一种基于局部—全局主题关系的演化式摘要系统
2018-10-19吴仁守王红玲
吴仁守,刘 凯,王红玲
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
随着大数据时代的到来,互联网逐渐成为了人们获取和发布信息的主要渠道,互联网上关于热点新闻事件的报道与日剧增。当人们想要了解某一新闻事件时(例如,Egyptian Crisis),可以轻易在互联网上搜索到大量相关的报道,但是这些报道通常只是报道了这个新闻事件在某一时间段内的信息,且各个报道之间会有大量重复信息。面对海量的信息,人工逐一浏览归纳是非常耗时耗力的,为方便用户快速、全面地了解事件的发展,自动文摘成为一个有效手段。
传统多文档自动文摘把与事件相关的文档作为一个文档集合并为之生成摘要,集合中文档数目通常较少。面对互联网中大量相关且相似的文档,传统多文档自动文摘无法很好地工作。而且,由于传统多文档自动文摘没有考虑各个文档之间的时间和主题关系,很难让用户了解该事件的演化发展过程。与之相比,带有时间标志的演化式文摘(evolutionary timeline summarization,ETS)可以针对互联网上新闻事件的报道文档,按时间顺序抽取出演化式摘要,为用户提供该事件全部发展过程,方便用户全面了解事件的前因后果和发展脉络,如表1所示。
随着时间推移,新闻话题的内容往往会发生变化,如何有效地组织这些大规模文档,生成主题在不同发展阶段的局部摘要,使其既能够提炼出主题的局部摘要信息,又能体现相邻时间段的主题演化,同时避免引入上一阶段的冗余信息,是演化式摘要面临的一个主要难题。由此,本文提出了一种基于局部—全局主题关系的演化式摘要方法,该方法将新闻标题作为文摘的候选句子,大大降低了数据量,并对事件进行主题分割,在考虑时间演化的基础上同时考虑子主题间的主题演化,最后通过一种改进的PageRank[1]算法将子主题和大主题相关联。该方法与以往方法的不同之处在于: 以往方法通常通过抽取命名实体来追踪事件的演化,并且只考虑了时间维度或主题维度上的演化。本文除了考虑不同时间段的演化关系,还引入了子主题间的演化关系,并对传统的PageRank进行了拓展,利用句子、时间和主题三者相互强化来对句子打分排序。

表1 Wikipedia中关于Egyptian Crisis的部分带时间标签摘要
1 相关工作
