基于三维卷积神经网络的航运监控事件识别
2019-01-06王中杰张鸿
王中杰 张鸿

摘 要:針对传统的机器学习算法对大数据量的航运监控视频识别分类的效果不佳,以及现有的三维(3D)卷积的识别准确率较低的问题,基于3D卷积神经网络模型,结合较为流行的视觉几何组(VGG)网络结构以及GoogleNet的Inception网络结构,提出了一种基于VGG-16的3D卷积网络并引入Inception模块的VIC3D模型对航运货物实时监控视频进行智能识别。首先,将从摄像头获取到的视频数据处理成图片;然后,将等间隔取帧的视频帧序列按照类别进行分类并构建训练集与测试集;最后,在保证运行环境相同并且训练方式相同的前提下,将结合后的VIC3D模型与原模型分别进行训练,根据测试集的测试结果对各种模型进行比较。实验结果表明,VIC3D模型的识别准确率在原模型的基础上有所提升,相较于组约束循环卷积神经网络(GCRNN)模型的识别准确率提高了11.1个百分点,且每次识别所需时间减少了1.349s;相较于C3D的两种模型的识别准确率分别提高了14.6个百分点和4.2个百分点。VIC3D模型能有效地应用到航运视频监控项目中。
关键词:智能航运监控;视频识别;深度学习;三维卷积;神经网络
中图分类号: TP391.4 文献标志码:A
Shipping monitoring event recognition based on three-dimensional
convolutional neural network
WANG Zhongjie1,2*, ZHANG Hong1,2
(1. College of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan Hubei 430065, China;
2. Hubei Province Key Laboratory of Intelligent Information Processing and Real-time Industrial System
(Wuhan University of Science and Technology), Wuhan Hubei 430065, China)
Abstract: Aiming at the poor effect of traditional machine learning algorithms on large data volume shipping monitoring video recognition classification and the low recognition accuracy of previous three-Dimensional (3D) convolution, based on 3D convolutional neural network model, combined with the popular Visual Geometry Group (VGG) network structure and GoogleNets Inception network structure, a new VGG-Inception 3D Convolutional neural network (VIC3D) model based on VGG-16 3D convolutional network and introduced Inception module was proposed to realize the intelligent recognition of the real-time monitoring video of shipping goods. Firstly, the video data acquired from the camera were processed into images. Then, the video frame sequences by equal interval frame fetching were classified according to the categories, and the training set and the testing set were constructed. Under the premise of the same operating environment and the same training mode, the VIC3D model after combination and the original model were trained separately. Finally, the various models were compared based on the test results of the testing set. The experimental results show that, compared with the original model, the recognition accuracy of VIC3D model is improved, which is increased by 11.1 percentage points compared to the Group-constrained Convolutional Recurrent Neural Network (GCRNN) model, and the time required for every recognition is reduced by 1.349s; the recognition accuracy of VIC3D model is increased by 14.6 percentage points and 4.2 percentage points respectively compared to the two models of C3D. The VIC3D model can be effectively applied to the shipping video surveillance projects.
