不同矩阵分解方法对海洋数据同化的影响*
2019-01-17管志斌肖俊敏季统凯洪学海谭光明
管志斌,肖俊敏,季统凯,洪学海+,谭光明,马 岩
1.中国矿业大学(北京)机电与信息工程学院,北京 100083
2.中国科学院 计算技术研究所 高性能计算机研究中心,北京 100190
1 引言
当今时代,对海洋生态系统和海洋动力学的研究早已进入卫星时代,科研人员可以通过数据传输卫星,获取分布于各个海洋不同区域内,大量传感器所收集的海洋中的多尺度信息。但是,随着大量的海洋观测数据的获取,不可避免地出现了一些亟待解决的难题,即如何将这些海洋观测数据或者数据结果,与相应的数据模型进行结合,从而使得其更接近于现实世界中实际的海洋状态。
海洋数据同化是一种能够将海洋观测数据与相应的海洋数值模型进行融合的有效方法。海洋数据同化方法主要是将收集到的海洋观测数据与理论数值模型相结合,取两者的优点,从而得到更接近于实际状态的结果[1-2]。高效的数据同化方法,不仅可以从大量的海洋观测数据中快速地提取出有价值的信息,而且可以通过提高数据分析的精度和预测技巧,使人类加深对海洋生态系统和海洋动力学等相关领域信息的理解和认识,从而更好地处理海洋与人类社会关系。
海水温度和盐度是诸多海洋水文信息中两个最基本、最重要的信息尺度。温度是度量海水冷热程度的基本物理量;盐度是对海水含盐量的一种衡量尺度,是海洋水体的最重要理化特性之一。随着Argo(array for real-time geostrophic ocean-ography)浮标的全球海洋大范围覆盖以及遥感观测卫星的连续性观测,使得温盐等观测数据被大量获取,如何有效地利用这些海洋观测数据,并对不同海洋尺度信息进行融合,对海洋信息研究具有极其重要的意义[3-4]。
通过海洋数据同化,将观测数据与数值模型进行融合,并从大量海洋数据中提取有价值的信息。在实际中,预报误差的形成,主要是由于模型欠缺以及预见性误差,而数据同化可以确保系统的预报具有稳健的正确性[5-6]。海洋数据同化方法,不仅可以结合原始的海洋观测数据与数值模型的优点,使预测结果更接近于客观的实际海洋状态,而且能够使人类更深入地研究并理解海洋状态[7-9]。
本文的结构如下:第1章对海洋数据同化的基本概念进行简单介绍;第2章中,在阐述海洋数据同化基本流程和数据来源之后,将分别介绍集合卡尔曼滤波同化方法,可有效节省计算开销的集合最优插值,以及目前集合最优插值中所采用的基于奇异值分解进行矩阵求逆的方法;第3章将尝试对同化过程中分析场的求解算法进行改进,主要集中在矩阵求逆运算,对比LU分解求逆、Choleskey分解求逆、QR分解求逆以及奇异值分解(singular value decomposition,SVD)求逆;在第4章中,将给出同化程序基于四种不同矩阵分解的性能测试结果,并对数值结果进行对比分析;第5章对全文进行总结,并给出展望。
2 数据同化方法
2.1 海洋数据同化
在对海洋温盐数据(Argo温盐廓线数据)进行同化的过程中,由于EnOI(ensemble optimal interpolation)所具有的不可忽略的计算便捷性等优点,EnOI常常被作为实际应用中的同化方法[10]。
具体的流程如图1所示。

