基于TDNN-FSMN的蒙古语语音识别技术研究
2018-10-19王勇和高光来
王勇和,飞 龙,高光来
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
0 引言
语音是人类最自然、便捷的交流方式,而语音识别技术,就是让机器能够“听懂”人类的语言并将语音信号转化为对应的文本或命令。基于高斯混合模型—隐马尔可夫模型(Gaussian Mixture Model-Hidden Markov Models,GMM-HMM)的语音识别框架在很长一段时间都是语音识别系统的主导框架,其核心就是用GMM对语音的观察概率进行建模,而用HMM对语音的转移概率进行建模[1]。近年来,深度神经网络(Deep Neural Network,DNN)[2]的研究和应用极大地推动了语音识别的发展,相比传统的基于GMM-HMM的语音识别系统,其最大的改变是采用DNN替换GMM对语音的观察概率进行建模来计算HMM状态的后验概率。根据文献[3],基于DNN-HMM的声学模型采用固定长度的输入窗对语音的上下文特征进行建模,而语音是一种各帧之间具有很强相关性的复杂时变信号,所以这种方法不能充分利用语音的上下文时序信息。
相比DNN,时延神经网络(Time Delay Neural Network,TDNN)[4]同样是一种前馈网络架构,它对每个隐藏层的输出都在时域进行扩展,即每个隐藏层接收到的输入不仅是前一层在当前时刻的输出,还有前一层在之前和之后的某些时刻的输出。在文献[5]中,通过选择正确的时间步长和对隐藏层输出进行降采样,TDNN可以从输入上下文中的所有时间步长提取足够语音特征信息。因此,TDNN会参考前一层网络的历史输出,可以对更长的历史信息进行建模而不能对未来信息进行建模。Zhang等人[6-7]提出了一种更简单的“记忆”存储神经网络结构,即前馈型序列记忆网络(Feed-forward Sequential Memory Network,FSMN),已被证明在大词汇量连续语音识别任务中具有比DNN和长短时记忆模块(Long-Short Term Memory,LSTM)更好的性能。FSMN是在DNN隐藏层旁边引入“记忆”模块的多层前馈神经网络模型。该“记忆”模块用于临时存储固定大小的上下文信息作为短期记忆机制,能够以时间序列学习长期依赖性信息。在本文中,TDNN融合FSMN的网络结构被应用于蒙古语语音识别声学模型。
目前,在中国内蒙古自治区、蒙古国及周边地区大约有600万人将蒙古语作为第一或第二官方语言,但是蒙古语语音识别研究仍处于初始阶段。高光来等[8]在2006年首次构建了蒙古语语音识别系统,在文献[9-10]中进一步对声学模型进行优化和设计。在文献[11]中,飞龙等人提出了基于词干的蒙古语语音关键词检测方法,并使用分割的方法在蒙古语大词汇量连续语音识别中取得了较好的效果[12]。