高铁运营安全监督系统奖惩机制优化研究
2018-10-29李科宏张亚东
李科宏,张亚东,郭 进
(西南交通大学信息科学与技术学院,成都610031)
0 引 言
目前,我国高速铁路已经由大规模建设阶段逐步向稳定运营阶段转化,因此,国家铁路局和铁路总公司制定和出台了各项安全规章来对高铁运营过程进行安全管理.高铁运营安全监管制度是保证各项规章贯彻实施的关键,有必要建立完善的监管奖惩机制以控制系统中各相关方的违规行为.在委托运输管理模式[1]下,有关高铁运营安全监督系统奖惩机制存在问题的研究大多为定性分析.陈茂莹[2]认为应该完善针对委托路局的奖惩考核机制以确保其完成经营目标.韩世通[3]认为应当修订和完善激励约束机制以加强高铁委托运输管理.姬志洲等[4]使用博弈论研究铁路企业与监管部门之间存在的行为以提高监管效率.在其他领域,张弓亮等[5]使用演化博弈论对高速公路共谋逃费行为进行了分析,认为增强对监管者的监管和处罚力度等措施可以有效遏制共谋逃费现象.蔡玲如[6]使用演化博弈论对环境污染的治理问题进行了研究,认为将惩罚力度与被监督检查方的违规率相联系有助于抑制博弈过程的波动.贾璐[7]使用演化博弈论对工程安全监管过程中的相关方进行分析,提出了制定惩罚策略的建议.李振龙等[8]使用演化博弈论建立了超速驾驶行为的博弈模型,提出通过奖惩措施来规范交通管理者和超速驾驶员的行为.朱庆华等[9]使用演化博弈论分析了碳减排政策下地方政府与制造企业双方的博弈关系,并引入政府动态补偿策略,剖析政企双方策略的互动机制.
之前的工作中[10],我们通过分析高铁运营安全监督系统现状,建立了高铁公司、国家铁路局和委托路局三方组成的系统静态演化博弈模型.通过演化博弈理论证明结合系统动力学(SD)仿真,得到了系统各方在博弈过程中产生利益冲突的长期动态波动特征并验证了该模型不存在演化稳定策略均衡(ESS).本文通过对静态模型进行优化,分别提出动态奖励,动态奖惩和优化动态奖惩模型,最终通过优化动态奖惩模型使系统演化博弈的波动趋势得到有效抑制并达到最优,为提高高铁安全监督的效果提供了理论支持.
1 高铁运营安全监督系统动态奖励演化博弈模型分析
1.1 动态奖励模型描述及建立
假设国家铁路局以比率X对委托路局的安全生产状况进行监管,X=0和1分别表示不监管和实时监管.假设国家铁路局对委托路局进行监管的支付成本为CS.如果国家铁路局不进行监管,则委托路局可能违反高铁委托运输协议及安全规章,导致事故发生率上升,其将承担后期的资产和声誉损失成本为Ls;如果国家铁路局对委托路局和高铁公司进行监管,发现他们存在违规行为将分别对其进行处罚PR和PE.假设委托路局按照国家铁路局的相关规章和与高铁公司签订的委托协议进行安全投入,安全投入率为Y,其正常生产所获得的收益为πR,而违反协议进行违规操作时,将获得收益CR(即节约的安全投入成本),同时承担高铁事故率上升的期望损失成本WR.假设高铁公司以比率Z对委托路局进行安全监督,高铁公司严格监督的成本为CE,但在严格监督的情况下可能由于监督人员素质等原因出现监督失误,失误率为RE;假定高铁公司安全监督获取的正常收入为πE,而不监督时,将承担后期的期望损失成本LE.
由于之前建立的静态演化博弈模型并不存在ESS,为了抑制系统各方在博弈过程中产生的波动性,国家铁路局可以根据安全监管的结果,使用动态奖励机制对委托路局和高铁公司进行奖励[9].假设对委托路局的奖励与其安全投入率成正比,对高铁公司的奖励与其履行监督职责的比率成正比,即B′R=αYBR,B′E=βZBE,其中,BR,BE分别为国家铁路局对委托路局和高铁公司的一般性奖励,α,β分别为奖励系数(初始都为1).则使用动态奖励策略,国家铁路局,高铁公司与委托路局博弈三方的收益矩阵如表1所示.
