基于多尺度属性粒策略的快速正域约简算法
2019-01-06陈曼如张楠童向荣东野升龙杨文静
陈曼如 张楠 童向荣 东野升龙 杨文静

摘要:传统启发式正域属性约简算法在每次迭代的过程中需要添加当前正域依赖度最大的属性进入已选定的特征属性子集,算法迭代次数多且效率低,难以应用于高维大规模数据集的特征选择中。针对上述问题,研究决策系统中正域之间的单调关系,给出了多尺度属性粒(MSAG)的形式化描述,提出了一种基于多尺度属性粒的快速正域约简算法(MAG-QPR)。由于多尺度属性粒包含多个属性,可以对已选定的特征属性子集提供较大的正域,因此,通过每次迭代添加MSAG,可以达到减少迭代次数和使选定的特征属性子集能更快地趋近于条件属性全集的正域分辨能力的目的,从而提高了启发式正域约简算法的效率。在实验部分,选取8组UCI数据进行实验,对于数据集Lung Cancer、Flag和German,MAG-QPR与基于正向近似的正域保持属性约简算法 (FSPA-PR)、基于正向近似的条件熵属性约简算法(FSPA-SCE)、后向贪婪正域保持属性约简算法 (BGRAP) 和后向贪婪启发式广义决策保持属性约简算法(BGRAG)的运行时间加速比分别为9.64、15.70、5.03、2.50;3.93、7.55、1.69、4.57;3.61、6.49、1.30、9.51。实验结果表明,所提算法MAG-QPR提高了算法效率,具有更好的分类精度。
关键词:属性约简;粗糙集;多尺度属性粒;正域约简;快速约简算法
中图分类号: TP181;TP301.4文献标志码:A英文标题
Multi-scale attribute granule based quick positive region reduction algorithm
CHEN Manru1,2, ZHANG Nan1,2*, TONG Xiangrong1,2, DONGYE Shenglong1,2, YANG Wenjing1,2
(1. Key Lab for Data Science and Intelligence Technology of Shandong Higher Education Institutes
(Yantai University), Yantai Shandong 264005, China;
2. School of Computer Science and Control Engineering, Yantai University, Yantai Shandong 264005, China)
Abstract: In classical heuristic attribute reduction algorithm for positive region, the attribute with the maximum dependency degree of the current positive domain should be added into the selected feature attribute subset in each iteration, leading to the large number of iterations and the low efficiency of the algorithm, and making the algorithm hard to be applied in the feature selection of high-dimensional and large-scale datasets. In order to solve the problems, the monotonic relationship between the positive regions in a decision system was studied and the formal description for the Multi-Scale Attribute Granule (MSAG) was given, and a Multi-scale Attribute Granule based Quick Positive Region reduction algorithm (MAG-QPR) was proposed. Each MSAG contains several attributes and can provide a large positive region for the selected feature attribute subset. As a result, adding MSAG in each iteration can reduce