用户交易数据不足情况下的商品关联规则扩展与应用
2019-03-01陈可嘉
陈可嘉 赵 政
(福州大学经济与管理学院, 福建福州 350108)
一、引言
随着信息技术的不断发展,信息数字化的程度不断加深,各行各业每天都有海量的数据产生。而如何对这些数据进行有效的处理,挖掘其中蕴涵的商业价值,是目前一个亟待解决的问题。关联规则挖掘是数据挖掘领域中最为常用的几种研究方法之一[1],其能够挖掘出不同商品之间的关联关系,获得消费者购买范式的一般性规则,因此被广泛地应用于电商、金融、医疗、物流等领域。[2]但传统的关联规则挖掘算法,需要大量的用户交易数据作为支撑。如最早由Agrawal和Srikant提出的基于频繁项集的经典关联规则挖掘Apriori算法,就需要用到大量的消费者历史购物篮信息。[3]而后续学者对关联规则挖掘的研究,又大多是以Apriori算法为基础,集中在对频繁项集挖掘的效率和性能上进行改进。[4][5][6]这些研究仍然需要以用户交易数据为基础,对用户交易数据不足的商品,比如刚上架的新品,往往会由于达不到置信度和支持度的要求而无法及时生成相应的关联规则。
现今随着网购逐渐成为用户的主流购物方式之一,电商平台上每天都会有大量的新品上架。这些新上架的商品有成为爆款的潜力,但刚上架时却没有足够的用户交易数据可用来做关联规则挖掘。因此,有学者尝试在原有关联规则的基础上进行扩展。如李学明等注意到关联规则中隐含着否定关系,提出了一种扩展型关联规则模型,从而得到更多的规则知识。[7]而董俊等在领域本体的规则扩展上,通过KDD技术来进行规则的扩展,使扩展得到的规则能与基于历史数据的关联规则保持一致。[8]Liu提出了一种基于用户引导的多关系关联规则挖掘算法,引入ID传播思想,来对传统的关联规则挖掘方法进行扩展。[9]Abbache等则在关联规则的基础上,进一步利用WordNet词典进行规则查询扩展,并通过实验证明了该方法在MAP和召回率指标上具有更好的表现。[10]
但目前的关联规则扩展方法又大多是以用户交易数据为基础,研究如何有效地从这些交易数据中挖掘出更多的信息来进行规则扩展。那么是否可以借助一些反映商品本身信息的数据来生成关联规则?比如通过商品相似度的构建,来实现关联规则的扩展?事实上在进行关联规则挖掘时,除了考虑从用户的交易数据中挖掘用户对商品需求间的关系,商品自身的信息,如对商品的文字描述、商品图片等也在一定程度上反映了商品间的相似性,而两个足够相似的商品则可认为是能够相互替代的。
因此,本文从相似性的角度出发,引入商品文本信息,以关联规则推荐算法中经典的Apriori算法为基础,通过构建商品间相似度矩阵来对关联规则进行扩展,提出了一个基于商品相似度的关联规则扩展方法,解决了传统关联规则算法无法对用户交易数据不足的商品得出具体关联规则的缺陷,并通过实验验证了该方法的有效性和实用性。
二、用户交易数据不足情况下的商品关联规则扩展
本文提出的用户交易数据不足下的商品关联规则扩展方法主要分为以下三个阶段:第一阶段为数据收集和预处理,第二阶段为关联规则挖掘,第三阶段为计算商品相似度并生成新规则。整个方法流程如图1所示。

图1 用户交易数据不足情况下的关联规则扩展流程
(一)数据收集和预处理
1. 数据收集
用户交易数据无法用爬虫软件从公开的网络上直接获取。因为用户交易数据具有重大的商业价值,企业一般不会把这些数据完全公开在网络上。但也有一些企业会把部分用户交易数据在经过脱敏处理后进行公开,以供社会研究需要。而使用这些经过脱敏处理的真实用户交易数据来进行研究则比用仿真模型构造交易数据更加可靠、贴近实际。
2. 数据预处理
用户在网购时并非都会一次性结清所有的商品,常常分次结账。同时注意到有些互补商品的购买往往是在使用一段时间之后进行的。因此,在数据预处理时需要对同一用户在一段时间内的所有购买记录进行汇总。此外,由于刷单现象的存在,为了尽可能降低其对推荐结果的影响,本文把短时间内购买大量商品的行为视为异常,予以剔除。
(二)关联规则挖掘
1. 关联规则挖掘相关定义
定义1规则项。规则项一般可表示为
定义2支持度。支持度指所有数据中同时包含x和y的事例的占比。