在文献[13]中,张晖等人在蒙古语语音识别研究中引入了基于DNN的声学模型,获得了显著的性能提升。最近,基于深度神经网络的声学模型广泛应用于蒙古语语音识别中,如卷积神经网络(Convolutional Neural Network,CNN)和长短时记忆模块等,获得比DNN更好的识别结果[14]。然而,与其他语言如中文和英文相比,蒙古语语音识别声学模型仍有很大的优化空间。
为进一步提高蒙古语语音识别性能,本文首先将TDNN融合FSMN应用于蒙古语语音识别系统声学模型,通过对长序列语音帧进行建模来充分挖掘上下文相关信息。其次,FSMN中“记忆”模块用于存储对判断当前语音帧有用的历史信息和未来信息,本文通过用“记忆”模块中不同的历史和未来语音帧信息长度对模型进行建模,分析其对蒙古语语音识别系统性能的影响。最后,研究了不同隐藏层数目和每个隐藏层节点数对融合的TDNN-FSMN模型性能的影响。
1 基于TDNN-FSMN的蒙古语语音识别系统
1.1 TDNN声学模型
TDNN是一种多层(通常三个以上)前馈神经网络模型,传统的前馈神经网络每个隐藏层的输入都是前一层网络的输出,而TDNN在网络传播的过程中对各个隐藏层的输出也做了扩展,它将隐藏层的当前输出与其前后若干时刻的输出拼接在一起,作为下一个隐藏层的输入。因此,TDNN每个隐藏层的输入会参考前一层网络的历史输出,可以对更长的历史信息进行建模。
传统的TDNN每一个时间步长上,隐藏层的激活函数都会被计算一次。因此,在相邻时间步长中,大量的上下文相同信息被重复计算,大大增加了神经网络的训练复杂度。而TDNN相邻节点之间的变化可能很小,包含了大量的重复信息,因此可以每隔几帧合并计算一次结果,从而加速训练和解码过程。在文献[5]中,提出一种在TDNN训练中采用降采样技术来减小模型计算复杂度,通过选择合适的时间步长来大幅减少运算量,同时不能使所有的历史信息都可以被网络学习到。图1表示常规TDNN(实边+虚边)和降采样TDNN(实边)结构图。传统TDNN每个隐藏层的隐藏层单元(实边+虚边)都会被计算,而且相邻时间步长会重复计算隐藏层单元。采用降采样技术的TDNN在每个隐藏层只会计算一定时间间隔的隐藏层单元(实边),不仅能够对长时间依赖性的语音信号进行建模,而且模型复杂度较传统TDNN有大幅度降低。
1.2 FSMN声学模型
前馈型序列记忆网络是一种含有多个隐藏层的前馈神经网络。相比传统的DNN结构,FSMN在其隐藏层旁边增加了一个称为“记忆块”的模块,这些“记忆块”用于存储语音序列中与当前帧相关的历史关联信息以及未来关联信息。这些信息使得FSMN可以对语音序列中的长期相关性信息进行建模。图2表示在隐藏层中添加两个“记忆块”的FSMN结构图。