Key words: intelligent shipping monitoring; video recognition; deep learning; three-Dimensional (3D) convolution; neural network
0 引言
近几年人工智能[1]迅速发展,越来越多地应用到计算机以外的行业,许多传统行业开始不断地智能化。特别是关于视频监控这一领域,很多传统行业以及各大安全部门都设有相应的监控系统,一般是安排相关人员管理监控室进行人工监控,并对异常情况发出警报。但由于人类会产生疲劳感并且在监视大量的摄像头时难免产生遗漏,因此有必要考虑引入人工智能实现自动化,也就是智能监控系统[2-4]。
航运监控是针对江海中运输货物的船舶进行监控,通过在船上安装摄像头来监视船只,以防止船家偷取货物,以及对船舶的异常状态进行预警。而监控时产生的视频数据是智能航运监控的数据集来源,这就需要使用视频识别的方法来训练模型。
目前智能航运监控跟城市交通监控系统[5]一样,对摄像头要求比较高,需要得到较高分辨率的视频,并且拍摄角度的不同也会产生较大影响。还有江海上不良天气的影响,如雨雪天气、大雾以及光照不一等对识别率的影响也较大。这些因素使得获取的视频或者图像数据质量较差,而传统方法对这类数据的训练效果不佳,并且传统方法在训练数据量较大的模型时效果也不好。
近几年随着大量学者对深度学习[6-8]的不断研究,越来越多的研究领域开始使用深度学习,深度学习方法在计算机视觉领域不断取得突破,并且取得了相对较好的效果,特别是训练数据量较为庞大的模型时,其优势较为明显。然而,以往的深度学习使用的卷积神经网络并不能用于处理视频数据。因此,针对视频识别领域,学者们以深度学习为基础提出了一些新的网络结构,如:以文献[9]为代表的双流(two-stream)网络,以文献[10]为代表的三维卷积神经网络(three-Demensional Convolutional Neural Network, 3DCNN),以及以文献[11]为代表的循环卷积神经网络等。
本文基于3D卷积神经网络模型,对航运货物实时监控视频进行智能识别,并对船的异常情况进行预警,提出了基于视觉几何组-16(Visual Geometry Group-16, VGG-16)网络并与Inception结构[12]融合的VIC3D(VGG-Inception 3D CNN)模型,对识别模型的准确率进行优化。本文使用智能航运监控项目中获取的数据集,并将其分为装卸货等8个类别进行训练,将不同方法训练获得的模型进行检测并比较分析。实验结果表明,本文模型在识别精度方面优于基础模型: 在稍微降低识别速度的前提下将识别准确率提高到了93.8%;相较于单纯使用VGG-11结构的模型,本文模型的准确率提高了4.2个百分点,识别速度则平均仅慢了0.198s。
1 相关工作
近几年深度学习的相关研究逐渐成熟后,国内外众多研究者针对视频识别提出了许多新方法或者基于现有研究的改进方法,基于这些方法,视频识别领域的研究得到了迅速的发展。可以将其大致分为两类:传统方法和深度学习方法。
1.1 传统方法
传统方法也就是深度学习引入之前的方法,通常从检测时空兴趣点(Space-Time Interest Points, STIP)[13]开始,然后用局部表示来描述这些点,基本步骤为关键点的选取、特征提取、特征编码、训练分类器。