Fig.1 Flow chart of ocean data assimilation图1 海洋数据同化流程图
(1)需要获取Argo温盐廓线数据,并进行适当的质量控制,使用已有的背景场数据,执行同化命令,先对Argo数据进行同化,包括Argo海流数据的同化、Argo温度数据的同化、Argo盐度数据同化,完成Argo数据的同化之后,得到更新的背景场[11]。
(2)在获取海面高度计异常数据(sea level anomaly,SLA)之后,同样先进行质量控制,再使用同化Argo得到的背景场,对高度计数据进行同化,得到更新的背景场。
(3)在完成海表面温度数据(sea surface temperature,SST)的质量控制之后,使用(2)中更新过的背景场,来同化海表面温度数据,完成海洋数据同化任务[12]。
2.2 数据来源
Argo是全球范围内的3 800个左右的自由漂移剖面浮标,被放置在不同海洋的多个区域内,用于测量海洋上层2 000 m左右范围内的温度和盐度的信息[13]。使用这些浮标,可以使得其连续观测的海洋数据,如海洋温度、盐度、流速等,在收集后数小时内即可公开并使用。
如图2所示,Argo浮标会自动潜入距海平面2 km深处的等密度层上,并随深层海流保持中性漂移,在经过预定时间之后,会自动上浮,并在上浮的过程中,利用Argo浮标自身携带的各种温度、盐度等传感器进行连续的剖面测量。Argo浮标给出的是离散的剖面观测数据,包括海洋特定位置上的温度、盐度、压力传感器的联合测量值[14-15]。当浮标到达海平面后,会自动搜索用于数据传输的卫星,在实现自身定位后,会使用数据传输卫星系统,将收集到的连续时间内的测量数据,传送到卫星地面接收站[16]。当浮标收集的测量数据全部传输完毕之后,会再次自动下沉,执行下一个循环过程,进行数据的收集操作。

Fig.2 Flow chart ofArgo data collection图2 Argo数据收集流程图
2.3 集合卡尔曼滤波
集合卡尔曼滤波(ensemble Kalman filter,EnKF),是一种利用蒙特卡罗的短期集合预报方法,来估计预报误差协方差的四维集合同化方法;EnKF是由Evensen于1994年真正地应用,并首次推广到数据同化领域;EnKF将集合预报(ensemble forecast)的思想与卡尔曼滤波(Kalman filter,KF)相结合,总结两者的优点,通过对一组有限的预测集合进行估计,得到背景场误差协方差,在此基础上,再进行最优分析,计算出具有复杂结构的基于流的,随空间、时间变化的预报误差统计量[17-18]。
由于背景误差协方差是决定数据同化质量的关键因素之一,因此背景误差协方差矩阵的建立与构造就显得尤为重要[19]。
集合卡尔曼滤波(EnKF)继承了卡尔曼滤波(KF)的优点,是一种基于迭代更新的计算方法[20]。
集合卡尔曼滤波中“分析场”的表达式如下:
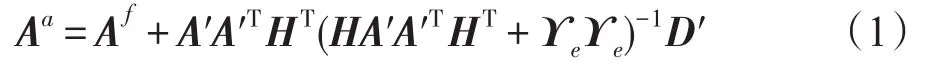
其中,Af是预测矩阵,称为背景场矩阵,A′是扰动预测矩阵,D′=D-HAf,D是扰动测量矩阵,ϒe是扰动测量误差矩阵;而H是测量算子,表示真实模型状态值与测量值之间的映射关系。
令:

由式(1)可知,在Aa的计算过程中最耗费时间的部分是对M求逆。为了得到M-1,传统的方法是直接对M这个m×m矩阵,进行特征分解,使得:

而由此所产生的计算开销则为m2,特别的,当m特别大时,这种开销将无法承受。因此,可以使用其他更有效的分解算法,先将矩阵M分解成子矩阵的乘积,且这些矩阵的求逆过程具有较小的计算开销。
由于集合扰动和测量误差之间是不相关的(与预测误差也是不相关的),可以得到:

