基于局部线性重构的近邻填充算法
2017-08-10温海标
温海标
(广西师范学院计算机与信息工程学院,南宁 530023)
基于局部线性重构的近邻填充算法
温海标
(广西师范学院计算机与信息工程学院,南宁 530023)
K近邻填充算法(KNNI)对缺失数据填充时,使用K个近邻的训练样本属性值的平均值作为KNNI算法的填充值,该值偏离真实值较大,一种有效的方法是K近邻样本属性值的加权平均值作为填充值。如何确定K近邻样本的权值,是KNNI算法研究热点。为此,提出引入局部线性重构方法用于近邻填充,该方法是用K近邻样本重构测试样本得出权值。实验结果表明提出的算法比KNNI算法填充效果更好,填充值更接近真实值。
缺失值填充;重构技术;K近邻;LLR
0 引言
在机器学习的实际应用中,样本的一些数据经常因为某些原因导致样本数据不完整,例如数据暂时无法得到、被遗漏等原因导致数据缺失[1]。样本数据的缺失会影响机器从样本数据学习得来的模型性能或规则的正确性。因此在机器学习领域,缺失数据填充是基础而又重要的研究问题。
目前,已有多种方法处理缺失值,例如最近邻、决策树、贝叶斯网络、支持向量机、粗糙集和模糊集、神经网络等方法[2]。其中K近邻填充算法[3]时间复杂度低,填充效率和准确率高等优点受到了广泛研究。其基本原理是通过相似度量函数计算出缺失样本的K个近邻完整样本,计算求得K个样本的均值作为填充值。KNNI(K-Nearest Neighbor Imputation)存在一个明显的缺陷,如图1,当K=3时,A、B、C样本作为缺失样本的近邻,A、B、C样本的均值作为缺失样本的填充值,该值偏离真实值的偏差是较大的,因为C样本离缺失样本较远,其中对填充值有较大影响。一个有效的方法是对A、B、C样本设置权值,离缺失样本越近,权值越大,即A最大,C最小,A、B、C样本加权平均值作为缺失样本的填充值。这种方法就是降低离缺失样本较远的整样本的值对填充值的影响。本文用局部线性重构的方法用于KNNI算法,找出合适的K近邻样本权值,进一步降低填充值的偏差。
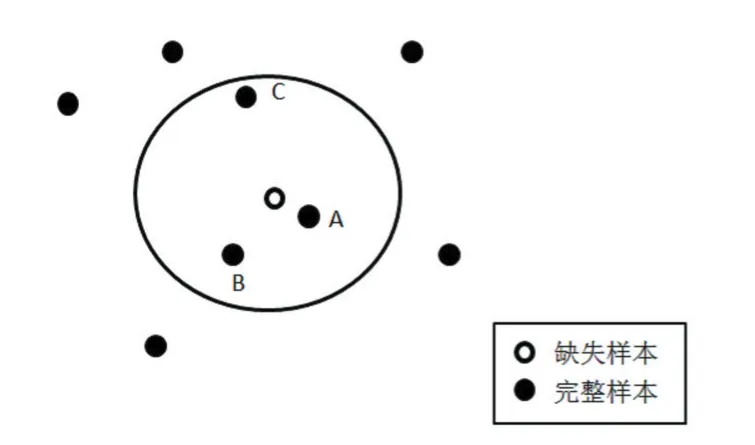
图1 缺失样本近邻点选择
1 LLR-KNNI算法
1.1 重构技术理论
一个向量被一组线性无关的向量线性组合近似表示,称为重构[4]。已知一组线性无关向量x1,x2,x3,…,xk,xk∈Rd,和被这组线性近似表示的向量y,y∈Rd,其中d表示向量的元素个数,根据重构理论,得出如下函数:


式(1)中,wi为重构系数,值越大,说明xi向量的元素值和y向量元素值接近。W为重构系数向量。式(2)中的e为重构误差,e的值越小,说明这组线性无关向量的近似表示的向量与y接近。目前重构技术的应用得到广泛应用,如人脸识别、图像去噪、属性降维等[5],其中属性降维中的局部线性嵌入算法较为经典。局部线性嵌入(Locally Linear Embedding,LLE)算法[6]假设在一个高维样本空间中某个流行局部小领域看成局部线性,即在这个小领域里的某点可以用重构技术被它周围的点线性重构表示。高维样本空间中,局部小领域的点是近邻关系,降维后这些点仍然是近邻关系,是一种基于流行的降维算法。LLE算法因计算复杂度低,需配置参数少,鲁棒性好等优点得到了广泛应用。