比较经典的有:密集轨迹(Dense Trajectories, DT)算法[14],利用光流场获取视频序列中的一些轨迹,沿着轨迹提取光流直方图(Histograms of Optical Flow, HOF)、定向梯度直方图(Histograms of Oriented Gradients, HOG)、運动边界直方图(Motion Boundary Histogram, MBH)和轨迹(trajectory)四种特征,最后利用Fisher矢量(Fisher Vector, FV)方法对特征进行编码,再基于编码结果训练支持向量机 (Support Vector Machine, SVM)分类器;改进的密集轨迹(Improved Dense Trajectories, IDT)算法[15],在DT算法的基础上利用前后帧视频间的光流和快速鲁棒特征(Speeded Up Robust Features, SURF)关键点进行匹配,从而消除/减弱相机运动带来的影响。相对来说,传统方法计算速度快,结构也相对简单,但是数据量过大时识别准确率较低。
1.2 深度学习方法
随着深度学习方法的提出,卷积神经网络逐渐广泛应用于计算机视觉领域,无论是图像分类、目标检测还是视频识别方面,都有大量学者采用深度学习的方法来进行研究。
文献[16]使用固定大小的窗口来堆叠由卷积神经网络提取的每一帧特征图,然后用时空卷积来学习视频特征。文献[17] 提出了一个多任务端到端联合分类回归递归神经网络,以更好地探索动作类型和时间定位信息,并通过采用联合分类和回归优化目标,自动定位动作的起点和终点。文献[18]提出了时序保留卷积 (Temporal Preservation Convolutional, TPC)网络,采用时序卷积操作能够在不进行时序池化操作的情况下获得同样大小的感受野而不缩短时序长度,但在卷积解卷积卷积(Convolutional-Deconvolutional -Convolutional, CDC)滤波器之前时间上的下采样存在一定时序信息的丢失。
文献[19]在文献[11]的基础上将循环卷积神经网络加以改进,提出了一种新的端到端深度神经网络模型——组约束卷积循环神经网络(Group-constrained Convolutional Recurrent Neural Network, GCRNN)用于时间序列分类(Time-Series Classification, TSC)。首先,采用并列的数个卷积神经网络对连续的几个视频帧提取特征并训练,再将前面提取的特征输入到后续的门控循环单元(Gated Recurrent Unit, GRU)神经元构成的循环神经网络来学习时序特征,最后进行全连接并使用softmax层训练。
可以看出,上述GCRNN模型训练过程较为繁杂,并且计算量较大,进行识别时所花的时间也相对较长。文献[10]中的3D卷积神经网络则解决了该问题,该网络将传统的二维卷积扩展到了三维,相比前面的方法,能更好地学习到视频帧的时序特征。因为二维卷积在进行第一次卷积之后就将时序信息完全折叠了,而三维卷积则在卷积之后保留了时序信息。文献[10]中采用的卷积网络是VGG-11网络,网络结构较为简单并且训练速度非常快,但由于训练的节点信息较少所以准确度相较于现在研究较为一般。因此基于上述考虑,本文将目前在识别准确率方面明显优于VGG-11网络的VGG-16网络作为三维卷积网络的骨干,并为了学习到更多的特征在此基础上加入部分Inception网络结构,并取得了更高的识别精度。
2 VIC3D模型
由于船舶的状态变化不明显,采用短时间内的连续帧的方法很难提取到有效的时序信息,对装卸货的识别准确率影响较大。因此本文采用每5min取一帧的方法,将相邻帧之间船舶的变化幅度扩大使装卸货的过程中货物量的变化更加明显,以6帧时序帧序列作为输入,以三维卷积作为基础框架,使用VGG-16网络并结合Inception网络的VIC3D模型来训练数据集,最后用模型对航运监控中船舶一段时间内的状态进行预警。
2.1 基于航运监控视频的三维卷积方法
三维卷积神经网络既学习图片的空间特征,也学习了视频相邻帧之间的时序信息,这得益于它采用的特殊卷积核。本文航运监控图像三维卷积的方法如图1所示。