此时对矩阵M的求逆过程,可以转换为先对Q进行求逆计算,从而降低计算开销。
通过EnKF可以得到同化过程的最优解,但是EnKF使用的是大量的预报样本和测量数据,这在数值计算上是较为低效的;因此,本文所采用的是,在数值计算上极其高效的,相比较于EnKF,可以得到次优解的集合最优插值方法。
2.4 集合最优插值
集合最优插值(EnOI),是在集合卡尔曼滤波(EnKF)思想的基础之上提出的一种次优的集合同化方法,记为 EnOI[21]。
与EnKF的不同之处在于,EnOI只需要传入一个样本数据,即EnOI只需要利用一组有限的、静态的模式状态的样本集合,就可以完成对背景误差协方差的估计与构建,并实现对背景误差的流依赖性的刻画,而EnKF的使用过程需要多个预测样本,因此,在计算资源的开销上,EnOI要远远小于EnKF,更加适用于大气海洋数据的研究[22-23]。EnOI分析的计算方程与式(1)相似,可以通过如下方程进行计算:

其中:
G=αHA′A′THT+ϒeϒeT,′=(d-Hθf),θf是包含多个变量的背景场,θa是相应的分析场,参数α∈(0,1]是额外引入的权重因子,作用在集合中的测量值上;很显然,式(8)每次只需要计算一个模型状态。
EnOI中,所使用的模型状态样本数据,来自于多年积分的模式结果,在客观世界中,由于不同时间段的气候差异较大,这会影响到分析结果,因此引入参数α,来降低气候差异所带来的负面影响[24-25]。
类似于式(5),则:
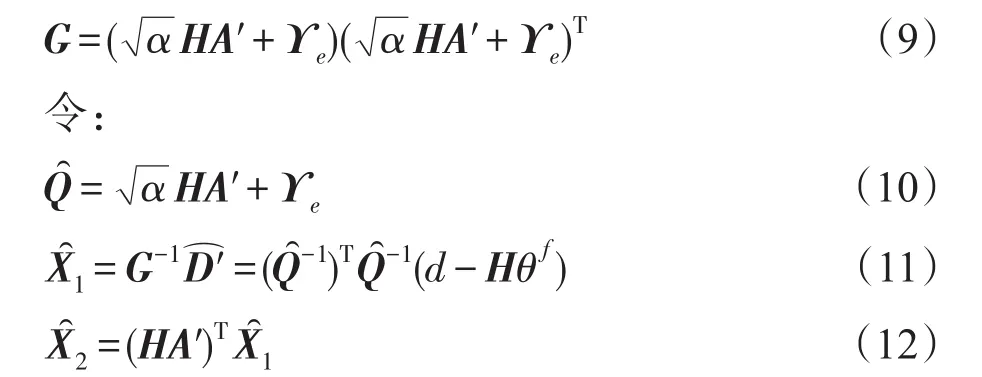
则集合最优插值中的求解方程转化为:

EnOI是一种非常受关注的方法,它可以有效地节省计算时间。当不随时间变化的静态样本集合被创建之后,在分析过程中[26],由于仅对一个模型状态进行更新,因此同化过程中最后的计算开销会从O(N2)降低到O(nN),其中N表示测量值向量的数量,n表示测量值向量中存储的测量值的数量。
在EnOI中求解矩阵的逆所用的传统方法是奇异值分解,在下一节,将介绍奇异值分解方法[27]在EnOI中的具体实现。
2.5 奇异值分解
定理1(奇异值分解(SVD))设A是秩为r的m×n实值矩阵,则存在m阶的正交矩阵Um×m=(u1,u2,…,um)和n阶的正交矩阵Vn×n=(v1,v2,…,vn),及对角矩阵Σ,使得:

此时,根据奇异值分解(SVD)定理,可先对式(10)进行SVD分解,得到:

其中,U和VT均为正定矩阵,Σ是对角矩阵,其对角线上存储的是矩阵的奇异值,并且按递减的顺序在对角矩阵Σ的对角线上进行排序。进一步,根据式(9)可知:

其中,Λ-1=Σ-1(Σ-1)T。因此,式(8)可以转化为SVD分解的形式,如下:
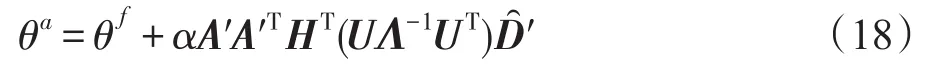
在实际应用EnOI进行海洋数据同化的过程中,通过实验了解到,EnOI算法中的使用SVD分解进行矩阵求逆的过程相对耗时较大;因此,本文的主要目的是通过对矩阵求逆的过程进行优化,从而减少矩阵求逆过程的运行时间;所采用的方法是,使用其他的矩阵分解求逆方法进行替代,从而对EnOI的计算过程进行优化。在下一章中,将介绍其他矩阵分解求逆方法。
3 矩阵分解求逆
在海洋数据同化应用中,传统的用于对式(10)进行矩阵求逆运算的方法是SVD分解;在同化程序中,对矩阵进行分析,发现矩阵是一个稠密的对称正定矩阵,矩阵维度是150×150;而矩阵求逆过程,需要迭代执行394×750次;因此,可以尝试采用其他的矩阵分解方法进行替代,来实现海洋温盐数据同化过程中的矩阵求逆。
本章将分别介绍矩阵的LU分解[28]、Choleskey分解[29]以及QR分解[30];然后,将这些分解方法分别应用到同化过程的矩阵求逆过程中。
3.1 矩阵LU分解
定理2(LU分解)给定一个可逆矩阵A,则存在一个下三角矩阵L和一个上三角矩阵U,使得:

LU分解是将矩阵A通过初等变换L,变成一个上三角矩阵U,本质上就是高斯消元的另一种表达形式。LU分解的计算时间复杂度为O(2n3/3)。
在此,将矩阵进行LU分解,得到:
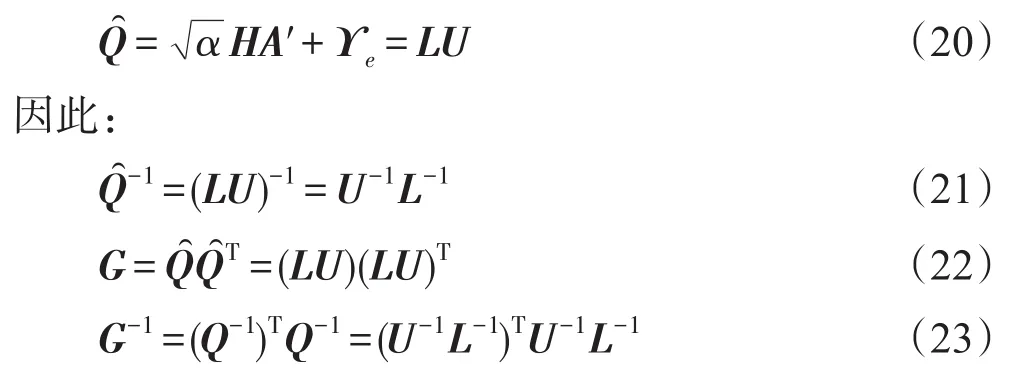
于是,可以得到式(8)的LU分解形式,如下:

3.2 矩阵Choleskey分解
定理3(Choleskey分解)给定一个n×n维的对称正定矩阵A,则存在一个主对角线元素严格正定的下三角矩阵L,满足:

其中,L∗是矩阵L的共轭转置矩阵。Choleskey分解的计算时间复杂度为O(n3/3)。
在这里,将矩阵进行Choleskey分解,如下:

由此,模型分析值计算式(8)的Choleskey分解形式,如下:
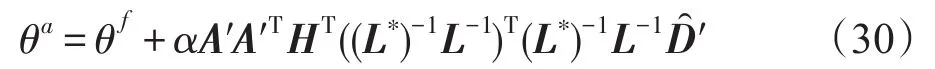
3.3 矩阵QR分解
定理4(QR分解)给定一个n×n维的可逆矩阵A,如果矩阵A的列向量线性无关,则A可以分解为:

其中,Q是n×n正交矩阵,R是非奇异的上三角矩阵。
将矩阵的QR分解应用到矩阵的求逆过程中,令:

则分析场的求解式(8)变为如下形式:
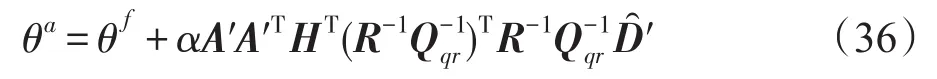
本章所介绍的矩阵LU分解、Choleskey分解、QR分解的主要思想是将待求逆矩阵分解为容易进行求逆的三角矩阵或正定矩阵的乘积;通过对分解后的矩阵进行求逆,再进行相应的矩阵乘积变换之后,即可得到最初的待求逆矩阵的逆;从时间复杂度上来看,三角矩阵或正定矩阵的求逆过程的时间复杂度要远小于最初稠密矩阵求逆过程的时间复杂度;在下一章中,将给出具体的实验结果,以及对实验结果的分析和总结。
4 实验结果与分析
采用控制变量法,测试5种不同时间段的数据分别在不同进程数量下,采用SVD分解求逆、LU分解求逆、Choskey分解求逆、QR分解求逆之后,数据同化程序的运行时间的对比结果,以及本文所采用的三种矩阵分解方法,使同化程序性能提升倍数的比较。其中所使用的数据,来源于不同时期的海洋Argo温盐廓线曲线数据、海表面温度数据(SST)、高度计数据(SLA);不同的时期包含有:2012_003,2012_005,2012_007,2012_033,2012_035,即2012年的第3、5、7、33、35天的数据。使用的进程数(NP)分别是2、4、6、8、10、12、14、16。
表1~表5(a)给出的是,针对5种不同的数据(2012_003,2012_005,2012_007,2012_033,2012_035),分别基于矩阵SVD分解、LU分解、Choleskey分解、QR分解来实现矩阵求逆之后,在不同进程数下(NP=2,4,6,8,10,12,14,16),数据同化程序的运行时间(elapsed time)对比,斜体数值表示耗时最长且性能最差,加粗数值表示耗时最少且性能最优。表1~表5(b)展示的是,相比SVD分解而言,分别采用LU分解、Choleskey分解、QR分解之后,在不同进程数下(NP=2,4,6,8,10,12,14,16),同化程序的性能提升倍数。表1~表5清晰地展示了LU分解、Choleskey分解、QR分解相比于SVD分解,能够使得集合最优插值的计算效率提升至少两倍以上。
从表1~表5中可以明显地看出,传统的SVD分解进行矩阵求逆,程序运行所需的时间要远多于LU分解、Choleskey分解和QR分解,即总体耗时:SVD>QR>LU>Choleskey;在进程数为2时,SVD分解求解所需要的时间最多,是其他3种分解方法进行求解所需时间的3倍左右;随着进程数目的增加,4种分解方法进行求解所需的时间都逐渐降低,但采用LU分解、Choleskey分解、QR分解之后,程序的运行时间依然明显小于传统方法所采用的SVD分解。
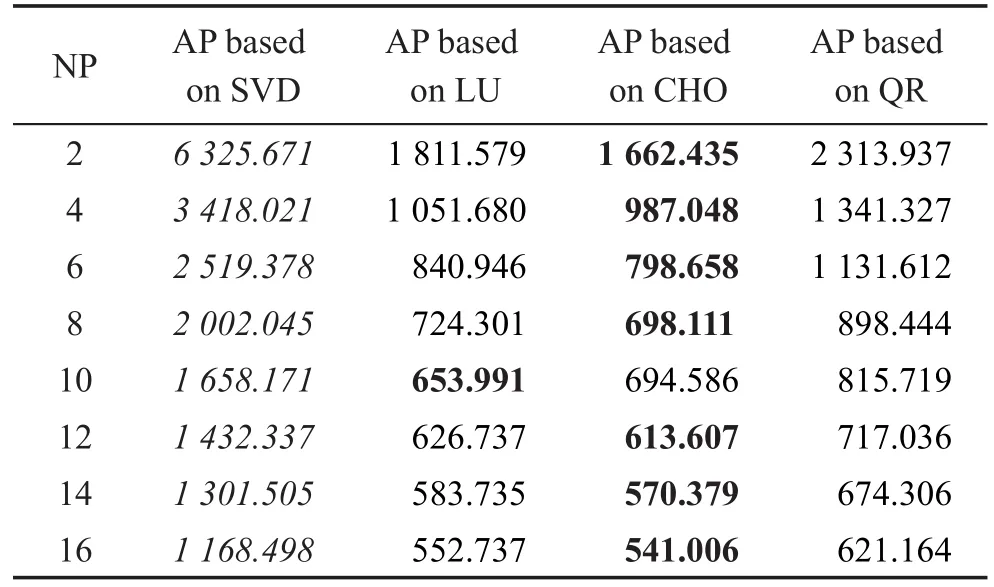
Table 1(a) Comparison of runtime on assimilation program(AP)(Data1)表1(a) 同化程序的运行时间对比(数据1) s

