基于TF-IDF向量空间模型文本相似度算法的分析
2018-08-07甘秋云
甘秋云
(福州理工学院 工学院,福建福州350014;福建工程学院国脉信息学院,福建福州350014)
在实际的工作学习中,为了比较两个不同文档之间是否具有一定的相似性,往往需要使用一定的方法来计算文本之间的相似程度。相似度算法就是通过一定的方法来计算不同字符串之间的相似程度,这种算法在剽窃系统检测、用户输入纠错,数据清洗、自动评分系统以及网页搜索和DNA序列匹配等方面都有广泛的应用。
目前衡量文本相似度的方法主要有基于向量空间模型(如余弦算法、汉明距离等)和基于词条空间(如最长公共子串、最少编辑距离法等)。基于向量空间模型(VSM)是目前最常用的相似度计算模型,在自然语言的处理中有着非常广泛的应用。本文主要通过传统的基于向量空间模型(VSM)文本相似度算法及TF-IDF词频统计方法,分析探讨基于TF-IDF的文本相似度算法的实现[1]。
其中Wk是Tk的权重(1<=k<=n)。
计算两个文本D1和D2之间的内容相关度Sim(D1,D2),使用余弦相似度计算,公式为:

1 VSM文本相似度算法
对于不同的文本或短文本对话,可以将文本中词语映射到向量空间,形成文本中文字和向量数据的映射关系,通过计算不同向量之间的差异大小判断文本的相似度。
假设文本用D(Document)表示,特征项指在文档中能反映文档内容的基本语言单位,一般由单词或短语构成,用T(Term)表示。文本和特征项可以使用集合表示为D(T1,T2,…,Tn),其中Tk是特征项(1<=k<=n),例如某文档有a,b,c,d,e五个特征项,则该文档可以表示为D(a,b,c,d,e)[2]。
包含n个特征项的文本,每个特征项都有一个权重值,用W表示,文档D的权重向量可以表示为:
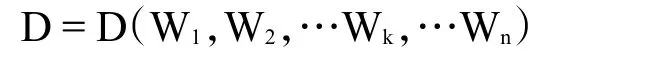
其中,Ai、Bi分别表示文本D1和 D2第 i个特征项的权重值(1<=i<=n)。
文档D1,D2中n维向量是:D1=D1(A1,A2,…,An),D2=D2(B1,B2,…,Bn)。
则两个向量的点积为:A*B=A1*B1+A2*B2+......+An*Bn
公式中的模为:

相似度计算结果为:

Sim的结果就是两个向量的空间夹角的余弦值。
向量空间模型的基本思想是把文本简化为以特征项(关键词)的权重为分量的N维向量空间。余弦相似度,是基于向量空间模型,通过测量向量空间中两个向量夹角的余弦值作为衡量二者之间差异的大小。图1描述了向量夹角的余弦值与相似度的关系。

图1 向量夹角余弦值与相似度关系图
从图1可知,向量可以看作是从原点([0,0,…])出发的两条线段,它们指向不同的方向,余弦值的范围在[-1,1]之间。两条线段之间存在一个夹角,若夹角为0度,余弦值为1,表示方向相同,线段重合,个体差异小;若夹角为180度时,余弦值为-1,表示方向相反,个体差异大。因此,通过向量之间的夹角余弦值可以计算不同文本在统计学方法中的相似度情况,该算法主要用于文件的比较[3]。
本实验以5个文档为例子,文档内容如图2所示。

图2 文档内容
通过分词,最终得到12个文本特征词,表1是文档D1至D5的词频表。

表1 文档词频表
通过余弦相似度算法计算,分别得到文档之间的相似余弦值,Sim(D1,D2)=0.67082,Sim(D1,D3)=0.223607,Sim(D1,D4)=0.258199,Sim(D1,D5)=0.316228。
从表中可知,文档D1与D2之间共有的特征项有3个,计算得到的相似度余弦值为0.67028,相似度偏高,但从实际理解出发,二者之间的相似度并不大,结果与实际存在一定的偏差。
此外,在文本的词频计算中,如果对所有词语或短句进行词频计算,不仅工作量繁琐,而且对于某些词语,即使出现的频率极高,但实际对于文本内容的区分意义不大。因此,在计算词频时,需要对文本进行预处理,它的主要目的是进行中文分词和去停用词,通过对每一个词条进行查询,判断是否存在于停用词表中,若存在则从词条串中删除,通过剔除,过滤筛选后的词语再计算词频计算。对于文档中出现的词语是否具有文本类别区分作用的,可以通过TF-IDF统计方法对文档中词语的重要性及类别区分能力进行判断。
2 TF-IDF词频统计方法
TF(Term Frequency,词频)表示一个给定词语t在一篇文档d中出现的频率。TF越高,说明词语t对文档d越重要,TF越低则词语t对文档d越不重要。在实际的文档中,往往会出现一些对文本内容识别意义不大的高频词、符号、标点或乱码等,例如“那,这,是,的,在”等,若直接根据TF作为相似度的评判标准,显然存在问题。IDF(Inverse Document Frequency,逆向文件频率)是一个词语对于整个文档集或语料库的重要性的判断依据。在文档集或语料库中国,若包含词语t的文档越少,则IDF越大,说明词语t在整个文档集层面上具有很好的识别区分能力。因此,基于TF-IDF的权重词频计算方法,是一种统计方法,它的评判标准是根据字词在文件中出现的次数判断其重要性。如果某个词语或短句在一篇文章中出现的频率高(TF高),并且在其他文章中很少出现(IDF高),则认为该词语或短句具有较好的区分能力,适用于分类。因此,TF描述了某个词语t对某篇文档的重要性,而IDF则是描述了词语t相对整个文档集的重要性[4]。
假设对于某一篇文档dj里的词语ti而言,ti的词频可以表示为:

其中,ni,j表示词语 ti在文档 dj中出现的次数,分母表示文档dj中所有词语出现的次数总和。例如,某文档中单词“分子”出现的次数为20,文档中所有词语出现的总次数为500,则词语“分子”的TF为20/500=0.04。
对于某一特定的词语的IDF,由总文件数除以包含该词语的文件数,对所得的商取对数,表示为:

其中|D|是语料库中所有文档的总数,分母表示包含词语ti的所有文档数。例如,共有100份文件,其中包含词语“分子”的文件数为20,则词语“分子”的IDF为log(100/20)=1.609。
TF-IDF的计算是以TF和IDF乘积作为特征空间坐标系的取值测度,即TF-IDF=TF×IDF,它与该词出现频率成正比,与在整个语料库中出现的次数成反比。一个单词出现的文本频率数越小,它区别不同类别文本的能力越大。通过TF-IDF的方法,可以得出文档中词语的重要性,从而对文本词语进行过滤筛选,选择出适合的文本特征项,再通过计算词频,建立权重向量空间,最终计算余弦值判断文本相似度。
3 基于TF-IDF的文本相似度算法的实现
基于TF-IDF统计方法,分别对5个文档的各个词语进行TF-IDF权重词频的计算,通过分词、过滤停用词后,建立权重向量空间,最后通过余弦相似度算法计算余弦值。
本实验中,分别对5个文档进行TF-IDF的算法实现,计算各个特征项的TF,IDF及TF-IDF值,图3是以文档1为例的统计结果。

图3 文档1各个特征词TF-IDF计算结果
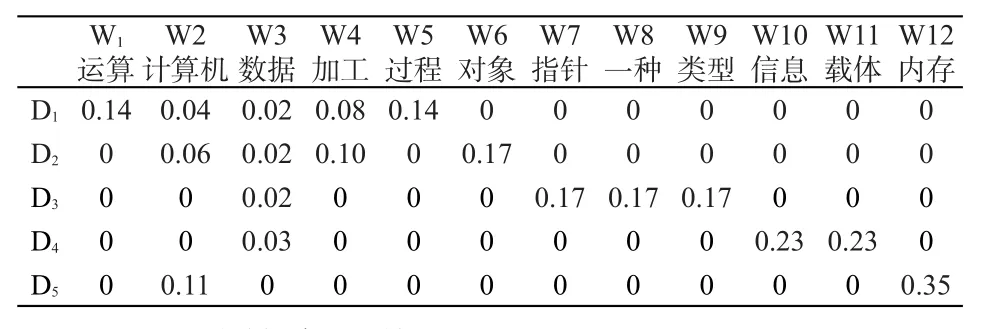
表3 词频权重
通过计算余弦值,得到5个文档与文档1之间的相似度及相似度查找时间统计,结果存放在.txt类型的文件中,如图4。

图4 文档相似度计算结果
图5是传统VSM文本相似度算法与基于TFIDF的文本相似度算法得到的相似值对比图。

图5 传统VSM算法与基于TF-IDF的文本相似度算法对比
由图4可知,对文档的相似度查找耗时不到1秒,该方法在分类的速度和相似度的效果上都得到了明显的提高。由图3-3发现,5个文档之间的相似性的曲线走向没有改变,但是通过TF-IDF词频计算后,各个文档之间的相似性降低,如文档1和文档2在传统VSM算法得到的Sim值为0.67028,调整后的Sim值为0.238997,明显减小了文档之间的相似度,结果更符合实际的理解。
一个词预测主题的能力越强,权重就越大,反之越小。在权重的计算中,往往过滤权重为0的词语,上述实验主要用于说明基于TF-IDF权重的词频计算较传统的词频计算在求余弦相似度结果上更合理。在实际的文本比对中,剔除了权重值为0的词语,使用权重值较高的词语作为文本特征项,计算得到的文本相似度也更加准确,基于TF-IDF的文本相似度算法不论在分类的速度还是相似度的效果上有较好的应用水平[5]。
4 总结
向量空间模型(VSM),将文本内容转化为空间中的点,以向量的形式表示文本,大大降低了文本内容的处理难度,简化了文本中关键词之间的复杂关系,该算法将语言问题更好的转化为数学问题,使得该算法模型具有可计算性。通过词频计算,建立权重向量空间,最后计算余弦值确定文本之间的差异大小,该算法实质就是归一化后的点积结果,在文本的相似度计算方面受到普遍认可。
