面向中文网络评论情感分类的集成学习框架
2018-10-19黄佳锋刘志煌黄英仁李万理
黄佳锋,薛 云,2,卢 昕,刘志煌,吴 威,黄英仁,李万理,陈 鑫,3
(1. 华南师范大学 物理与电信工程学院,广东 广州 510006;2. 广东省数据科学工程技术研究中心,广东 广州 510006;3. 深圳职业技术学院 工业中心,广东 深圳 518055)
0 引言
随着电子商务行业的发展,产生了大量的网络评论文本数据。面对这些海量的网络评论,消费者需要快速了解评论的情感倾向,优化自己的购买决策,而商家也需要从消费者的网络评论情感倾向中总结得到商品的市场反馈信息,对商品进行改善。因此,如何对评论文本进行情感分类已经成为自然语言处理领域的一个重要研究课题。
文本情感分类常用的技术分为基于规则的方法和基于统计的方法。但是基于规则的方法所描述的语言规则非常有限,难以处理复杂的、非结构化的中文网络评论文本[1];而基于统计的方法一般很难通过单个算法构造一个高准确率的分类模型,即某些模型可能只对一类或几类问题有效,而在其他问题上的效果不好,泛化能力差。为了改善这些缺陷,集成学习技术应运而生,并在文本情感分类任务上验证了集成学习的有效性[2]。
但是在针对中文网络评论文本的情感分类任务上,目前还存在以下三个挑战: 第一,中文网络评论具有表达多样化、句子长度不一致的特点,在特征提取时,以TF-IDF为代表的单词权重计算方法[3-4],容易造成文本特征语义信息缺失、特征向量稀疏等问题。第二,由于中文网络评论文本的复杂性,从中提取到的特征通常达到上千个,经典的Random Subspace集成学习方法[5]虽然可以解决特征繁多问题,但是由于特征子空间是完全随机抽取的,难以保证基分类器的性能。第三,一个评论文本很可能包含多个产品属性词语,这些属性共同决定着评论的情感倾向,以往的句子级情感分类方法通常把评论中的所有属性都当成一个整体,没有单独分析每个属性带有的情感信息,容易造成情感类别误判。
针对上述问题,本文提出一种针对中文网络评论进行情感分类的集成学习框架,主要包括以下部分: ①采用词性组合模式、频繁词序列模式和保序子矩阵模式作为输入特征,使得特征携带更完整的语义信息和情感信息,并且利用语义相似度克服了特征向量稀疏的问题; ②基于信息增益的随机子空间算法,解决了评论文本复杂多样而造成的特征繁多的问题,并且根据重要度权值抽取特征子空间,尽量提高基分类器的分类性能; ③基于产品属性构造基分类器算法,考虑不同产品属性对应不完全相同的特征集合、相同的特征在不同产品属性中可能产生的不同影响,使得最终的分类结果更加精确。文中的框架利用多种分类器在ChnSentiCorp-Htl-ba-4000中文酒店评论数据集[6]上进行对比实验,结果表明该框架在情感分类任务中能达到更优的分类效果。
本文的内容安排如下: 第一部分介绍情感分类和集成学习的相关工作;第二部分介绍本文提出的框架具体内容;第三部分介绍本文提出的框架和其他经典方法的对比实验;第四部分给出结论。
