基于多策略的乌孜别克语名词词干识别研究
2018-10-19艾孜海尔江祖力克尔江艾孜尔古丽玉素甫艾白都拉
艾孜海尔江,祖力克尔江,艾孜尔古丽,玉素甫·艾白都拉
(1. 新疆师范大学 计算机科学技术学院,新疆 乌鲁木齐 830054;2. 新疆师范大学 文学院,新疆 乌鲁木齐 830054)
0 引言
2013年中国国家主席习近平提出了包括“丝绸之路经济带”和“21世纪海上丝绸之路”的一带一路战略。从此中国成为与新疆接壤的部分中亚国家最主要的贸易伙伴,并相继成为哈萨克斯坦、乌兹别克斯坦、吉尔吉斯斯坦和塔吉克斯坦的第二大贸易伙伴。随着中乌两国政治、经济文化交流的发展,汉语和乌孜别克语之间交流频繁,这两种语言交流的重要性日益凸显。乌孜别克语自然语言处理技术和汉—乌机器翻译的实现对“一带一路”战略的实现发挥着重要的作用。
乌孜别克语属黏着性语言,在词法结构上与维吾尔语相比存在着一定的区别。帕提古丽、玉素甫等人深入研究乌孜别克语中的语音变化现象,并提出音变现象的自动还原模型。该文分析乌孜别克语中发生语音变化的词干本身的特征,设计音变现象的还原模型,并结合词干库配对方法来实现自动还原[1]。祖日古丽、玉素甫等人对乌孜别克语的音节结构进行分析,在前者的研究基础上,归纳了乌孜别克语词汇的音节变化规律[2]。阿西穆·托合提提出了基于词典和规则相结合的维吾尔语和乌孜别克语机器翻译方法[3]。文献[4]利用维吾尔语和乌孜别克语之间的这种相似关系,设计并实现了乌孜别克语-维吾尔语双语语料库构建平台。
本文构建一定规模的乌孜别克语西里尔文生语料库,将其转换为对应的拉丁文,结合乌孜别克语词法特征,提出基于多策略的乌孜别克语名词标注方法,研究一种融合乌孜别克语形态特征的最大熵名词标注模型。乌孜别克语名词识别技术可以广泛应用于乌孜别克语名词短语分析、词性标注、机器翻译等领域,并且能部分消解歧义。乌孜别克语信息化研究,对“一带一路”战略语言服务提供技术、方法及数据支持,具有一定的研究和应用价值。