传统多文档自动文摘(multi-document summarization,MDS)[2]是将同一主题下多个文本描述的主要信息按压缩比提炼出一个文本摘要的自然语言处理技术。根据文摘句选取方式的不同主要可分为两种: 抽取型(extraction)文摘[3]和理解型(abstraction)文摘[4]。
作为多文档自动文摘的一种,演化式摘要为每个文档做上时间标记,然后按时间序列构成一个摘要,它的一个重要属性是动态演化性[5]。演化式摘要的动态演化性与话题检测与跟踪(TDT)任务中的话题演化研究类似,但又有所不同。TDT衡量的是同一个话题随时间推移表现出的动态性、发展性和差异性。演化式文摘通常针对单个新闻事件(或话题),重点考虑内容演化,忽略强度演化。同时,不需要根据演化趋势做出预测,而需要根据演化趋势抽取代表句子生成摘要。
与时间有关的文摘技术最早由Allan[6]提出,通过抽取关键名词短语和命名实体来实现。Tran[7]也是通过抽取命名实体来追踪事件演化的,但是和上述方法不同的是,他利用了维基百科关于该事件的词条中实体的分布,并且综合考虑了实体在当前日期文档集合中的显著性(salience)和该实体在所有文档集中的信息性(informativeness),据此抽取实体和它的上下文。Chieu[8]通过计算句子的新奇性(interest)和爆发性(burstiness)来抽取得分较高且日期不相连的句子作为摘要。不过这些方法都没有考虑新闻事件所特有的演化特性。Yan[9-10]使用基于图的方法,根据时间将句子映射到同一个平面,然后创建演化性文摘。其认为各个摘要组件既相互独立又相互联系,强调相关性、范围性、一致性和跨日期多样性,并通过构造一个最优化框架来平衡局部和全局的关系。其中Yan[10]通过将当前时间段文档集合附近的文档集,根据时间的间隔投影到当前文档集中来考虑文档集合之间的联系。该方法与本文提出的方法相似,但是它只考虑了时间的演化而忽略了主题的演化。Li[11]把演化摘要任务看作主题演化的过程,利用层次狄利克雷过程为每一个日期文档集抽取出主题,捕捉主题演化的模式,通过考虑主题相关性、覆盖率和一致性等不同方面,抽取句子作为摘要。William[12]使用表示学习的方法把这个问题作为一个句子推荐任务。在纯文本语料库的基础上,利用了来自网络上排名最高的相关图像,使用卷积神经网络对图像进行建模,并提出了一种可扩展的低秩近似方法来学习新闻故事和图像的联合嵌入。Meena[13]使用与自然演化过程类似的遗传算法来优化线性搜索问题。