the number of the iteration and make the selected feature attribute subset more quickly approach to the positive region resolving ability of the condition attribute universal set. Therefore, the computational efficiency of the heuristic attribute reduction algorithm for positive region is improved. With 8 UCI datasets used for experiments, on the datasets Lung Cancer, Flag and German, the running time acceleration ratios of MAG-QPR to the general improved Feature Selection algorithm based on the Positive Approximation-Positive Region (FSPA-PR), the general improved Feature Selection algorithm based on the Positive Approximation-Shannons Conditional Entropy (FSPA-SCE), the Backward Greedy Reduction Algorithm for positive region Preservation (BGRAP) and the Backward Greedy Reduction Algorithm for Generalized decision preservation (BGRAG) are 9.64, 15.70, 5.03, 2.50; 3.93, 7.55, 1.69, 4.57; and 3.61, 6.49, 1.30, 9.51 respectively. The experimental results show that, the proposed algorithm MAG-QPR can improve the algorithm efficiency and has better classification accuracy.英文關键词
Key words: attribute reduction; rough set; multi-scale attribute granule; positive region reduction; quick reduction algorithm
0引言
粗糙集理论(rough set theory)[1-2]是一种描述不精确、不确定性信息的形式化工具。目前已经广泛地应用于机器学习、模式识别和数据挖掘等研究领域。属性约简(attribute reduction)[3-9]是粗糙集与粒计算研究的重要问题之一,受到众多学者的广泛关注与深入研究。随着大规模高维数据集中数据量的迅速膨胀,数据的冗余特征(属性)也伴随增多,这会严重降低计算机的计算效率,增加计算机存储的负担,降低数据分类模型的泛化、预测能力。因此,找到与原始数据集具有相同分辨能力(或分类能力)的特征子集显得尤为重要。在粗糙集与粒计算研究中,这样的特征(属性)子集的选择过程被称为属性约简,或属性(子集)选择。
粗糙集中现有的属性约简方法主要分为基于差别矩阵的约简方法和基于启发式的约简方法。为了求取给定数据集的所有特征子集(约简),文献[10]较早地给出了差别矩阵(discernibility matrix)的形式化描述, 但由于差别矩阵求解约简需要将差别函数中的主合取范式(Conjunctive Normal Form, CNF)转换为主析取范式(Disjunctive Normal Form, DNF),因此,通过差别矩阵求解约简是一个NP-hard问题。当数据集中数据量增加时,基于差别矩阵的约简效率会急剧降低。相较于基于Skowron差别矩阵的约简方法,基于启发式的约简方法可以通过启发式的搜索策略得到一个约简结果。相同数据量下,其算法效率优于基于差别矩阵的约简方法。因为现代社会信息化程度的日益提高,数据量的急速增加,对信息时效性的需求变得愈加强烈,为了更高效、快捷地求取属性约简,众多学者展开了深入的讨论、分析。文献[11]设计了论域划分的快速求解办法并提出了一种新的属性约简方法。文献[12]通过删除启发式搜索迭代过程中的部分对象(粗粒度下的正域),构造了基于正向贪婪的属性约简加速算法框架。