基于正则表达式的Web页面信息抽取技术研究
2017-08-10罗粮朱儒明
罗粮,朱儒明
(重庆城市管理职业学院,重庆 401331)
基于正则表达式的Web页面信息抽取技术研究
罗粮,朱儒明
(重庆城市管理职业学院,重庆 401331)
通过分析网页信息抽取技术和正则表达式相关理论,提出基于正则表达式的Web信息抽取方法,并设计相应的网页信息抽取算法。通过对此算法实现的信息抽取系统进行测试实验表明,所提出的Web页面信息抽取方法能达到较高的召回率和准确率。
信息抽取;正则表达式;网页信息
0 引言
随着互联网时代的到来,Internet上大量的Web信息已成为最大和最重要的数据来源,如何在这些海量信息中提取有价值、有针对性的数据信息,已越来越成为备受重视的研究课题。从Web中提取的信息,有很高的实用价值,不仅可为用户直接提供其关注的有用信息,而且可为其他一些专家系统、大数据分析等提供有价值的数据源。
互联网上的Web信息有其特殊的结构和组织方式,大部分基于HTML语言,具有半结构化的特点,如何从这些半结构化的资源中抽取出有用有价值的信息,并将其用结构化和可视化的形式呈现出来,是Web信息提取技术的核心。本文通过正则表达式(Regular Expression)准确、强大的模式匹配和数据提取功能进行信息抽取算法(或Web内容信息抽取系统)的设计,具有较高的准确率和抽全率,提高了信息提取及处理的自动化效率,减少了人工手工操作工作量,对于其他专家系统如舆情分析系统、智能搜索引擎、大数据分析系统等也有很好的参考价值。
1 Web信息特点与正则表达式
1.1 Web 页面信息格式分析
互联网中存在海量的Web信息资源,而这些资源大部分以Web网页为信息的载体,主要采取不同版本的HTML语言或者其他类型的文本标记语言编写,在HT⁃ML文档中,主要使用以“<”和“>”符号包含的特定字符串,称为HTML标记符,大部分标记成对出现,中间相夹正文内容,或格式设置等命令。整个页面文档就由这些HTML标记与各种离散文本,包括正文文本、链接、导航、广告、版权信息等等字符串序列内容共同组成。客户端浏览器会解析这些HTML编码,从而呈现出用户看到的各种文字、音视频、图片、动画等信息,而真正使这些信息能够显示的正是这些种类的超文本标记语言。其中的HTML标记控制着文字、音视频、图片等各种内容的显示,但本身不带有语义,主要用于数据的表现,其他离散的正文文本则是真正有价值的抽取信息,除此外还有导航、友情链接、广告等一些噪音信息。
总之,Web信息,大部分为HTML文档格式,属于一种半结构化的文档,存在着一些可以直接处理的结构化的信息,但是语法语义信息的作用有限,还有一定量的噪音信息,使得固定抽取规则的编写方式存在一定的难度。
1.2 正则表达式
正则表达式(Regular Expression)的功能和匹配规则都很强大,经常用于字符串的模式匹配和查找搜索等操作,它是由两类字符构成的文本模式串,一类是普通的字符,如ASCII字符等,另一类则是特殊字符,被称为正则表达式‘元字符’,如+、*、[、]等;这两类字符可以共同构成一种字符模式串,通过它可设置复杂的控制规则,从而匹配到一组或者一类特定的字符串,通过模式串与待查找原串的匹配,得到的结果就是要匹配或要搜索查找的那一组或一类字符串。因此,正则表达式常用来快速而高效地处理文本类信息。
2 Web信息抽取算法设计与系统实现
2.1 Web 页面预处理
Web页面是一种半结构化文档,在信息提取前先要进行预处理,即规范化处理,将其转化为格式良好的XML格式文档[3]。预处理主要包含以下内容:
(1)统一网页编码,包含汉语的页面编码主要有:国标码(GBK)、UTF-8、大五码(Big5)及Unicode编码等。需要统一为UTF-8或GBK等标准编码。
(2)每个网页需有一个根元素,为。全部的html元素标签均统一转换为小写或大写,以便后期HT⁃ML的遍历与信息提取。