给定序列w1=(x11,x12,…,x1N),X={x1,x2,…,xt},每个xt∈X表示时间t的输入数据。相应的隐藏层输出表示为H={h1,h2,…,ht}。图2即为“记忆块”的结构示意图,当前语音帧ht及其前N1帧的输出和后N2帧的输出被计算到固定大小维度,并将其与当前隐藏层的输出一起作为下一个隐藏层的输入。
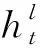
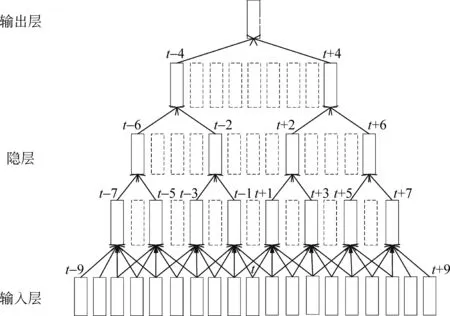
图1 TDNN结构图

图2 FSMN模型

图3 “记忆块”结构图
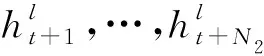
根据要使用的编码方法,编码系数a可以初始化为标量系数或向量系数。
(1) 如果编码系数a设置为标量,则FSMN称为标量FSMN(简称sFSMN),如式(1)所示。
(1)
(2) 如果编码系数a设置为向量,则FSMN称为向量FSMN(简称vFSMN),如式(2)所示。
(2)
由于vFSMN具有更好的建模能力,因此在本文中采用了vFSMN,简称为FSMN。
1.3 TDNN-FSMN声学模型
本文中,TDNN与FSMN相融合的神经网络结构被应用于蒙古语语音识别系统的声学模型。TDNN在网络传播过程中对各个隐藏层的输出做了扩展,传统前馈神经网络每个隐藏层的输入都是前一层网络的输出,TDNN则会参考前一层网络的历史输出,能对更长的历史信息进行建模,而且深层次的TDNN网络结构可以更加有效地提取训练数据中高层次信息的特征。双向FSMN神经网络结构在隐藏层旁增加了一个称为“记忆块”的模块,用于存储对判断当前语音帧有用的历史信息和未来信息。与循环网络结构一样,网络传播过程中可以学习到历史信息和未来信息。不同的是,FSMN采用非循环的前馈结构,不需要像循环网络结构那样必须等待语音输入结束才能对当前语音帧计算,其只需等待有限长度的未来语音帧输入即可。本文结合TDNN与FSMN的优点,将其融合应用于蒙古语语音识别声学模型。
如图4所示,TDNN与FSMN交替融合,包含六个隐藏层。在TDNN隐藏层中,使用{-n,m}表示将当前帧的历史第n帧、当前帧的未来第m帧和当前帧拼接在一起作为下个网络层的输入。假设t表示当前帧,在TDNN1(隐藏层1),将帧{t-2,t-1,t,t+1,t+2}拼接在一起作为下一个隐藏层的输入。在TDNN2和TDNN3处,将帧{t-3,t+3}拼接在一起作为下一个隐藏层的输入。因此,在网络的最高层,至少可以学习到上下文相关的8帧历史信息及8帧未来信息。
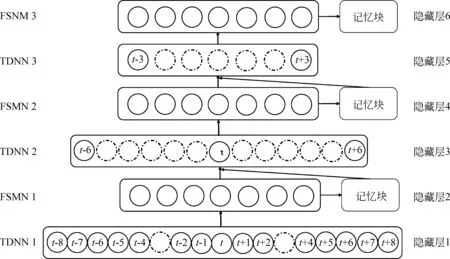
图4 TDNN-FSMN结构图
2 实验设置
2.1 实验语料
本文采用的蒙古语语音库是由193个说话人录制完成,其中采样率设为16kHz,每采样点进行16bit量化,声道为单声道。语音库包含69 781句蒙古语朗读语音数据,总时长大约有78h,每句话时长为5~10s。实验中随机选择88%的语音数据作为训练集,12%的语音数据作为测试集。发音词典由38 107个单词列表构成。对于语言模型,本文从蒙古语网站搜集大约8 500万单词的文本进行3-gram语言模型训练。
