1~3句是计算“词项-文档”矩阵,根据式(1)求出TF-IDF值,基于LSI计算“词项-文档”转置矩阵的相异度。第5~10句执行k-means算法,迭代移动各个簇的记录的均值中心点,直到收敛,并比较NED值的大小,返回最大的NED函数值的划分。
3.3 依赖性分析
分析源代码程序控制流程图,可以建立代码实体之间的调用依赖关系,而数据流程图则反映出系统的业务关系。
定义1(调用依赖性) 设场景中包含的特征以及调用序列构成二维矩阵,R2⊆S×(M×M),(si,p,q)∈R2,∀p,q∈si&&p→q,表示在场景Si实体p一次或多次调用另一个实体q。
定义2(系统类之间依赖关系) 设C(s)是系统类的集合,R(C)表示类的依赖关系,结构类的依赖性包括类的继承、聚合和类的方法调用集合等,则实体p与实体q的结构类的依赖性定义为:

根据定义1,在动态调用的实体间进行扩展,构建类的动态依赖图,静态依赖图则需要通过源代码分析获取。根据定义2,需要考虑在两个类之间各种可能的关系,如方法调用、泛化关系、实现关系等。在具体分析中,不是考虑所有的实体类型,而是只考虑在执行迹中出现的与特征相关的实体,查找其对应的依赖图。依赖图分析检查与特征相关的实体未被调用的情况,同时,也用于反馈到场景设计过程[34-37]。通过迭代补充相关的场景和特征,完善已经建立的框架结构。系统类依赖图用节点和边表示,节点代表类,边代表依赖关系,示例如图2所示。

Fig.2 Dynamic and static class dependency graph图2 动态和静态的类依赖图
在图2中,左图表示执行迹特征feature1获得的类的动态依赖图,右图为通过静态分析得到的依赖关系图。假设所有的动态依赖关系在静态依赖图中都有对应。如在特征feature1中,如果存在动态依赖,并且经过静态结构分析,各相关的类均包含在特征中,那么表示对应特征和场景已经设置,不再进一步分析。如果在特征feature1中,类之间存在静态依赖关系,同时存在没有被该特征动态调用的类,那么对应如下三种情况:(1)类C3依赖类C5,但类C5不在特征feature1范围中,这表明在feature1的特征实现集中缺少类C5的可能性,建议准备一个额外的场景来包含类C5的调用S=S∪{Snew}。(2)类C6依赖类C1,但类C6不在特征feature1范围中。这表明被调用者可能是feature1的入口点,如果类C6未被分类到任何特征中,则可能存在当前场景中缺失的新特征F=F∪{Fnew}。(3)类C2和类C4都在特征feature1中,但并没有动态依赖,表明需要建立一个新的场景来触发其依赖关系。
可见,通过类依赖图的分析,可以获取特征和场景补充的建议,如根据对应的实体,重新设计场景或添加新的特征,这对于动态分析获取功能全面且平衡的测试用例或场景集有很大的帮助。需要说明的是,特征和场景的添加和执行,修改了已建立的基本架构,按照本文的图1流程,需要重新进行迹的收集和算法1的处理等工作。但如果依赖性分析只是根据依赖图推荐没有被动态执行到的代码实体,可以根据如下的算法2,进行相关实体与已形成簇的相似度比较,以确定候选实体与基本架构是合并还是舍弃。
算法2归类算法(merging algorithm)


算法2通过命名规格进行相似度匹配。其中,第5句首先排除名称相同的已有的实体,不再进行比较。第5~10句目标是基于依赖性,将各实体与算法1中已经聚类的各个簇进行循环比较,选择相似度最高的簇,如果大于设定的阈值,则将实体合并到该簇,否则舍弃。其中,算法第6句通过计算特征向量的余弦相似度进行比较。该定义描述如下:设有程序元素m和p,分别对应n维向量,则m和p的余弦相似度值为:
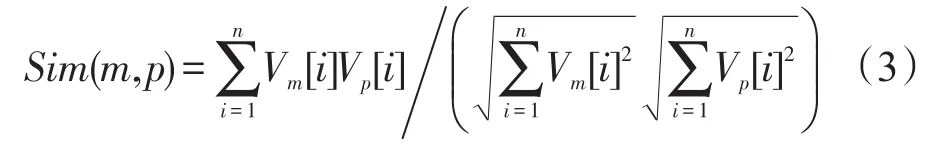
以下说明提取包含在类名的概念词的方法:比如有实体类A和簇B的名称分别为{DrawingChange-Event}和{DrawingEditor,FigureChangeAdapter},经转换后形成概念词集合分别为{Draw,Change,Event}和{Draw,Editor,Figure,Change,Adapter},共用词项{Draw,Change,Event,Editor,Figure,Adapter},则类A和簇B词频向量分别为{1,1,1,0,0,0}和{1,1,0,1,1,1},由式(3)得到A与B的余弦相似度为51.6%。
4 案例研究
本章通过对开源项目的案例研究,介绍研究的目标系统,描述聚类方法的细节,与目标系统的设计者提供的实际结果比较以评估聚类质量。
4.1 目标系统
以 JHotDraw(http://www.JHotDraw.org/)和 JEdit(http://www.jedit.org/)作为案例研究分析实验步骤和结果。JHotDraw项目是描述二维图形的开源系统,主要用于支持编辑器开发,具有良好的框架结构和命名规范,并且有相应的功能需求文档;JEdit是一个带有可扩展插件体系结构的程序文本编辑器,具有良好维护过程和可扩展性能。因此,包结构可以作为实验方法的权威参考。实验的软件系统如表1所示。