1 相关工作
文本情感分类任务的目标是识别主观文本的情感极性,即正面(positive)的赞赏和肯定、负面(negative)的批评与否定[7]。目前公认的情感分类研究工作始于Bo Pang等人[8]的工作,该方法以unigram等作为输入特征,用朴素贝叶斯、最大熵、支持向量机等分类算法实现电影评论的情感分析,取得了较好的分类效果。目前主流的文本情感分类方法仍然是机器学习中的有监督学习方法,这种方法的关键步骤是特征提取和分类器设计。
在针对中文网络评论的情感分类任务中,文本的特征提取和表示是关键步骤之一。Salton等人[9]提出了基于词频和逆文档频率的句向量表示方法,即TF-IDF方法。这种方法通常需要利用情感词库来筛选特征词,然后用TF-IDF计算特征权重,已被广泛应用于自然语言处理领域。随着深度学习研究的兴起,文本特征抽取和表示的研究聚焦在词嵌入模型(word embedding)[10-11],这种方法使用原始语料训练得到词语的分散式表示(distributed representation),优点是可以用稠密、低维、连续的向量来表示词语,并且语义相近的词语在词向量空间中彼此的位置也很靠近,即可通过词向量的距离来衡量词语的语义相似性。
另外,分类器设计也是文本情感分类任务的重要环节之一,机器学习中的BP神经网络、K最近邻、支持向量机等分类算法被广泛应用到情感分类任务中[12]。为了提高文本情感分类的准确率,一些学者开始使用集成学习技术来融合不同的分类模型。集成学习可以组合多个精确度一般的分类模型,利用单个模型之间的差异性,来改善模型的泛化性能,提高分类的精确度。近年来,在文本情感分类、数据挖掘、模式识别等众多领域的研究表明,大多数通过集成学习得到的模型要明显优于单个模型[13]。根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即以Boosting为代表的个体学习器间存在强依赖关系、必须串行生成的序列化方法,和以Bagging和Random Subspace为代表的个体学习器间不存在强依赖关系、可同时生成的并行化方法。Wang Gang等人[14]基于五种基分类器,使用了三种经典集成学习方法,在十个公共情感分类数据集上,进行了大量对比实验。实验结果表明,在情感分类任务上,集成学习方法大大地提高了单个基分类器的性能。Deriu等人[15]利用大规模的Twitter微博文本数据进行弱监督学习,训练两个结构相同、参数和输入不同的卷积神经网络,然后将卷积神经网络的输出作为随机森林元分类器的输入,通过集成学习得到Twitter微博文本的情感极性,该方法在Semeval-2016任务4的评测中获得了第一名的好成绩。
在复杂多样的中文网络评论中,评论的整体情感倾向通常需要综合消费者对评论中全部产品属性的意见,而且在情感分类任务中不同的产品属性对应的特征集合通常不会完全相同。因此,本文在对中文网络评论进行情感分类时,首先提取评论中的产品属性,然后再基于产品属性对评论语料和对应特征集合做进一步划分,并基于各属性对应的评论语料和特征集合分别训练分类器,最后再结合评论中每个产品属性各自对应的情感分类概率,得到整条评论的句子级情感倾向。