1.2 LLR-KNNI
局部线性重构(Local Linear Reconstruction,LLR)是基于重构理论和LLE算法得出并应用于KNNI算法中,局部指的是重构缺失样本的完整样本来自缺失样本的某个领域,LLR-KNNI算法分为预处理和决策过程,预处理中,首先把数据样本分为训练样本和测试样本,具有完整数据的作为训练样本,含缺失数据的样本作为测试样本。样本属性可分为一般属性和决策属性,缺失样本的缺失属性值可以是一般属性,也可以是决策属性,LLR-KNNI算法把缺失属性视为决策属性,即当缺失属性值是一般属性的值时,该属性作为决策属性,其他为一般属性。其次将整个数据样本除决策属性之外的其他属性值规范化到[0,1]区间。决策过程中,每个缺失样本通过相似度量函数计算出k领域的k个近邻样本,通过重构方法找出k个近邻样本的重构系数,这个系数称为权值,权值越大,说明,该权值对应的近邻样本与缺失样本越相似。最后加权求和得出填充值。算法描述如下:
训练样本X∈Rn×d,测试样本Y∈Rm×d,m,n为样本数,d为属性个数。
步骤1数据样本将非决策属性规范化为[0,1]区间,规范化方法采用最小最大规范化法,如下式:

式(3)中,max和min分别表示样本属性A的最大值和最小值。
步骤2通过相似度量函数计算测试样本的K个近邻样本,相似度量函数采用欧氏距离函数:
测试样本与每个训练样本根据式(4)计算距离,计算结果从小到大排序,取前K个距离对应的样本作为测试样本的K近邻样本。
步骤3测试样本的K近邻样本根据下式重构测试样本
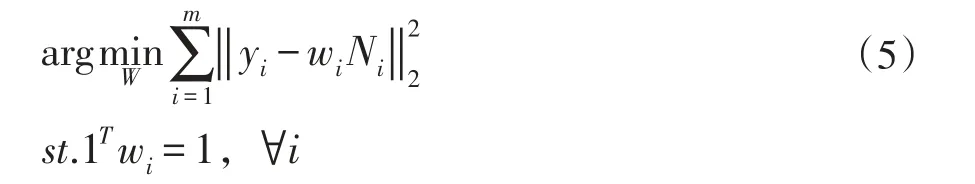
式(5)中,Ni∈Rk×d是近邻样本矩阵,存储的是测试样本的K个近邻样本,wi∈R1×k为近邻样本权值向量,W∈Rm×k为近邻样本权值矩阵。
步骤4通过求解式(5)的目标函数,得出测试样本K个近邻样本的权值,假设样本第j个属性为决策属性,根据下式计算试样本的填充值:
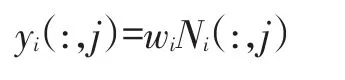
其中Ni(:,j)表示抽取矩阵Ni的第j个列向量。算法的伪代码如下:
算法1 LLR-KNNI算法
输入:训练样本X,测试样本Y,近邻个数K
输出:测试样本决策属性值

2 实验结果与分析
实验的评价指标采用均方根误差(Root Mean Square Error,RMSE),计算公式如下:

其中m为测试样本的缺失值个数,yi*和yi分别为填充值和真实值。RMSE表明填充值和真实值之间的关系,RMSE值越小,说明填充值与真实值差值越小,即填充值越接近真实值。
实验过程中,LLR-KNNI算法和KNNI算法分别对缺失样本填充,分别计算RMSE值,作为比较LLRKNNI算法和KNNI算法的填充性能。
实验部分的数据集选取UCI[7]机器学习知识库中的部分数据集(表1)进行实验,所选的数据集全部是无缺失值的完整数据集,以测试LLR-KNNI算法的填充性能。
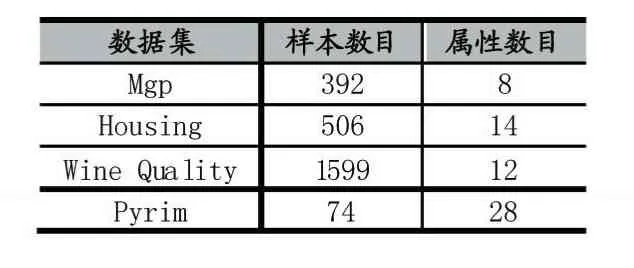
表1 实验采用的UCI数据集