1.2 动态奖励模型三方复制动态系统
根据演化博弈理论,结合表1可得动态奖励场景下,高铁运营安全监督系统博弈演化的复制动态方程组为
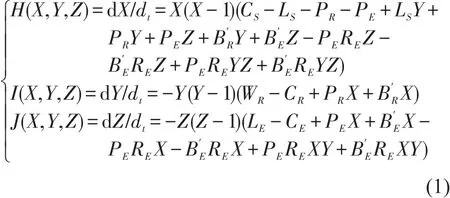
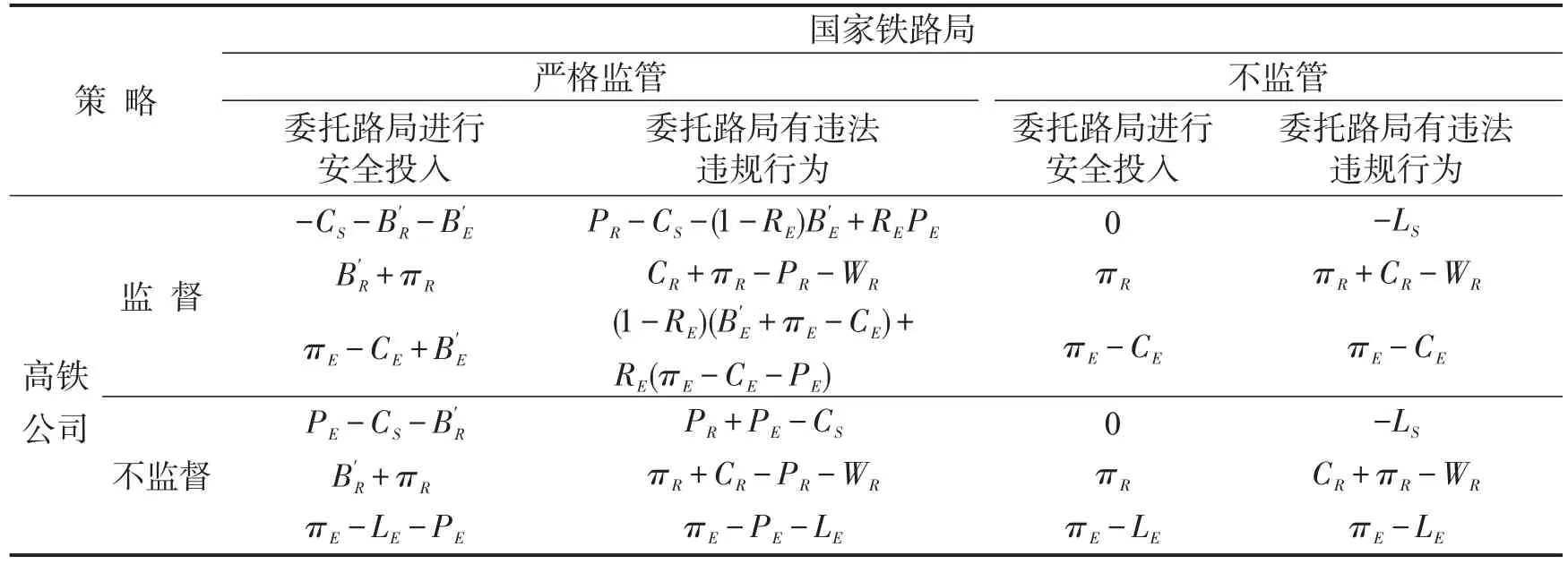
表1 国家铁路局、委托路局和高铁公司的收益矩阵Table 1 Payoff matrix of the regulatory agencies,commissioned railway bureau and high-speed railway company
由式(1)可得博弈系统的雅可比矩阵为
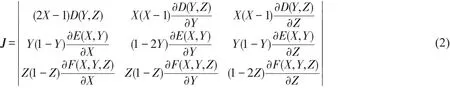
其中,
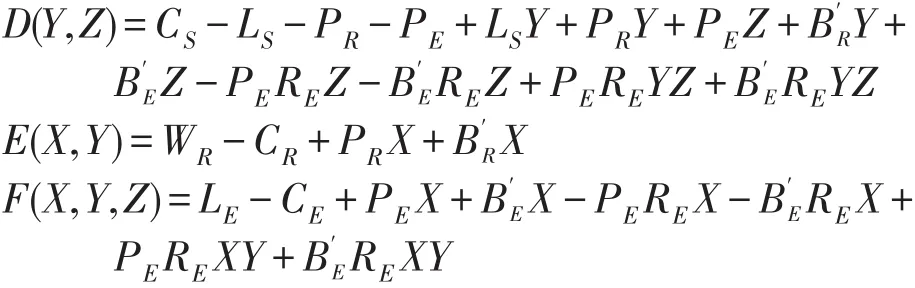
由于模型的表达式比较复杂,为了方便求解分析,首先对相关变量进行赋值解得各个均衡点,然后通过理论推导和SD仿真分析博弈模型各个均衡点的稳定性.通过文献[9]并结合领域内专家经验,得到模型中各参数设置如表2所示.