2 本文框架
2.1 特征工程
在以往基于情感词典和TF-IDF的特征提取、向量化方法中,情感词典往往不能覆盖语料中的所有情感特征。另一方面,中文网络评论具有表达多样化、句子长度不一致的特点。因此,采用传统的TF-IDF方法提取特征,容易造成文本特征语义信息缺失、特征向量稀疏等问题。下文将阐述本文框架中三种特征提取方法,以解决上述问题。
2.1.1 词性组合模式
在很多文本情感分类中,通常是将单个词语作为分类特征,再根据TF、TF-IDF等方法生成评论的特征向量。但在处理中文评论的情感分类问题时,该方法存在着以下不足之处: 第一,在中文网络评论中,该类方法不能刻画词语之间的语序信息;第二,在描述不同上下文语境时,同一情感词有时可以表达不同的情感倾向,例如,词组“水平高”和“价格 高”中的词语“高”分别表达着积极和消极的情感倾向。
为了解决上述问题,本文把连续词组作为分类特征,使得特征能携带更准确的情感信息。另外,在中文网络评论中,大部分评论者通常使用形容词来表达自己的主观情感。因此,在第一种特征提取方法中,本文通过词性组合模式来挖掘连续词组特征。本文参考了文献[16],并结合中文网络评论的特点,总结归纳了八种词性组合规则如表1所示,其中词语的词性表示参考中科院计算所汉语词性标记集。

表1 词性组合规则
综上所述,本文首先对语料进行分词和词性标注,然后通过词性组合规则挖掘得到词性组合模式feature_pos,将其作为情感分类任务的输入特征之一。
2.1.2 频繁词序列模式
面对表达口语化的中文网络评论时,词性组合模式存在一定不足: 一方面它依赖于先验的语言学知识,必须事先由专家设定足够多的规则;另一方面,词性组合模式没有考虑词组特征中词语之间可能出现的间隔,例如: 词组“交通 方便”和“交通 路线 方便”,只有考虑词语之间的间隔,才能提取出同样的特征“交通 方便”。因此,本文根据频繁序列模式和中文语言的特点,基于Matsumoto等人[17]提取频繁词语子序列的思想,进行了相应的改进。对于一个频繁词序列模式p={w1,w2,…,wm},其中wi为短语p中的词语,m为短语p的词语个数,它的定义描述如下:
(1)p在训练集语料中的支持度必须大于最小支持度阈值,即sup(p)≥min_sup;
(2)p中任意两个相邻词语wi和wi+1在评论中可以不连续,但是一定要在评论中按照先后顺序出现;
(3)p中相邻两个词语在评论中的最大间隔必须小于间隔阈值max_gap,即p中任意两个相邻词语wi和wi+1在评论中的间隔gap(i)≤max_gap;
(4)p的区分度必须大于最小区分度阈值,即dist(p)≥min_dist,区分度dist(p)计算如式(1)所示。
(1)
其中,n为情感分类任务中的情感倾向类别数目,supi(p)为p在训练集第i类语料中的支持度,sup(p)则为p在整个训练集语料中的总支持度。