本文算法采用MATLAB软件编程实现,MATLAB软件版本为2014a。系统平台为AMD AthlonⅡX2 B24 3.0 GHz,4GB内存,操作系统:Windows 7旗舰版。LLR-KNNI算法和KNNI算法近邻个数K设置为5,实验的验证方法采用10折交叉验证法,对数据集拆分10份,第一次实验时,第1份设为测试集,其余为训练集,第二次实验将第2份设为测试集,其余为训练集,此操作重复十次。对表1中的每个数据集采用10折交叉验证法实验十次,并取十次实验得出的RMSE的均值加上标准差得出如表2。
从表2可以看出,在每个数据集上,LLR-KNNI算法的RMSE的值比KNNI的小,说明LLR-KNNI算法的填充值更接近真实值,即LLR-KNNI算法的填充性能优于传统KNNI算法。从每个数据集中的标准差的值可以看出,LLR-KNNI算法的标准差值比KNNI的小,说明LLR-KNNI算法比KNNI算法有更好的稳定性。从图2更直观看出LLR-KNNI的优越性,也说明LLRKNNI算法比KNNI具有更好的填充性能。

表2 LLR-KNNI算法和KNNI算法在各数据集上RMSE的比较(均值标准差)
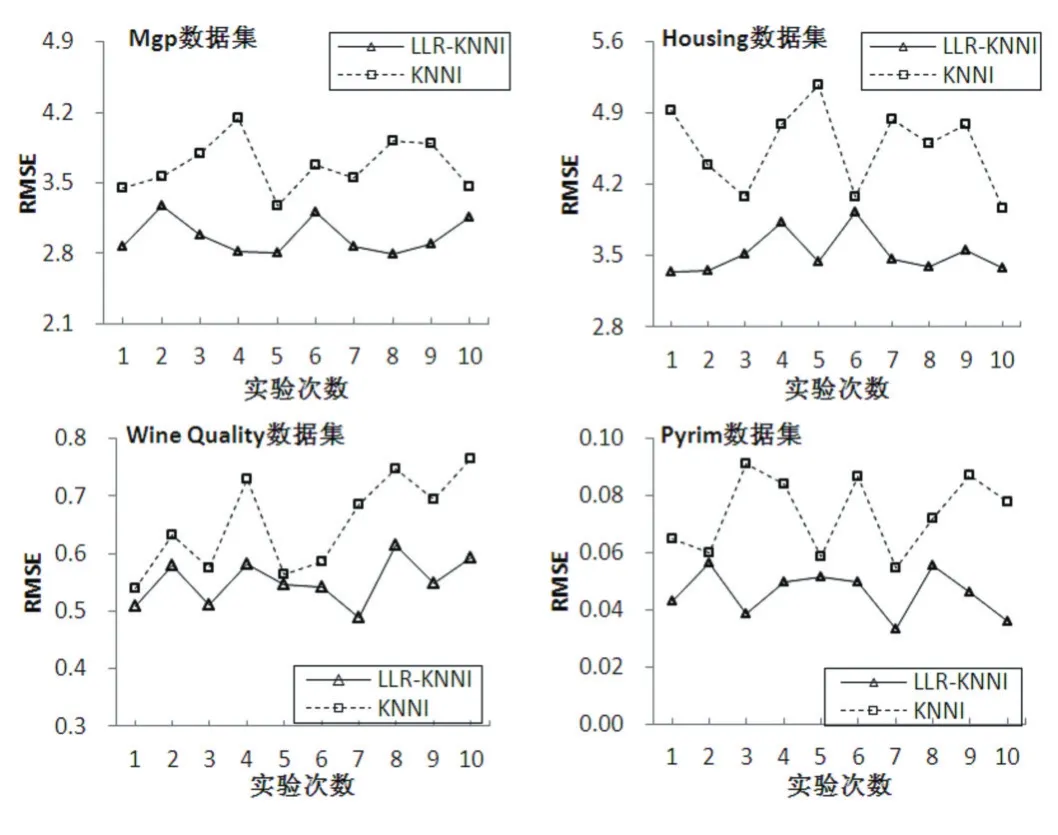
图2 算法在各数据集十次实验RMSE对比图
3 结语
本文的LLR-KNNI算法,使用线性重构的方法得出样本近邻点的权值,近邻样本权值的大小说明与缺失样本的相似程度,离缺失样本越远,近邻样本权值越小,一定程度降低KNNI算法中较远的近邻点对算法的填充性能影响。通过对比LLR-KNNI算法和KNNI算法的均方根误差的实验分析表明,LLR-KNNI算法的填充性能优于KNNI算法。
[1]Little,Roderick J A,Rubin,et al.Statistical Analysis with Missing Data[J].American Journal of Sociology,1988,26(Volume 94,Num-ber 1):1322-39.
[2]Zhang S,Jin Z,Zhu X.Missing Data Imputation by Utilizing Information Within Incomplete Instances[J].Journal of Systems&Software,2011,84(3):452-459.
[3]Cover T,Hart P.Nearest Neighbor Pattern Classification[J].IEEE Transactions on Information Theory,1967,13(1):21-27.
[4]Kang P,Cho S.Locally Linear Reconstruction for Instance-Based Learning[J].Pattern Recognition,2008,41(11):3507-3518.
[5]Zhang L,Chen C,Bu J,et al.Active Learning Based on Locally Linear Reconstruction[J].IEEE Transactions on Pattern Analysis& Machine Intelligence,2011,33(10):2026-38.
