社会化信息对股市波动影响分析—基于SparkR平台的实现
2017-04-14倪丽萍马驰宇刘小军
倪丽萍 马驰宇 刘小军
(合肥工业大学管理学院 安徽 合肥 230009)(合肥工业大学过程优化与智能决策教育部重点实验室 安徽 合肥 230009)
社会化信息对股市波动影响分析—基于SparkR平台的实现
倪丽萍 马驰宇 刘小军
(合肥工业大学管理学院 安徽 合肥 230009)(合肥工业大学过程优化与智能决策教育部重点实验室 安徽 合肥 230009)
社会信息化的飞速发展使得社会化信息日益丰富。这些信息会对股市波动产生一定影响,然而这些信息数量巨大且多属于非结构化数据,使得分析社会化信息对市场的影响具有一定的难度。尝试通过分布式计算技术来解决这个问题,并从信息量和信息情感两个方面考察社会化信息对股市的影响。通过搭建SparkR平台,首先讨论如何利用该平台解决大数据环境下股市社会化信息的特征选择以及情感分类问题,其次对比了信息量和信息情感对市场的影响情况,说明信息情感变化更能准确说明市场的波动变化情况。为进一步验证方案的可行性,定义了不同的情感计量方式并对比了不同方案的优缺点,进而给出分析社会化信息对股市波动影响的综合解决方案,并且通过实验验证了该方案的有效性。
SparkR 特征选择 分布式计算 文本挖掘 情感分类
0 引 言
近年来随着社会信息化的飞速发展,金融门户网站日益繁荣,微博、论坛日趋活跃,金融行业产生了海量数据,尤其是海量的非结构化数据。研究表明这些非结构化文本数据中包含的评论、情感因子等信息对金融行业产生着巨大的影响,所以金融文本数据分析日益兴起和被重视,国内外学者在金融文本数据分析方面也取得了一系列成果。
国外,研究者Wuthrich等人开发了一个基于门户网站上隔夜新闻的股票指数预测系统,根据该系统的建议进行交易,平均收益率达到5.2%。Lavrenko等人在2000年左右开发了基于雅虎财经网站公布的新闻文章的Enalyst系统来预测美国股市的价格趋势,利用该系统平均每次交易的收益为23个基点[3]。Zhang等人研究了Twitter上金融信息对美国三大股指的影响[4]。Gilbert等利用博客数据构建了焦虑情绪指数并证明该指数能够反向预测标普500指数走势[5]。Bollen等基于Twitter数据发现情绪可以预测未来2~6天的道琼斯指数走势[6]。Peramunetilleke等人将文本分类技术应用到外汇市场短期走势中,得到了较好的结果[7]。相较于国外,国内关于金融文本数据分析的研究尚处于起步阶段,一些学者将文本分析技术用于金融市场。黄润鹏等将微博中的信息用于上证指数的预测[8]。赖凯声等讨论了微博情绪因子和上证指数的相关性走势图[9]。朱浩然等讨论了金融微博中的情感分析问题,并进而将其应用于市场预测中[10]。此外,还有一些学者讨论了特定文本信息源下金融文本分析技术,例如,王岩等研究了面向金融领域论坛的话题检测和热度评价方法[11]。
上述研究虽然促进了文本金融数据分析方法和应用的发展,但是网络金融文本数据具有数据来源广泛、结构复杂多样和数据量大的特点,上述研究没有考虑到处理的时效性。因此要求寻找新的解决方案以适应大数据的挑战。
本文将分布式计算技术引入到文本金融数据分析中。构建了SparkR平台既可以利用R语言的便利性和易于操作性,也可以利用Spark平台进行分布式计算,解决文本金融数据分析中的大数据挑战。
基于上述,本文以SparkR为基础讨论基于SparkR平台下社会信息量和社会信息情感态度对市场的影响情况。
1 社会化信息对股价波动的影响分析
本文分别考察新闻信息量和新闻信息情感对股价波动的影响,为了完成这一任务需要解决如下两个问题:(1) 进行特征选择来挑选出关键信息以便通过情感分类算法区分社会化信息的情感态度;(2) 对社会化信息进行情感分类区分其情感态度后,量化情感态度并考察其对股市波动的影响。为了解决这两个问题,本文设计了三个模型从不同的角度予以探讨。所有模型以上证50股指为研究对象,因此选取上证50所包含的50只股票在2013年-2014年内的所有要闻。选取方法为以50只股票所属企业的主题名称作为关键词,在每个网站进行搜索,抓取所有相关新闻网页。通过爬虫函数抓取和讯财经、新浪财经、腾讯财经三个网站的股票要闻板块新闻,建立模型分析互联网股票新闻与上证50股指波动的相关性。