在中文方面,与Tran[7]类似,宋俊等[14]提出面向实体的演化式多文档摘要生成方法,利用一个概率主题模型联合建模文档主题的演化和实体的参与情况,然后结合实体对句子进行评分和选择。徐伟等[15]利用词项强度和熵来确定代表性词项,然后基于内容覆盖性、时间分布性和传播影响力等三种指标构建出评价时间线摘要的综合评价指标,最后采用滑动窗口的方法,遍历时间轴上的微博消息序列,生成微博时间线摘要。
2 基于主题关系的演化式摘要方法
一个新闻事件通常包含了多个子主题[16],每个子主题表现了这个新闻事件的某一个点。这些子主题往往是相互关联的,但是在一定程度上也是相互独立的,并不是所有子主题都和某个特定的子主题紧密关联。为了更好地刻画事件演化过程,我们分别从两种角度对事件主题进行建模: 一种是局部的,基于子主题内部时间演化;另一种是全局的,基于子主题间主题演化。
如图1所示,我们将新闻标题集合C划分为k个子主题集{T1,T2,T3,…,Tk}。对于各个子主题ti,分别计算其对应的子主题内得分[Local(i)]与子主题间得分[Global(i)],并生成子主题摘要。
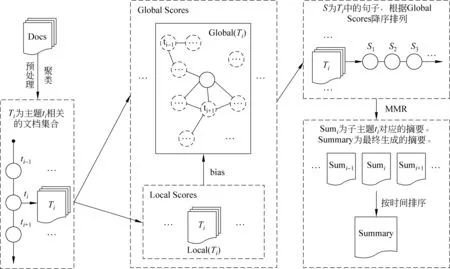
图1 系统框架图
2.1 子主题内得分
在计算子主题内得分时,我们认为各个子主题是相互独立的。对于任意子主题ti,对应的标题集Ti中标题的主题基本相似,标题之间主题演化不明显,因此在计算子主题内得分时不考虑标题间的主题演化,而仅仅考虑其时间演化。
2.1.1 标题间时间距离
一般来说,如果两个标题之间的时间间隔越长,两个标题之间的联系就越弱,因此标题间的时间差异可以通过标题间时间距离来衡量。Rui Yan[10]利用高斯核函数将不同时间集中的句子映射到当前时间集来计算句子间的转移概率。与其类似但又有所不同,我们没有将不同时段的标题映射到同一时间段上,而是通过圆核函数来计算两个标题之间的时间距离。圆核公式如式(1)所示。
(1)
其中ts表示时间戳,σ为最大时间间隔。一般来说,σ的最优设置可以根据新闻集而变化,因为句子可能在某些新闻主题中具有更广泛的语义范围,因此需要更高的σ值,反之亦然。
2.1.2 子主题内标题排序模型
通过对子主题ti对应的标题集Ti构建有向图,可以使用普通的随机游走模型来计算子主题内各标题得分。设Ti={h1,h2,…,hn},构建一个有向图G=(V,E),V中的结点由Ti中的标题构成,结点vi到vj的边eij的权重由vi到vj的转移概率pij决定,如式(2)所示。
(2)
其中,fij表示标题hi和hj对应的TF-ISF特征向量的余弦距离。