[6]Roweis S T,Saul L K.Nonlinear Dimensionality Reduction by Locally Linear Embedding[J].Science,2000,290(5500):2323-6.
[7]UCI Repository of Machine Learning Datasets[DB/OL].http://archive.ics.uci.edu/-m.
Nearest Neighbor Filling Algorithm Based on Local Linear Reconstruction
WEN Hai-biao
(School of Computer and Information Engineering,Guangxi Teachers Education University,Nanning 530023)
Knearest neighbor filling algorithm for filling missing data,the average value of training sample attributes uses Kneighbor values as the filling value of KNNI algorithm,the value is far from the real values,an effective method is to sample attribute weighted Knearest neighbor average as filling value.How to determine the weights of Knearest neighbor samples is a hot research topic of KNNI algorithm.For this reason,proposes a method of local linear reconstruction for nearest neighbor filling.The method uses the Knearest neighbor sample to reconstruct the test sample.The experimental results show that the proposed algorithm is better than the KNNI algorithm,and the filling value is close to the real value.
温海标(1989-),男,广东河源人,硕士研究生,研究方向为数据挖掘、机器学习
2017-03-24
2017-05-15
1007-1423(2017)15-0003-04
10.3969/j.issn.1007-1423.2017.15.001
Missing Values Filling;Reconstruction Technique;KNearest Neighbor;LLR