2.2 语音识别系统建立及评测
本文基于Kaldi[15]语音识别开发平台搭建了蒙古语语音识别系统。采用MFCC作为识别的特征参数。同时,对语音特征进行倒谱均值方差归一化(Cepstrum Mean Variance Normalization,CMVN)使得带噪语音特征参数的概率密度函数(Probability Density Function,PDF)更接近于纯净语音的概率密度函数,以减少训练语料与测试语料环境的不匹配度。之后使用线性判别分析与最大似然线性变换结合(Linear Discriminant Analysis-Maximum Likelihood Linear Transform,LDA-MLLT)将归一化后的上下文包含7帧(即±3)的高维特征进行区分性投影来降低特征向量维数至40维,保留具有分辨率的特征成分并使其集中在对角线上,以满足对声学模型在影响最小的情况下构建对角矩阵[16]。最后,使用基于特征空间最大似然线性回归(feature space Maximum Likelihood Linear Regression,fMLLR)进行说话人自适应训练,将fMLLR特征用于训练DNN,TDNN,FSMN和TDNN-FSMN。
传统神经网络进行非线性运算时通常采用Sigmoid,Tanh函数作为激活函数。然而,文献[17]研究表明,修正线性单元(Rectified Linear Unit,ReLU)作为激活函数可以提高神经网络的性能。在本文中,所有神经网络的训练都使用ReLU非线性激活函数。
实验中采用的评价指标为国际通用的WER计算方式,具体如式(3)所示。
(3)
式中,S代表替换错误词数,D代表删除错误词数,I代表插入错误词数,T为句子中的总词数。WER结果越小,表示识别性能越好。
3 实验与分析
3.1 不同神经网络的比较实验
在DNN-HMM声学模型训练中,首先对GMM-HMM训练得到的识别结果进行强制对齐,获得上下文相关的三音素状态作为声学模型训练的标签信息,共计3 762个独立的上下文相关状态,对应于DNN声学模型的输出维度。DNN的输入为15帧固定上下文窗口(即±7),每帧提取40维MFCC特征,共计600维特征向量。实验中DNN模型包含六个隐藏层,每个隐藏层节点数为2 048个。使用基于RBM预训练方法逐层初始化DNN。小批量尺寸固定为256,初始和最终学习率参数分别设定为0.05和0.008。通过mini-batch随机梯度下降算法进行迭代更新,mini-batch大小为256,学习率在最初几次迭代中保持不变,当训练的准确率在两次迭代中没有太大的变化时,将学习率减少并进行下次迭代。