从图1中可以看出,三维卷积不仅提取了单帧图片的空间特征,也提取了不同帧之间的时序特征,通过采用三维卷积核来提取相邻帧中同一区域的特征,因此获得的特征图也是三维的,而图中同种线型的线条代表提取特征时共享了权重。相较于使用传统的二维卷积,该方法解决了以往卷积方式无法提取时序特征的问题;然而该方法在卷积过程中,每次卷积都会对时间维度进行压缩,因此只能采用浅层的神经网络,但最后的卷积过程仍使用二维卷积,导致时序信息提取失败。
2014年牛津大学计算机视觉组合和Google DeepMind公司研究员提出了VGGNet系列的结构之后,文献[10]在文献[20]的研究基础上,引入了VGG-11网络,将其扩展到三维并经过改进后能保持使用三维卷积进行特征提取,避免了因引入二维卷积而丢失时序信息。因此本文将后者作为基础结构并加以改进。
2.2 基于三维卷积网络的Inception结构
最初,谷歌网络(GoogLeNet)对网络中的传统卷积层进行了修改,提出了Inception结构,主要特点在于不仅增加了神经网络的深度,还增加了宽度,以此来提高神经网络的性能,从最开始的Inception v1不断改进延伸到Inception v4,均在当时取得了不错的效果。
本文采用了Inception v4中的第三个模块(Inception-C),并对其中的各项参数作出调整来适用于本文的三维卷积神经网络模型。该模块可以更方便地与本文的模型结合,并且不会让模型过于复杂而导致计算资源不足的问题。由于网络层次过深的话容易出现梯度弥散而导致模型性能下降,并且会导致实际应用中的识别所需时间大幅增加,因此本文放弃了其他模块的加入。本文改进后的Inception-C结构如图2所示。
从图2中可以看出,该结构除了深度上的卷积层外,并列了多个卷积层以提取更多的特征,从而提高了模型的学习效果。
2.3 基于VGG与Incption网络的三维卷积网络模型
本文在上述三维卷积神经网络的基础上,选用效果更优的VGG-16網络作为基础网络,加入了Inception-C模块,并将最后一层卷积后的特征矩阵作为本文Inception-C结构的输入,在进行了级联操作后经过3个全连接层,最后一层是softmax层。本文VIC3D模型结构如图3所示。
本文的输入部分为等间隔取帧的连续6张图片,针对这种输入方式将VGG结构的前3层中池化层的步长设置为了1×2×2,避免了过早地将时间维度压缩而导致时序特征提取不够充分的问题。
该VGG结构的5层卷积层后的池化操作均采用了最大池化的方式,前2层卷积层均连续进行2次卷积,后3层则均连续进行3次卷积,共计13次卷积操作。
在第5层卷积层池化之后为Inception结构,由图2可以看出,该部分将前面卷积之后的特征图分别并列进行了4种卷积操作,最左侧的平均池化操作中的步长为1×1×1,采用了Valid填充方式,因此不会使输入的特征图大小发生改变。由于本文输入数据的时间维度为第一个维度,因此图2中的1×3×3卷积核仅是对空间部分特征的提取,而3×1×1卷积核则是单独对时间部分特征的提取,这种方式能够提取更加丰富的特征。该结构的最后部分是将5个特征图并联起来作为后续输入。
本文三维卷积结构的最后部分首先采用了一层平均池化层将时间维度进行最后的压缩,然后进行全连接,这里将全连接层的大小改为2048以减少计算量。
此外,本文对基于VGG的三维卷积网络加入了滑动平均来更新变量,滑动平均可以看作是变量的过去一段时间取值的均值,相较对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大。变量的更新可以表示为:
其中:变量v在t时刻更新之后记为v(t);变量v在t时刻更新之前的取值为θ(t);衰减率α决定了变量的更新速度,取值越大变量越趋于稳定,一般选取接近1的值。
本文损失函数选用的多分类任务中常用的交叉熵(Cross-Entropy)损失函数,其定义如下:
其中:n表示样本数;m为类别数;y为实际类别的one-hot向量;f∧(x)为预测的类别概率。用式(2)来计算softmax回归处理之后预测概率分布与真实概率分布之间的距离。