(3)修正html元素标签,使每一个开始标记,并且保证html标签的正确嵌套。如
(4)其他需修正的html规范,如html标记的属性,统一为属性="值"的形式,属性名要与属性值一一对应,属性值须用英文双引号包含。
2.2 网页清洗
网页清洗即网页去噪,即过滤掉html标签中与信息抽取无关的噪音信息。主要包含以下几个方面的清洗:
(1)多余的空白符、无实际内容的嵌套标记,如之类的空标记。
(2)注释、一些格式标记、排版标记等,与正文相关性不大的网页节点,如script、div、style、object、type等。
(3)广告内容和与正文相关性不大的友情链接等的网页噪声。根据统计,这部分噪声大都集中于部分table节点中。此步需根据统计原理,分析统计出有用字符数的比例,再根据正文相关度进行筛选和清洗。
2.3 正则表达式抽取模式串设计
在利用正则表达式进行Web信息抽取时,首先需设计好要抽取信息对应的正则表达式匹配模式串,然后把预处理的网页信息处理成字符串形式,从而进行匹配得到要提取的信息。实际应用当中,应该根据不同的抽取需求编写具体对应的正则表达式模式串进行匹配,例如常见的电邮和超链接的匹配模式串如下表所示:

表1 正则表达式匹配模式串
2.4 正则表达式抽取算法设计
设定正则表达式匹配模式串集合为S={s1,s2,…,sn}F={fl,f2,…,fn},Web页面节点集合 NodeSet= {node1,node2,…,nodeN}。
(1)输入:网页URL(例如待抽取的为新闻页面——网易,URL=WWW.163.COM)。
(2)输出:需提取的Web页面信息,如正文中关键词,新闻标题、作者、链接等各种相关信息数据。
(3)建立输出数据信息集合节点ResultSetInfo,初始化为空集,主要用于存放输出的文本信息节点。在正则表达式集合S中利用要抽取信息对应的模式串s1|s2…|sn,从集合NodeSet中找到对应信息项相关度最高的标签节点nodek(1≤k≤N)。
(4)递归遍历nodek中的节点,通过正则表达式集S匹配到对应文本信息节点TxtNodej(j≥1)存入集合ResultSetInfo,得到输出集合ResultSetInfo={TxtNode1,TxtNode2,…,TxtNodej}。
3 系统测试与实验结果分析
通过上述Web页面信息提取算法,就可以设计与实现出相应的信息抽取系统。系统主要用Java语言实现,后台数据库采用MySQL,同时,再利用Java开源库HTMLParser(小巧快速的纯java编写HTML解析库,主要用于改造或提取HTML),就可设计出接口统一、功能完备的通用Web信息抽取系统。
利用Web信息抽取系统以不同网站为实例进行抽取测试,得到召回率和准确率等指标数据如下表所示:
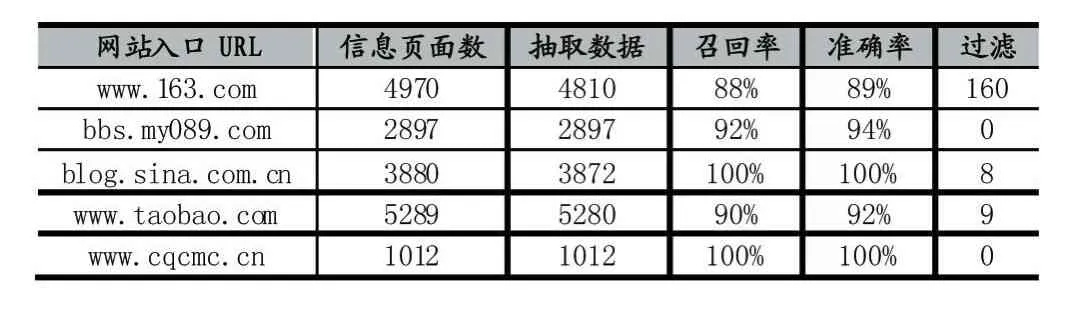
表2 系统实验测试数据
通过上述测试数据可发现,本信息抽取算法具有良好的抽取效果,利用此算法设计的系统,对新闻、论坛和博客、校园网等各类网站的信息抽取都能达到较高的召回率和准确率。
4 结语
Web信息抽取技术对于从海量网络资源中准确、快速提取到我们需要的信息,以便进行后期处理具有十分重要的意义。本文通过研究目前Web信息抽取方法的特点,和正则表达式技术,提出了一种基于正则表达式的网页信息提取算法并设计了相应的Web信息抽取系统。最后通过系统测试实验结果证明,本系统具有较高的准确率与召回率,也可整合进其他各种信息系统,为其提供数据源,有较高的实用应用价值。
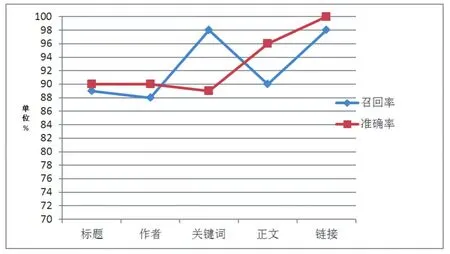
图1 召回率与准确率统计图
[1]Luke Welling等著,武欣译.PHP和MySQL Web开发[M].北京:机械工业出版社,2014.
[2]袁津生,蔡岳.搜索引擎原理与实践[M].北京:北京邮电大学出版社,2008.
