基于多尺度多列卷积神经网络的密集人群计数模型
2019-01-06陆金刚张莉
陆金刚 张莉


摘要:針对尺度和视角变化导致的监控视频和图像中的人数估计性能差的问题,提出了一种基于多尺度多列卷积神经网络(MsMCNN)的密集人群计数模型。在使用MsMCNN进行特征提取之前,使用高斯滤波器对数据集进行处理得到图像的真实密度图,并且对数据集进行数据增强。MsMCNN以多列卷积神经网络的结构为主干,首先从具有多尺度的多个列中提取特征图;然后,用MsMCNN在同一列上连接具有相同分辨率的特征图,以生成图像的估计密度图;最后,对估计密度图进行积分来完成人群计数的任务。为了验证所提模型的有效性,在Shanghaitech数据集和UCF_CC_50数据集上进行了实验,与经典模型Crowdnet、多列卷积神经网络(MCNN)、级联多任务学习(CMTL)方法、尺度自适应卷积神经网络(SaCNN)相比,所提模型在Shanghaitech数据集Part_A和UCF_CC_50数据集上平均绝对误差(MAE)分别至少减小了10.6和24.5,均方误差(MSE)分别至少减小了1.8和29.3;在Shanghaitech数据集Part_B上也取得了较好的结果。MsMCNN更注重特征提取过程中的浅层特征的结合以及多尺度特征的结合,可以有效减少尺度和视角变化带来的精确度偏低的影响,提升人群计数的性能。
关键词:密集人群计数;密度图;卷积神经网络;多尺度;尺度和视角变化
中图分类号: TP311;TP391.4文献标志码:A
Crowd counting model based on multi-scale multi-column convolutional neural network
LU Jingang1, ZHANG Li1,2*
(1. School of Computer Science and Technology, Soochow University, Suzhou Jiangsu 215006, China;
2. Jiangsu Provincial Key Laboratory for Computer Information Processing Technology (Soochow University), Suzhou Jiangsu 215006, China)
Abstract: To improve the bad performance of crowd counting in surveillance videos and images caused by the scale and perspective variation, a crowd counting model, named Multi-scale Multi-column Convolutional Neural Network (MsMCNN) was proposed. Before extracting features with MsMCNN, the dataset was processed with the Gaussian filter to obtain the true density maps of images, and the data augmentation was performed. With the structure of multi-column convolutional neural network as the backbone, MsMCNN firstly extracted feature maps from multiple columns with multiple scales. Then, MsMCNN was used to generate the estimated density map by combining feature maps with the same resolution in the same column. Finally, crowd counting was realized by integrating the estimated density map. To verify the effectiveness of the proposed model, experiments were conducted on Shanghaitech and UCF_CC_50 datasets. Compared to the classic methods: Crowdnet, Multi-column Convolutional Neural Network (MCNN), Cascaded Multi-Task Learning (CMTL) and Scale-adaptive Convolutional Neural Network (SaCNN), the Mean Absolute Error (MAE) of MsMCNN respectively decreases 10.6 and 24.5 at least on Part_A and UCF_CC_50 of Shanghaitech dataset, and the Mean Squared Error (MSE) of MsMCNN respectively decreases 1.8 and 29.3 at least. Furthermore, MsMCNN also achieves the better result on the Part_B of the Shanghaitech dataset. MsMCNN pays more attention to the combination of shallow features and the combination of multi-scale features in the feature extraction process, which can effectively reduce the impact of low accuracy caused by scale and perspective variation, and improve the performance of crowd counting.