1 乌孜别克语名词词干提取研究
1.1 乌孜别克语名词形态分析研究
乌孜别克语共有29个字母,其中6个元音字母、23个辅音字母。
乌孜别克语元音字母如表1所示。
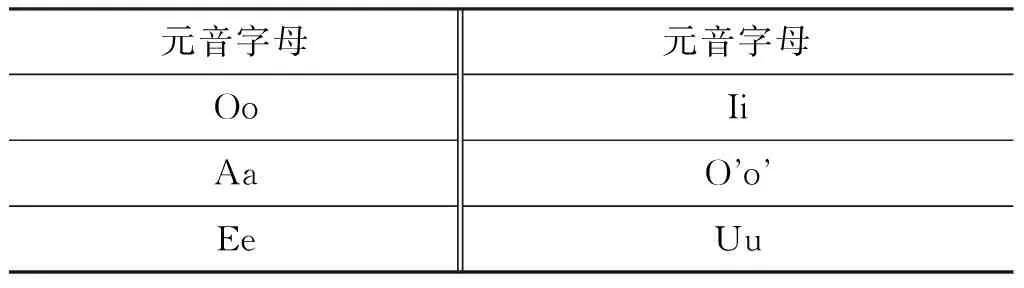
表1 乌孜别克语元音字母
乌孜别克语辅音字母如表2所示。
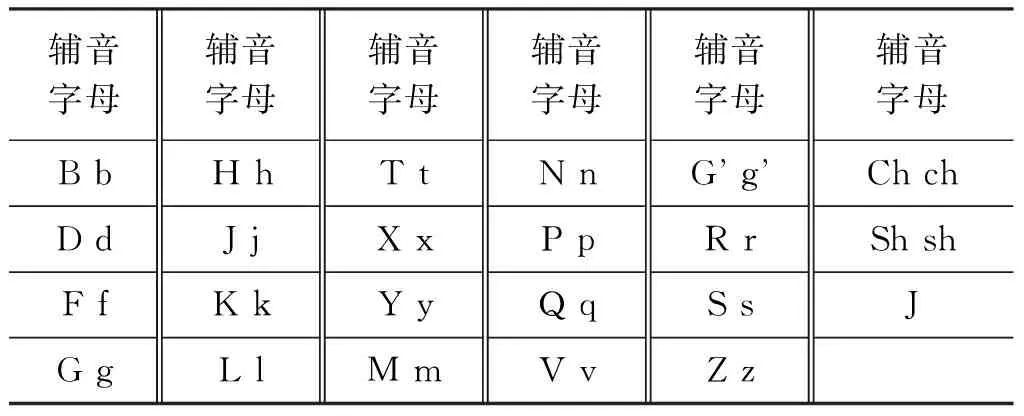
表2 乌孜别克语辅音字母
1.2 乌孜别克语音节研究
乌孜别克语词由若干个音节组成。音节是人的听觉能够自然感受到的最小语音片段。以元音字母结尾的音节叫做开音节,如u(他)、o-na(母亲)、do-i-ra(范围)。以辅音字母结尾的音节叫做闭音节,如biz(我们),aql(智慧),gul(花)。
词由一个或多个语音组成,每个音节由元音或元音与辅音字母组成。字母组合次序不同,导致音节结构也不同。乌孜别克语具有九种类型的音节结构。在音节结构中“V”表示元音字母,“C”表示辅音字母,音节类型如表3所示。

表3 音节结构类型
前六种乌孜别克语音节表示基本音节结构,后三种是借用外来词描述的音节结构。
1.3 乌孜别克语词分类
乌孜别克语词法包括词的构成、形态变化和词的分类等内容,语法学中主要研究词的形态变化。乌孜别克语和维吾尔语都是黏着性语言,具有较为复杂的形态变化。
乌孜别克语词分为虚词、实词、模拟词、叹词等四大类。实词包括形容词、名词、动词、数词、副词、代词,虚词包括连词、后置词、语气词[5]。本文主要研究对象是乌孜别克语名词,即用于表示人或事物的词类的词,如Alisher(艾力西尔),kitob(书),mushuk(猫)等。
1.4 乌孜别克语词的结构