Table 1(b) Multiple of performance enhancement on assimilation program(AP)(Data1)表1(b) 同化程序的性能提升倍数(数据1)

Table 2(a) Comparison of runtime on assimilation program(AP)(Data2)表2(a)同化程序的运行时间对比(数据2) s

Table 3(a) Comparison of runtime on assimilation program(AP)(Data3)表3(a) 同化程序的运行时间对比(数据3) s

Table 4(a) Comparison of runtime on assimilation program(AP)(Data4)表4(a) 同化程序的运行时间对比(数据4) s
此外,从表1~表5(b)中可以看到,在并行运行下,分别采用LU分解、Choleskey分解、QR分解之后,同化程序在性能上,相比较于SVD分解提升了至少两倍左右;而LU分解和Choleskey分解的提升效果最为明显。

Table 2(b) Multiple of performance enhancement on assimilation program(AP)(Data2)表2(b) 同化程序的性能提升倍数(数据2)

Table 3(b) Multiple of performance enhancement on assimilation program(AP)(Data3)表3(b) 同化程序的性能提升倍数(数据3)

Table 4(b) Multiple of performance enhancement on assimilation program(AP)(Data4)表4(b) 同化程序的性能提升倍数(数据4)
值得一提的是,采用矩阵QR分解的同化程序,在性能提升效果上远不如LU分解和Choleskey分解。这一现象的主要原因是,采用QR分解之后,得到的是一个正交矩阵Q和一个上三角矩阵的乘积,而采用LU分解和Choleskey分解之后得到的是下三角矩阵和上三角矩阵的乘积;由于稠密正交矩阵Q求逆过程的时间复杂度要大于下三角矩阵求逆的时间复杂度,因此,造成了QR分解的效果不如LU分解和Choleskey分解。
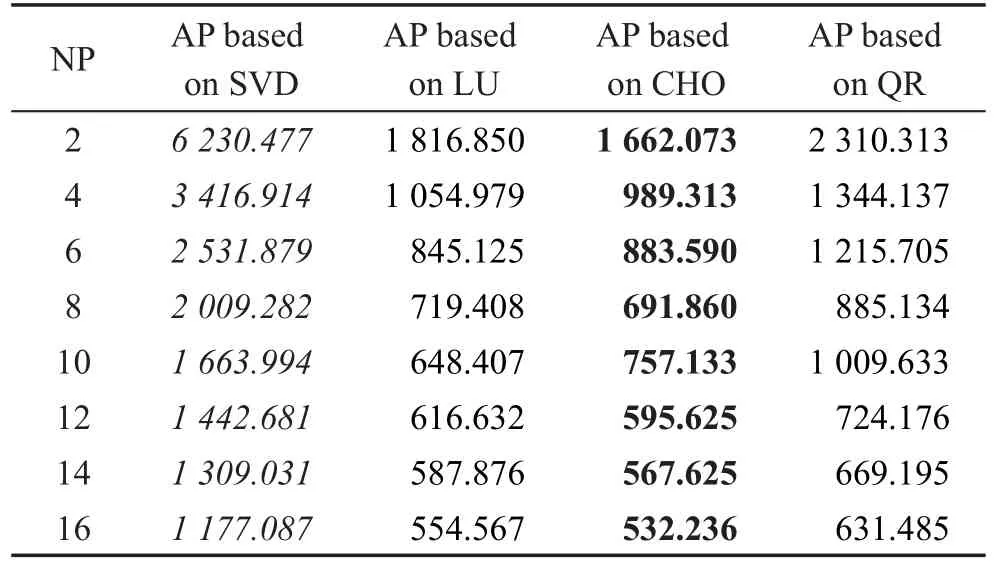
Table 5(a) Comparison of runtime on assimilation program(AP)(Data5)表5(a) 同化程序的运行时间对比(数据5) s
从同化程序运行时间上来看可以了解:QR分解>LU分解>Choleskey分解,即采用矩阵的Choleskey分解之后,同化程序的运行时间会被缩短到最低,大幅度缩减了同化程序的运行时间,提高了程序计算效率。
