基于深度示例差异化的零样本多标签图像分类*
2019-01-17李慧慧何宇清
冀 中,李慧慧,何宇清
天津大学 电气自动化与信息工程学院,天津 300072
1 引言
传统图像分类系统通常要求测试类别在训练阶段有大量训练数据。然而在实际应用中,随着事物种类的不断增多和细化,大量数据标注信息的获取非常昂贵,使得传统的分类任务的扩展性差,难以满足实际需求。零样本学习技术的出现,则在一定程度上解决了标签缺失问题[1-5],其目的在于模仿人类无需看过实际视觉样例,就能识别新类别的能力。人类之所以具备这种能力,是因为能够将未见类和已见类通过语义信息建立联系。类似地,零样本图像分类技术通过有标签的训练数据(即已见过的类别),在视觉空间和语义空间之间建立映射关系,而后根据训练数据和未见类别的测试数据在视觉和语义上的联系,为测试数据赋予类别标签。
目前相关研究主要集中于单标签图像分类任务。然而在实际应用中,一幅图像不同的区域往往对应若干语义标签,因此将多标签图像分类技术与零样本学习相结合,即零样本多标签图像分类,更具实际应用价值。几种不同任务的关系如图1所示。

Fig.1 Relationship between zero-shot multi-label classification and related techniques图1 零样本多标签分类与相关技术的关系
近年来,越来越多的学者开始关注于这一任务,并提出了一些解决方案。例如,Fu等人[6]提出一个解决框架,将原始图像直接映射至语义空间,并在语义空间针对映射后的特征分别利用直接相似性度量和直推学习两类算法进行标签分类。Mensink等人[7]则将多标签学习分解为多个独立的二进制分类问题,并利用标签间的统计相关性以提高分类性能。Sandouk等人[8]分别建立视觉、标签空间到语义空间的映射,且不同图像中的同一标签的具体含义、语义表征不同,从而充分地利用图像和标签间的多义性实现分类。最近,Zhang等人[1]提出一种映射主方向模型,具有很好的泛化能力。他们利用跨模态映射模型实现多标签图像至对应语义空间的嵌入,嵌入后的特征向量作为分类主方向,和图像相关性越大,在主方向的排名越靠前。然而,目前针对零样本多标签图像分类的研究仍处于起步阶段,其有效性和鲁棒性仍存在很大的提升空间。
为此,本文借鉴零样本单标签分类和多示例多标签图像分类中的思想,提出一种新的零样本多标签图像分类方法,通过深度嵌入模型(deep embedding model,DEM)将视觉空间映射至语义空间,并在语义空间利用示例差异化算法(instance differentiation,InsDif)实现零样本多标签分类。所提方法称为Deep ZSL-ID(deep zero-shot learning with instance differentiation),其系统框图如图2所示。
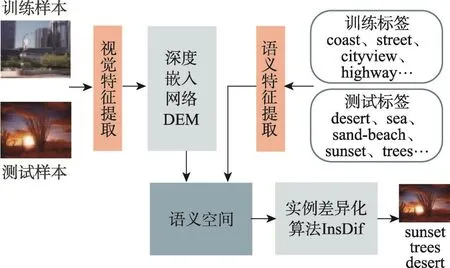
Fig.2 Illustration of proposed Deep ZSL-ID framework图2 所提Deep ZSL-ID系统框图
2 相关工作
2.1 多标签分类
多标签学习已广泛应用于诸多场合,其关键挑战在于多标签空间大小呈指数增长。例如类别个数为20时,对应标签空间的大小为220。为应对这种输出空间指数爆炸的问题,通常需要利用标签间的相关性促进学习过程[9]。例如,已知图像含有标签“热带雨林”“足球”,则被标注为“巴西”的概率就较高。除标签间相关性外,根据标签量充足与否,多标签分类任务可分为三类:(1)直接实现从视觉特征空间到标签空间的分类[9-11],容易迁移至不同数据集,具有普适性,但性能不能得以保证。(2)针对大规模训练样本和大量标签,此时标签空间存在指数爆炸,对此通常利用标签空间降维和特征选择方案[12-13],将视觉特征和标签向量同时映射至某一低维隐空间,再实现从隐空间至标签空间的反向预测。(3)针对标签缺失或训练样本不足,此时需要借助一定的辅助信息实现分类,例如Kong等人[14]采用直推式算法,同时利用已标记和未标记数据以获取最佳标记标签。情况(3)中标签不足的极端情况即为零样本多标签分类任务问题设定,此时借助的辅助信息一般称为语义信息。