乌孜别克语词具有“词根+词缀+词尾”的语法结构,词根、词缀和词尾的结合存在严格的次序规则,其中乌孜别克语中的词缀有改变词义的功能,词尾具有语法功能。乌孜别克语的词去除词尾后剩下的部分称为词干,因此乌孜别克语的词也是由词干和词尾构成的[6],具体构词方式如图1所示。
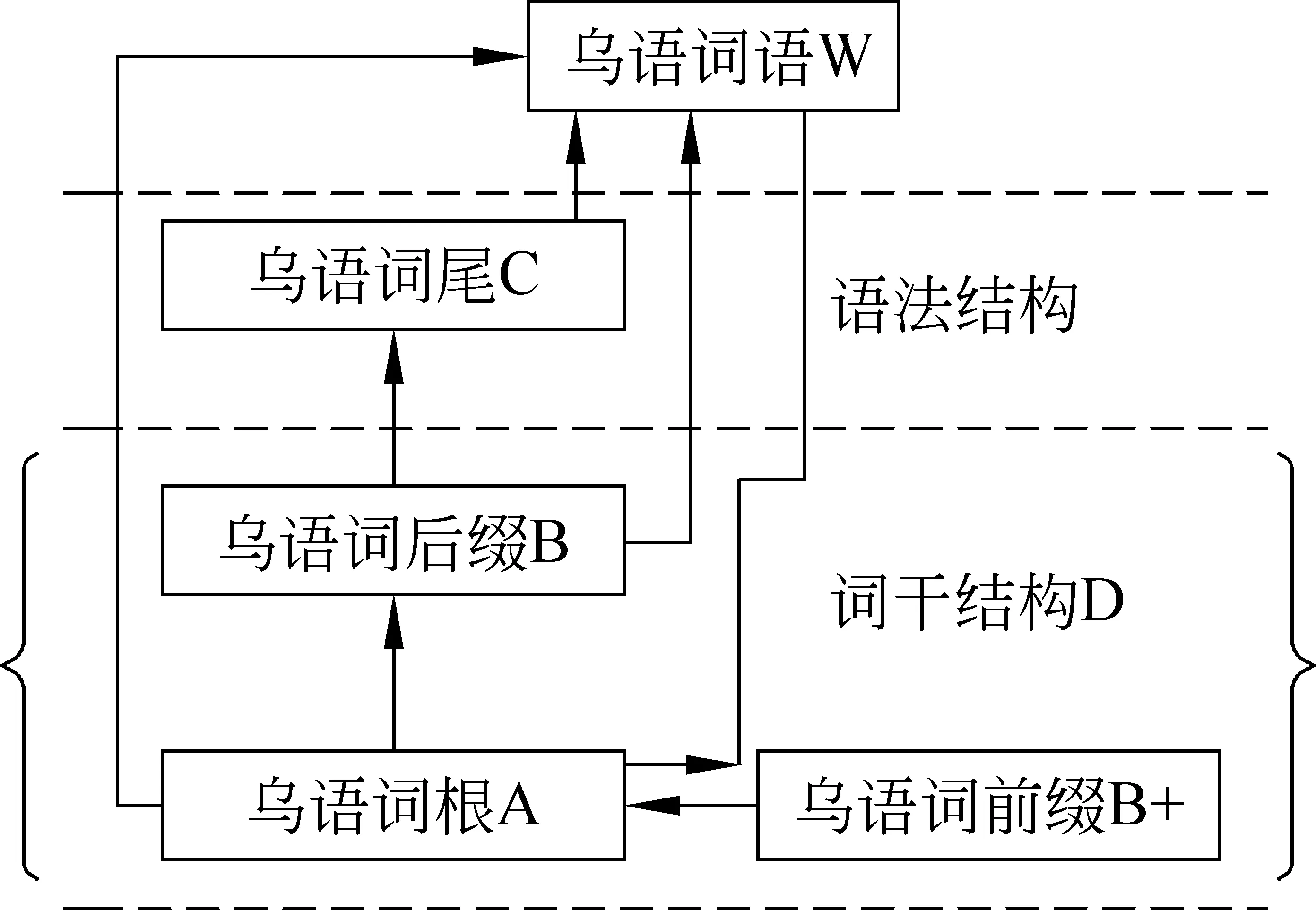
图1 乌孜别克语构词方式
图1中,A表示词根,B表示后词缀,C表示词尾,D表示词干,B+表示前词缀,W表示词语。
乌孜别克语词干的概念就是一个实词在语言应用过程中要求追加附加成分(词缀)的一种词语形式。例如,yo’linglar(你们的路) [yo’l+ing+lar ]。由此可见,对最后的复数词缀“lar”来说,词形“yo’ling(你的路)”是词干;对中间的单数第二人称词缀“ing”来说,词形“yo’l(路)”是词干。为此可以得出结论: 词干不同于词根。词根是不可再切分的语义单位,是固定的。因此,它与构形词缀没有直接关系;而词干与构形词缀是有着直接的关系。根据语言实际运用的需求,一个实词可以附加一个或两个以上的构形词缀。对词汇中的每一个构形词缀来说,该词缀前面的部分就是词干。因此,词干是非固定的。需要进一步说明的一点是,派生词对社会语言学来说是可以切分的。例如,
ish工作(名词)+chi=ishchi工人(名词)
osh饭(名词)+xona=oshxona餐厅(名词)
be (表示否定意义的前缀)+xabar消息(名词)=bexabar没有消息
乌孜别克语的格范畴有六种,即主格、属格、宾格、从格、向格、位格。为方便从计算语言学的角度处理乌孜别克语,本研究还添加了从格、止格、范围特征格、量似格、形似格。乌孜别克语名词的复数附加成分有1个、格附加成分有10个、领属附加成分有10个,总共有21个词缀。
(1) 乌孜别克语的格范畴
名词的格表示名词与句子中其他词之间的语法关系。乌孜别克语的名词有以下10种形式:
① 主格,没有词缀符号,例: Kitob(书),said(人名)。
② 属格,ning,例: kitobning(书的),ishekning(门的)。
③ 向格,ga/ka /qa,例: kitobga(向书),ishekka(向门)。
④ 宾格,ni,例: kitobni(把书),ishekni(把门)。
⑤ 位格,da,例: kitobda(在书上),ishekda(在门)。
⑥ 从格,dan,例: kitobdan(从书上),ishekdan(从门那里)。
⑦ 止格,gacha,例: kitobgacha(到书那里),ishekgacha(到门那里)。
⑧ 范围特征格,dagi,例: kitobdagi(书里的),ishekdagi(门口的)。
⑨ 形似格,dek,例: kitobdek(像书一样),ishekdek(像门一样)。
⑩ 量似格,chali,例: kitobchali(和书相同),ishekchali(和门相同)。
从上10种乌孜别克语格可见,只有向格有三个变体,其他的格只有一种变体。
(2) 名词的复数词缀
名词的复数范畴是表示人或事物跟数量的关系的语法范畴。乌孜别克语只有一种词缀,如lar(复数词缀)。
(3) 名词的领属词缀
名词的领属范畴是表示人或事物属于另一个事物的语法范畴。乌孜别克语里每个形式均有两个变体。例如,
① 第一人称:
单数,mim,例: Aka-Akam,kitob-kitobim。
复数,mizimiz,例: Akam-Akamiz,kitob-kitobimiz。
② 第二人称:
一般,nging,例: Aka-Akang,kitob-kitobing。
尊称,ngizingiz,例: Aka-Akangiz,kitob-kitobingiz。
③ 第三人称:
i-si,例: Aka-Akasi,kitob-kitobi。
1.5 基于词法分析的名词词干提取方法