标题hj得分通过模型中随机游走的访问概率来估计,该概率使用下列等式迭代计算,如式(3)所示。
(3)
其中转移概率pij在计算时已经归一化以满足马尔科夫属性,阻尼因子d=0.85。当相邻两次迭代后,各个标题的得分差异小于0.000 1时,迭代停止。
2.2 子主题间得分
在计算子主题间得分时,我们认为各个子主题是相互关联的。因此,不仅要考虑各个标题之间的时间距离,还需要考虑各子主题间的主题差异。
2.2.1 子主题距离
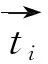
(4)
(5)
2.2.1 子主题间标题排序模型
在为子主题ti对应的标题集进行排序时,我们将其余子主题根据其与子主题ti的距离映射到当前子主题中,并利用之前计算的子主题ti内部排序结果为子主题ti内的标题设置偏好。如图1所示,在计算Global(i)时,实线圆代表当前计算的子主题ti,虚线圆代表映射到子主题ti的其他子主题。为满足需求,我们对传统的PageRank算法进行了改变。
传统的PageRank算法表示如式(6)、式(7)所示。
其中Rank为PageRank值,M为N×N的转移概率矩阵。Taher H[17]通过使用非均匀个性化向量p来增加某些类别的页面的影响,从而创建主题敏感的PageRank。他认为偏置p涉及在计算的每次迭代中向适当的节点引入额外的等级,而不仅仅是在标准PageRank向量上执行的后处理步骤。与其类似,我们利用计算子主题内得分时得到的标题得分来修改p,将子主题ti内的局部特征融入到子主题间标题排序的全局建模中。
对于子主题ti,我们使用不均匀的p=vji,如式(8)所示。
(8)
其中β为阻尼系数,设置为0.8,S(hi)为标题hi在主题内的得分,N为所有新闻标题的数目。
对于标题集C的所有标题,我们构建转移概率矩阵M,pij表示标题i到标题j的转移概率,如式(9)所示。
(9)
有了转移矩阵M和偏置p,就可以利用传统PageRank算法的求解过程进行求解。
2.3 摘要生成
根据各子主题对应的子主题间排序结果,分别从各个子主题中抽取一定数目的标题,并按照时间顺序输出作为摘要。各个子主题抽取的标题数目η由该子主题包含的标题数目|Ti|以及总的标题数目|C|来决定,具体计算如式(10)所示,最终生成摘要包含标题数目n如式(11)所示。
其中k为子主题数目,偏置b用于对最终生成摘要数目进行调整。当给定最终生成摘要包含标题数目n时,可以通过调整b的值进行控制。