[3]Basu S,Bilenko M,Mooney R.A Probabilistic Framework for Semi-Supervised Clustering.In:Proceedings of 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2004.
[4]Wang X,Wu H,Wei L,Zhou A.A Similarity-Based Analysis Model for Topic Distillation.International Journal of Computational Intelligence and Application,2002,2(3):267-275.
[5]韩忠明,李文正,莫倩.有效HTML文本信息抽取方法的研究[J].计算机应用研究,2008,25(12):3560-3564
[6]李中言,李普跃.信息抽取技术在数字图书馆中的应用[J].现代情报,2007,10(10):96-97.
[7]王磊,陈曙晖,苏金树等.深度报文检测中基于GPU的正则表达式匹配引擎[J].计算机应用研究,2010,27(11):4324-4327.
[8]陈琼,苏文健.基于网页结构树的Web信息抽取方法[J].计算机工程,2005,15(20):54-55.
[9]韩存鸽.Web信息抽取方法研究[J].计算机系统应用,2009.
[10]黄颖,黄治平.HTML Parser提取网页信息的设计与实现[J].江西理工大学学报,2007,18(6):21-23.
[11]张丽娜,陈俊杰,赵丽欣.基于HTMLParser的BT种子网页信息抽取[J].电脑开发与应用,2010.
[12]靳小川,刘万军,赵雷.基于正则表达式的企业主页信息抽取[J[.计算机系统应用,2010.
Research on Web Information Extraction Technology Based on Regular Expression
LUO Liang,ZHU Ru-ming
(Chongqing City Management College,Chongqing 401331)
Through the analysis of Web information extraction technology and regular expression theory,proposes a Web information extraction meth⁃od based on regular expression and designs a corresponding Web page information extraction algorithm.The experiment results show that the information extraction system based on this algorithm can achieve high recall ratio and retrieval precision.
罗粮(1977-),男,重庆沙坪坝人,硕士,讲师,研究方向为分布式计算、软件复用
2017-03-14
2017-05-03
重庆城市管理职业学院科研项目(No.2015kyxm017)、重庆市教委科学技术研究项目(No.KJ1503208)、重庆市教育科学“十三五”规划2016年度课题(No.2016-GX-183)
1007-1423(2017)15-0017-04
10.3969/j.issn.1007-1423.2017.15.004
朱儒明(1965-),男,重庆巴南人,本科,副教授,研究方向为软件工程、自组织网络
Information Extraction;Regular Expression;Web Page Information