图3~图5分别给出了4、8、16个进程下的同化程序性能对比。
在图3~图5(a)中,同化程序分别采用SVD分解、LU分解、Choleskey分解以及QR分解,并针对5种不同数据进行测试(2012_003,2012_005,2012_007,2012_033,2012_035),得到的运行时间对比;图3~图5(b)给出的则是分别采用LU分解、Choleskey分解以及QR分解之后,同化程序的运行时间对比。

Table 5(b) Multiple of performance enhancement on assimilation program(AP)(Data5)表5(b) 同化程序的性能提升倍数(数据5)
从图3~图5可以看出,在性能对比上,分别采用LU分解、Choleskey分解或QR分解进行矩阵求逆的同化程序,其性能远远优于采用SVD分解进行矩阵求逆的同化程序。
综上所述,采用本文3种矩阵分解算法的同化程序,相比较于采用SVD分解算法的同化程序,其性能提升至少两倍左右;并且采用Choleskey分解能够最大程度地减少同化程序运行时间,且其扩展性与LU分解和QR分解同样优异。因此,Choleskey分解值得被应用于EnOI的矩阵求逆过程中,它将大幅度地提升目前海洋数据同化程序的计算效率。
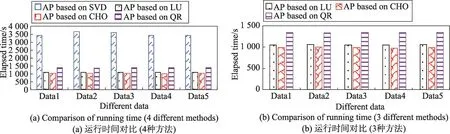
Fig.3 Performance comparison of assimilation programs(AP)(NP=4)图3 同化程序的性能对比(NP=4)

Fig.4 Performance comparison of assimilation programs(AP)(NP=8)图4 同化程序的性能对比(NP=8)

Fig.5 Performance comparison of assimilation programs(AP)(NP=16)图5 同化程序的性能对比(NP=16)
5 结束语
使用集合最优插值(EnOI)进行海洋数据同化时,由于EnOI的矩阵求逆过程所采用的SVD分解非常耗时,因此本文着眼于对矩阵求逆过程进行优化,尝试使用矩阵LU分解、Choleskey分解、QR分解来替代SVD分解。通过并行程序实验结果的对比和分析可以看出,本文所尝试的LU分解、Choleskey分解、QR分解,相比较于SVD分解,可以使同化程序的性能提升至少两倍左右,并且Choleskey分解明显优于其他的矩阵分解方法,可以最大程度地降低时间复杂度,缩短同化程序运行时间。
因此,在未来的工作中,可以考虑将矩阵Choleskey分解应用到实际的工程项目中,以达到提高性能的目的。