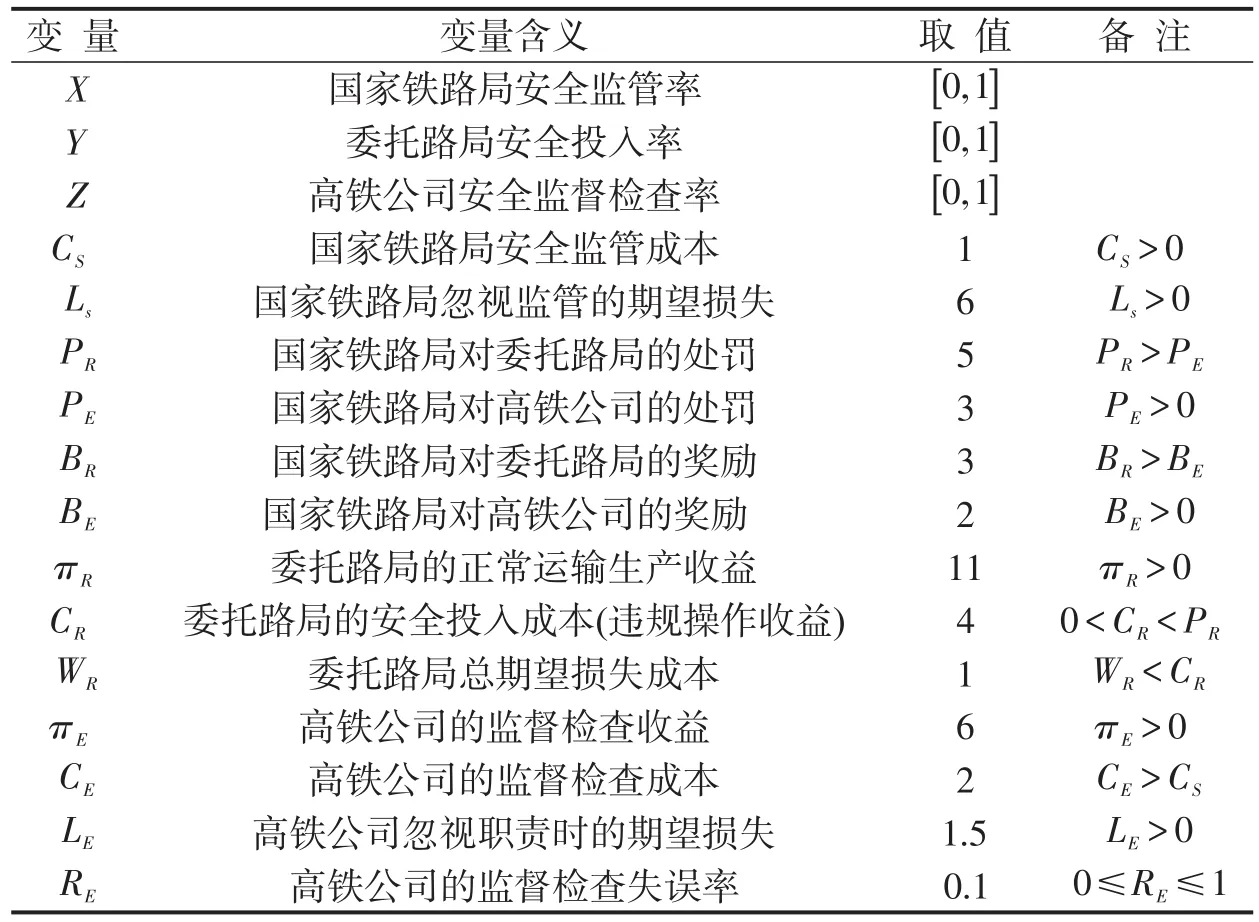
表2 仿真参数设置Table 2 Simulation parameter setting
1.3 动态奖励模型求解及稳定性证明
Friedman提出通过分析系统在均衡点时雅可比矩阵(Jacobian)行列式和特征值的方法来得到系统复制动态方程均衡点的稳定性[11-12].根据李雅普诺夫(Lyapunov)稳定性理论,若所有特征值均具有非正实部,则系统稳定,否则系统不稳定.将表2中的参数设置带入式(1)和式(2)中计算可以得到模型各均衡点对应的特征值及其稳定状态,如表3所示.由表3可知,该模型并不存在ESS.