根据上述定义,本文采用了Pei等人[18]提出的PrefixSpan算法来挖掘频繁词序列模式feature_freseq,作为情感分类任务的输入特征之一。
2.1.3 保序子矩阵模式
在中文网络评论中存在着以下两个特点: 第一,评论的表达多样化,即不同词汇表达相近语义;第二,评论的长度通常不一致,评论包含的词语数量相差较大。由于这些特点,TF-IDF特征提取方法容易造成特征向量稀疏、不同评论之间权重相差较大等问题。因此,为了解决以上问题,本文结合基于词嵌入的近义词和保序子矩阵算法对该方法进行了改进。
(1) 基于词嵌入的近义词
本文对词语进行相似度计算,把语义相近的词语当成一个词语处理,从而克服传统TF-IDF向量的稀疏性问题。本文采用Word2Vec[11]训练中文大语料,得到评论语料的词嵌入矩阵We∈d×|V|,其中We的每一列代表一个词向量。假设Xi和Xj是We中两个词向量,用余弦距离来衡量词向量之间的相似性,计算如式(2)所示。
(2)
设定实验参数相似度阈值SimT,如果Sim(i,j)≥SimT,则表示Xi和Xj对应的词语是近义词。接下来把近义词都归并成同一个簇,根据簇来计算TF-IDF向量,得到评论语料的矩阵表示Wtfidf,计算如式(3)所示。
(3)
其中,N表示语料库中的评论总数;tfij表示近义词频,即在评论j中第i个簇中词语出现的次数;dfi表示近义词文档频率,即语料库中含有第i个簇中词语的评论个数。
(2) 保序子矩阵
由于网络评论通常长度不一,假如直接使用Wtfidf进行分类的话,一方面会造成语义相近但句子长度差别很大的两个评论向量之间的距离较大,对情感分类任务产生负面影响;另一方面Wtfidf中的特征是独立的词语,无法体现词语之间的语义相互作用。为了解决这个问题,本文采用双聚类中的保序子矩阵算法来挖掘Wtfidf中的保序子矩阵模式。
本文参考了Liu Zhiwen和Xue Yun等人[19]提出的方法,利用公共子序列挖掘得到Wtfidf的全部保序子矩阵模式,输出满足最小列阈值min_column和最小行阈值min_row要求,并且各行都来自于同一类情感标签评论的保序子矩阵模式feature_opsm,并连同上文得到的词性组合模式feature_pos和频繁词序列模式feature_freseq,一起作为情感分类任务的输入特征。
2.2 基于信息增益的随机子空间
由于中文网络评论文本的多样性和复杂性,经过上文三种特征提取方法得到有效的分类特征后,特征数目通常会达到上千个,如果直接使用的话,容易造成特征向量稀疏,导致分类效果不佳。因此本文借鉴了Ho等人提出的随机子空间算法[5]。该方法是一种基于特征多样性的集成学习方法,首先从原始特征空间中随机抽取出若干个特征子集,然后基于每个特征子集训练一个基分类器,最后集成所有基分类器的结果,得到最终的分类结果。但是在复杂多样的评论文本中,不同特征对分类的贡献是不一样的,假如随机抽取的特征子集都是一些相对冗余、不太重要的特征,将会严重影响基分类器的分类性能,从而影响最终的分类结果。为此,本文提出了一种基于信息增益的随机子空间算法,在保证基分类器间独立性的同时,尽量提高基分类器的分类性能。