模型一 探讨新闻信息量对股价波动的影响。
定义1 新闻信息量。新闻信息量是指在一段时间内一家企业发生的相关新闻总量。
计算新闻信息量时,将以该企业主题名搜索的相关网页归属于该企业新闻,赋予权重α,对以其他企业主题名搜索却包含该企业主题名称的新闻赋予权重β,对每一家企业求取加权的新闻和,得到每一家企业的新闻信息量。具体公式如下:
Ii=αPi+βNi
(1)
其中0<β<α<1,Pi为归属于该企业的新闻数量,Ni为包含该企业主体名但不属于该企业的新闻数量。最后通过上证50指数的派许加权方式得到上证50的新闻信息量。模型一没有进行特征筛选和情感态度分类,仅仅考察了社会化信息数量上如何影响股市波动。
模型二 探讨新闻情感信息量对股价波动的影响。
定义2 新闻情感信息量。新闻情感信息量是指在一段时间内一家企业发生的正向新闻与负向新闻数量之差。
即使是要闻板块的新闻也不会全部对股价波动有较大影响,并且新闻对股价的影响有正负之分,所以需要对新闻进行分类以区分新闻对股价的不同影响。因此模型二引入新闻情感来区分新闻,并分别统计同一段时间段中正向新闻和负向新闻的数量,进而考察新闻情感信息量对股价的影响。
在模型二中,本文依然采用模型一的新闻归属与赋权方式。为了筛选出对股价有影响的新闻并对这些新闻进行情感分类,本文通过K-means聚类获取所需的特征词和训练集。为了提高聚类准确率并充分提取分类极性词,本文选取周股价涨跌幅在5%以上的企业新闻文本作为聚类训练集,去除训练集包含的一些金融常用词、停用词后,将新闻聚为正反两类。分别选取包含文本数较多的正类和负类作为分类训练集,计算极性词频后将正反新闻都高频出现的极性词删除作为特征词候选集。为了进一步提取最终的特征词,本文利用如下方法实现,实现过程分为如下三步:
Step1 设训练样本初始特征集为φ,按词频从大到小依次从候选词集中选择一个特征词添加到特征集中,并对训练样本进行训练得到初步模型。
Step2 将分类后的新闻与之前的聚类结果做比较,人工标注分类与聚类不同的新闻样本,再针对性地对特征词进行调整。调整的过程为如果人工标注结果与聚类结果一致,则按照特征集提取关键词,从特征集中去除在相应反类中词频最高的关键词。如果人工标注结果与分类器结果一致,则将该篇文章从训练集中删除,调整相应的词频,完成整个调整过程。
Step3 重复Step1、Step2,直到准确率保持稳定后停止训练,得到最终模型。最后利用训练好的分类器对新闻分类,确定新闻的情感,并将一些由于信息混杂或情感信息不充分导致无法分类的新闻作为对股价影响不明显的新闻去除。
通过上述步骤可求得每一家企业的新闻情感信息量,具体公式为:
Ii=α(Li-Ji)+β(Mi-Ki)
(2)
其中Li为归属于该企业新闻中正向情感新闻数量,Ji为归属于该企业的新闻中负向情感新闻数量,Mi为包含该企业主体名但不属于该企业的新闻中正向情感新闻数量,Ki为包含该企业主体名但不属于该企业的新闻中负向情感新闻数量。最后通过上证50指数的派许加权方式得到上证50的新闻情感信息量。流程如图1所示。
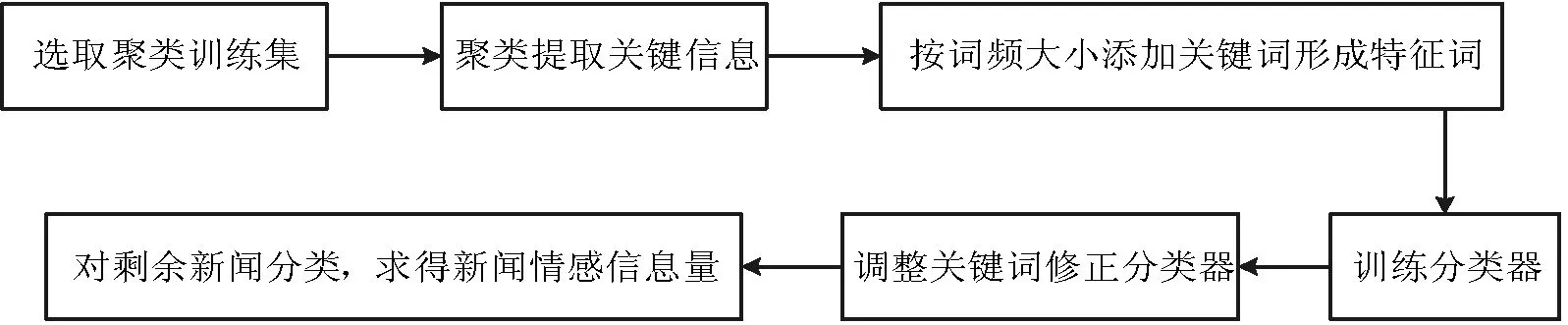
图1 新闻情感信息量模型流程图
模型二通过聚类算法来进行特征选择。通过分类算法进行情感分类。本文中通过有偏的选择训练样本来提高聚类的准确性。本文认为聚类的结果包含两种,一种是需要的包含特殊信息的新闻,这一类新闻对股市的影响较大,通过分词可以获取所需的主要特征,即解决特征选择问题。另一种是包含信息不充分、对股市影响较小或不明确的新闻,这一类新闻予以删除。通过样本有偏选择和聚类算法,可以充分利用大量新闻准确快速提取关键信息,以适应数据量爆炸和快速响应的现实需求。
模型三 探讨新闻情感词强度对股价波动的影响
定义3 新闻情感词强度。新闻情感词强度是指在一段时间内一家企业发生新闻中正向情感词与负向情感词数量之差。
模型二通过分类算法求得新闻的情感,还可以利用情感词的数量来表示新闻的情感。为了研究的充分性,模型三引入新闻情感词强度。本文依然采用模型一的新闻归属与赋权方式,引入路透社金融词典并对其进行人工修正选出其中的情感词作为情感词词典。分别求取每篇新闻中包含的正负情感词数量,求得每家企业的新闻情感词强度,公式为:
Ii=α(Wi-Xi)+β(Yi-Zi)
(3)