Table 1 Descriptive statistics of target systems表1 目标系统的描述性统计
通过对待分析系统的需求文档查询,确定了对应的特征和场景描述,用标记的执行迹来精确记录对应的特征场景。从而快速建立起特征和系统实体之间的对应关系。图3是收集的JEdit系统的部分执行迹片段。
表2显示了研究所选择的特征。在特征选择上,本文尽可能选择覆盖各个方面,以取得特征集的平衡。由于只分析踪迹中特定类的活动,只要保存每个踪迹的不同类别的实体。执行场景后,生成特征-实体的关联矩阵,根据算法1后得到如表3所示的初步划分。

Fig.3 Partial execution traces slice of JEdit system图3 JEdit系统的部分执行迹片段

Table 2 Partial features and scenarios used in this experiment表2 实验的部分特征和场景

Table 3 Clusters results generated by k-means algorithm表3 通过k-means算法产生的聚类结果
从表3可以看出,在所划分的簇中,包含了系统的基本框架,但各个簇中包含的类数量较少,与实际的包结构有较大差别,因此结合本文第3.3节所提出的方法,对特征-实体矩阵中的实体进行依赖性分析,根据不同的特征,将系统类之间的依赖标识出来,然后按照补充特征,推荐特征没有执行过的实体,根据算法2的方法补充到相关的簇中,例如:standard.CreationTool→ application.DrawApplication;figures.RectangleFigure → figures.ImageFigure;application.DrawApplication → contrib.CommandMenu;figures.AttributeFigure → figures.FigureChangeEvent;Viewframework.ConnectionFigure → framework.Handle;standard.StandardDrawingView→framework.Drawing。
4.2 基准实验比较
本文对JHotDraw和JEdit两个开源系统采用了分阶段聚类的算法,为评估该算法的质量,分别采用Tzerpos等人提供的ACDC(algorithm for comprehension driven clustering)算法[32]和 Bunch 聚类算法[4]作为基准实验对相同的实验系统进行测试后进行初步比较。以下是两种算法的描述:
(1)ACDC是一种基于程序理解模式的算法,是通过使用模式驱动的方法识别子系统,根据所使用的模式创建最终分解的框架。
(2)Bunch提供如穷举和爬山等算法的集成用户界面,将节点视为程序单元或模块(如文件或类),并将节点之间的边界视为这些模块之间的调用如函数调用或继承等关系。可以使用预定义的聚类来评估或提高系统聚类的质量。
在软件体系结构恢复和演化领域,聚类是一项基本的活动。对基于聚类的过程的整体质量的评估通常是一个关键问题。考虑在这个领域广泛采用的三个评估度量[24]:权威性、分布合理性和稳定性。比较三种方法对软件架构恢复的影响。
4.3 实验评估
为了评估聚类的质量,本文以MoJo距离(measure based on move and join distance)作为度量指标,比较实验聚类结果同实际系统结构的差异。MoJo距离表示将源分区转换为目标分区的最小“移动”和“合并”操作数。“移动”表示将实体从一个簇中移动到另一个现有簇或新创建的簇,“合并”操作将两个簇类合并成一个簇类。

其中,N是待聚类的实体的总数,MoJo(A,B)=min(mno(B,A),mno(A,B))。Mno(X,Y)是“移动”或“合并”操作所需的最小数量。MoJoSim值越高表明越接近实际划分。输入文件格式之一是RSF(rigi standard format)文件格式,相比较对象应当包含依赖关系及对象集合具有相同的数量等条件。转换的工作流程设计如图4所示。