Key words: crowd counting; density map; Convolutional Neural Network (CNN); multi-scale; perspective and scale variation
0引言
近年来,国内外发生了多起重大的人群踩踏事故,造成了众多人员的伤亡。此外,由于诸如视频监控、公共安全设计和交通监控等实际应用的需求,准确地对视频图像中的人群进行人数估计引起了人们的极大关注[1]。人群计数任务面临着许多挑战,究其原因是图像中的人群存在严重遮挡、分布密集、视角失真以及尺度显著变化等问题。
早期的人群计数方法是基于检测或者回归的。基于检测的方法把人群看作是一组被检测的个体实体,通常采用基于滑动窗口的检测算法来计算图像中对象实例的数量[2-6]。虽然基于检测的方法在人群计数上有一定的效果,但在估计有严重遮挡和背景杂乱的图像时,该类方法会受到严重影响。相关研究中,基于回归的方法被提出来应用于解决人群计数问题。基于回归的方法通常学习一种从特征到人数[1,7-10]或者密度图[11-13]的映射关系。然而,基于回归的方法会受到尺度和视角急剧变化的影响,导致基于回归的方法的准确度很难进一步提升,而这些变化在图像中是普遍存在的。
近年来,因为卷积神经网络(Convolutional Neural Network, CNN)已经在各种计算机视觉任务中取得了成功,所以基于CNN的方法相继被提出并用于人群计数任务[14-21]。Zhang等[14]利用深度卷积神经网络来估计不同场景的人群计数。该模型在训练场景和测试场景上都需要生成视角图,并且利用视角图来训练和微调。尽管这个模型在大多数公开数据集上取得了比较好的效果,但是在人群计数的实际应用中很难生成视角图。Boominathan等[15]提出了Crowdnet模型,该模型通过结合浅层网络和深层网络来解决图像的尺度变化问题。之后,Zhang等[16]注意到已有方法固定了感受野,只适合提取单一尺度的特征,所以提出了多列卷积神经网络(Multi-column CNN, MCNN)来提取图像在不同尺度下的特征。在此基礎上,Sindagi等[17]提出了一种端到端的级联多任务学习(Cascaded Multi-task Learning, CMTL)方法,该网络同时学习人群计数的分类和密度图的估计。Zhang等[18]随后提出了尺度自适应卷积神经网络(Scale-adaptive CNN, SaCNN),该网络结合了从多个层提取的多尺度特征图。
虽然以上几种经典方法都取得了不错的计数效果,但是都不能很全面地解决人群图像中存在的尺度和视角变化导致的误差较大的问题。因此,为了进一步提高计数效果,本文在MCNN和SaCNN的基础上提出了多尺度多列卷积神经网络(Multi-scale Multi-column CNN, MsMCNN ),适用于任意图像的人群计数。在MsMCNN中,输入为单张图像,输出为图像对应的密度图,对密度图积分就可以获得人数的估计。在Shanghaitech数据集和UCF_CC_50数据集上进行实验,实验结果表明,本文提出的MsMCNN相较于大多数现有的人群计数方法有更好的计数能力。本文的主要工作如下:
1)设计了一种新的网络模型MsMCNN用于人群计数。和MCNN相比,MsMCNN模型深度更深,每列有更多的卷积层,能提取更多的细节特征。
2)MsMCNN在每列中引入了多尺度,并通过结合不同层的特征来适应图像中人头或者人的尺度和视角的变化,使得这些层可以共享相同的低层特征图。
3)为了方便结合不同层的特征图,MsMCNN在MCNN的基础上增加了一个反卷积层和一个核大小为3×3、步长为1的最大池化层,其目的是使得要连接的特征图具有相同的分辨率。
1本文模型MsMCNN
受到MCNN和SaCNN的启发,本文提出了一种新的多尺度多列卷积神经网络模型MsMCNN,用来学习图像的密度图,以此来估计图像中的人数。在本节中,将详细介绍MsMCNN模型的网络结构,并讨论训练的实现细节。1.1网络结构