在该框架下,分别提出了正区域保持不变、条件信息熵保持不变、梁的条件信息熵保持不变、組合熵保持不变的四种加速算法。实验结果表明,采用该框架可以有效地提高四种算法的属性约简效率。除了考虑迭代过程中删除的正区域对象,文献[13]还在属性约简的迭代过程中删除了不必要的特征集合,提出了一种快速的启发式属性约简框架。文献[14]通过给出一种求解等价类的快速排序算法,设计了一种算法复杂度为O(|C|2|U|)的冲突域属性约简方法。文献[15]通过对论域中所有对象进行抽样,提出了基于样例选取的差别矩阵属性约简算法ISDMAR,实验证明ISDMAR能在保持分类精度不降低的情况下有效提高约简算法效率。考虑到文献[15]中提出的算法是基于差别矩阵的,在大规模数据集合中效率较低,文献[16]基于启发式的论域对象抽样属性约简算法,大幅降低了算法运行的时间,提高了算法的效率。文献[17]与文献[18]分别对变精度粗糙集模型(Variable Precision Rough Set Model, VPRSM)近似集的动态更新和动态更新在决策系统中规则的应用先后进行了研究。文献[19]根据相关分辨度的概念设计了一种新的属性约简贪心算法。在不完备信息系统,文献[20]提出了两种单调的启发式信息,由两种启发式信息分别提出了基于不可分辨关系的快速约简算法ARIR(Attribute Reduction algorithm based on the Indiscernibility Relation)和基于分辨关系的快速约简算法ARDR(Attribute Reduction algorithm based on the Discernibility Relation)。为了降低计算正区域所占用的时间,文献[21]给出了属性依赖度计算的快速算法,该算法能有效地降低算法在内存中的占用率,从而降低算法运行时间。文献[22]对主要属性约简方法的复杂度、完备性进行了有效的分析。文献[23-24]在动态变化数据值下提出了一种组增量式属性约简算法使得算法更高效。
第12期 陈曼如等:基于多尺度属性粒策略的快速正域约简算法计算机应用 第39卷综上,现有加速启发式算法的方法有优化等价类划分、正向近似加速机制、优化启发因子等,在迭代过程中计算候选属性子集时很少有学者进行优化研究。本文研究了决策系统中正域之间的单调关系,给出了多尺度属性粒的形式化描述,提出了一种基于多尺度属性粒策略的快速正域约简算法(Multi-scale Attribute Granule based Quick Positive Region reduction algorithm, MAG-QPR)。该算法通过在启发式属性约简的每次迭代中添加多属性粒,达到减少迭代次数并使得选定的特征属性子集能更快地趋近于完整的条件属性集正域分辨能力的目的,从而加快了启发式正域约简算法速度,进而提高算法效率。
1基础知识
本章将介绍与本文研究相关的粗糙集基本概念和定理,更加详细的内容请参见文献[1]。
定义1[3]信息表(信息系统)。InS可以形式化为一个二元组InS=(O,A)。在InS中,论域O表示对象(样本)的集合;属性集A表示属性(特征)的集合。
若属性集A由C与D两个交集为空的非空集合组成,C为条件属性集,D为决策属性集,则InS是被称为一个决策表(决策系统),表示为Des=(O,C∪D)。经典粗糙集中,讨论的决策属性集D通常只包含一个决策属性,即D={d}。
定义2[3]给定的信息表InS=(O,A),论域O={o1, o2,…, on},oi, oj∈O,对于QC,定义Q上的不可分辨二元关系为:
IR(Q)={(oi,oj)|(oi,oj)∈U2,m∈Q,f(ui,m)=f(uj,m)}
易得IR(Q)满足IR(Q)=∩m∈QIR({m}),且IR(Q)是一个等价关系。
[oi]IND(Q)={oj|oj∈U且m∈Q, f(oi,m)=f(oj, m)}是关于属性集Q包含对象oi的等价类,商集O/IR(Q)={[oi]IND(Q)|oi∈O}。
在不引起混淆的情况下,IR(Q)可用Q来表示。
定义3[3]给定的信息表InS=(O,A),若SO,QA,则定义S的下、上近似集为:
Q(S)=∪{[o]Q|[o]QS}
Q(S)=∪{[o]Q|[o]Q∩S≠}
对于QC与SO, S的下近似集由相对于Q的确定属于S的对象构成,S的上近似是由相对于Q的可能属于S的对象组成。由定义3易得,上近似集Q(S)包含下近似集Q(S)。
根据上述定义给出以下定义:
PSQ(S)=Q(S)
NGQ(S)=O-Q(S)
BNQ(S)=Q(S)-Q(S)
其中:PSQ(S)是S关于Q属性集的正域,由属性集Q下确定属于集合S里的对象构成;NGQ(S)为S关于属性集Q的负域,由属性集Q下确定不属于集合S的对象构成;BNQ(S)是S关于Q属性集的边界域,由属性集Q下不确定属于集合S的对象构成。