一般的,子主题包含的标题数目越多,该子主题越重要,因此抽取的标题越多。当η小于1时,可以认为该子主题重要性较弱,不对其生成摘要。在冗余控制方面,利用最大边缘相关(MMR)[18]算法来去除冗余的句子。
3 实验与评价
3.1 数据集
我们利用Giang Tran[19]论文中的数据集[注]Available at http: //www.l3s.de/*gtran/timeline/,其中包含了埃及革命、叙利亚战争、也门危机和利比亚战争的四个长期事件。
数据集中的文章主要来源于Google搜索,针对用于创建参考摘要的新闻机构,构建了例如“埃及(革命或危机或起义或内战)”等问题,利用Google进行查询,并收集前300个答案。数据集中的参考摘要来源于包含BBC、CNN和Reuters等在内的多家知名通讯社出版的,由专业记者手动创建的对应事件的时间表。具体信息见表2。

表2 参考摘要概述
注: 参考摘要数量 (#TL),所有参考摘要时间点个数 #Timepoint,真实状况时间点个数(#GT-Date),时间范围(#TL-Range),每个参考摘要上每个日期的平均句子(#a.sent),新闻文章数量 (#News)
3.2 评价方法
ROUGE[20]是Chin-Yew Lin在2004年提出的一种自动摘要评价方法,被广泛应用于NIST组织的自动摘要评测任务中。ROUGE基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。基本思想为由多个专家分别生成人工摘要,构成标准摘要集,将系统生成的自动摘要与人工生成的标准摘要相对比,通过统计二者之间重叠的基本单元(n元语法、词序列和词对)的数目,来评价摘要的质量。通过与标准人工摘要的对比,提高评价系统的稳定性和健壮性。该方法现已成为自动评价技术的通用标准之一。本文采用ROUGE中ROUGE-1,ROUGE-2,ROUGE-L和ROUGE-SU4的F值来对生成的摘要进行评价。
3.3 对照实验
LexPageRank[21]: 是基于图排序的自动摘要算法,使用句子作为图结点,如果两个句子余弦相似度大于阈值则在这两个句子之间添加无向边,利用PageRank算法求解。其主要思想是: 若一个句子与众多其他句子相似,那么此句话就可能是重要的。
Chieu: 提出了“interest”和“burstiness”两种测量标准,认为在事件发生之后的一段时间内经常会在许多新闻文章中重复出现,并且有不同的更新和评论的事件是重要的。