3 实验与结果分析
3.1 数据集描述
本文采用的数据集为航运智能监控项目中积累的数据集,船上摄像头的监控视频传到服务器后处理成了连续的视频帧,本文将从图片服务器上获取的数据按照相应类别分好后形成了初步的数据集,并舍弃了黑夜部分的数据,仅保留了白天部分用作训练。
经过长时间的筛选,去除了数据集中图像质量不佳、图片显示不完整以及一些严重受到天气影响的数据,然后将剩下的数据集每一类的数量进行了平衡,避免因不同类别之间数据量差异过大而导致模型训练不佳的问题;对那些数据量过大的类别,采取对同一条船同一天的数据适量选取的方法,既可以适当削减该类别占数据集的比重,又可以丰富该类别数据的多样性。
经过上述筛选,截至目前为止,本文的数据集总共包含153000张图片,相当于25500个视频片段,共计8个类别,其中装货以及卸货部分数据量最少,两者分别为9990张和10800张。因此,在进行数据预处理时按照适量选取的方式将每一类数据量控制在12000张图片,也就是2000段视频片段,并按照9∶1的比例建立训练集与测试集。
3.2 模型训练
1)GCRNN模型训练。
该部分采用的是GCRNN模型[17]对本文的数据集进行训练,输入的图片大小为256×256,首先用6个卷积网络对每张图片进行特征提取,然后将提取的特征合并后输入循环神经网络(采用的GRU神经元)学习时序特征,设置如下:丢失率为0.9,学习率为0.001,batch_size为32,训练总次数为7000。
本文在上述基础上将前面提取特征的卷积网络替换为了50层的残差网络(Resnet50),该网络能更充分地提取图像特征。对于该部分网络提取的特征,经过实验比较之后,最终选择了第二模块的最后一层特征图作为后续循环神经网络的输入,因为层数过浅的特征提取得信息不够完善,而层数过深的则损失了过多的船体结构信息,导致后续循环神经网络部分提取的时序信息不足,从而影响模型的效果。其他参数的设置与上述一致。
2)以VGG与Inception结构为基础的三维卷积模型训练。
首先将分好的数据集进行后续处理,按照每连续6张图来建立一个子文件夹,这样一个子文件夹就相当于一段输入视频,由于VGG网络的标准输入为224×224,所以将连续的6张图片缩放为224×224的大小作为VGG网络的输入,也就是输入数据的大小为6×224×224×3。
首先,采用基于VGG-11网络结构的三维卷积模型进行训练,设置:丢失率为0.8,batch_size为8,学习率为0.0001,滑动平均衰减率为0.9999,训练总次数为3000次。然后,在VGG-11网络的最后一层卷积层之后加入Inception-C模块,将训练次数设置为4000,其他参数不变。接着,将VGG-11网络替换为VGG-16网络,训练次数设置为4000。最后,将Inception-C模块加入到VGG-16网络中,其他参数不变。
3.3 结果分析
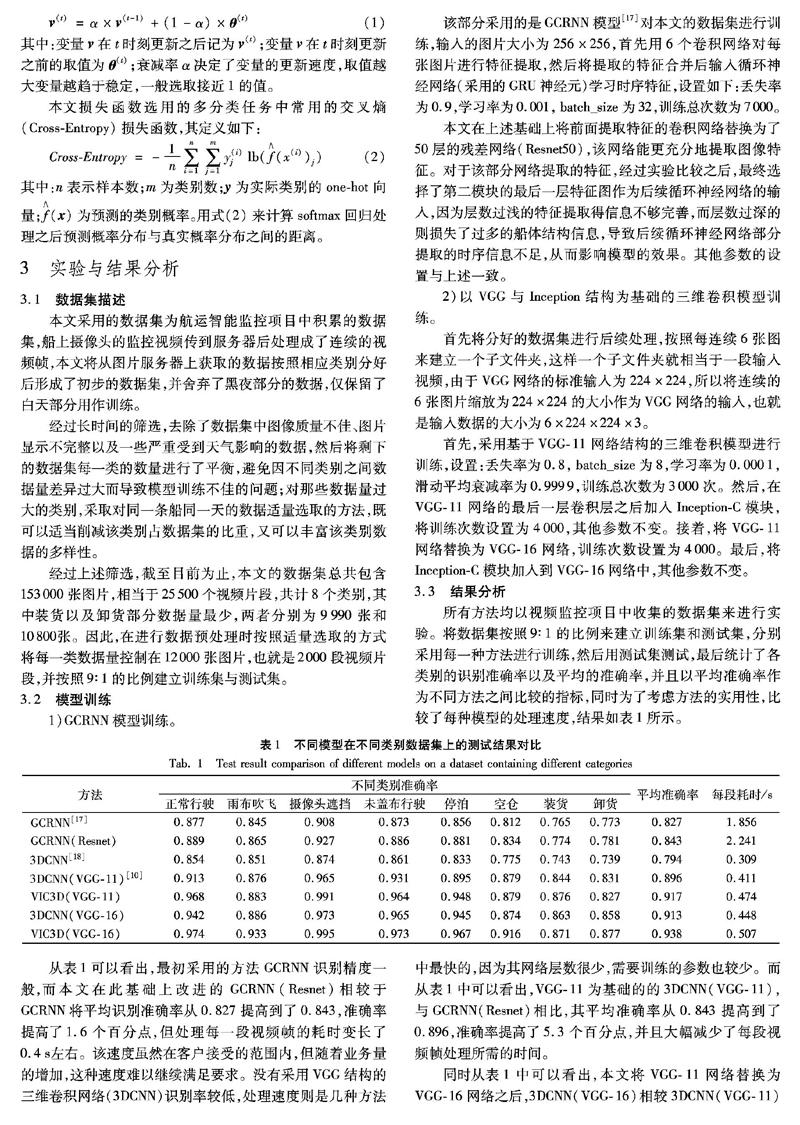
所有方法均以视频监控项目中收集的数据集来进行实验。将数据集按照9∶1的比例来建立训练集和测试集,分别采用每一种方法进行训练,然后用测试集测试,最后统计了各类别的识别准确率以及平均的准确率,并且以平均准确率作为不同方法之间比较的指标,同时为了考虑方法的实用性,比较了每种模型的处理速度,结果如表1所示。
从表1可以看出,最初采用的方法GCRNN识别精度一般,而本文在此基础上改进的GCRNN(Resnet)相较于GCRNN将平均识别准确率从0.827提高到了0.843,準确率提高了1.6个百分点,但处理每一段视频帧的耗时变长了0.4s左右。该速度虽然在客户接受的范围内,但随着业务量的增加,这种速度难以继续满足要求。没有采用VGG结构的三维卷积网络(3DCNN)识别率较低,处理速度则是几种方法中最快的,因为其网络层数很少,需要训练的参数也较少。而从表1中可以看出,VGG-11为基础的的3DCNN(VGG-11),与GCRNN(Resnet)相比,其平均准确率从0.843提高到了0.896,准确率提高了5.3个百分点,并且大幅减少了每段视频帧处理所需的时间。