乌孜别克语自身具有独特的形态特征。乌孜别克语中存在大量的构形、构词词缀,而且它们都有同形或兼类现象,在乌孜别克语中名词、动词、数词、形容词等词类具有特定的构形附加成分[5]。乌孜别克语名词识别研究主要包括乌孜别克语语料采集、词汇统计、词干提取、词性标注等关键技术与方法。
乌孜别克语的词干提取方法的设计与实现,要求掌握语言的形态变化规则和理解应用系统的需求。由于乌孜别克语的形态结构与规则不同,因此本研究采用多策略词干提取方法,其流程如图2所示。
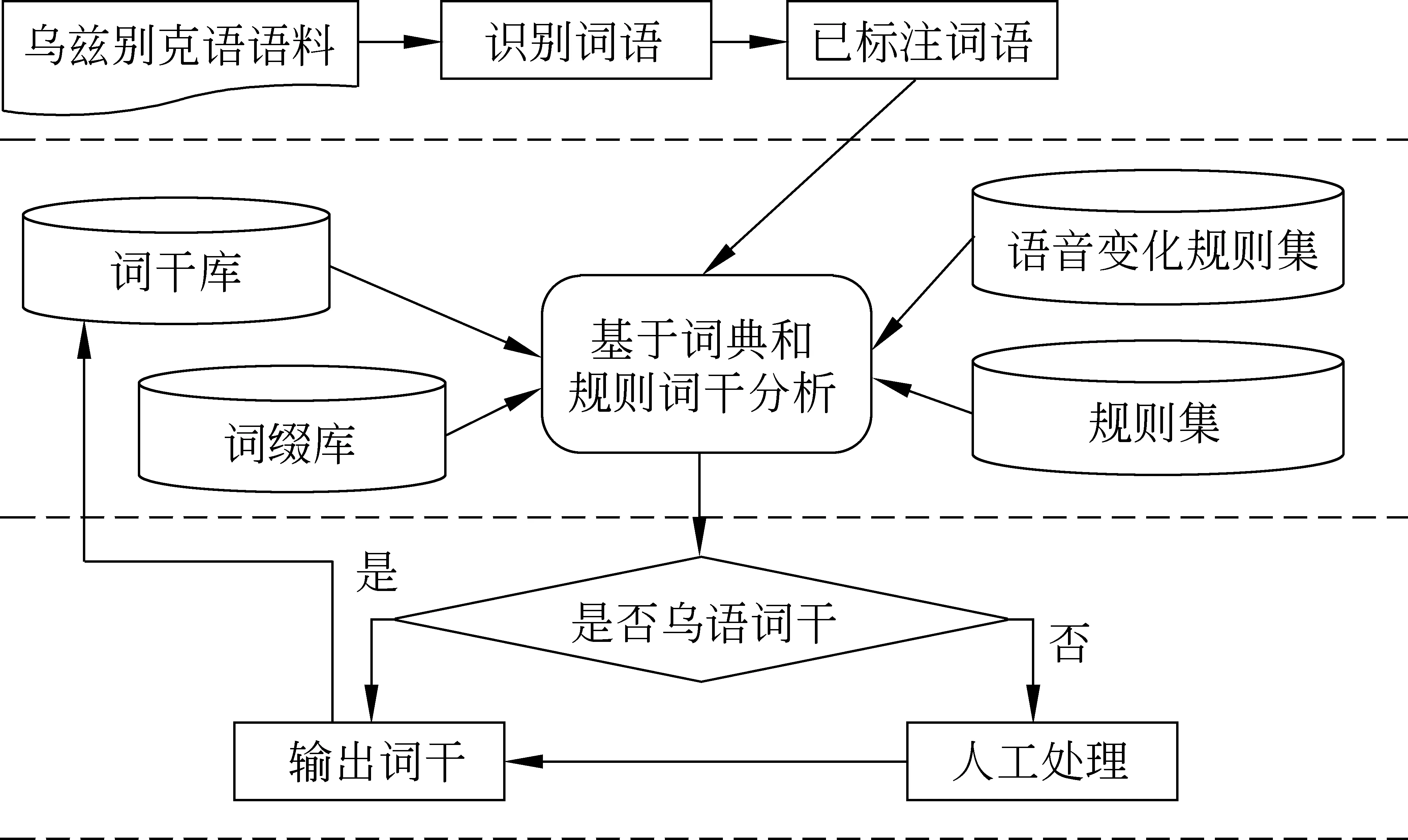
图2 多策略词干提取方法流程图
2 融合乌孜别克语形态特征的最大熵名词标注模型
熵是描述事物无序性的参数,熵越大说明事物的无序性越强。Jaynes首次提出了最大熵模型,其基本原理如下: 对所有的已知事实建模,对未知不做任何假设,也就是建模时选择一个满足约束的且熵尽可能大的概率模型。若将词性标注或者其他自然语言处理任务看作一个随机过程,最大熵模型就是从所有符合条件的分布中,选择最均匀的分布,此时熵值最大。最大熵方法通过将样本数据中的已知知识转化为特征来进行。特征可以定义为以下的二值特征函数[7]:
(1)
由最大熵理论可知,系统必须选择能够满足所有的作用在特征值上的约束,表示为式(2)。
(2)
最大熵原理的主要思想描述为: 将已知事实作为制约条件,求得可使熵最大化的概率分布作为正确的概率分布,该模型的形式[8]如式(3)、式(4)所示。
其中,Zλ(x)为归一化函数;fi(x,y)∈(0,1)为特征函数;λi是特征函数的权重,代表每个特征函数的重要性,每个λi对应一个特征函数[8]。