已有多标签分类方法大都基于单示例多标签假设,但多标签图像具有多义性,只用一个示例表征过度简化,容易丢失有用信息。为此,Zhou等人借鉴多示例学习思路,将单幅图像表征为多维数组,提出了多示例多标签(multi-instance multi-label,MIML)学习框架[15-16]。几年来,随着深度学习技术的发展,多示例学习为端对端实现零样本多标签图像分类提供了可能[16]。
2.2 单标签零样本学习
零样本学习(zero-shot learning,ZSL)旨在解决标签缺失问题,即测试类别的标签在模型训练过程中没有对应的训练数据。这一过程的实现通常需要借助中间辅助信息,例如属性向量[4]及词向量。词向量中常用的方法是将语料库中的单词表示成一个向量[17],并且向量之间的相似度可以较好地模拟单词语义上的相似度。
求得已见类别和未见类别的语义特征后,各类别间的语义相关性即可由语义特征间的距离求出。然而由于视觉特征和语义特征之间语义鸿沟的存在,两者不能直接建立联系,现有方法大多利用训练样本的视觉特征和对应标签语义特征学习跨模态嵌入模型。已有的方法大致可分为三类:(1)视觉至语义空间的嵌入,该方案是零样本学习最广泛的解决方案,典型算法有线性回归、神经网络[18]和流形学习[19]等。(2)语义至视觉空间的嵌入,该方案由Shigeto等人[20]最早提出,并证明可以缓解零样本学习中广泛存在的hubness问题。最近,Zhang等人[21]利用该映射方式实现了一个端对端模型。(3)视觉语义特征嵌入公共空间,例如采用典型相关分析模型[3]以及Ji等人提出的MBFA(multi-battery factor analysis)模型[4]。视觉特征和语义特征映射至同一空间后,通常直接进行相似性度量得出最终预测结果。
3 零样本多标签图像分类
3.1 问题设定
给定已标记的训练集S={(XS,TS,YS,WS)}以及对应文本集,其中n为训练标签个数。XS={x1S,x2S,…,表示训练样本视觉特征向量,而TS={t1S,表示对应标签向量,,u=1,2,…,n表示样本i包含标签u,反之,NS为训练样本个数。WS={w1,w2,…,wn}表征文本经语义变换后的词向量集合,为标签向量和对应词向量线性组合结果,即训练样本XS的语义空间表征。特别地,d和p分别表示视觉特征空间和语义特征空间维度。类似地有测试集U={(XU,TU,YU,WU)}及其候选文本集,其中m为测试样本候选标签数,测试样本数记为MU,各符号含义与训练集对应,在本文零样本多标签任务设定中,满足假设。为区别样本的相关标签和不相关标签,标签向量T可划分为不相交的两个集合 (T,),Ti为样本i中ti=1的标签集合,则为ti=-1的集合。显然集合Ti中标签和样本i的相关性大于中标签和样本i的相关性。
一般来说,训练集及其标注信息已知,WU和XU也可利用对应特征提取方法获取。此时,给定新的测试样本xiU,i=1,2,…,MU,目的是预测其语义表征及其对应标签向量。注意到可能被任意2m个标签组合向量标记,本文定义一个新的幂集合P={(TP,YP,WU)},其中TP∈{-1,1}m×2m为所有标签组合向量,为对应线性组合的语义表征,WU为测试样本候选标签对应语义向量。表1对主要符号进行总结说明。

Table 1 Main symbol description表1 主要符号说明
本文所提零样本多标签图像分类方法的大体流程如图2所示,具体来说,主要包括如下几个步骤。
(1)特征提取阶段。提取样本的视觉特征X∈X和类别语义特征W∈V,视觉特征提取器选择经ImageNet预训练的VGGNet-19模型[22],选取Word2Vec模型[17]提取语义,文本至词向量的映射为v:T→V,其中X、T、V分别表示视觉、标签和语义空间;在语义空间V中容易获取标签间的相关性,并且一个多标签样本的语义表征可通过单个标签的词向量线性组合来表征,形式上有:

测试集、幂集的对应关系类似。
(2)跨模态映射阶段。利用深度嵌入模型DEM实现视觉特征空间至语义特征空间的跨模态映射f:X→V,利用训练集对模型进行参数训练。
(3)测试样本语义预测阶段。测试样本xiU利用第(2)步所得跨模态映射模型可得预测语义表征。
(4)语义空间的分类阶段。利用示例差异化算法InsDif实现语义特征空间至标签空间的分类h:V→L,最终可得测试样本对应标注。
3.2 深度嵌入模型
为了实现针对零样本多标签学习任务的跨模态映射功能f:X→V,本文设计了深度嵌入模型,如图3所示。模型主要由三层全连接网络(fully connected layer,FC)组成,其中前两个全连接层后分别有一个Leaky ReLU(leaky rectified unit)激活单元。原始图像经视觉特征提取器后得到4 096-D的视觉特征向量,该特征向量依次经过三个全连接层和两个对应激活函数,向量维度由4 096依次变为2 048、1 024和100。特别地,对每层FC网络的超参进行L2正则化以使该嵌入网络更具鲁棒性,在测试集中具有良好的泛化性能;FC层的末端连接一个回归损失函数层,旨在最大限度地减小训练样本的语义特征和其视觉特征嵌入向量在语义空间的差异。采用和文献[21]中相同的损失函数机制,最终目标函数如下:


Fig.3 Architecture of DEM model图3 DEM模型结构
3.3 基于示例差异化算法的多标签分类
本文将示例差异化算法[15]的思想应用到零样本多标签分类任务,将单示例多标签样本转化为多示例多标签样本。主要思路为:首先将一维样本特征转换为包的形式,从而显式地描述图像中多个对象的歧义性;然后利用MIML学习器[15-16]对转换后的数据集进行分类学习,具体过程为:
首先,计算含标签j,j=1,2,…,m的所有样本特征平均值,用作标签j的原型向量νj;基于该原型向量,将每个原始训练样本转换为示例包:

其中,包的大小等于该样本包含类别数q。
其次,利用两层分类策略对转换后的数据集(BiP,tiP),i=1,2,…,2m进行分类学习。第一层利用聚类算法将新的训练集划分为g个不相交子集:

其中,i表示每个子集包含训练样本的个数,将g个包的集合记作{G1,G2,…,Gg}。集合{G1,G2,…,Gg}为各聚类子集Gl的簇中心,每个子集Gl和对应的中心Ql满足:
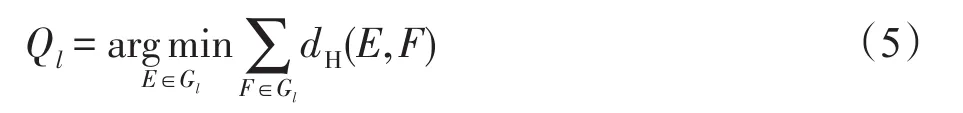
其中,dH(E,F)用于计算包E和F之间的Hausdorff距离[15]。第二层对应权值矩阵W=[ωlj]g×q,其中ωlj为连接包Ql与输出的权值。该权值矩阵的求解与文献[15]一致,通过最小化如下误差函数得到:
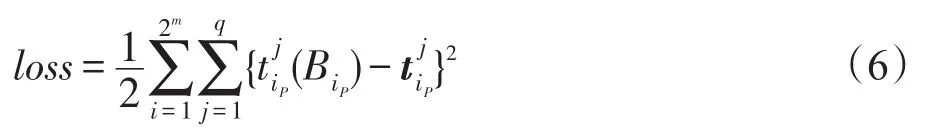
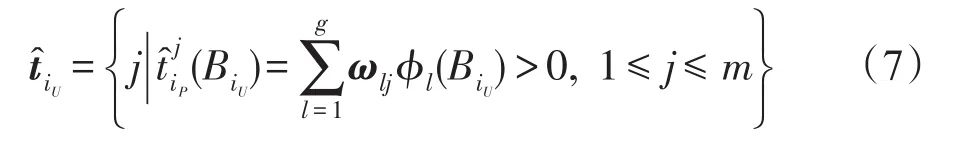
4 实验结果与分析
4.1 数据集与实验设置
本文利用主流数据集Natural Scene[10]和IAPRTC-12[24]进行实验验证。其中,Natural Scene数据集包含2 000张自然场景图像,每幅图可被desert、mountain、sea、sunset和tree共5个标签任意组合标记,且超过22%的图像是多标记的。对于该数据集的验证实验,选取含2 688张图像8个标签的单标签数据集Scene[25]用作训练,Natural Scene数据集用作测试。IAPRTC-12数据集则包含来自275个类别的20 000张图像,该数据集包含 6 个主要子集:humans、animals、food、landscape nature、man-made和其他。为保证样本数据的均衡分布,与文献[6]一致,本文选取Natural Scene和Scene两个数据集用作训练,IAPRTC-12的landscape nature子集(共计9 663张图像,其中超过30%是多标签图像)用作测试,并选择该分支中出现频率最高的8个标签用作候选类。
对于所有样本图像,使用经ImageNet预训练的VGGNet-19模型[22],将隐藏层最顶层的4 096维输出作为视觉特征,输入图像的大小调整为224×224。本文选取文本特征作为中间辅助信息,在维基百科语料库训练Word2Vec模型[17]以形成100维的词向量。上述视觉特征、语义特征在进行跨模态映射或多标签分类时,均进行L2归一化处理,训练DEM模型时从训练集随机选取20%作为验证集,用以调整深度网络超参。
4.2 评价指标
记h(∙)为分类器,r(∙)为中间预测所得实值函数,本文选取文献[6]中4个标准度量指标来评估标注结果,分别如下所示。
(1)Ranking Loss(RL):该指标用于衡量未正确排序对的平均值,数值越小,性能越好。