基于信息增益的随机子空间算法具体描述如算法1所示。
2.3 基于产品属性构造基分类器
在中文网络评论中,评论的整体情感倾向通常需要综合消费者对评论中全部产品属性的意见,而且不同的产品属性在情感分类任务中对应的特征集合不完全相同,即使是相同的特征,它们在不同的产品属性中也可能蕴涵着不同的语义信息,因此本文采用基于产品属性构造对应基分类器的算法对评论进行情感分类。
算法1基于信息增益的随机子空间算法

2.3.1 产品属性提取
在本文框架中,采用基于类序列规则的方法来提取产品属性集合,并利用词语相似度将产品属性划分到不同的属性类别中。
(1) 基于类序列规则的产品属性提取
序列模式挖掘是数据挖掘中一个重要的分支,而类序列规则(class sequence rules,CSR)是传统序列模式挖掘的变种,它在序列模式挖掘的基础上考虑了类信息,通过将模式和类信息结合起来,找到与类信息具有高度相关性的序列模式。
为了提取出中文网络评论中的产品属性,本文参考了文献[20]中观点特征抽取的思想,采用基于类序列规则的方法提取产品属性,即将训练集中已知的属性词和情感词搭配信息作为类序列规则中的类信息,将词性搭配作为被挖掘的序列模式,利用类序列规则提取评论中的产品属性。
本文以酒店领域为背景,从大众点评网站上爬取了十万多条酒店领域中文网络评论作为实验语料。具体地,首先将中文网络评论语料进行预处理、中文分词和词性标注等操作后,得到序列标注的结果,并预先给定少数的属性词和情感词作为种子词,在评论语料中标注这些种子词,使得少数样本带有类信息。然后去掉词语,只保留词性和类信息,得到带有类信息的词性序列。再通过改进的PrefixSpan算法来挖掘这些带有类信息的词性序列,本文在PrefixSpan频繁序列模式挖掘算法的基础上进行改进,加入由类信息所决定的置信度,得到满足最小支持度和最小置信度的频繁序列模式,同时筛选得出所有元素都在评论中同一分句的模式,作为提取产品属性的词性搭配规则。最后将语料中所有满足词性搭配规则的属性词提取出来,得到属性词语集合。基于类序列规则的产品属性提取算法如算法2所示。
(2) 产品属性类别划分
通过基于类序列规则的产品属性提取算法得到产品属性词语集合后,还需要将产品属性集合划分成若干个类别。本文首先确定产品属性类别基准词,然后再通过每个属性词语与基准词的语义相似度来划分该属性词语所属的类别。
算法2基于类序列规则的产品属性提取算法

通过对酒店语料和产品属性集合的观察,本文归纳得到“服务”“美食”“环境”“价格”“设施”“场馆”这六个属性类别基准词。接下来,同样采用Word2Vec对语料进行训练,得到产品属性集合的词嵌入矩阵W∈d×|A|,并采用余弦距离来衡量各属性词向量和属性类别基准词向量之间的语义相似度。然后设定实验超参数最小相似度min_Sim,如果属性词与多个属性类别基准词之间的相似度大于min_Sim,则选取与该属性词的相似度最大的属性类别基准词作为属性类别标记;如果属性词语全部六个属性类别基准词之间的相似度都小于min_Sim,则将该属性词的属性类别归类为“其他”。最终将属性词集合划分为七个属性类别,分别为“服务”“美食”“环境”“价格”“设施”“场馆”“其他”。