定义3置信度。置信度指所有数据中同时包含x和y的事例与只包含x的事例的比值。
定义4频繁项。频繁项指支持度大于最小支持度的规则项。
2. 规律规则挖掘算法
在进行关联规则挖掘时,本文主要采用Apriori算法。该算法的核心思想是从低维向高维循环生成频繁项集,并用支持度进行减枝去掉低价值的频繁项,最后再把这些频繁项集按置信度来生成关联规则,其基本运算步骤如图2所示。

图2 Apriori算法基本运算步骤
(三)商品相似度的计算以及关联规则的扩展
传统的关联规则挖掘算法往往借助于用户的交易数据来寻找这种商品对,但若交易数据不足,比如刚上架不久的新品,就会由于置信度过低而无法生成关联规则。针对这些暂时没有丰富的用户交易数据的商品,本文从相似性的角度切入,引入商品文本信息作为补充数据源。
购买了商品A的用户,有很大概率会购买商品B。关联规则挖掘就是找到这种A、B组合的商品对。那么对通过关联规则算法挖掘到的规则“A=>B”,若有一个商品C与商品B足够相似,甚至在功能上可以相互替代,那么对用户来说,购买商品C和购买商品B给他带来的价值、满足其需求的程度基本一样。这也就意味着,在已知规则“A=>B”的前提下,若商品C与商品B足够相似,那么“A=>C”也可以被视作一条合理的“关联规则”。即使这种关联关系暂时没有体现在用户的交易数据里,但若向购买了商品A的用户推荐商品C,购买了商品A的用户会接着购买商品C的概率可能非常大。
因此,可以通过商品间的相似度来对关联规则进行扩展,从而实现在交易数据不足情况下的商品推荐。而要通过相似度来对关联规则进行扩展,一个需要解决的问题就是商品间相似度的计算。
1. 商品相似度的计算
在相似度的计算上,本文主要引入了商品文本信息,把商品按照描述其特征的文本信息表示成一个多维向量,并通过计算向量间的余弦相似度构造了一个商品的相似度矩阵。具体步骤如下。
首先把描述商品的数据按特征维度进行划分。商品各维度以什么标准来赋权,这主要取决于获得的描述商品的数据。本文引入的是商品文本信息,因此将其按文本分词的形式来处理权重。这样对于商品A,就可以用维度向量表示,如公式(1)所示。
A=(A1,A2,…,An)
(1)
其中:n表示分词数量;Ai表示商品A在第i个分词上的重要程度。
接着,需要确定商品各维度的重要程度,即Ai值。由于商品维度向量以文本分词的形式呈现,因此将其以评价文本分词的常用方法来处理权重。而评价分词重要度的一个较为客观的标准就是该分词出现的频率,即一个分词出现的次数越多,则该分词就越重要。因此,商品分词重要度di可用公式(2)表示。
Ai=ln(1/fi)·Vi
(2)
其中:fi表示商品A同类目的所有商品中,含有第i个分词的商品的占比;Vi表示第i个分词在商品x中出现的频率。
最后则是计算不同商品的相似度,并构建一个商品相似度矩阵。计算向量间相似度最常用的一个方法是余弦相似度,由于上述步骤已把商品描述成向量形式,因此可直接使用余弦相似度公式来计算商品间的相似度。本文把商品与其自身的相似度记为1,那么对于商品A和商品B,他们之间的相似度可用公式(3)表示。
(3)
其中:MA,B表示商品A与商品B之间的相似度。此外,由于MA,B=MB,A,故只需计算矩阵的上三角,就可求得任意两商品间的相似度。
2. 关联规则的扩展
为了实现对关联规则进行扩展,本文假定两个相似度足够高的商品是可以互相替代的,且新规则的置信度可以认为是原规则的置信度与商品间相似度的乘积。
那么对已有的规则
在上述假设下,就可以用商品相似度矩阵M对原始关联规则按置信度要求进行扩展。
三、 实例分析
(一)数据收集和预处理
淘宝网是中国目前最大的网购零售平台,每天都有海量的用户交易数据产生。阿里天池大数据竞赛则向参赛者提供淘宝网上经过脱敏处理后的海量真实交易数据。这些数据具有较高的可靠性和真实性,适用于数据挖掘方面的研究。因此,本文主要采用阿里天池大数据竞赛中的数据进行实证研究。
对阿里天池提供的数据,本文选取了其中169405条淘宝服装类商品用户交易数据和500350条服装类商品数据进行研究。
1. 对同一用户的交易记录进行合并