1.4 基于SD的动态奖励模型稳定性分析
在高铁运营安全监督系统演化博弈过程中,每个博弈参与者会主动模仿同种群其他高收益参与者的行为,从而动态改变自己的策略,因此,可以使用SD方法来分析均衡解的稳定性[6-7,13].根据上述博弈模型的假设,运用Vensim PLE 5.6a建立系统的动态奖励演化博弈模型如图1所示.该模型由3个子系统构成,分别为国家铁路局子系统、高铁公司子系统及委托路局子系统.其中模型的所有变量赋值及变量间的关系可以参照表1和式(1)中的3个复制动态方程.
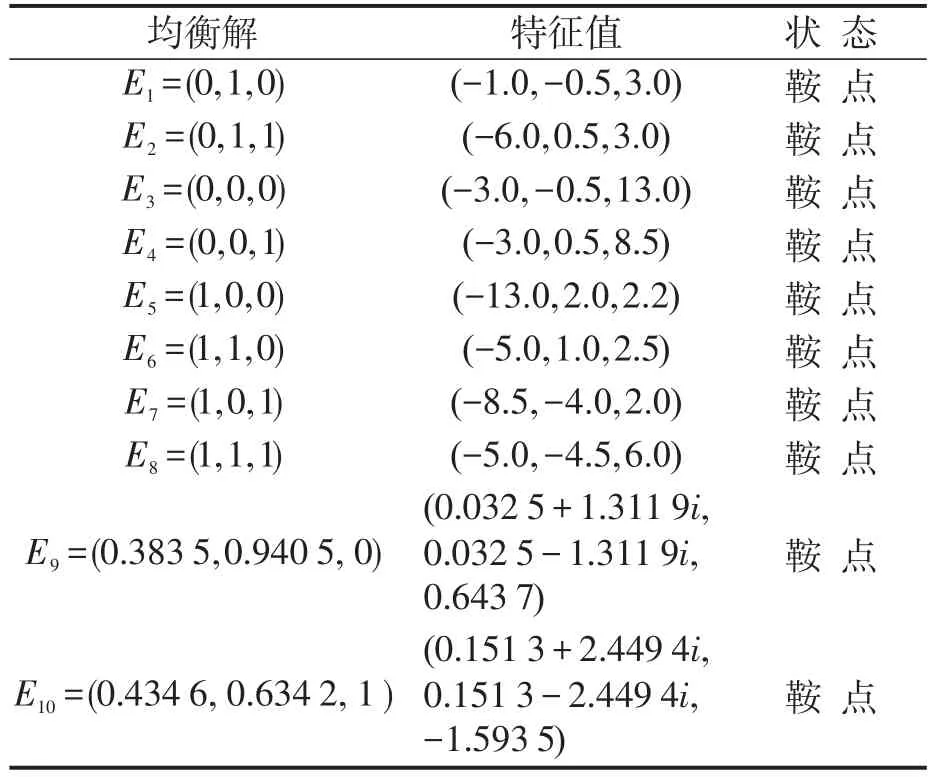
表3 动态奖励策略模型各均衡点及其特征值Table 3 Equilibrium point and characteristic values of the game model based on dynamic rewarding scenario
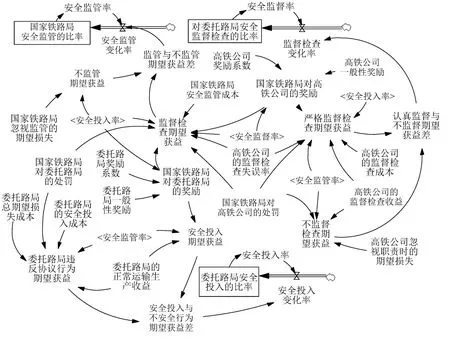
图1 高铁运营安全监督系统动态奖励演化博弈SD模型Fig.1 System dynamics model of high-speed railway operation safety supervision evolution game system based on dynamic rewarding scenario
以E10为例进行仿真,模型设定如下:INITIALTIME=0,FINALTIME=40,TIMESTEP=0.007 812,Units for Time=week,Integration Type:Euler.仿真结果如图2所示.由图2(a)可知,博弈三方表现出了相对稳定的状态;但是如果其初始选择策略发生微小改变(X=0.434 6改变为X=0.43),则仿真结果如图2(b)所示,说明均衡点E10的平衡状态并不稳定.