2.3.2 基于产品属性构造基分类器
在中文网络评论中,评论者对产品意见的表达多种多样。而对于一个较长的评论,不能只通过其中某一个产品属性来判别它的情感类别。另外,相同的特征对于不同的属性可能起到相反的作用。为了解决上述两个问题,本文采用基于产品属性构造基分类器的算法对评论进行集成情感分类。一方面,根据上文得到的属性类别将评论数据和特征集合进行划分,使得不同属性类别对应各自的特征集合,而且相同的特征可以在不同的属性类别中起到不同的情感表达作用;另一方面,将根据属性类别划分好的评论数据和特征集合分别进行训练得到基分类器,然后集成不同的基分类器来判别整个评论的情感倾向,使得分类器在判别评论的情感倾向时,能够综合评论中全部属性的情感信息。基于产品属性构造基分类器的算法具体描述如算法3所示。
算法3基于产品属性构造基分类器的算法

3 实验
实验部分将对数据集、实验流程、实验结果和分析进行详细介绍,实验的主要内容是采用本文的框架和评测数据集实现中文网络评论情感分类任务,并和其他相关方法进行分析比较。
3.1 数据集
为了验证文本所提框架的有效性,本文使用了中文情感语料库ChnSentiCorp[6]中的中文酒店评论数据集ChnSentiCorp-Htl-ba-4000作为实验评测数据,数据集包括2 000个积极情感评论文本和2 000个消极情感评论文本,过滤掉重复评论文本后,剩余共3 147个评论文本。另外,本文在大众点评网站上爬取了102 268个酒店评论文本,作为提取酒店领域产品属性的评论语料。在基于词嵌入的近义词、产品属性类别划分中,采用Sogou新闻语料[21]和大众点评酒店评论语料作为Word2Vec训练语料,语料大小为2.02GB。
3.2 中文分词和词性标注
在数据预处理中,本文采用中科院ICTCLAS[22]对评论文本进行中文分词和词性标注。
3.3 实验流程介绍
根据文中的集成学习框架,本文实现对中文网络评论的两类情感分类。在情感分类实验中本文采用五折交叉验证,语料的训练集、验证集和测试集比例为3∶1∶1,其中积极语料和消极语料数目基本平衡。实验流程如图1所示。

图1 实验流程
在上述实验的集成学习框架中,采用机器学习常见的分类算法作为基分类器中的分类算法,包括Logistics Regression(LR),Decision Tree(DT),Support Vector Machine(SVM)这三种分类算法。
另外,本文的实验框架存在一些超参数,如基于信息增益的随机子空间算法中的特征子空间数目S,对于这些超参数的确定,本文使用控制变量法进行调参。在确定某个超参数时,首先设置一组该超参数的值,然后保持其他超参数不变,通过验证集在实验中的平均分类准确率确定最优值。