以用来标识用户的“user_id”字段为标准,把所有“user_id”相同的交易记录进行合并,共把169405条交易记录合并成13738条相关性交易记录。
2. 对相关性交易记录进行统计分析
发现其中有99.94%的交易记录里所包含的商品个数在100以内。因此,单条交易记录包含商品数超过100的交易可以视为极端情况,予以剔除。最终得到13738条相关性交易记录。剔除极端交易后的交易记录其每条包含商品数的均值10.79。
(二)关联规则挖掘
在R-3.3.1版本的环境下用Apriori算法包对上述步骤得到的13738条相关性交易数据进行关联规则分析。为把错误推荐的负面影响降到最小,本文采取保守策略,认为高置信度下的关联推荐才是可靠的,因此选择0.0005的支持度和0.6的置信度进行实验,共挖掘出74条高质量的关联规则,如图3所示。代表商品的气泡当置信度越高时距离越近,支持度越多则面积越大。从中可以直观地感受商品间的关联关系。

图3 关联规则分布
其中置信度最高的前20条关联规则如表1所示。这些关联规则提升度都非常高,具有很高的可靠性。此外,从中可以发现有一些关联规则的规则左项和规则右项是互相颠倒的,如规则<3112554=>1865937>和<1865937=>3112554>,且其置信度均为1,这意味着3112554号商品和1865927号商品要么是捆绑销售,要么是绝对的互补品,购买其中一个商品的用户必定会买另一个商品。

表1 20条置信度最高的关联规则
(三)商品相似度的计算以及关联规则的扩展
在上述关联规则挖掘基础上,针对用户交易数据不足的情况,考虑进一步引入商品文本信息,把商品按照文本特征表示成向量的形式,并可以通过计算向量间的余弦距离求得任意两个商品间的相似度,从而构建一个商品相似度矩阵。
此外,为了使扩展得到的关联规则具有较高的价值,本文把进行规则扩展的相似度要求从关联规则挖掘时的0.6置信度提升到0.8。因此,若要在最低满足0.8的相似度要求下对关联规则进行扩展,则只需保留相似度在0.8之上的商品。再者,为了使扩展得到的规则不会过于膨胀,本文只选取与同一商品相似度top10的商品来进行关联规则的扩展。
综上,为了得到较高价值的规则,在计算相似度矩阵时,本文只保留对同一商品相似度在0.8之上(包括0.8)且位列top10的商品,其余均设置为0。图4展示了编号前30的商品的相似度矩阵。其中,有些商品比较独特,没有与其相似度在0.8之上的同类商品,比如23、24号商品,这类商品替代品较少;有些商品则比较大众,与其相似度在0.8之上的同类商品较多,比如16、17号商品,有着较多的替代品。
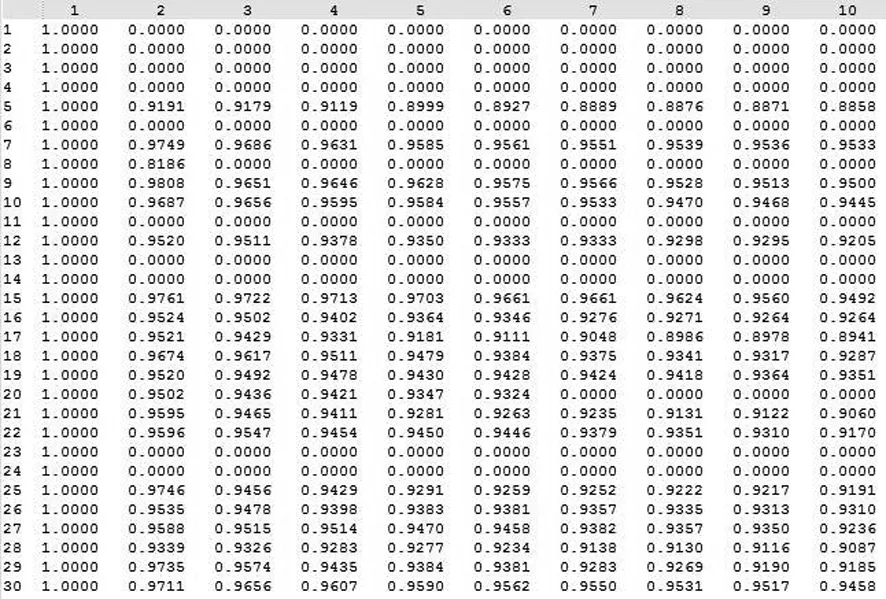
图4 商品相似度矩阵
在不同置信度下,得到的关联规则扩展情况如图5所示。从中可以发现,用Apriori算法挖掘到的关联规则数量和本文方法扩展得到的关联规则数量都随着置信度的提高而下降。在0.96置信度前,用本文方法扩展得到的新关联规则数都比原关联规则数量要多;但当置信度不断向1逼近时,用本文方法扩展得到的新关联规则数则下降得越快,而原关联规则数则趋于稳定。

图5 扩展规则与原规则数量对比
在对扩展效率的评价上,用在Apriori算法下因用户交易数据不足没有生成关联规则而在本文方法中生成了关联规则的规则数占比(Vi)来衡量,可用公式(4)表示。
(4)
其中:Ni表示在置信度为i时,基于本文方法生成的新关联规则的总数;Mi表示在置信度为i时,Apriori方法生成的原始关联规则的总数。
计算结果如图6所示。从中可以发现,本文方法的规则扩展效率在置信度为0.94之前整体呈现一个较为平缓的态势。这意味着本文提出的规则扩展方法能在较高置信度下保持一个稳定的扩展效率。而在0.94置信度后,随着置信度不断向1逼近,规则扩展的效率快速下降,在置信度达到0.98之后,扩展效率为0。即随着置信度越靠近1,无论是规则扩展的数量还是效率都会快速下降直至为0。一个合理的解释是与同一商品足够相似的商品的数量会随着相似度要求的提高而不断减少。总体来看,本文方法能在较高置信度下,借助商品相似度实现对用户交易数据不足的商品生成关联规则,具有较高的有效性和实用性。