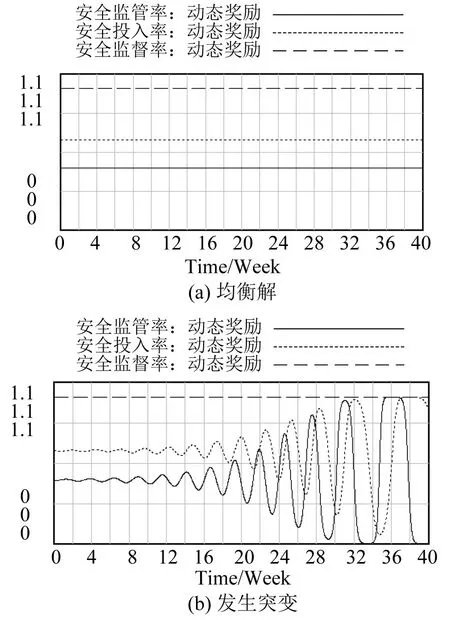
图2 E10策略下系统演化博弈过程Fig.2 Game results under the equilibrium solutionE10 strategy and mutation
2 高铁运营安全监督系统动态奖惩演化博弈模型分析
2.1 动态奖惩模型求解及稳定性证明
在控制博弈过程波动性的研究中,文献[6-7]提出将违规处罚与其违规概率相联系来控制模型策略的波动.因此在动态奖励模型的基础上,本文提出动态奖惩模型,在动态奖励的同时国家铁路局对委托路局和高铁公司进行动态处罚,即对委托路局的处罚与其违法行为的比率成正比,对高铁公司的处罚与其忽视监督职责的比率成正比,分别为,其中γ,δ和PR,PE分别为对委托路局和高铁公司的处罚系数和一般性处罚.令处罚系数γ,δ都等于1,则将带入式(1)和式(2)中,可以解得8个纯策略均衡解和2个混合策略解,分别求其相应的特征值,可以得到每个均衡解的稳定状态如表4所示.
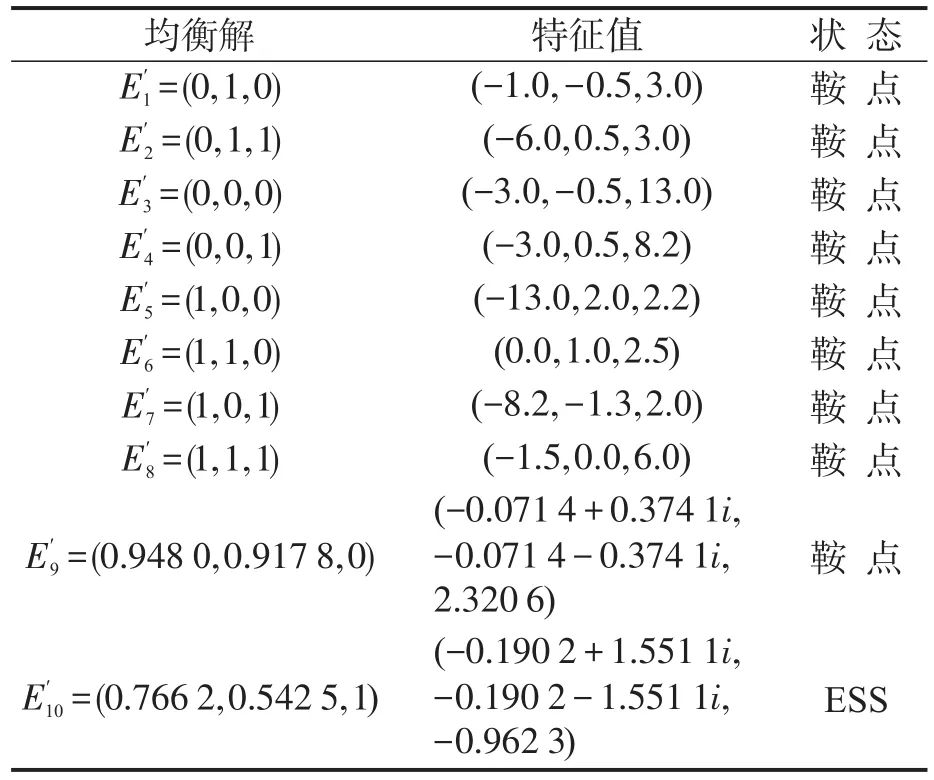
表4 动态奖惩策略模型各均衡点及其特征值Table 4 Equilibrium point and characteristic values of the dynamic rewarding and punishment game model
2.2 基于SD的动态奖惩模型稳定性分析
通过SD仿真对动态奖惩模型的各均衡点进行验证,系统演化博弈SD模型如图3所示.