MsMCNN模型以MCNN模型为主干网络,同时引入了SaCNN模型中多尺度连接的概念。和MCNN模型类似,MsMCNN也由三组并行的子卷积神经网络组成,其中每组子网络除了卷积核的大小和个数不同外其他的结构都相同。在CNN模型中,池化操作虽然能对特征图进行压缩并降低网络计算复杂度,但是也会导致特征的丢失。受到SaCNN模型的启发,在每组子网络中,对不同层的特征图进行多尺度连接,以此来自适应图像中的尺度和视角变化。经连接后的特征图具有多尺度特征的特点,包括低级特征和高级特征,分别对应小尺度和大尺度的人头或人。
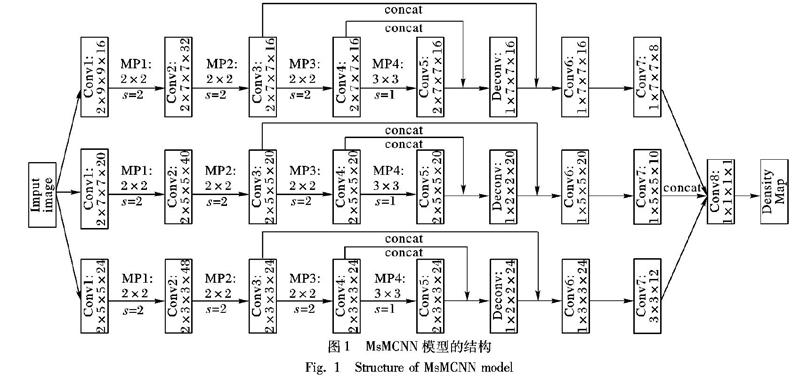
MsMCNN的整体结构如图1所示。
正如在图1中能看到的,每组子网络共有12个卷积层、1个反卷积层、4个最大池化层以及2个多尺度连接。结合图1,下面对子网络中的组成分量进行简要介绍:
1)多尺度连接。在图1中concat表示多尺度连接。多尺度连接将不同卷积层输出的相同分辨率的特征图在通道数上连接起来。这样做的目的是能够共享相同的低层次参数和特征图,进而可以减少参数的数量和训练数据,并且可以加速训练过程。
2)卷积层。在图1中Conv表示卷积层,参数p1×p2×p3×p4中p1表示卷积层个数,p2×p3表示卷积核大小,p4表示卷积核通道数。
3)最大池化层。在图1中MP表示最大池化层,池化区域大小为p5×p6。除了最大池化层MP4以外,其他最大池化层的池化区域大小都定义为2×2且步长为2。为了能将Conv4和Conv5输出的特征图多尺度连接起来,本文方法设定MP4的池化区域大小为3×3及步长为1。
4)反卷积层。在图1中Deconv表示反卷积层,其参数形式和卷积层相似。本文方法使用一个反卷积层将Conv4和Conv5进行多尺度连接后的特征图上采样到输入图像分辨率的1/4。因此,可以进一步将Deconv输出的特征图和Conv3输出的特征图进行多尺度连接。
本文方法把三组子卷积神经网络在Conv7上输出的特征图连接起来,并且经Conv8将连接之后的特征图生成估计密度图。在Conv8上,使用一个卷积核大小为1×1且通道数为1的卷积层。因为最后输出的估计密度图的分辨率是输入图像的1/4,所以为了计算网络损失,将真实的密度图下采样到输入图像的1/4。在整个网络中,采用线性整流函数ReLU(Rectified Linear Unit)作为激活函数。如上所述,MsMCNN是在MCNN和SaCNN的基础上提出的,这样可以同时继承两者的优点。和MCNN相比,MsMCNN有更多的卷积层和池化层来提取更细节的特征,而且引入了MCNN没有的多尺度和反卷积的概念。和SaCNN相比,MsMCNN有更多列(这些列有不同大小的卷积核,对应着不同尺度的人头),同时减少了VGG16中不重要的层。这些不同之处使得MsMCNN对尺度和视角的显著变化更加具有鲁棒性。
1.2训练和实施细节
1.2.1真实密度图
假设训练集为{(Xk,Zk)}Nk=1,这里Xk表示第k张图像,Zk表示图像Xk的真实人头标注图像,N表示训练图像的总数。要想直接训练从Xk到Zk的映射关系是比较困难的,所以研究者们偏向于使用真实密度图而不是真实人头标注图像。本文采用比较成熟的真实密度图生成方法,详见文献[16]。
令D是(X,Z)的真实密度图。对于给定的(X,Z),假设图像Z的坐标点(xi,yi)处有一个人头,或者Z(xi,yi)=1,用δ函数来表示:
δ(x-xi,y-yi)=1,x=xi∧y=yi
0,其他(1)
真实密度图D在坐标点(x,y)处的值可以通过将该δ函数和一个高斯滤波器进行卷积计算而得:
D(x,y)=∑Mi=1δ(x-xi,y-yi)Gσ(x,y)(2)
其中:M表示图像X中的人头总数;Gσ(x,y)是元素总和为1的高斯滤波器,σ>0是高斯滤波器的参数,σ的设置可以参考文獻[15-16]。密度图D中元素总和等于图像中的人头总数:
M=∑x∑yD(x,y)(3)
在图2中,展示了两张Shanghaitech数据集上的图像及其对应的密度图。现在,通过这样处理后,可以令新的训练集为{(Xk,Dk)}Nk=1。
1.2.2网络损失
在训练阶段,MsMCNN采用平方损失来衡量估计密度图和真实密度图之间的距离。平方损失函数定义如下:
L(Θ)=12N∑Nk=1‖D^k(Θ)-Dk‖22(4)