ETTS: 是迄今为止在新闻领域最好的无监督TS系统之一。它利用句子中的单词分布与整个语料库中的单词分布以及相邻日期之间的相似性构造本地和全局摘要并进行优化组合。
3.4 实验设置
实验采用Java编程,运行服务器配置为3.40GHz Inter(R) Core(TM) i7-6700 CPU和16GB内存,使用Windows系统和JKD1.8.0_101环境。
我们将四个事件中的“也门危机”作为开发集,来对系统的各项参数进行调整。各个对比实验中的超参数均按照其对应论文中推荐的值进行设置,并根据本文数据集的大小及时间跨度等特点做了轻微的调整。在其他三个事件中进行交叉验证,将系统生成的自动摘要与人工生成的标准摘要利用ROUGE评价包(1.55版本)分别计算每次实验结果的ROUGE-1,ROUGE-2,ROUGE-L和ROUGE-SU4的F值,最后取平均值。
具体实验步骤如本文第二节。以下详细介绍文本预处理、子主题划分方法与参数设置。
3.4.1 文本预处理
我们对数据集中的特殊字符(例如@、#等)和长度小于4的标题进行过滤,并对单词进行词干提取以减少词表大小。最后,通过类似TF-IDF的TF-ISF(S为Sentences)技术将新闻标题转化为特征向量。
3.4.2 子主题划分
本文利用K-means聚类方法对新闻标题集合C进行子主题划分,子主题数目k值根据轮廓系数法[22]得到。通过枚举,令k从2到10取值,在每个k值上重复运行数次k_means,并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
3.4.3 参数设置
偏置b主要用于对生成摘要包含标题数目进行调整。为适应本文所用数据集,我们控制生成摘要包含标题数目在50个左右。因此,实验中b值统一设置为事件包含的总标题数目|C|的二分之一。
最大时间间隔σ主要用于对超出一定时间间隔的数据进行截断,减少干扰。为适应本文所用数据集,通过在“也门危机”事件数据集上对不同σ值进行实验,本文实验中σ值统一设置为一个月。
3.5 实验结果及分析
实验结果如表3所示(其中LGT为本文方法)。结果显示,本文提出的方法在三个事件中的各项测量指标均高于对比实验方法,说明本文提出的方法是有效的。和预想的相同,由于LexPageRank并没有考虑时间因素,所以其在三个事件中表现都为最差,而Chieu考虑了事件的演化性,所以效果优于LexPageRank。出乎意料的是: ETTS三个事件中的各项测量指标普遍高于Chieu,但是在叙利亚战争中ROUGE-2低于Chieu。通过比较两者生成的摘要,发现Chieu倾向于选择含有相似短语的标题作为摘要。当该短语是标准事件表中的重要短语时,Chieu获得了更高的ROUGE-2值。我们猜测这是由于Chieu算法本身造成的。它为句子集中具有高相似度的句子赋予高权重,而其自带的去冗余方法主要针对去除日期相近的句子。