在动态奖惩场景下,当随机选取系统博弈三方的初始策略分别为X=0.1,Y=0.1,Z=0.1时,系统演化博弈模型的仿真结果如图4所示.
从图4可以看出,动态奖惩场景下,系统博弈三方的博弈演化过程都大概收敛于
说明存在ESS使博弈过程最终趋于稳定状态,这同表4显示的结果一致.同时,动态奖惩场景下的系统演化博弈过程在前期仍然有比较大幅的波动,虽然最终国家铁路局的安全监管率和高铁公司的监督检查率稳定值都比较高,但委托路局的安全投入率稳定值却刚刚过半.由于在实际当中,国家铁路局的安全监管应该比较有限,高铁运营安全生产更多依靠高铁公司的实时监督,说明最终模型仿真的稳定效果并不理想.
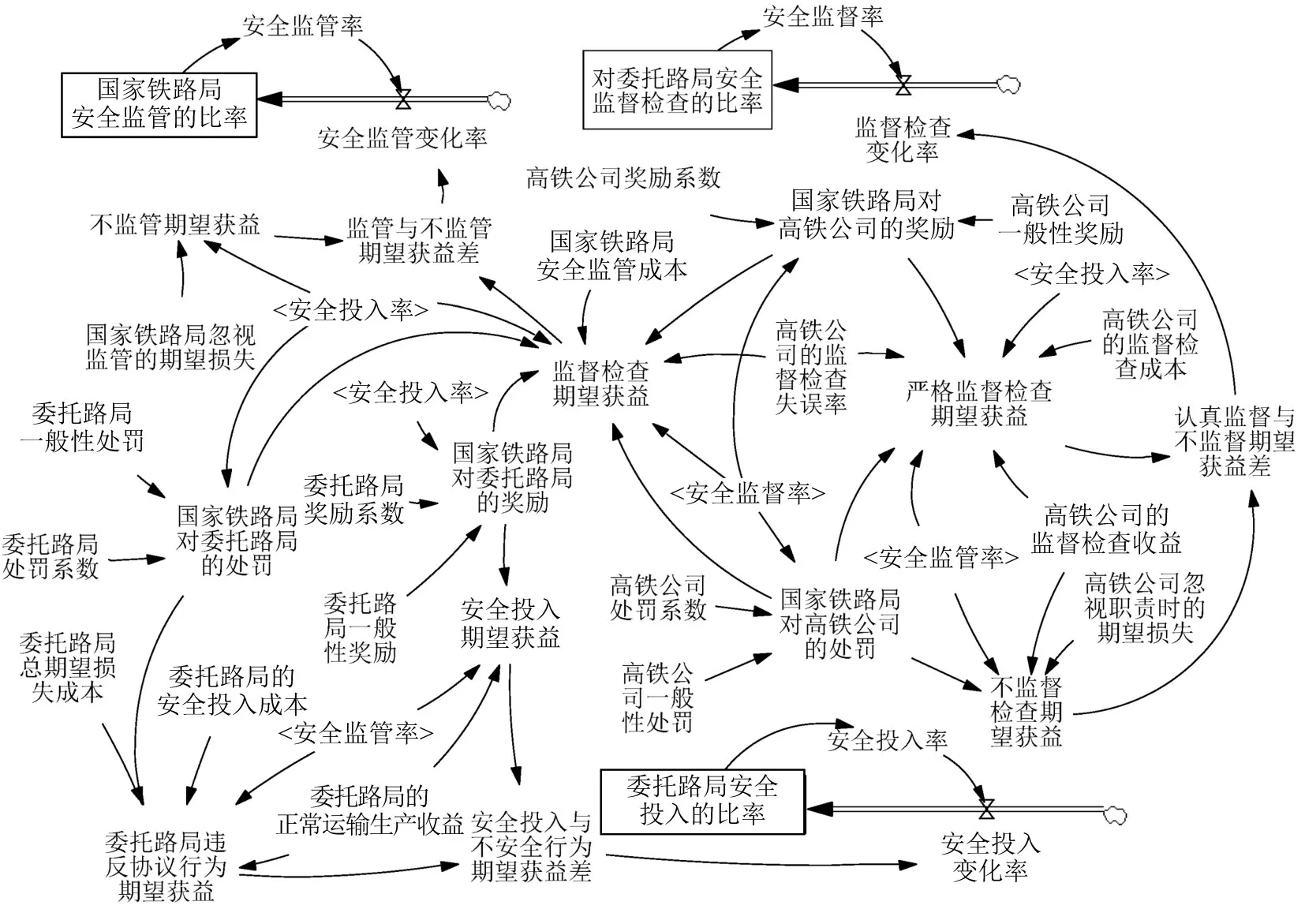
图3 高铁运营安全监督系统动态奖惩演化博弈SD模型Fig.3 SD model of high-speed railway operation safety supervision evolution game system based on dynamic rewarding and punishment scenario
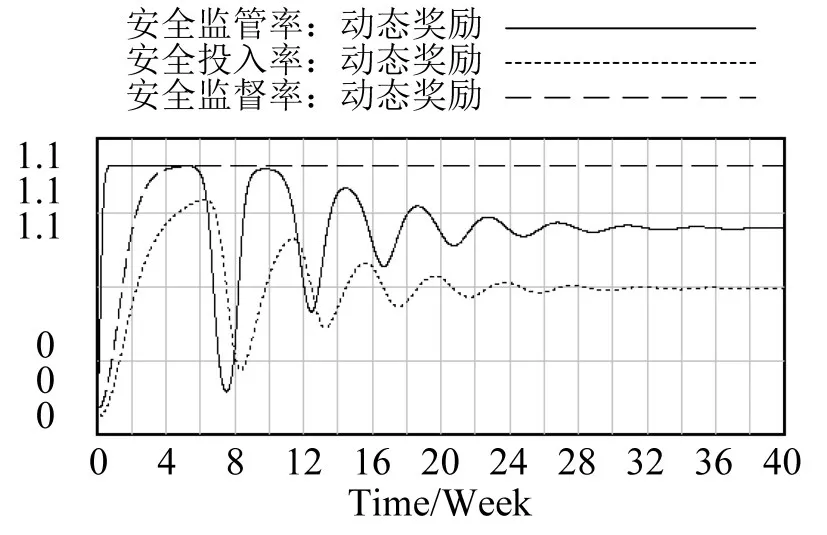