同时从表1中可以看出,本文将VGG-11网络替换为VGG-16网络之后,3DCNN(VGG-16)相较3DCNN(VGG-11)平均准确率提高了1.7个百分点,处理速度稍微下降,表明了VGG-16网络相较于VGG-11能更有效地学习视频特征。而与之相对的,采用VGG-11与Inception结构相结合的方法VIC3D(VGG-11)比单纯替换为VGG-16的方法3DCNN(VGG-16)平均准确率提高了0.4个百分点,相较VGG-11的方法3DCNN(VGG-11)则提高了2.1个百分点。相较之前用到的三种三维卷积方法3DCNN(VGG-11)、VIC3D(VGG-11)、3DCNN(VGG-16),本文选用的最终方法VIC3D(VGG-16)的平均准确率分别提高了4.2个百分点、2.1个百分点和2.5个百分点,处理每段视频帧的速度也只是稍微下降,并且该处理速度在实际应用中完全满足需求。
通过对比不同方法的检测结果可以发现:GCRNN中的循环神经网络部分虽然可以学习时序特征,但应用到视频识别方面的效果还是不太理想,并且模型过于复杂而导致了训练所需时长较长,收敛速度与处理速度也比较慢;没有使用VGG网络的三维卷积网络3DCNN与使用的3DCNN(VGG-11)相比,准确率差别达到了10.2个百分点,主要是因为3DCNN在卷积时折叠了时序特征,导致最后的特征图中时序信息大部分丢失,从而影响了识别效果。对于基于VGG结构的三维卷积网络,加入了Inception模块的方法在稍微牺牲处理速度的前提下准确率均要优于没有加入该模块的方法,并且本文提出的VIC3D方法在这些方法中取得了最高的识别准确率。
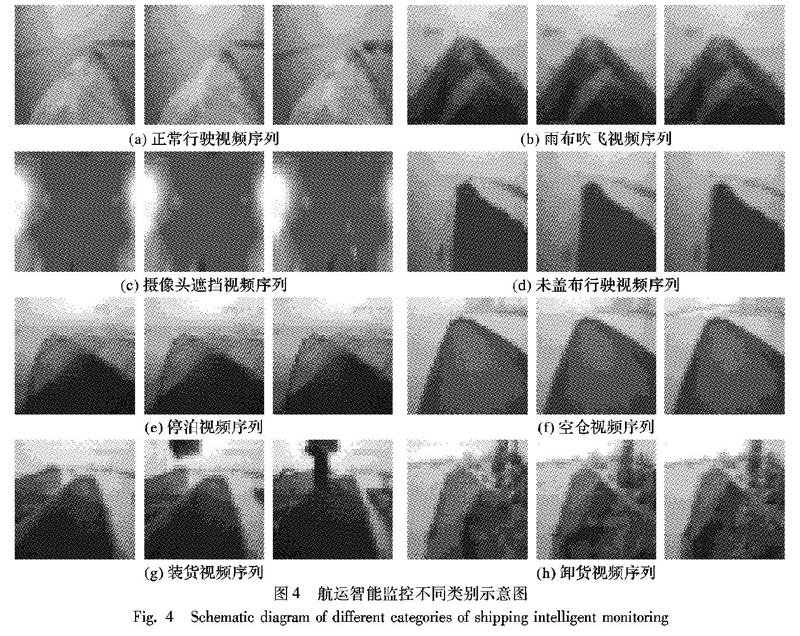
表1中各個类别为客户要求而选择的类别划分,从表1中可以看出,本文提出的VIC3D方法在各类别的识别准确率相较其他方法要更高;但各类别之间识别率差别较大,装卸货、空仓以及雨布吹飞的准确率相对较低,其中雨布吹飞容易错分为正常行驶,空仓容易错分为未盖布,装卸货则容易错分为停泊等,主要原因是有些类别之间的界限不是很明确,以及江海上恶劣天气的影响。航运智能监控类别示意图如图4所示,其中:(1)~(3)为正常行驶,(4)~(6)为雨布吹飞,(7)~(9)为摄像头遮挡,(10)~(12)为未盖布行驶,(13)~(15)为停泊,(16)~(18)为空仓,(19)~(21)为装货,(22)~(24)为卸货。
由于在实际应用中客户会对某一类别比较关注,这时仅采用准确率作为衡量指标不能满足客户需求,如出于对货物安全的考虑,客户对雨布吹飞这个类别更为关注,因此对于该类别,本文比较了不同方法的查全率、查准率以及F1度量。不同方法对于雨布吹飞这个类别的上述三种指标值的结果如表2所示。
从表2中可以看出,本文提出的方法VIC3D(VGG-16)取得了最高的查准率和F1度量,并且查全率也相对较高,表明了本文所提模型有相对最优的性能。
4 结语
针对传统的机器学习算法对大数据量的航运监控视频识别分类效果不佳,以及以往的三维卷积识别准确率较低的问题,本文提出了一种基于VGG-16的三维卷积网络并引入Inception模块的VIC3D模型对航运货物实时监控视频进行智能识别。实验中,使用智能航运监控项目中获取的数据集,并将其分为装卸货等8个类别进行训练,将不同方法训练获得的模型进行检测并比较分析。在航运智能监控项目数据集上的实验结果表明,本文提出的VIC3D模型能有效提高监控视频识别的准确率,并且在处理每段视频帧的速度上也足以满足客户需求。