TDNN声学模型包含六个隐藏层,每个隐藏层包含512个节点。其输入为5帧固定上下文窗口(即±2),每帧提取40维MFCC特征,共计200维特征向量。六个隐藏层的配置为{0},{-1,1},{-1,1},{-3,3},{-3,3},{-6,3},其中{0}表示常规的非拼接隐藏层。初始和最终学习率分别设置为0.001和0.0001。
FSMN声学模型包含六个隐藏层,每个隐藏层为512个节点,其中前三个隐藏层包含“记忆”模块,后三个隐藏层为常规隐藏层。实验中同样提取40维MFCC特征,由于FSMN的固有存储机制,不需要连续太多的语音帧序列作为输入,因此3帧固定上下文窗口(即±1),共计120维特征向量作为FSMN的输入特征。“记忆”模块中包含5帧历史信息和5帧未来信息。FSMN在训练过程中被随机初始化,不用任何预训练方法。模型训练过程中更新策略同DNN训练参数设置保持一致。
TDNN-FSMN包含六个隐藏层。第一个隐藏层为包含512个节点的TDNN,输入特征为5帧固定上下文窗口(即±2),共计200维特征向量。第二、四和六隐藏层为包含512个节点的FSMN,“记忆”模块中包含5帧历史信息和5帧未来信息。第三和五隐藏层是TDNN,隐藏层配置信息为{-3,3},FSMN隐藏层输出共记1 536个输出状态作为其输入。
表1显示了在蒙古语语音数据集训练的基于DNN,TDNN,FSMN和TDNN-FSMN声学模型的识别结果。实验中调节DNN模型为最优性能,每个隐藏层包含2 048个节点,其他三种神经网络结构隐藏层节点数设置为512。从实验结果可以看出,TDNN-FSMN得到的识别性能明显优于最优性能的基线DNN模型,WER从12.90%下降到12.00%,表明基于TDNN-FSMN的声学模型在蒙古语语音识别中有显著提升。
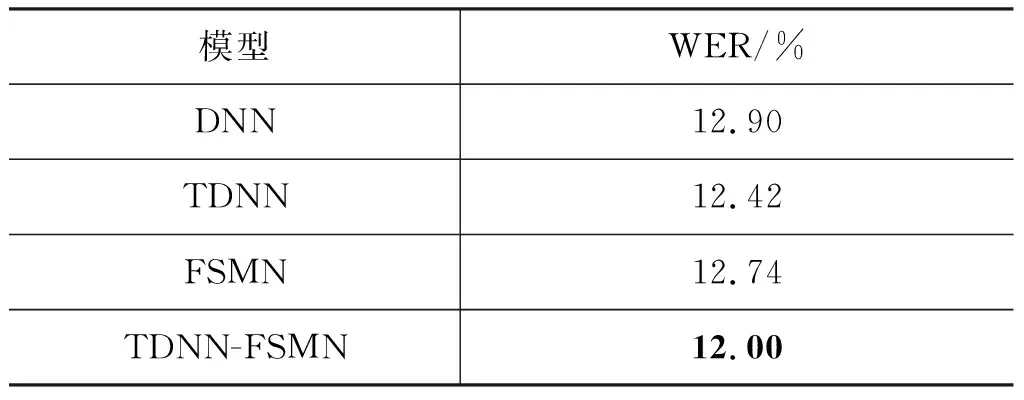
表1 不同声学模型对比实验结果
3.2 FSMN隐藏层不同结构的对比实验
本文对TDNN-FSMN中FSMN隐藏层“记忆”模块中包含历史信息和未来信息的帧数对蒙古语语音识别性能的影响进行了对比实验。其中,TDNN-FSMN网络结构包含六个隐藏层,每个隐藏层为512个节点。在实验中,TDNN-FSMN_5h_5f表示“记忆”模块中包含5帧历史信息和5帧未来信息,TDNN-FSMN_5h_4f表示“记忆”模块中包含5帧历史信息和4帧未来信息。模型训练过程中更新策略与基线实验TDNN-FSMN训练参数设置保持一致。
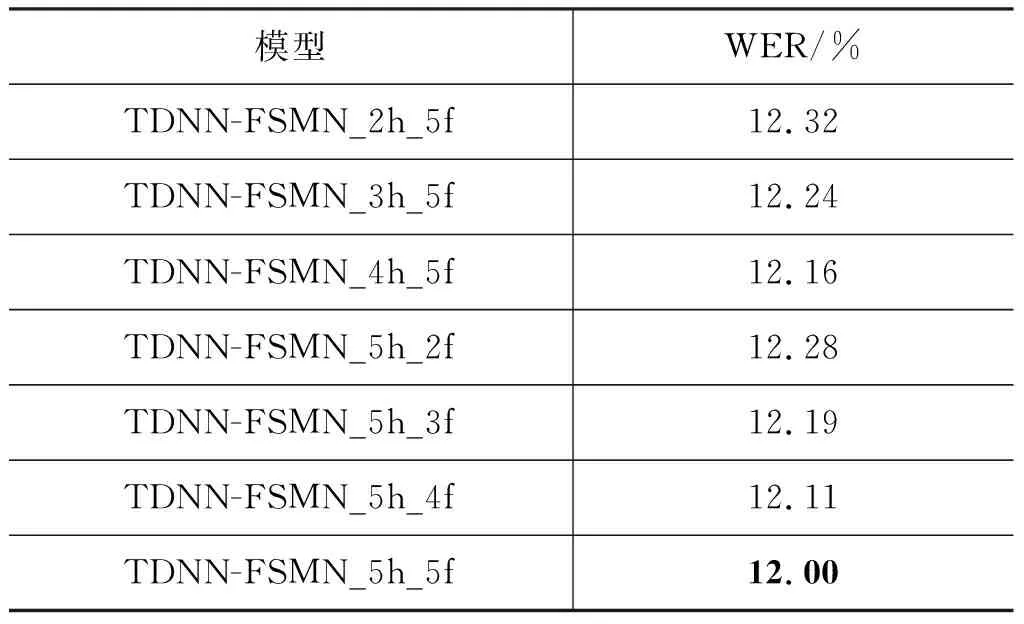
表2 FSMN隐藏层不同结构对比实验结果
从表2的实验结果可以看出,“记忆”模块中包含5帧历史信息和5帧未来信息,表现出的性能最优。这是因为“记忆”模块包含历史信息帧和未来信息帧的数量增加,将使TDNN-FSMN在训练过程中可以获得更多固定长度的时间上下文关联信息。而且,“记忆”模块中包含相同数量帧时,包含较多数量的历史信息帧比包含较多数量的未来信息帧表现得性能更优,表明上下文相关的历史信息对网络的性能更加有利。