下面介绍频繁词序列模式中三个超参数对实验结果的影响变化趋势。
由图2看出,当min_sup=30时,实验的平均准确率达到最优值。

图2 平均分类准确率随最小支持度的变化趋势
由图3看出,当max_ gap=1时,实验的平均准确率达到最优值。
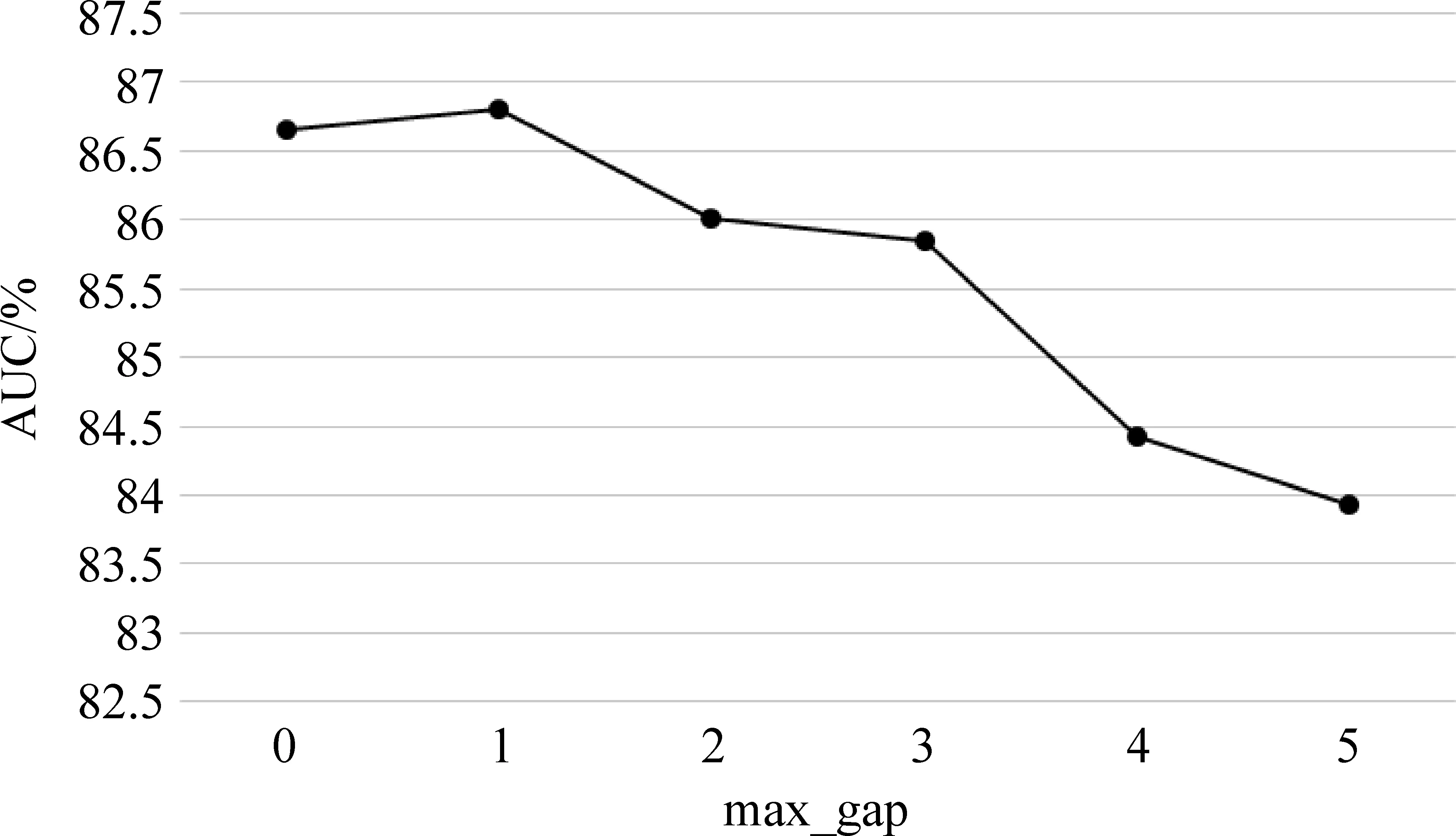
图3 平均分类准确率随最大间隔阈值的变化趋势
由图4看出,当min_dist=0.65时,实验的平均准确率达到最优值。
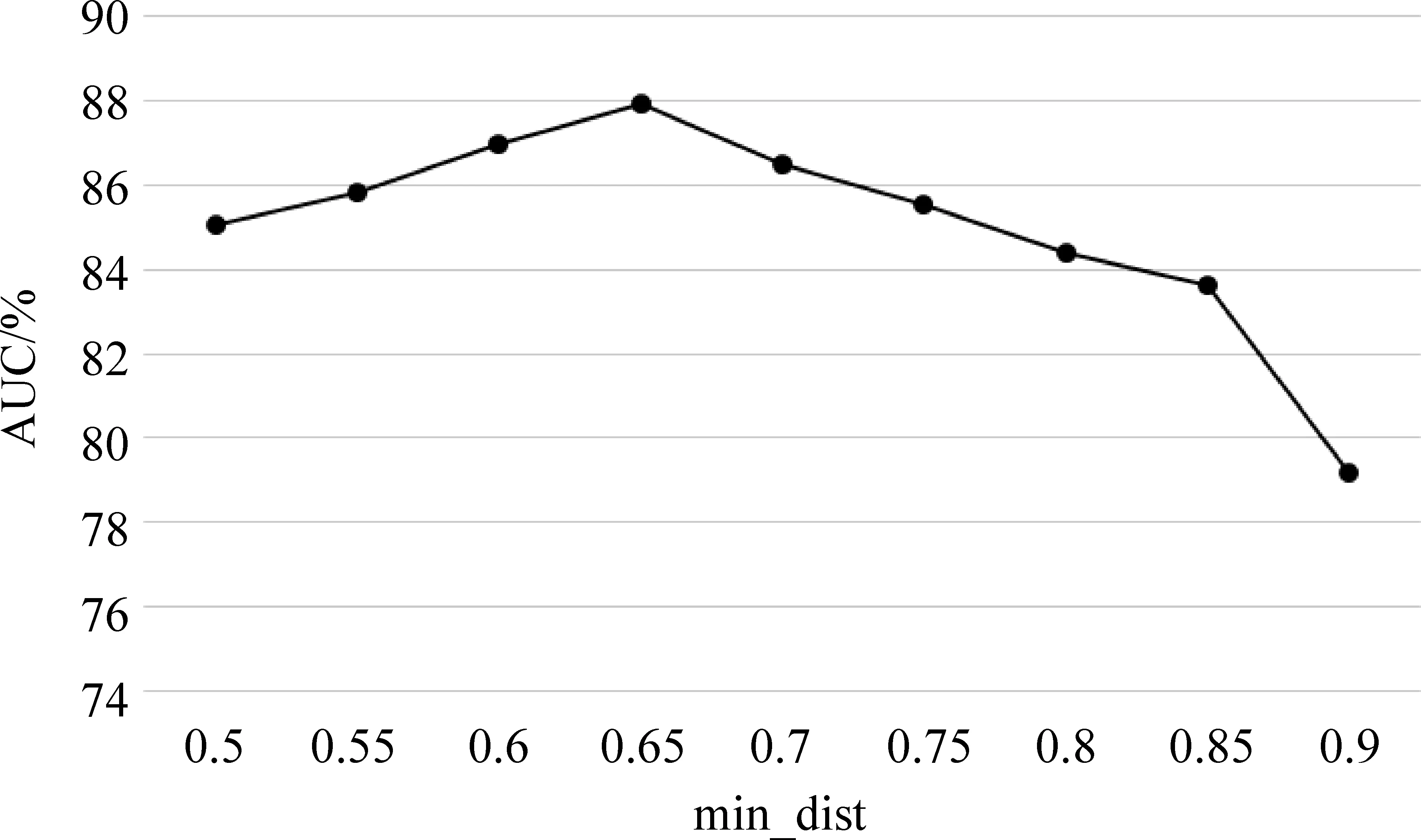
图4 平均分类准确率随最小区分度阈值的变化趋势
由于超参数较多,本文只分析了上述三个超参数对实验结果的影响。最终得到的最优超参数值如表2所示。

表2 最优超参数值
在下文的实验结果中,超参数按照实验得到的最优值进行设置。
3.4 实验结果及分析
本文在实验方案中设置了三组对比实验,第一组将本文的方法和单分类器进行对比,单分类器分别采用不同的输入特征向量;第二组将本文的方法和经典集成学习分类算法进行对比;第三组将本文和深度学习算法进行对比。本文采用了Scikit-Learn[23]、WEKA[24]和Tensorflow[25]来实现方案中的对比实验,参数统一取默认值。实验使用文本情感分类领域常用的评价指标: 平均分类准确率(Average Accuracy),其计算如式(4)所示。
(4)
第一组对比实验将不同输入特征向量的单分类器和本文的方法进行对比,实验结果如表3所示,其中不同的输入特征向量分别如下:
(1) “lexicon+TF-IDF”: 表示输入特征是基于情感词典提取的词语,再使用TF-IDF方法对评论文本进行向量化;
(2) “Word2Vec”: 表示采用Word2Vec对评论语料进行训练,得到词向量,再将词向量相加求平均得到评论的输入特征向量;
(3) “pos+freseq+opsm”: 表示将文中提到的三种特征进行合并,再根据特征是否在评论中出现生成0/1输入特征向量。
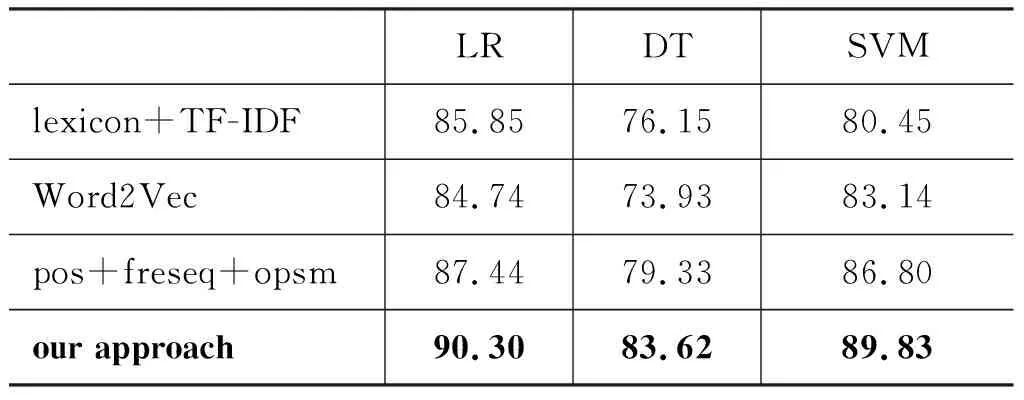
表3 和单分类器的实验对比结果(%)
第二组对比实验将不同的经典集成学习算法和本文的方法进行对比,集成学习算法包括Bagging、Boosting、Random Subspace,“Random Subspace_IG”代表基于信息增益的随机子空间算法,输入特征向量采用“pos+freseq+opsm”形式,实验结果如表4所示。

表4 和集成分类器的实验对比结果(%)
第三组对比实验将三种深度学习算法和本文的方法进行对比,深度学习算法包括Recurrent Neural Networks(RNN)、Long Short-Term Memory(LSTM)、Gated Rucurrent Unit(GRU),“our approach(LR)”代表本文框架在LR基分类器算法上的分类准确率,实验结果如表5所示。