本文提出一种融合乌孜别克语形态特征的最大熵名词标注模型。依据上文中提出的乌孜别克语构词特点,定义了上下文特征模板,提取其特征集,然后根据人工设置的规则筛选模板,并训练最大熵概率模型参数。实验结果表明,使用该模型标注乌孜别克语名词能获得较好的性能。本文依据乌孜别克语名词本身的构词特点选择了相应的模型特征。根据乌孜别克语构词特点和统计结果,本文分别设计了词内部特征和前后依存词特征。
词内部特征表现了一个词的内部变化,其中包括词干信息和词缀信息。乌孜别克语中的词是通过在一个词干之后连接不同的词缀(构词词尾)构成的,词缀信息表现词性等语法意义,故本研究设计了词干信息和词缀信息两个类型的词内部信息特征模板。
(1) 词干信息
乌孜别克语构形词尾不影响整个词的词类信息,对于乌孜别克语词干、词根上连接构形词尾构成的词,只需要考虑该词的词干或词根的标注信息。比如,joyda是名词,该词由词干joy加上词缀da构成,只需要考虑词干joy的词性即可,特征函数定义为式(5)。
(5)
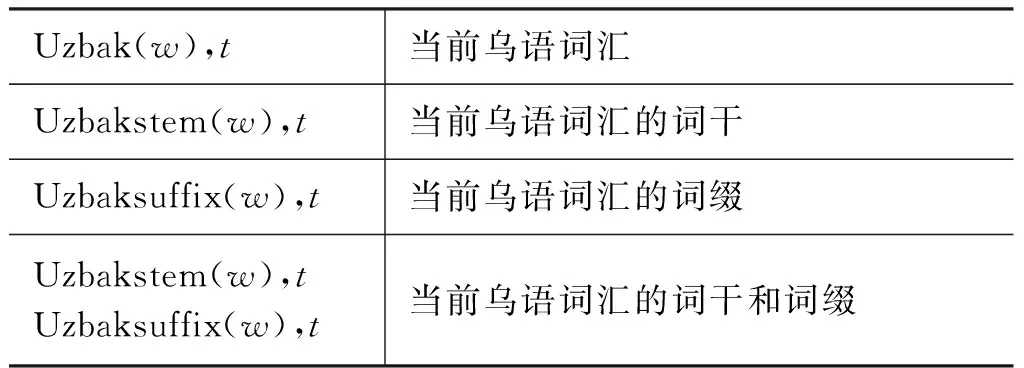
表4 词内部信息特征模板
(2) 词缀信息
尽管乌孜别克语的构词和构形都是以词根、词干上连接不同词尾来形成各类词,但是词尾信息是有限的,根据“乌孜别克语法信息词干词典”收录为准乌孜别克语词缀中过滤的词缀。设计例如,“da”等作为名词词缀的一些特征模板。特征函数可以定义为式(6)。
(6)
(3) 前后依存词特征
前后依存词特征体现一个句子中与当前词紧密联系的词之间的关系。使用前后依存词相关信息可以解决一词兼多个词类的问题[5]。例如,句子1: Men otga minishni o’rgandim(我学会了骑马)和句子2: Siz boshqa basketbol o’yinchilar otish(请你篮球扔给对方选手)中的“ot”有动词和名词两种词性,可以通过其前后词的词类特征进行消歧处理。本文设计的特征如表5所示。
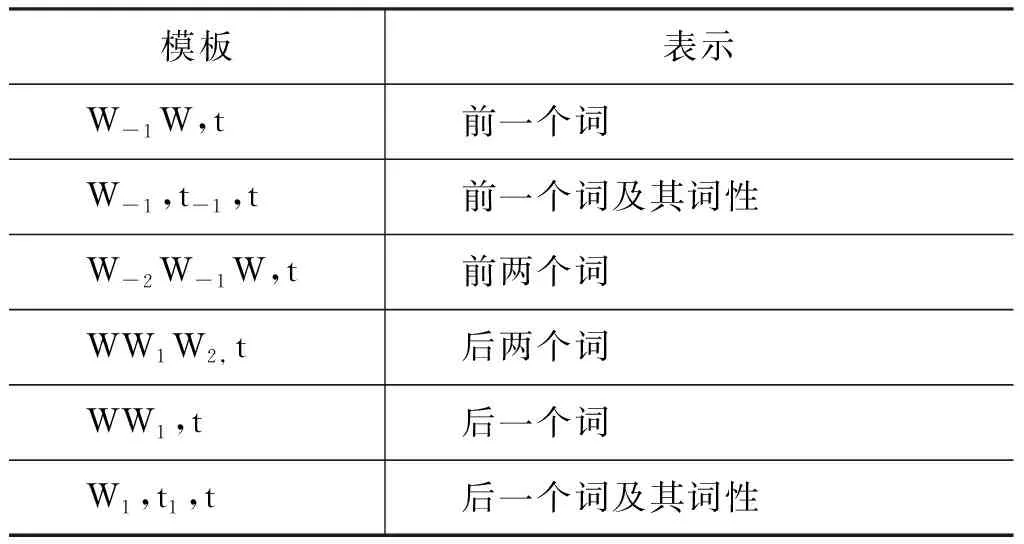
表5 前后依存词信息特征模板