Fig.4 RSF generation approach图4 RSF处理方法
4.3.1 权威性比较
评估的一个重要指标是实验所产生的划分与权威划分的相似程度。比较由实验生成的划分A与权威划分B,采用公式MoJoSim(A,B)并使用实际项目中的Java包结构作为权威划分。权威性值比较结果如图5所示。

Fig.5 Comparison results of authoritativeness scores图5 权威性值比较结果
4.3.2 稳定性比较
聚类方法不会因为聚类对象的细微变化而导致聚类结果的显著差别。两个连续版本的系统中由相同聚类生成的两个划分Pi和Pi+1之间的相似性来衡量算法的稳定性。通过计算MoJoSim(Pi,Pi+1)值比较聚类算法的稳定性。稳定性值比较结果如图6所示。

Fig.6 Comparison results of stability scores图6 稳定性值比较结果
4.3.3 分布合理性比较
分布合理性NED是指聚类结果应该尽可能少地出现星云与黑洞[38],NED计算参见式(2)。NED值比较结果如图7所示。

Fig.7 Comparison results ofNEDscores图7 NED值比较结果
4.3.4 分阶段聚类的符合度比较
显然MoJoSim度量指标只是反映聚类的质量,还需要将实验结果与实际设计的包结构进行对比分析。为此将实验的两个阶段的聚类结构分别与开源系统的真实结构进行比较,以区分实验在第二阶段的聚类效果,具体的方法是采用Jaccard相似度计算,以包结构为单位,比较实验聚合的簇与实际的包中所包含的各类,设有clusterA和packetB分别是实体类的集合,则clusterA和packetB的符合度定义如下:

例如在JHotDraw 5.2设计的包结构中,除了测试用例和示例代码外,共有7个包,比如,在framework包中,共含有18个类,集合为{Drawing,figure,painter,tool,locator,connector…},以JHotDraw和JEdit的各个版本的实验初期和实验后期形成的聚类分别考虑,选择的原则是按照名称最相似的簇中类分别与实际的各个包中类进行比较,获得的部分数据如图8所示。

Fig.8 Distribution of comparison conformance图8 比较符合度分布
4.4 方法的有效性讨论
从图8可以看出,最初的聚类与实际的包结构的符合度在50%以下,经过后一阶段的聚类后,达到50%以上的较好的符合度。分析主要有以下几点原因:首先,在静态分析过程中通过算法2,利用类的依赖、继承和调用等关系,在形成的框架中添加实体,扩充了核心簇类中的实体数量,总的簇数目根据需要调整,这与使用的方法有关,如果把引入的实体与以往的核心簇重新聚类,可能会影响核心架构的特征功能。而采用迭代的架构恢复方法,当需要特征和场景的添加和执行时,需要重新运行算法1,并构建基本框架。因此,在方法的处理上具有灵活性。从代码的架构来看,设计者基本上是按照功能实现进行命名和结构划分的,如JHotDraw 5.2中的standard包有47个类,application包和applet包都只有1个包等。因为applet主要功能是针对网页应用,application包同样是针对Samples包的应用设计的,不是系统的核心功能,所以采用以NED最大值作为聚类算法的划分是可行的。同时,恢复原始软件包意味着可能识别出有重构意义的程序元素,从低内聚性软件包开始,可以将软件包分成更多具有更高内聚性的模块。
其次,本文以动态特征分析为起点,尽管采用依赖性分析扩充分析的范围,但对结构影响最大的是初期的特征和场景的选择。在实验的初期,如果只选择功能相类似的特征,聚类后的系统结构很可能包含大部分实体的小部分簇,形成极端分布的现象。因此通过迭代和比较分析,扩充特征和场景的方法取得结构的平衡。本文首先建立起基本的功能框架,构建特征层次的结构恢复,这与静态的聚类或面向模式的恢复方式相比,在恢复的结构上可能存在着差异。
5 总结和展望
本文的中心是通过分阶段的聚类算法,达到目标系统结构恢复的目的。在方法的实现上,采用特征作为聚类标准创建基本结构,按照动态调用的赋值权重分配给提取的信息以提高聚类的准确性。根据合理性分布的聚类质量要求,达到自动确定聚类数量的效果。结合静态依赖图补充特征和程序元素,循环迭代是获取特征和场景的平衡集,以恢复比较全面的框架结构。
在实验效果的评估上,从权威性、稳定性和分布合理性等方面,比较形成的结构与设计的包结构的差异以评估实验方法的质量,为进一步的程序理解和系统可能的重新模块化提供帮助。此外,依赖关系作为恢复中的重要因素,如何提供更精确的权重度量以提高恢复的精确度是需要考虑的工作。从实验结果看,方法还受到主观因素的制约,如特征和场景的构建,度量指标的选择等,这些都需要更多的实验总结和完善。