其中:Θ表示MsMCNN要学习的参数集;D^k(Θ)表示图像Xk的估计密度图;Dk表示图像Xk的真实密度图;L(Θ)表示估计密度图和真实密度图之间的损失。L(Θ)和D^k(Θ)都是与Θ参数集相关的函数。
对于一张未见过的图像X,通过如下方法估计它的人数:
M^=∑x∑yD^(x,y)(5)
2实验与结果分析
为了验证MsMCNN的效果,在Shanghaitech和UCF_CC_50数据集上对它进行评估。这里选择四种方法用于比较:Crowdnet[15]、MCNN[16]、CMTL[17]以及SaCNN[18]。所有的实验均在Ubuntu系统下,以Python 2.7在Pytorch框架下,在GPU上进行。在本文方法的实施中,采用随机梯度下降(Stochastic Gradient Descent, SGD)优化器来训练MsMCNN。另外,经验表明,将学习率设为10-5且动量设为0.9比较适合训练。实验结果均为在相同的实验参数设置和训练集数据增强下的复现结果。
2.1数据集
Shanghaitech和UCF_CC_50数据集是两个典型的用于人群计数的数据集,其基本情况见表1,详细描述如下:
1)Shanghaitech数据集是由Zhang等 [16]提出的一个大规模人群计数数据集。该数据集包含1198张标注图像,总共有330165个标注人头。该数据集包括两部分:Part_A和Part_B。Part_A包含从网上随机获取的482张图像,被分成300张训练集和182张测试集;Part_B包括716张来自上海繁华街头的图像,也被分为训练集和测试集,其中400张用于训练,316张用于测试。
2)UCF_CC_50数据集是由Idrees等 [9]提出,只有50张图像,总共有63974个人头标注,每张图像的人头数从94到4543不等。因为该数据集规模小,人群密度跨度大,所以该数据集是极富挑战性的。参考文献[9],进行5倍交叉验证来得到平均测试效果。
2.2评估准则
和已有的人群计数工作一样,采用平均绝对误差(Mean Absolute Error, MAE)和均方误差(Mean Squared Error, MSE)来评估不同的方法,MAE和MSE的定义如下:
MAE=1N′∑N′i=1Mi-M^i(6)
MSE=1N′∑N′i=1(Mi-M^i)2(7)
其中:N′表示测试图像数;Mi表示第i张测试图像中的实际人数;M^i表示第i张测试图像的估计人数。一般来说,MAE评估估计的准确性,MSE评估估计的鲁棒性。
2.3Shanghaitech数据集上的实验结果
为了增强训练集来训练MsMCNN,在每张原始训练图像上不同位置裁剪9张图像,每张小图像是原始训练图像的1/4。这样,Part_A和Part_B分别有2700张图像和3600张图像来训练MsMCNN。使用式(2)来生成图像的真实密度图,根据经验σ=4。图3(a)和图3(b)分别展示了在Part_A和Part_B上单张测试图像的真实密度图和估计密度图,并和SaCNN的估计密度图进行了对比。可以看到估计密度图能在一定程度上反映真实密度图。
將MsMCNN和四种已有方法进行对比,结果如表2所示。
由表2可以看出,本文方法在Part_A上取得了最好的MAE(即89.1)和最好的MSE(即142.8)。与排在第二的SaCNN方法相比,MsMCNN在MAE和MSE上分别减少了10.6和1.8。此外,本文方法在Part_B上也取得了不错的结果,为20.3和37.2。和最好的CMTL方法相比,MsMCNN在MAE和MSE上分别只差了3.2和7.9。
分析在Part_B上未能达到最好的原因:Part_B中的图像来源于街道,人群密度相对较小且干扰背景比较多。
2.4UCF_CC_50数据集上的实验结果
和Shanghaitech数据集类似,在UCF_CC_50数据集上进行了数据增强。在每次实验中,原始训练图像被随机裁剪成25张图像,每张大小为原始图像的1/4。这样,共有1000张图像用于训练,10个原始图像用于测试。图3(c)展示了UCF_CC_50数据集上两张测试图像的真实密度图和其估计密度图,并和SaCNN得到的估计密度图进行了对比。