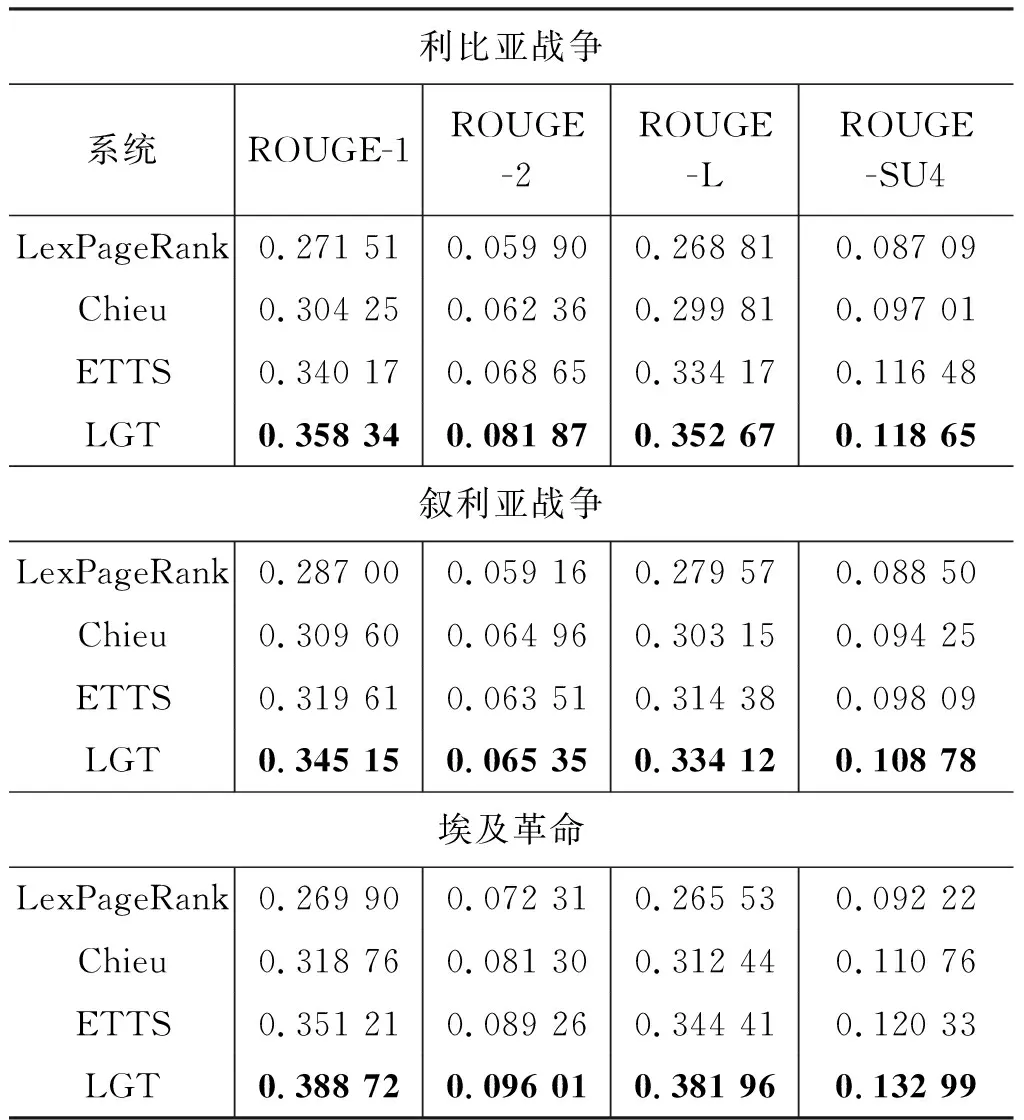
表3 实验结果
针对利比亚战争,表4和表5分别列出了CNN人工编辑的部分摘要和本文方法抽取的部分摘要。结果显示,对于延续时间较长且在主题演化主线上的子主题,例如,“对利比亚实行禁飞区”和“北约对利比亚发动军事行动”等子主题,本文方法可以较好地识别并抽取出相关内容,说明本文的方法是有效的。但是,对于持续时间较短、偏离主题演化主线的事件,例如,“伊曼·奥贝迪(Eman al-Obeidy)事件”等,本文方法还是无法很好地识别出来。
表5显示,在冗余度控制方面,无论是在时间粒度上或是子主题粒度上,本文方法生成的摘要冗余度都很低。但是,本文方法生成的摘要会包含一些评论性语句,例如,“What can be done to end the crisis in Libya?”等,这些语句通常并没有涉及具体的事件,不适合作为时间标签摘要。我们猜想,抽取到这些句子的原因可能是这些评论性句子中通常包含多个该事件下的主题词,例如,“libya”“crisis”等,导致这些句子获得了高得分。
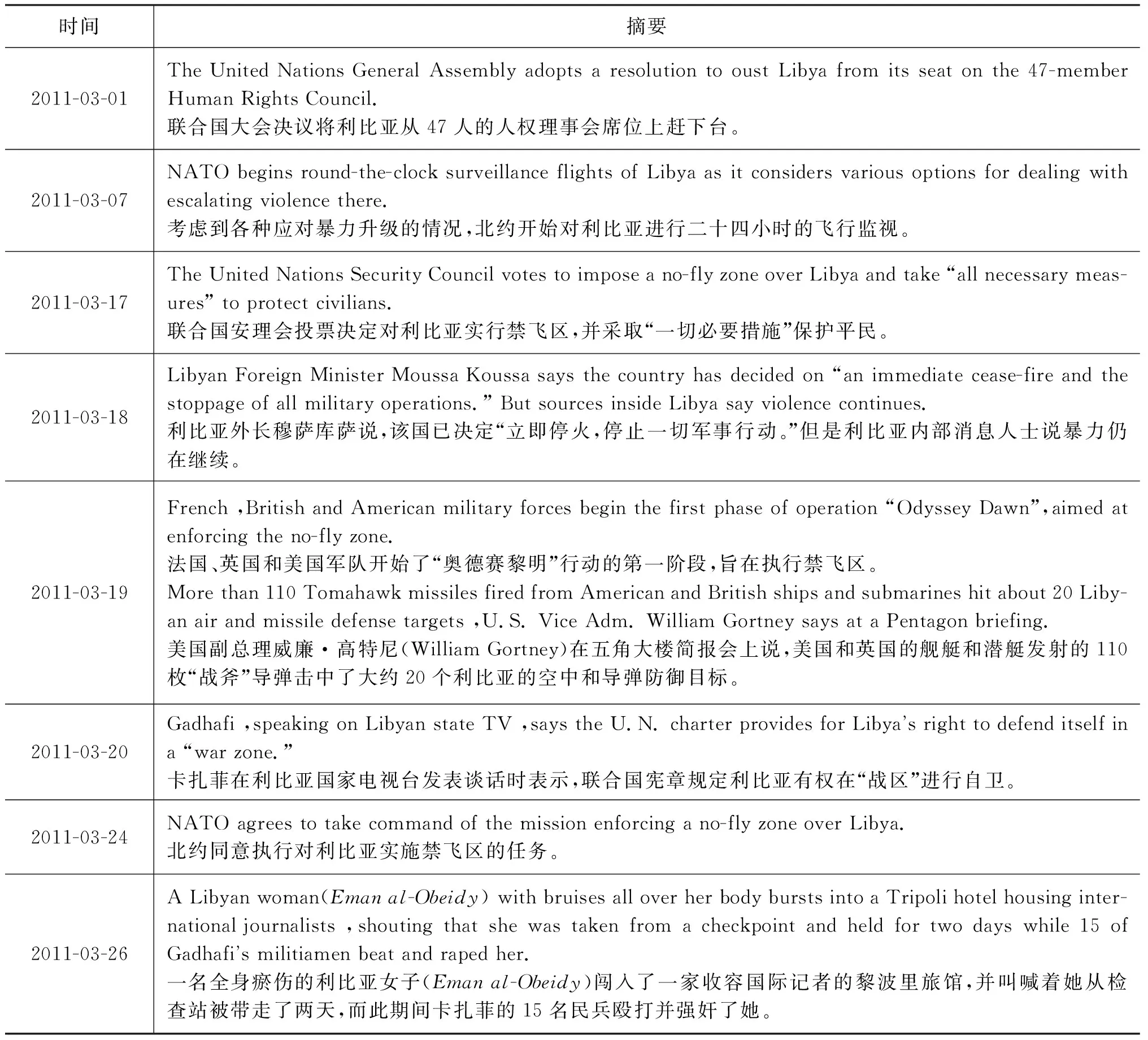
表4 CNN针对利比亚战争人工编辑的时间标签摘要(节选,2011年3月)
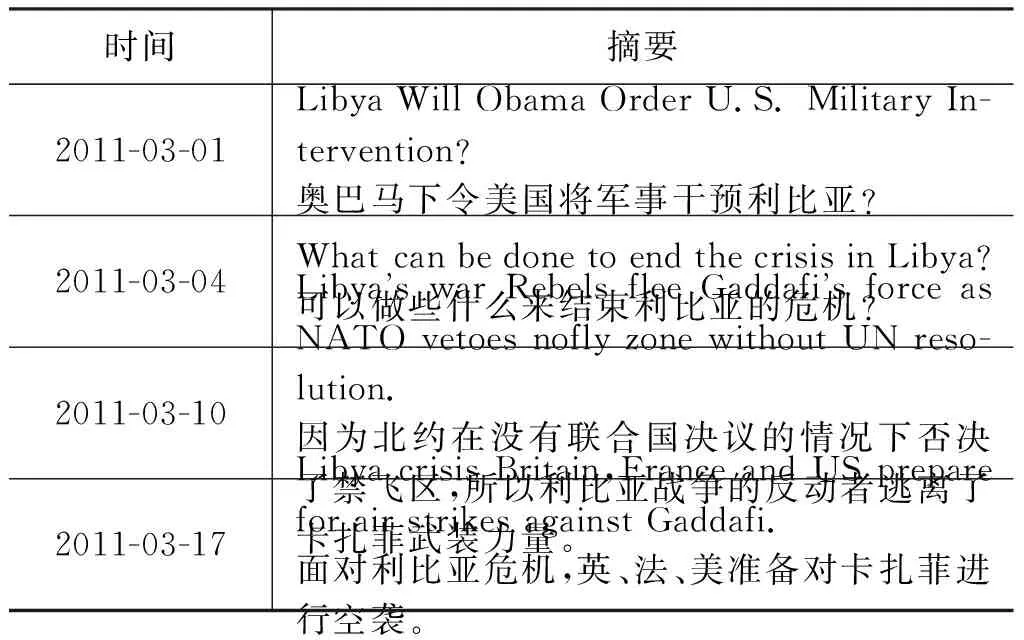
表5 LGT生成关于Egyptian Crisis的部分带时间标签摘要(节选,2011年3月)

续表
4 结束语
演化式摘要作为多文档自动文摘的一种,它在传统多文档摘要的基础上需要额外考虑事件随时间变化的演化特性。为此,本文提出了一种基于主题和时间变化的演化式摘要方法,其分别考虑了子主题内部和子主题间的主题和时间关系,并通过变种的PageRank算法将两者联系起来。实验结果表明,该方法与现有方法相比在ROUGE值上有较大提升。未来,我们将通过句法结构分析、单词词性等文本特征来判断句子是否属于评论性句子,避免这些不涉及具体事件的句子在摘要中出现。另外,我们还将尝试不同的文本表示方法,例如,LDA、Word Embedding等,并考虑将时间和主题等特征加入文本表示的向量中。