PSQ(S)、BNQ(S)和NGQ(S)的关系如图1所示。
定义4[3]给定的决策表DeS=(O,C∪D),对QC,论域对D的划分表示为U/D,Dj∈U/D。关于属性集Q的决策下近似和上近似集定义为:
Q(D)=∪{[o]Q|[o]QDj}
Q(D)=∪{[o]Q|[o]Q∩Dj≠}
PSQ(D)=Q(D)是关于属性集Q的决策属性D的正域。
定义5[3]给定的决策表DeS=(O,C∪D),QC是一个DeS的正域约简(a reduct for positive region),当且仅当Q满足如下两个条件:
1)|PSQ(D)|=|PSC(D)|;
2)PQ,|PSp(D)|<|PSQ(D)|。
例1表1是給定的决策表,论域O={o1, o2,…, o8},条件属性集C={a1,a2,a3,a4},决策属性集D={d}。
2本文算法MAG-QPR
基于迭代中一次添加多个属性的策略,本节提出了一种新的快速正域约简算法,并对算法复杂度进行了分析。
定理1[12]给定的决策表DeS=(O,C∪D),若PQC,则PSP(D)PSQ(D)。
定理2[12]给定的决策表DeS=(O,C∪D),若PiC,则:
PSOPi+1(D)=PSOPi(D)∪PSOi+1Pi+1(D)
其中,O1=O且Oi+1=O-PSOPi(D)。
定理3[12] 给定的决策表DeS=(O,C∪D), 对于任意的QC,O=O-PSOQ(D)。对m,n∈C-Q,|PSOQ∪{m}(D)-PSOQ(D)|≥|PSOQ∪{n}(D)-PSOQ(D)|,则:
|PSOQ∪{m}(D)-PSOQ(D)|≥|PSOQ∪{n}(D)-PSOQ(D)|
定理3是一个正域属性重要度的保持定理,该定理表明:若在论域为O的计算空间下,m关于正域的外部属性重要度大于等于n关于正域的外部属性重要度。则在论域为O*Q的计算空间下,m关于正域的外部属性重要度仍大于等于n关于正域的外部属性重要度。因此,在迭代计算中,为了提高启发式算法效率,只需要以O*作为论域(计算空间)即可。
定理4给定的决策表DeS=(O,C∪D),对QC,则∪m∈QPS{m}(D)PSQ(D)。
证明m,n∈Q, PS{m}(D)∪PS{n}(D)PS{m}∪{n}(D)。因此,∪m∈QPS{m}(D)PSQ(D)。证毕。
定理5给定的决策表DeS=(O,C∪D), 对于m,n∈C, PS{m}(D)-PS{n}(D)≠,若|PS{m}(D)|≥|PS{n}(D)|,则|PS{m}∪{n}(D)|>|PS{m}(D)|。
证明1)若|PS{m}(D)|>|PS{n}(D)|,由正域随属性变化的单调性,易得|PS{m}∪{n}(D)|>|PS{m}(D)|;2)若|PS{m}(D)|=|PS{n}(D)|,由于PS{m}(D)≠PS{n}(D),{m}∪{n}对组成的属性集产生比属性m(或属性n)更细的粒度,因此|PS{m}∪{n}(D)|>|PS{m}(D)|。证毕。
定义6 给定的决策表DiS=(O,C∪D), 对于QC,pi∈C-Q。如果:
|PSQ∪{p1}(D)|≥|PSQ∪{p2}(D)|≥…≥
|PSQ∪{p|C-Q|}(D)|
且:
PSQ∪{p2}(D)-PSQ∪{p1}(D)≠
PSQ∪{p3}(D)-PSQ∪{p1}(D)-PSQ∪{p2}(D)≠
…
PSQ∪{pk}(D)-PSQ∪{p1}(D)-…-PSQ∪{pk-1}(D)=
PSQ∪{pk+1}(D)-PSQ∪{p1}(D)-…-PSQ∪{pk}(D)≠
…
POSQ∪{p|C-Q|}(D)-POSQ∪{p1}(D)-…-
POSQ∪{pk-1}(D)-POSQ∪{pk+1}(D)-…-
POSQ∪{p|C-Q|-1}(D)≠
则grand(Q)={p1,p2,…,pk-1,pk+1,…,p|C-Q|}是关于集合Q的多尺度属性粒,其中1≤k≤|C-Q|。
定义6表明,通過做差集运算保证grand(Q)中的每个属性和集合Q的并集相对于决策属性D产生的正域之间两两不存在包含关系。即:grand(B)中的属性满足PSQ∪{p1}(D),PSQ∪{p2}(D),…,PSQ∪{pk-1}(D),PSQ∪{pk+1}(D),…,PSQ∪{p|C-Q|}(D)产生的集合不存在两两包含关系。
定理6给定的决策表DeS=(O,C∪D),集合QC,令grand(Q)={p1,p2,…,pj},则:
|PSQ∪grand(Q)(D)|>|PSQ∪{p1}(D)|
|PSQ∪grand(Q)(D)|>|PSQ∪{p1}(D)∪PSQ∪{p2}(D)|
…
|PSQ∪grand(Q)(D)|>|PSQ∪{p1}(D)∪PSQ∪{p2}(D)∪