实验执行五倍交叉验证,取其平均值,并将本文方法和四种经典方法进行了比较。实验结果如表3所示,MsMCNN在MAE和MSE上取得了最好的效果,分别为383.5和513.0,相比经典的方法,MsMCNN取得了显著提高,且和第二好的SaCNN相比,MsMCNN的MAE和MSE分别减少了24.5和29.3。
3结语
本文提出了多尺度多列卷积神经网络(MsMCNN)模型,该模型在MCNN模型基础上引入了多尺度连接,对图像中尺度和视角的变化不是很敏感,能较为准确地估计图像中的人数。在两个常见的人群数据集上进行实验,结果表明本文的方法MsMCNN在Shanghaitech数据集的Part_A和UCF_CC_50数据集上均优于对比的方法,充分验证了该方法对尺度和视角变化的稳定性。尽管如此,MsMCNN也有进一步提升的空间。该方法在Shanghaitech数据集的Part_B上的性能弱于CMTL和SaCNN,主要原因是MCNN对复杂背景的图像较为敏感,导致了以其为主干网络的MsMCNN也具有此缺点。虽然引入多尺度连接在一定程度上缓解了此问题,但解决得并不彻底。在下一步工作中,考虑对图像进行前景分割,以消除复杂背景对人群计数的影响。
参考文献 (References)
[1]CHAN A B, LIANG Z S J, VASCONCELOS N. Privacy preserving crowd monitoring: counting people without people models or tracking [C]// Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2008: 1-7.
[2]WANG M, WANG X. Automatic adaptation of a generic pedestrian detector to a specific traffic scene [C]// Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2011: 3401-3408.
[3]WU B, NEVATIA R. Detection of multiple, partially occluded humans in a single image by Bayesian combination of edgelet part detectors [C]// Proceedings of the 2005 10th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2005: 90-97.
[4]STEWART R, ANDRILUKA M, NG A Y. End-to-end people detection in crowded scenes [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 2325-2333.
[5]TOPKAYA I S, ERDOGAN H, PORIKLI F. Counting people by clustering person detector outputs [C]// Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway: IEEE, 2014: 313-318.
[6]LEIBE B, SEEMANN E, SCHIELE B. Pedestrian detection in crowded scenes [C]// Proceedings of the 2005 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2005: 878-885.
[7]CHAN A B, VASCONCELOS N. Bayesian poisson regression for crowd counting [C]// Proceedings of the 2009 12th IEEE International Conference on Computer Vision. Piscataway: IEEE, 2009: 545-551.