(2)Average Precision(AP):该指标用于衡量相关标签排序高于不相关标签的平均分数,数值越大,性能越好。
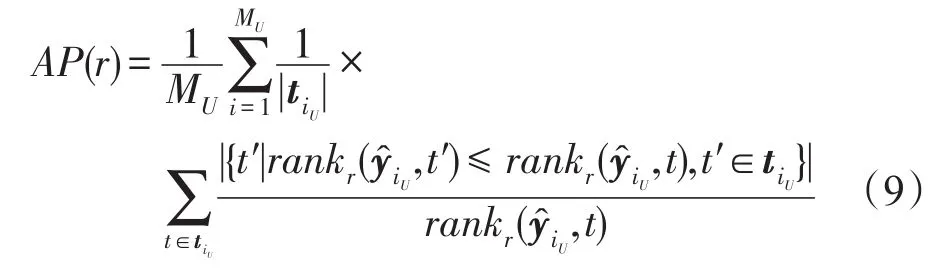
(3)Hamming Loss(HL):该指标用于衡量样本标签对被错分的次数,数值越小,性能越好。

其中,Δ表示两者的对称差异。
(4)MicroF1(MF1):该指标用于评估平均微精度(micro-precision)和平均微召回率(micro-recall)的微观平均值,数值越大,性能越好。

值得一提的是,上述4个指标从不同的角度对分类性能进行评估,通常很少有算法能同时在所有度量标准下实现最佳性能[6,11]。
4.3 与当前先进算法对比
表2给出了在Natural Scene和IAPRTC-12数据集中当前零样本多标签图像分类算法结果比较,实验主要选取Fu等人的工作[6]和Fast0Tag[1]作为对比算法。文献[6]利用Mul-DR(multi-output deep regression)深度回归模型实现从原始图像到语义特征空间的映射,并提出两种分类算法DMP(direct multi-label zeroshot prediction)和 TraMP(transductive multi-label zeroshot prediction)。其中,DMP通过直接相似性度量实现分类,TraMP属于直推式学习算法,分类过程中同时利用训练和测试样本信息。Fast0Tag[1]通过估计视觉特征映射至语义特征空间的主方向向量,来解决零样本多标签图像分类任务,认为标签与图像的相关性越大,对应在主方向向量的投影越靠前。该方法同时利用线性映射和非线性深度神经网络来估计该主方向向量,此处选取性能更优的非线性法Fast0Tag(net.)作为对比算法。此外,为进行公平比较,对比算法与所提算法采用相同的视觉和语义特征。
为便于观察,进行1-AP和1-MF1处理,此时对于所有指标均是取值越小性能越好。表中最佳结果加粗显示,次优性能斜体显示(后文设定一致)。可以看出:在数据集Natural Scene上,Mul-DR+TraMP算法整体性能优于Fast0Tag(net.)和Deep ZSL-ID,Fast0Tag(net.)和Deep ZSL-ID性能相当并优于Mul-DR+DMP;数据集IAPRTC-12上性能优先顺序大致为Deep ZSL-ID> Fast0Tag(net.)> Mul-DR+TraMP>Mul-DR+DMP。与Natural Scene数据集相比,IAPRTC-12的landscape nature分支规模更大,样本数据分布更丰富,而Deep ZSL-ID和Fast0Tag(net.)算法基于深层网络,需要大量的数据进行训练,因此在Natural Scene上性能较差。TraMP属于直推式[9]分类算法,分类时利用测试样本作为辅助信息,因此在Natural Scene上性能优越。此外,数据集Natural Scene上Deep ZSLID的HL指标较差,HL同时会加重误分类和缺失分类误差,而InsDif将单示例问题转换为多示例,在训练样本不足的情况下,转换多示例时会引入新的误差,使误分类/错分类比重增大。此外,为检验所提算法的稳定性,随机选择10组分类结果,对两个数据集的4个衡量指标分别进行方差检验,方差结果Δ列于表2最后一栏。总体而言,表2的比较结果可验证所提Deep ZSL-ID方法的有效性与先进性。