图4 动态奖惩场景下的系统演化博弈过程Fig.4 Game results based on dynamic rewarding and punishment scenario
3 高铁运营安全监督系统优化动态奖惩演化博弈模型分析
3.1 优化动态奖惩模型求解及稳定性证明
为了使系统各方的博弈过程达到最优,在动态奖惩模型的基础上提出优化动态奖惩模型继续进行追加处罚和奖励,即国家铁路局对委托路局和高铁公司的处罚和奖励,分别为
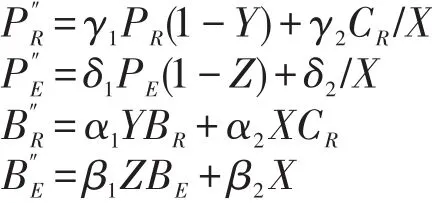
式中:γ1,γ2,δ1,δ2和α1,α2,β1,β2分别为国家铁路局对委托路局和高铁公司的处罚和奖励系数,且都设为1.
同样,通过式(1)和式(2),可以解得8个纯策略均衡解和1个混合策略均衡解,然后得到每个均衡解的稳定状态.特别地,对于,由于复制动态方程组中包含X为分母的情况,所以其不能为零.因此,使用占位符R代替X.对于,其对应的特征值为 :λ1=-R2-2R-1/2,λ2=-R2/4-3R-1,λ3=15R2/4+19R/2-6,由于R接近于0,可以得到λ1,λ2,λ3都小于0,所以该均衡解是ESS.同理可以证明其他均衡解E2′-E9′都不是ESS.9个均衡解的特征值及其均衡状态如表5所示.
3.2 基于SD的优化动态奖惩模型稳定性分析
使用SD仿真对模型的各均衡点进行验证,则优化后的系统演化博弈SD模型,如图5所示.