3 实验结果分析
3.1 实验数据说明
(1) 开发文字统一转换工具
本工具把乌孜别克语西里尔文文本转换成乌孜别克语拉丁文,形成统一的拉丁文文本语料库。文字转换工具模块,如图3所示。

图3 文字转换模块图
(2) 研制乌孜别克语词汇统计系统
在现有的维吾尔语统计技术基础上,结合乌孜别克语特点,研发乌孜别克语统计系统,总文本语料的70%作为封闭语料,构建乌孜别克词汇库,共建立五万多种词汇,是乌孜别克语词干库的构建及乌孜别克语词类标注的重要基础。
(3) 乌孜别克语词汇库词类标注
以乌孜别克语词汇库为处理对象,对36 790篇文本中出现的68 750个词汇进行词类标注,构建68 750种乌孜别克语标注词汇库,为建立乌孜别克语语法信息词干词典做准备。
(4) 建立乌孜别克语法信息词干词典
以上研究基础上,结合人机交互技术和人工参与的方法,对68 750种乌孜别克语标注词汇进行词干提取,建立规模为17 064种的乌孜别克语语法信息词干词典。
3.2 实验结果分析
实验数据如表6所示。

表6 乌孜别克语语料结果概括表
表6的实验结果表明,本方法可行、有效。在实验结果中,有些缀接词缀的动词命令式、带有属性人称的代词等也被识别成名词。为了提高识别效率,将要补充词干库,同时也需要进一步深入研究乌孜别克语的语法、语义特征。另外,还有一些不带附加成分的未登录词,不在名词库中的人名、地名、专有名词容易被忽略,需要丰富名词词干库,弥补本词库的缺陷,提高名词识别正确率及效率。
4 总结
本文介绍了乌孜别克语名词词干识别的一些研究工作,重点陈述了乌孜别克语名词的形态分析和在最大熵模型下的特征选择。依据乌孜别克语的自身特点,以词内部词干和词缀、词前后信息等形态信息为特征,提出了融合乌孜别克语形态特征的最大熵名词标注模型。实验结果表明,利用该模型,能够有效地利用上下文信息,可对乌孜别克语名词标注产生显著效果。