表5 和深度学习算法的实验对比结果(%)
综合表3、表4和表5的实验结果可以看出: ①在单分类器实验中,“pos+freseq+opsm”的分类准确率均高于“lexicon+TF-IDF”和“Word2Vec”,主要是因为前者采用三种特征模式作为输入特征,考虑了句子语序信息、句子长度大小的影响、间隔词组特征等因素,并且利用语义相似度克服了“lexicon+TF-IDF”的特征向量稀疏问题; ②Random Subspace的情感分类准确率均高于单分类器实验中的“pos+freseq+opsm”,主要原因是“pos+freseq+opsm”将feature_pos、feature_freseq和feature_opsm三种特征模式简单地进行合并,造成特征向量非常稀疏,而Random Subspace则采用随机划分特征子空间的方法解决了特征稀疏问题; ③“Random Subspace_IG”的情感分类准确率稍高于经典的Random Subspace,主要原因是“Random Subspace_IG”在Random Subspace基础上考虑了特征的重要度权值,根据重要度权值抽取特征子空间,在保证基分类器之间独立性的同时,尽量提高基分类器的分类性能; ④本文方法的实验效果均好于三种经典集成分类算法和“Random Subspace_IG”,特别是在LR分类算法上达到了90.3%的平均分类准确率,主要原因是本文方法考虑了不同产品属性对应不完全相同的特征集合、相同的特征在不同产品属性中可能起到的不同作用,并且综合了评论文本中不同产品属性的输出分类概率,使得最终的分类结果更加精确; ⑤本文方法在情感分类任务上的准确率比三种深度学习算法高,主要原因是本文方法考虑了更多中文评论语义信息和评论中不同产品属性的情感信息。
4 结论及未来工作
本文提出了一种针对中文网络评论情感分析任务的集成学习框架,该框架主要包含三个部分: 第一,采用词性组合模式、频繁词序列模式和保序子矩阵模式作为输入特征,使得特征携带更完整的语义信息和情感信息,并且利用语义相似度克服了特征向量稀疏问题;第二,采用基于信息增益的随机子空间算法,解决了评论文本复杂多样而造成的特征繁多问题,并且在保证基分类器之间独立性的同时能尽量提高基分类器的分类性能;第三,采用基于产品属性构造基分类器的算法,考虑不同产品属性对应不完全相同的特征集合、相同的特征在不同产品属性中可能起到的不同作用,并且综合了评论文本中不同产品属性的情感分类概率,使得最终的分类结果更加精确。实验结果证明本文的框架和不同特征输入的单分类器、经典的集成学习方法、一些深度学习方法相比,均可以获得更好的情感分类效果。
在针对中文网络评论的情感分类任务方面,未来还有很多工作需要深入研究。在随机子空间算法中,利用中文语言学知识来选取特征子空间是一个可行的研究方向。另外,结合神经网络中的注意力机制,更加细致地分析不同产品属性与特征对评论情感分类的影响,也是今后的重点研究工作之一。