Table 2 Performance comparison of different algorithms on Natural Scene and IAPRTC-12 datasets表2 不同算法在Natural Scene和IAPRTC-12数据集中的性能比较 %
4.4 不同分类算法比较
为了进一步验证文本分类方法的有效性,基于所提跨模态映射模型,本节选取经典多标签分类算法进行对比,它们是exDAP(extension of direct attribute prediction)[6]、DMP[6]、TraMP[14]和 COINS(co-training for inductive semi-supervised multi-label learning)[26]。具体地,exDAP算法将多标签分类任务分解为多个独立不相关的二元分类问题,直接进行分类预测。DMP算法同零样本单标签图像分类一致,该算法利用词向量间的语义相关性,将视觉嵌入特征ŶU和标签组合语义特征YP进行相似性度量,实现分类。TraMP算法则在分类过程中,将测试标签的组合语义特征YP作为先验知识,在ŶU和YP间进行标签传播,最终得出最接近的标签预测结果。同TraMP算法相反,COINS算法是一种归纳式、半监督算法,利用训练和测试数据协同训练多标签分类器,再利用所得分类器对测试集进行分类。
结果如表3所示。可以看出:在小样本数据集Natural Scene上,TraMP作为一种直推式算法,4个指标下均保持性能优势,InsDif、COINS、DMP和exDAP依次次之。TraMP作为一种直推式方法,利用测试样本的标签信息进行分类,这是该算法在小样本数据集下具备优势的原因。而随着样本数量集的增大,IAPRTC-12上性能优先顺序依次为InsDif>COINS>TraMP>DMP>exDAP。由此可见,随着样本数据增大,InsDif算法和COINS算法泛化能力强于TraMP算法。同时InsDif算法较COINS算法的性能优势也说明,将寻求单示例多标签间的对应关系转换为寻求多示例多标签间的对应关系,更满足实际需求。DMP利用语义信息间的语义语法关联进行相似性度量,性能优于忽略标签相关性的exDAP算法;InsDif、COINS和TraMP算法性能则显著优于DMP和exDAP,可见充分利用标签间相关性是多标签分类问题不可或缺的步骤。

Table 3 Performance comparison of different classification strategies表3 不同分类策略下的性能比较 %
此外,基于同一分类方法TraMP,选取文献[6]中的映射模型Mul-DR同所提模型DEM进行对比,用-M和-D分别表示基于Mul-DR和DEM模型的实验结果。从图4可见,DEM模型相比Mul-DR性能有显著提升,验证了本文所设计网络的有效性。

Fig.4 Performance comparison of different cross-modal embedding models图4 不同跨模态嵌入模型的性能比较
5 结束语
本文针对零样本多标签提出了一种基于深度嵌入网络的示例差异化分类方法。首先将视觉特征嵌入语义特征空间,然后在该嵌入空间进行零样本多标签分类。大量的实验比较和分析证明了所提方法的有效性和先进性。实验表明,相比寻求单示例多标签间的对应关系,寻求多示例多标签间的对应关系更符合实际任务本身。后续的研究方向是直接利用深度嵌入网络与示例差异化实现端到端的学习,以期望进一步提升性能。