…∪PSQ∪{pj-1}(D)|
其中1≤j≤|grand(Q)|。
证明根据定理5易知定理6成立。证明略。
因为grand(Q)中的属性和集合Q产生的正域不存在两两包含关系。因此,每次迭代添加的属性粒(集)形成的正域较经典启发式算法中每轮添加的单个属性形成的正域要大,故加快了迭代的速度,提高了算法效率。
基于多尺度属性粒策略的快速正域约简算法(MAG-QPR)算法伪代码如下。
算法1有如下四点优势:
1)一般情况下,算法1每次迭代添加的属性集形成的正域大于经典启发式正域约简算法中每次添加的单个属性形成的正域,这样可以更快地趋近于正域约简的停止条件,即定义5中的|PSQ(D)|=|PSC(D)|。
2)由于每次迭代添加的属性集包含多个属性,因此,算法1总的迭代次数较经典启发式正域约简算法较少。迭代次数减少,则算法效率提高。
3)现有的启发式算法求核仍采用删除法,即通过逐个删除属性的方法来求取核属性。在大规模数据集下,这显然是低效的。因此,算法1不从核属性集出发,直接进行迭代计算。
4)采用迭代过程中,删除一部分对象集(待计算空间的正域或粗粒度下的正域)的方法来减少计算空间,进而提高启发式算法的效率。算法1的主要流程如图2所示,其中,A部分采用多尺度属性粒方法来计算候选属性的正域重要度,B部分删除候选属性集的正域,C部分为取出启发式算法可能产生的冗余属性。
假设T表示算法1的时间复杂度,条件属性集的基数为m,论域的基数为n,迭代第i轮次中待评估的属性基数为mi,迭代第i轮次中的剩余对象数ni,k≤|C|表示需要迭代的轮次。除去正域与将多尺度属性粒添加到候选子集的时间复杂度可表示为O(∑ki=1mini),去除冗余属性的时间复杂度可表示为O(m2n)。综上,算法1的整体时间复杂度为T=O(m2n+∑ki=1mini)。
例2如例1中的决策系统,O={o1, o2, o3,…, o8}为论域,C={a1,a2,a3,a4}为条件属性集合,D={d}决策属性集合。
按照算法1对例1中的表进行属性约简,具体计算过程如下:
1) 开始首次迭代,初始R=,因此C=C-R中任意属性的决策正域值为|PSO1a1(D)|=1,|PSO1a2(D)|=0,|PSO1a3(D)|=0,|PSO1a1(D)|>|PSO1a2(D)|≥|PSO1a3(D)|≥|PSO1a4(D)|。且:
PSO1R∪{a2}(D)-PSO1R∪{a1}(D)=
PSO1R∪{a3}(D)-PSO1R∪{a1}(D)=
PSO1R∪{a4}(D)-PSO1R∪{a1}(D)=
则grand(R)={a1},R=R∪grand(R)={a1},O2={o1, o2,…, o8}。
由于|PSO2C(D)|≠|PSO2R(D)|,所以继续第二次迭代。
2)计算C-R中任意属性与R并集的决策正域的值为|PSO2R∪{a2}(D)|=4,|PSO2R∪{a3}(D)|=2,|PSO2R∪{a4}(D)|=3,|PSO2R∪{a2}(D)|>|PSO2R∪{a4}(D)|>PSO2R∪{a3}(D)|。且:
PSO2R∪{a4}(D)-PSO2R∪{a2}(D)≠
则grand(R)={a2,a4},R=R∪grand(R)={a1,a2,a4},O3=O2-PSO2R(D)={o7, o8}。
由于|PSO3C(D)|=|PSO3R(D)|,迭代结束。
如果R中减去任意的属性ai均不改变R的决策正域,因此,属性集R中不存在冗余或不相关的属性,整个算法结束;综上,可得决策表1的约简为R={a1,a2,a4}。
3实验与结果分析
本文的实验采用了UCI标准数据集对算法进行测试,UCI数据集的详细信息如表2所示,共有8组UCI数据集。实验所使用的PC机硬件环境为:CPU为Intel i5-2450M,内存为4GB。软件环境:操作系统为Windows 7,编程环境为Matlab 7.11.0(R2010b)。
实验分成四组。第一组:将本文提出的算法与FSPA-PR(a general improved Feature Selection algorithm based on the Positive Approximation-Positive Region) [12]、FSPA-SCE(a general improved Feature Selection algorithm based on the Positive Approximation-Shannon Conditional Entropy) [12]、BGRAP(a Backward Greedy Reduction Algorithm for Positive region preservation) [22]、BGRAG(A Backward Greedy Reduction for Generalized decision preservation) [25]四种算法对于算法消耗的时间与属性约简的长度进行详细的比较。第二组:将本文算法在不同数据集上迭代的详细情况和最终的约简结果进行比较。第三组:将本文算法与其他四种算法对于论域规模和消耗时间之间关系进行比较。第四组:将本文算法与其他四种算法在分类精度方面进行比较。