3.3 TDNN-FSMN不同结构的对比实验
在本实验中,分别对TDNN-FSMN中包含隐藏层的个数和隐藏层的节点数进行对比实验,其中FSMN隐藏层中“记忆”模块包含5帧历史信息和5帧未来信息。实验中分别设置隐藏层个数为6、9和12,每个隐藏层分别包含256、512和1 024个节点。当隐藏层个数为6时,第2、4和5层为FSMN隐藏层;当隐藏层个数为9时,第3、6和9层为FSMN隐藏层;当隐藏层个数为12时,第4、8和12层为FSMN隐藏层。其余层均为TDNN隐藏层,其配置信息如表3所示,第一列表示隐藏层中使用到的降采样节点配置信息,第二列表示每个隐藏层中使用第一列的信息。例如,6-1表示神经网络包含6个隐藏层,第一个隐藏层为TDNN,降采样使用的节点数为{-2,-1,0,1,2}。使用TDNN-FSMN-6L-256c表示包含6个隐藏层,每个隐藏层包含256个节点。
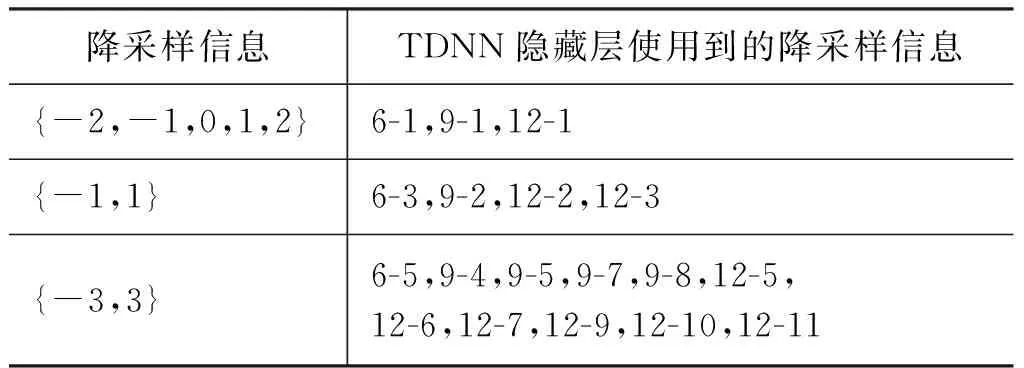
表3 TDNN 隐藏层配置信息
实验结果如图5所示,随着隐藏层个数增加及隐藏层节点数增加,单词错误率明显降低。这是因为随着层数和节点数的增加,将使TDNN-FSMN在训练过程中可以获得更多固定长度的时间上下文关联信息。最终,TDNN融合FSMN的神经网络结构在蒙古语语音识别声学模型中比最优的基线DNN模型有很大的性能提升。其中使用TDNN-FSMN-12L-1024c网络结构得到的实验结果最好,单词错误率为10.03%,与基线DNN模型相比相对降低22.2%,表明TDNN-FSMN能有效提升蒙古语语音识别的性能。然而,TDNN-FSMN-6L-256c网络结构识别准确率较基线DNN模型有所降低,由于参数规模降低,会使得TDNN-FSMN在训练过程中无法学习到足够的声学信息进而降低了声学模型的性能。
4 总结
本文首次将融合的TDNN-FSMN模型应用于蒙古语语音识别中,实验结果表明,TDNN-FSMN可以获得比DNN更好的性能。在不同结构FSMN隐藏层中,“记忆”模块包含5帧历史信息和5帧未来信息表现得性能最优,单词错误率较基线DNN模型相对降低7.0%。此外,通过对TDNN-FSMN中包含隐藏层的个数和隐藏层的节点数进行对比实验,发现随着层数和节点数的增加,TDNN-FSMN的性能明显提升,表明TDNN-FSMN在训练过程中可以获得更多固定长度的时间上下文关联信息。最终,包含12个隐藏层且每个隐藏层包含1 024个节点得到的实验结果最优,相比基线DNN模型,单词错误率相对降低22.2%。最终蒙古语语音识别系统词错误率达到了10.03%,表明基于TDNN-FSMN神经网络结构能有效地提升蒙古语语音识别性能。