本文方法是在多个现有方法的基础上,针对该数据集以及现有研究上的不足,最后将不同网络结构进行结合,以较高的准确率对航运监控视频作出类别预测,并在识别速度上满足了需求。但本文方法最终的准确率对于应用到项目上来说还不是很高,个别类别准确率仍有待于进一步提升,因此还需要进一步的研究以达到更高的准确率。
参考文献 (References)
[1]HASSABIS D, KUMARAN D, SUMMERFIELD C, et al. Neuroscience-inspired artificial intelligence [J]. Neuron, 2017, 95(2): 245-258.
[2]邓昀,李朝庆,程小辉.基于物联网的智能家居远程无线监控系统设计[J].计算机应用,2017,37(1):159-165.(DENG J, LI C Q, CHENG X H. Design of remote wireless monitoring system for smart home based on Internet of things [J]. Journal of Computer Applications, 2017, 37(1): 159-165.)
[3]梁光胜,曾华荣.基于ARM的智能视频监控人脸检测系统的设计[J].计算机应用,2017,37(S2):301-305.(LIANG G S, ZENG H R. Design of intelligent video surveillance face detection system based on ARM [J]. Journal of Computer Applications, 2017, 37(S2): 301-305.)
[4]GUAN Z, MIAO Q, SI W, et al. Research on highway intelligent monitoring and warning system based on wireless sensor network [J]. Applied Mechanics and Materials, 2018, 876: 173-176.
[5]LIU Z, JIANG S, ZHOU P, et al. A participatory urban traffic monitoring system: the power of bus riders [J]. IEEE Transactions on Intelligent Transportation Systems, 2017, 18(10): 2851-2864.
[6]刘全,翟建伟,章宗长,等.深度强化学习综述[J].计算机学报,2018,41(1):1-27.(LIU Q, ZHAI J W, ZHANG Z Z, et al. A summary of deep reinforcement learning [J]. Chinese Journal of Computers, 2018, 41(1): 1-27.)
[7]REN R, HUNG T, TAN K C. A generic deep-learning-based approach for automated surface inspection [J]. IEEE Transactions on Cybernetics, 2018, 48(3): 929-940.
[8]SCHMIDHUBER J. Deep learning in neural networks: an overview [J]. Neural Networks, 2015, 61: 85-117.
[9]LAN Z, ZHU Y, HAUPTMANN A G, et al. Deep local video feature for action recognition [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1219-1225.