表2给出了实验所需数据集的基本信息(样本数量、条件属性与决策类数量)。Ticdata2000数据集为了训练和验证预测模型并建立描述(5822个客户记录);Student Performance数据提供了接近两个葡萄牙语学校中学教育的学生成绩(数据属性包括:学生等级、人口统计学、社会学和学校相关特征等);QSAR Biodegradation为定量结构活性关系生物降解数据集,决策类别为是否可以生物降解;Zoo数据集为动物园数据集,由16个属性来描述样本,其中15个为布尔属性值{0,1}和1个分类属性(腿的数量){0,2,4,6,8};Kr-vs-kp数据集描述了灵长类动物的基因序列不完善理论;Flag数据集通过判断一个国家的国旗颜色、国旗上圆圈的数量,以及国旗上星星的数量等预测这个国家的宗教信仰;German数据集为德国信誉数据,通过人的属性描述一个人的好坏信誉;Lung Cancer数据集记录了病人的肺癌数据。由表2可以看出:数据集1的规模最大,包含的属性数目和样本数目均为最多;数据集2包含的决策类数目最多;数据集4包含的属性数目最少;数据集8包含的样本数目最少;数据集1、3、7和8包含的决策类数目最少。
表3给出了MAG-QPR与其他四种算法在消耗时间和属性约简长度的对比。不难看出,本文提出的MAG-QPR在8组数据集上的消耗时间均为最少,因此,MAG-QPR具有较高的运行效率。例如,在数据集Lung Cancer中,MAG-QPR所需要的时间为0.1150s,而算法FSPA-PR、BGRAP、FSPA-SCE与BGRAG所需的时间分别为1.1086s、0.5783s、1.8054s与0.2876s。这四种算法消耗时间分别是MAG-QPR消耗时间的9.64、5.03、15.70与2.50倍。在数据规模较大的Ticdata2000中,MAG-QPR所需要的时间为126.9767s,而算法FSPA-PR、BGRAP、FSPA-SCE与BGRAG所需的时间分别为527.5613s、250.2735s、823.1517s与3392.7184s。这四种算法消耗时间分别是MAG-QPR消耗时间的4.1、1.97、6.48与26.71倍。由于多尺度属性粒包含多个属性,因此在启发式约简的迭代过程中一次性添加进选定特征属性子集的属性数量较多,算法效率较高,同时删除了每次迭代中的部分正域,因此本文提出的MAG-QPR所需的时间相较于其他四种算法较短。
不同算法的时间效率对比如图3所示,图3给出了不同算法消耗时间随数据规模的变化趋势。图3中:纵轴代表算法消耗的时间;横轴代表论域(对象)的规模,将每个数据集的论域(对象集)分为10等份,逐一叠加作为测试数据集。例如,若给定的UCI数据集有4000个对象,将4000个对象分10等份,第一个测试数据集的论域由前400个对象构成,第二个测试数据集的论域由前800个对象构成,……,第十个测试数据集的论域由全部4000个对象构成。总体上,五种算法的消耗时间均随着论域规模的增大而增加,但在局部并不保持严格的单调性。例如:如图3(c),论域规模从5增加到6,算法FSPA-PR消耗的时间反而下降;又如图3(g), 论域规模从8到9,MAG-QPR消耗的时间变少。这是因为启发式算法迭代中每次选择的属性均为局部最优解,因此消耗时间在局部内会出现随着数据规模的增大而减少的情况。从图3还可以发现,相较于其他四种算法(FSPA-PR、BGRAP、FSPA-SCE与BGRAG),MAG-QPR曲线平均斜率偏小,更贴近于水平轴。且MAG-QPR曲线随着论域规模增大的计算时间变化较小,而其他四种算法随着论域规模增大的计算时间变化较大。对于图3中的每一个数据集,当论域规模较小时,五种算法消耗时间的差别并不是很明显;当随着论域规模由小变大时,五种算法消耗时间的差别越来越大,MAG-QPR消耗时间较少的优势越来越明显。因此,对于大规模数据集,本文提出的MAG-QPR具有较大的优势。
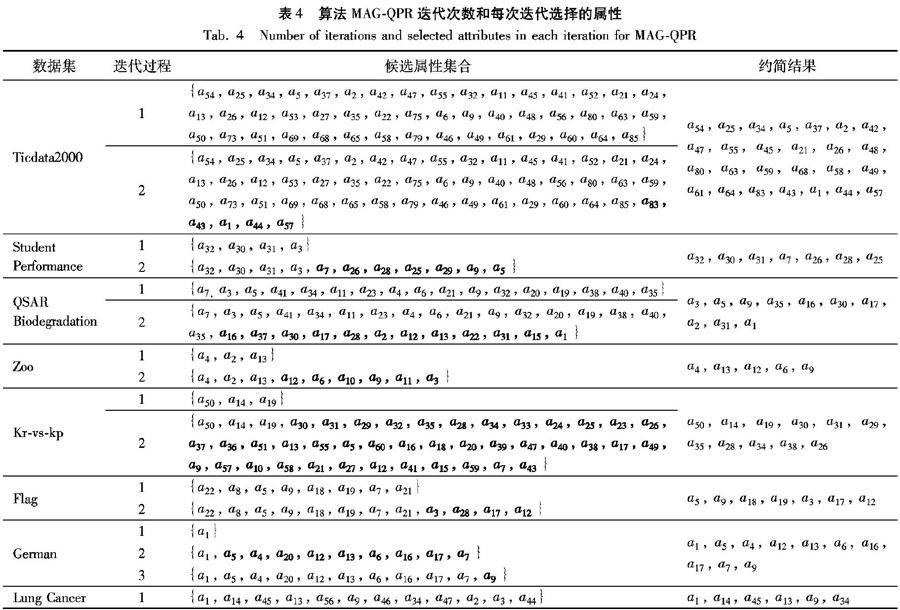
表4给出了MAG-QPR在不同UCI数据集上迭代次数和每次迭代添加属性的相关情况,采用ai∈|C|表示決策表中的条件属性。整体上,采用MAG-QPR,8组数据集的属性约简迭代次数均比较少,最大的是数据集German,迭代次数也仅为3次。迭代次数的减少会明显提高算法的运行效率。