图6 规则扩展效率
四、结语
本文针对传统关联规则推荐算法在用户交易数据不足情况下的推荐盲区,从相似度的角度出发,在用户交易数据的基础上,引入商品文本信息,并以关联规则推荐算法中经典的Apriori算法为基础,通过构建商品间相似度矩阵,提出了一个基于商品相似度的关联规则扩展方法,并以淘宝平台上的真实用户数据进行实证研究,证实该规则扩展方法能在较高的置信度下,得到对用户交易数据不足的商品的关联规则,具有较高的有效性和一定的实用性。此外,能用来衡量商品间相似性的数据并非只有文本信息,图片信息也是衡量商品相似性的一个重要数据源。如何在商品文本信息基础上,再引入图片信息来综合计算商品相似度需要做进一步的研究。
注释:
[1] Wu X., Kumar V., Quinlan J. R., et al.,“Top 10 algorithms in data mining”,Knowledge&InformationSystems, vol.14,no.1(2007),pp.1-37.
[2] 洪亮、李雪思、周莉娜:《领域跨越:数据挖掘的应用和发展趋势》,《图书情报知识》 2017年第4期。
[3] Agrawal R., Srikant R.,Fastalgorithmsforminingassociationrules,Proc of International Conference on Very Large Databases,1994,pp. 487-499.
[4] Czibula G., Marian Z., Czibula I. G.,“Detecting software design defects using relational association rule mining”,Knowledge&InformationSystems, vol.42,no.3(2015),pp.545-577.
[5] Liu Z., Hu L., Wu C., et al.,“A novel process-based association rule approach through maximal frequent itemsets for big data processing”,FutureGenerationComputerSystems, vol.81(2017),pp.414-424.
[6] Rachburee N., Arunrerk J., Punlumjeak W.,FailurePartMiningUsinganAssociationRulesMiningbyFP-GrowthandAprioriAlgorithms:CaseofATMMaintenanceinThailand,International Conference on IT Convergence and Security, 2017,pp.19-26.
[7]李学明、刘勇国、彭军,等:《扩展型关联规则和原关联规则及其若干性质》,《计算机研究与发展》2002年第12期。
[8] 董俊、王锁萍、熊范纶,等:《基于多维关联规则的本体规则扩展方法》,《模式识别与人工智能》2009年第5期。
[9] Liu D.,“Research on the multi-relational association rule mining algorithm based on user guidance”,InternationalJournalofAdvancementsinComputingTechnology, vol.4,no.22(2012),pp.779-787.
[10] Abbache A., Meziane F., Belalem G., et al. ,“Arabic Query Expansion Using WordNet and Association Rules”,InternationalJournalofIntelligentInformationTechnologies,vol.12,no.3(2016),pp.51-64.