在优化动态奖惩模型下,当随机选取系统博弈三方的初始策略分别为X=0.5,Y=0.5,Z=0.5时,系统演化博弈模型的仿真结果如图6所示.

表5 优化动态奖惩模型各均衡点及其特征值Table 5 Equilibrium point and characteristic values of the optimized dynamic rewarding and punishment game model
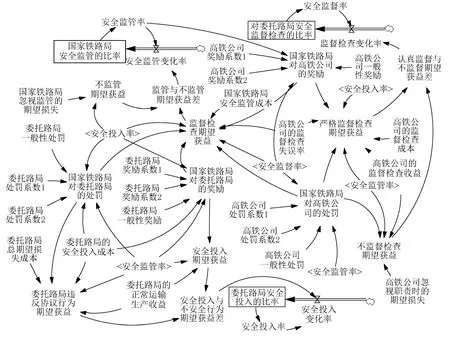
图5 高铁运营安全监督系统优化动态奖惩策略演化博弈SD模型Fig.5 System dynamics model of high-speed railway operation safety supervision evolution game system based on optimized dynamic rewarding and punishment scenario
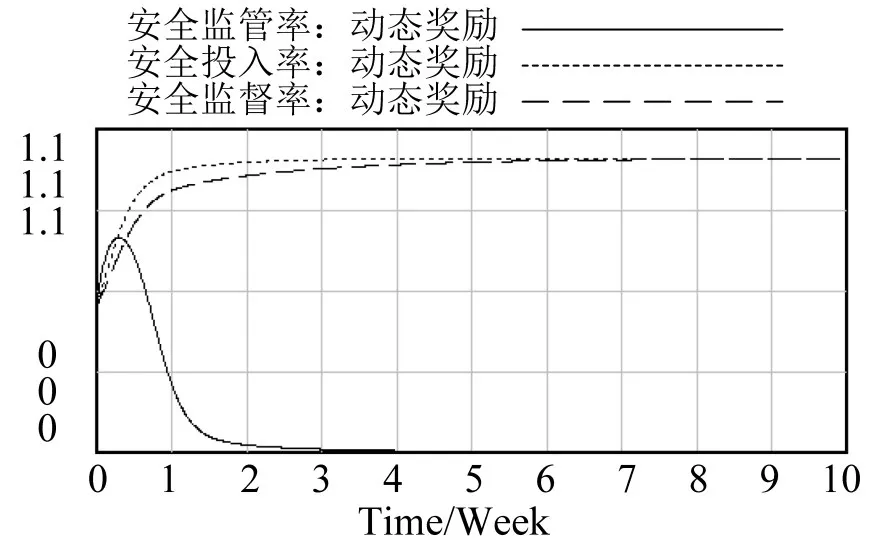
图6 优化动态奖惩场景下的系统演化博弈过程Fig.6 Game results based on optimized dynamic rewarding and punishment scenario
综上,通过理论证明,结合SD对高铁运营安全监督系统演化博弈进行仿真是解决演化博弈均衡解稳定性分析的有效方法.通过仿真发现,动态奖励场景下委托路局选择进行安全投入的比率存在波动增大的现象;动态奖惩场景下,其波动状态得到有效抑制,安全投入率的演化过程存在ESS,但并未达到最优;优化动态奖惩场景下,委托路局违反协议的行为得到有效控制,安全投入率在短期内达到最优.
4 结论
本文通过对高铁运营安全监督系统静态演化博弈模型进行优化,分别建立了基于动态奖励,动态奖惩和优化动态奖惩场景下的,包括国家铁路局、高铁公司和委托路局三方在高铁运营安全监督过程中的系统演化博弈模型,并通过演化博弈理论结合SD仿真,分析了3种场景下博弈三方策略的动态选择博弈过程.通过使用动态奖惩和优化动态奖惩模型,可以有效控制博弈三方策略选择的波动性,获得ESS.特别的,通过优化动态奖惩模型,国家铁路局的安全监管率下降的同时,高铁公司的安全监督检查率和委托路局的安全投入率都得到了有效提高,使三方在长期博弈过程中达到最优状态.以上结果为委托运输管理模式下,高铁运营安全监管机制的设计和应用提供了思路,具有重大的理论和实践意义.
本文中模型参数的赋值是基于参考文献[7]并结合本领域专家经验的基础上得到的,与实际情况可能存在差异,在未来的工作中,将进一步结合现场实际数据对模型进行仿真研究,以得到更具说服力的结果.