表4中,用粗体表示本次迭代选择的属性。例如,对于数据集Student Performance, 整个算法共迭代了2次,第一次迭代的属性集合为:{a32, a30, a31, a3},第二次迭代添加的属性集合为:{ a7, a26, a28, a25, a29, a9, a5}。因此,整个算法迭代过程结束以后,得到的属性集合为:{a32, a30, a31, a3, a7, a26, a28, a25, a29, a9, a5}。删除冗余的条件属性后,得到的正域约简结果为:a32, a30, a31, a7, a26, a28, a25 。
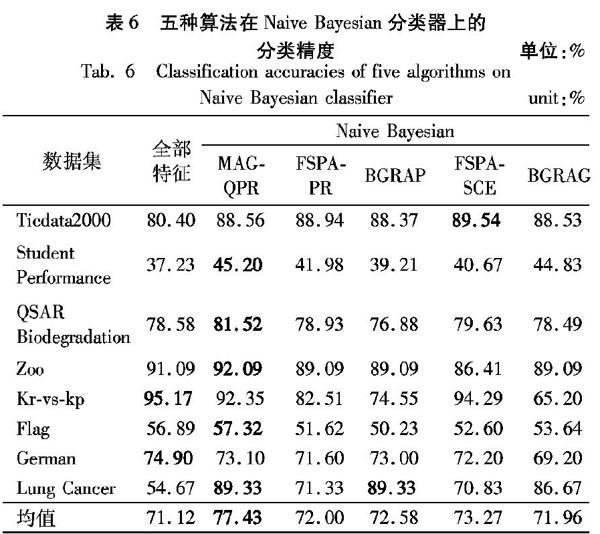
表5~6给出了采用五种算法得到的约简结果在KNN和Naive Bayesian两种分类器的分类精度对比,这里的分类精度实验采用十折交叉验证(10-fold cross validation)的方法。同一数据集中,用粗体表示分类精度最高值。在表5中,采用MAG-QPR的约简结果在4组数据集上的分类精度优于其他四种算法与原始系统的分类精度。在表6中,采用MAG-QPR的约简结果也在5组数据集上的分类精度优于其他四种个算法与原始分类精度。综上可知,MAG-QPR在两种分类器上的分类精度均值均优于其他四种算法的分类精度。
4结语
相较于差别矩阵正域约简算法,启发式正域约简算法具有较高的运行效率。但是面对大规模数据集,传统启发式正域约简算法需要在每次迭代的过程中添加当前重要度(正域依赖度)最大的属性进候选属性子集,效率低且算法迭代次数多,难以应用于大规模数据集的特征选择中。考虑到这种情况,本文设计了一种快速的正域属性约简算法——MAG-QPR。
该算法有如下四点优势:
1)MAG-QPR在每次迭代添加的属性集形成的正域大于经典正域算法中每次添加的单个属性形成的正域;
2)MAG-QPR不需要从核属性开始,直接进行迭代运算;
3)MAG-QPR每次迭代的添加以属性集作为基本单位,提高了迭代的效率,促使算法总的迭代次数较少;
4)在每次迭代中,删除部分对象集(粗粒度下的正域),从而使得计算空间变小,提高算法效率。
将本文的算法MAG-QPR与四种启发式算法(FSPA-PR、BGRAP、FSPA-SCE与BGRAG)进行比较,实验结果表明:
1)相较其他四种算法,MAG-QPR在选择的8组UCI数据集上的算法效率具有明显优势;
2)采用属性粒作为每次迭代添加的基本单位,可以有效地减少迭代次数,提高了算法效率;
3) 随着数据规模(论域规模或对象数目)的增多,MAG-QPR相较于其他四种算法具有明显的效率优势;
4) MAG-QPR在两种分类器上的分类精度的表现总体上好于其他四种算法的分类精度。
在今后的研究工作中,将在算法MAG-QPR中去除冗余属性效率和其他约简目标下的多尺度属性粒的快速约简方面继续进行深入的研究。
参考文献 (References)
[1]PAWLAK Z. Rough sets [J]. International Journal of Computer and Information Sciences, 1982, 11(5): 341-356.
[2]王国胤,姚一豫,于洪.粗糙集理论与应用研究综述[J].计算机学报,2009,32(7):1229-1246.(WANG G Y, YAO Y Y, YU H. A survey on rough set theory and applications [J]. Chinese Journal of Computers, 2009, 32(7): 1229- 1246.)
[3]MIAO D, ZHAO Y, YAO Y, et al. Relative reducts in consistent and inconsistent decision tables of the Pawlak rough set model [J]. Information Sciences, 2009, 179(24): 4140-4150.
[4]LI H, LI D, ZHAI Y, et al. A novel attribute reduction approach for multi-label data based on rough set theory [J]. Information Sciences, 2016, 367/368: 827-847.
[5]YAO Y, ZHAO Y. Attribute reduction in decision-theoretic rough set models [J]. Information Sciences, 2008, 178(17): 3356-3373.