[8]RYAN D, DENMAN S, FOOKES C. Crowd counting using multiple local features [C]// Proceedings of the 2009 Digital Image Computing: Techniques and Applications. Piscataway: IEEE, 2009: 81-88.
[9]IDREES H, SALEEMI I, SEIBERT C, et al. Multi-source multi-scale counting in extremely dense crowd images [C]// Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2013: 2547-2554.
[10]LIU B, VASCONCELOS N. Bayesian model adaptation for crowd counts [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 4175-4183.
[11]LEMPITSKY V, ZISSERMAN A. Learning to count objects in images [C]// Proceedings of the 2010 24th Annual Conference on Neural Information Processing Systems. New York: Curran Associates, 2010: 1324-1332.
[12]CHEN K, LOY C C, GONG S, et al. Feature mining for localised crowd counting [C]// Proceedings of the 2012 British Machine Vision Conference. Durham: BMVA Press, 2012: 1-11.
[13]KONG D, GRAY D, TAO H. Counting pedestrians in crowds using viewpoint invariant training [C]// Proceedings of the 2005 British Machine Vision Conference. Durham: BMVA Press, 2005: 1-10.
[14]ZHANG C, LI H, WANG X, et al. Cross-scene crowd counting via deep convolutional neural networks [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 833-841.
[15]BOOMINATHAN L, KRUTHIVENTI S S, BABU R V. Crowdnet: a deep convolutional network for dense crowd counting [C]// Proceedings of the 24th ACM International Conference on Multimedia. New York: ACM, 2016: 640-644.
[16]ZHANG Y, ZHOU D, CHEN S, et al. Single-image crowd counting via multi-column convolutional neural network [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 589-597.
[17]SINDAGI V A, PATEL V M. CNN-based cascaded multi-task learning of high-level prior and density estimation for crowd counting [C]// Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway: IEEE, 2017: 1-6.
[18]ZHANG L, SHI M, CHEN Q. Crowd counting via scale-adaptive convolutional neural network [C]// Proceedings of the 2018 IEEE International Conference on Advanced Video and Signal Based Surveillance. Piscataway: IEEE, 2018: 1113-1121.
[19]郭繼昌,李翔鹏.基于卷积神经网络和密度分布特征的人数统计方法[J].电子科技大学学报,2018,47(6):806-813.(GUO J C, LI X P. A crowd counting method based on convolutional neural networks and density distribution features [J]. Journal of University of Electronic Science and Technology of China, 2018, 47(6): 806-813.)
[20]唐清,王知衍,严和平.基于模糊神经网络的大场景人群密度估计方法[J].计算机应用研究,2010,27(3):989-991,1008.(TANG Q, WANG Z Y, YAN H P. Crowd density estimation of wide scene based on fuzzy neural network [J]. Application Research of Computers, 2010, 27(3): 989-991, 1008.)
[21]谭智勇,袁家政,刘宏哲.基于深度卷积神经网络的人群密度估计方法[J].计算机应用与软件,2017,34(7):130-136.(TAN Z Y, YUAN J Z, LIU H Z. Crowd density estimation method based on deep convolutional neural networks [J]. Computer Applications and Software, 2017, 34(7): 130-136.)
The work is partially supported by the Six Talent Peak Project of Jiangsu Province (XYDXX-054).
LU Jingang, born in 1993, M. S. candidate. His research interests include crowd counting, deep learning, machine learning.
ZHANG Li, born in 1975, Ph. D., professor. Her research interests include machine learning, pattern recognition.
收稿日期:2019-04-29;修回日期:2019-08-14;錄用日期:2019-08-16
基金项目:江苏省“六大人才高峰”高层次人才项目(XYDXX-054)。
作者简介:陆金刚(1993—),男,江苏南通人,硕士研究生 ,主要研究方向:密集人群计数、深度学习、机器学习;张莉(1975—),女,江苏张家港人,教授,博士,CCF会员,主要研究方向:机器学习、模式识别。
文章编号:1001-9081(2019)12-3445-05DOI:10.11772/j.issn.1001-9081.2019081437