[6]JIA X, SHANG L, ZHOU B, et al. Generalized attribute reduct in rough set theory [J]. Knowledge-Based Systems, 2016, 91(6): 204-218.
[7]张楠,苗夺谦,岳晓冬.区间值信息系统的知识约简[J].计算机研究与发展,2010,47(8):1362-1371.(ZHANG N, MIAO D Q, YUE X D. Approaches to knowledge reduction in interval-valued information systems [J]. Journal of Computer Research and Development, 2010, 47(8): 1362-1371.)
[8]HU Q, ZHAO H, XIE Z, et al. Consistency based attribute reduction [C]// Proceedings of the 2007 Pacific-Asia Conference on Knowledge Discovery and Data Mining, LNCS 4426. Berlin: Springer, 2007: 96-107.
[9]GUAN Y Y, WANG H K. Set-valued information systems[J]. Information Sciences. 2006, 176(17): 2507-25-25.
[10]SKOWRON A, RAUSZER C. The discernibility matrices and functions in information systems [M]// SOWINSKI R. Intelligent Decision Support: Handbook of Applications and Advances to Rough Sets Theory. Dordrecht: Kluwer Academic Publishers, 1992: 331-362.
[11]徐章艷,刘作鹏,杨炳儒,等.一个复杂度为max(O(|C||U|), O(|C|2|U/C|))的快速属性约简算法[J].计算机学报,2006,29(3):391-399.(XU Z Y, LIU Z P, YANG B R, et al. A quick attribute reduction algorithm with complexity of max(O(|C||U|), O(|C|2|U/C|)) [J]. Chinese Journal of Computers, 2006, 29(3): 391-399.)
[12]QIAN Y, LIANG J, PEDRYCZ W, et al. Positive approximation: an accelerator for attribute reduction in rough set theory [J]. Artificial Intelligence, 2010, 174(9/10): 597-618.
[13]LIANG J, MI J, WEI W, et al. An accelerator for attribute reduction based on perspective of objects and attributes [J]. Knowledge-Based Systems, 2013, 44: 90-100.
[14]葛浩,李龍澍,杨传健.基于冲突域的高效属性约简算法[J].计算机学报,2012,35(2):342-350.(GE H, LI L S, YANG C J. An efficient attribute reduction algorithm based on conflict region [J]. Chinese Journal of Computers, 2012, 35(2): 342-350.)
[15]王熙照,王婷婷,翟俊海.基于样例选取的属性约简算法[J].计算机研究与发展,2012,49(11):2305-2310.(WANG X Z, WANG T T, ZHAI J H. An attribute reduction algorithm based on instance selection [J]. Journal of Computer Research and Development, 2012, 49(11): 2305-2310.)
[16]杨习贝,颜旭,徐苏平,等.基于样本选择的启发式属性约简方法研究[J].计算机科学,2016,43(1):40-43.(YANG X B, YAN X, XU S P, et al. New heuristic attribute reduction algorithm based on sample selection [J]. Computer Science, 2016, 43(1): 40-43.)
[17]CHEN H, LI T, RUAN D, et al. A rough-set-based incremental approach for updating approximations under dynamic maintenance environments [J]. IEEE Transactions on Knowledge and Data Engineering, 2013, 25(2): 274-284.
[18]CHEN H, LI T R, LUO C, et al. A rough set-based method for updating decision rules on attribute values coarsening and refining [J]. IEEE Transactions on Knowledge and Data Engineering, 2014, 26(12): 2886-2899.
[19]TENG S, LU M, YANG A, et al. Efficient attribute reduction from the viewpoint of discernibility [J]. Information Sciences, 2016, 326: 297-314.
[20]SHU W, QIAN W. A fast approach to attribute reduction from perspective of attribute measures in incomplete decision systems [J]. Knowledge-Based Systems, 2014, 72: 60-71.
[21]RAZA M S, QAMAR U. Feature selection using rough set-based direct dependency calculation by avoiding the positive region [J]. International Journal of Approximate Reasoning, 2018, 92: 175-197.
[22]苗夺谦,李道国.粗糙集理论、算法与应用[M].北京:清华大学出版社,2008:87-214.(MIAO D Q, LI D G. Rough Sets Theory Algorithms and Applications [M]. Beijing: Tsinghua University Press, 2008: 87-214.)
[23]JING Y G, LI T, HUANG J, et al. A group incremental reduction algorithm with varying data values [J]. International Journal of Intelligent Systems, 2017, 32(9): 900-925.
[24]JING Y, LI T, FUJITA H, et al. An incremental attribute reduction method for dynamic data mining [J]. Information Sciences, 2018, 465: 202-218.