其中Wi为归属于该企业的新闻中正向情感词数量,Xi为归属于该企业的新闻中负向情感词数量,Yi为包含该企业主体名但不属于该企业的新闻中正向情感词数量,Zi为包含该企业主体名但不属于该企业的新闻中负向情感词数量。最后通过上证50指数的派许加权方式得到上证50的新闻情感词强度。模型三通过情感词典的方式进行特征选择,并通过计算词频来进行情感态度区分。这样区分相对较为简单,也可以得到情感结果。
由于新闻文本数众多以及文本分词后形成的词频矩阵属于高维稀疏矩阵,所以相应的聚类、分类算法需要在分布式平台下实现,以适应大数据金融分析的及时性与准确性要求。下面探讨这些算法在SparkR平台下的实现。
2 SparkR模型及网络金融文本数据挖掘算法实现
SparkR是AMPLab发布的一个R的开发包,其将Spark和R结合,其既具有Spark的数据结构和应用架构,又利用了R语言完成数据分析的便利性,所以十分适合完成金融大数据分析任务。该R包为ApacheSpark的R轻量前端,提供了RRDD的API,用户可以在集群上通过Rshell交互性的运行job。SparkR提供了PipelinedRDD优化,可以将Execute交由RVM计算的内容统一处理,然后统一将计算结果返回给Execute,而不用两者之间频繁渐次通信,从而大大地节省了传输和序列化反序列化的时间。最后,SparkR还支持常见的闭包功能,用户定义的函数中所引用的变量会自动被发送到集群中其他机器上。[1]SparkR将R语言结合SparkContext通过JNI接口来启动一个JavaSparkContext,然后由JavaSparkContext连接到Worker上的Executor。SparkR运行原理如图2所示。

图2 SparkR运行原理
由于可以很方便地利用该包实现相应的金融大数据分析所需的爬虫、聚类、分类算法,根据上节描述,在聚类算法上本文选取的是k-means算法,在分类算法上选择的是随进森林方法。具体的实现算法描述如下。
其中Step2完成选取特征词的任务,并在Step3利用reduceByKey算子得出特征词矩阵。
2.1 文本数据预处理
在获取新闻语料库后,需要对新闻进行文本预处理。而文本预处理的工作核心为将中文文档进行分词处理,并形成特征词词频矩阵。分词工具采取的是R提供的Rwordseg包。文本预处理任务分三个阶段完成。第一阶段,将爬虫抓取后的文本分布式存储到每个节点上,利用分词工具分布式对所有文本进行分词,形成文本的词频矩阵。第二阶段将自定义的有序金融词典特征词初始化为RDD并将之广播,通过进行字符匹配并记录下匹配到的特征词序号作为key值,value值为1。第三阶段利用reduceBeKey算子对每篇文档进行处理,将key值相同的value值相加,并加上新闻标号,则得到相应文档词频矩阵的三元组记为(i,key,value),其中i表示这是第i篇文档,key为关键词在金融词典的序号,value为该特征词在该文档出现的次数。相关步骤如算法1所示。
算法1 文本预处理算法
输入:待分词的新闻文本
输出:文本词频矩阵
Step1 将新闻文本初始化为RDD,并将之利用分词函数分词。
Step2 定义函数filter=function(x){if(x ==dictRDD[i]) return c(i,1)},lapply(fileRDD,fun=filter)结果记为featureRDD,为c(key,value)类型,key为i,value为1。
Step3 调用reduceByKey(featureRDD, “+”,2L),结果为每篇文档每个非0词频关键词的词频。
其中Step2完成选取特征词的任务,并在Step3利用reduceByKey算子得出特征词矩阵。
2.2 CART算法和随机森林算法在SparkR上的分布式实现
CART算法和随机森林算法主要用于分类。其中CART算法由Breiman等人在1984年提出,是应用广泛的决策树学习方法。CART假设决策树是二叉树,内部节点特征的取值为“是”和“否”,是一种给定输入样本条件下输出预测值条件概率分布的学习方法。该方法由生成树和剪枝两部分构成,其中生成树是递归构建二叉决策树的过程。CART方法采用基尼指数来进行分裂特征的选择[13]。
定义4(基尼指数)。分类问题中,假设有K个类,样本点属于第K类的概率为Pk,则概率分布的基尼指数定义为:
(4)
对于二类分类问题,若样本点属于第1个类的概率是p,则概率分布的基尼指数为:
Gini(p)=2p(1-p)
(5)
对于给定的样本集合D,其基尼指数为:
(6)
式中,Ck是D中属于第k类的样本子集,K是类的个数。如果样本集合D根据特征A是否取某一可能值a被分割成D1和D2两部分,即:
(7)
则在特征A的条件下,集合D的基尼指数定义为:
(8)
随机森林算法是一种集成分类算法,最早由LeoBreiman和AdeleCutler提出。随机森林是一个集成多个无剪枝CART树的分类器。其输出结果的类别取决于个别树输出的类别的众数而定。其中每棵树使用的训练集是从总的训练集中采用又放回抽样抽取出来的。这意味着总的训练集中的有些样本可能多次出现在一棵树的训练集中,也可能从未出现在一棵树的训练集中。在训练每棵树的节点时,使用的特征是从所有特征中按照一定比例随机地无放回抽取的。根据LeoBreiman的建议,假设总的特征数量为M,这个比例可以是sqrt(M)、1/2sqrt(M)和2sqrt(M)。下面本文将分别讨论如何在SparkR上实现CART树和随机森林算法。
2.2.1CART树的SparkR分布式生成算法
假定所有的特征变量的取值都是离散的,则将样本数据按行读入为DataFrame格式。分别抽取特征变量和类标签并使用toRDD算子转化为featureRDD和labelRDD。其中featureRDD和labelRDD中每个元素均为c(key,value)类型,其中key为该元素在原DataFrame中的行号,value为相应的值。则可以用三个步骤生成CART树,第一阶段首先生成一个由该行在每列特征变量取值与该特征变量名组合作为key,将1作为value的键值对,然后使用reduceByKey算子统计出每个变量值有多少样本。第二个阶段将第一阶段中的key与labelRDD组合作为key,1作为value的键值对,以便使用reduceByKey统计出每个变量属于特定类的样本数量。第三阶段,计算相应的Gini值,并通过split函数分割样本。记录原样本的行号,以保证样本一致性。具体算法步骤如算法2所示。
算法2CART树的SparkR分布式实现
输入:训练样本数据
输出:CART树
Step1 调用count(labelRDD)函数得到样本总数,记为m。
Step2 partitionBy (map(featureRDD,fun= function(k,v){c(特征变名, paste(k,v,sep=“-”))}))记为partitionRDD,将其缓存。
中国在全球奢侈品市场扮演的重要角色已无需解释,值得注意的是,过去一年,拥抱互联网和电商正逐渐成为钟表行业的主流趋势,特别在中国市场,不少代表传统钟表业核心价值的高端品牌正突破以往束缚,大胆试水线上渠道。
Step3 map(partitionRDD,fun= function(k,v){c(unlist(strsplit(v)) [1],paste(key, unlist(strsplit(v))[2],sep=“-”))}),将结果记为splitfeatureRDD并缓存。
Step4 调用map(splitfeatureRDD,fun= function(k,v){c(v,1)})函数,结果记为denRDD。
Step5 调用lapplyPartition(denRDD,fun=reduceByKey)函数。
Step6 调用unionRDD(splitfeatureRDD,labelRDD)函数,结果记为combineRDD。
Step7 调用lapplyPartition(combineRDD,fun=reduceByKey)函数。
Step8 调用map(combineRDD,fun= splitfun2)函数,结果记为numRDD。
Step9 调用lapplyPartition(numRDD,fun=reduceByKey)函数。
Step11 调用split(featureRDD,cp)函数,调用split(labelRDD,cp)函数
Step12 重复步骤1-8,直到满足停止条件。生成CART树。
Step10基尼指数中概率p为numRDD与denRDD中元素的value相除,分离变量的取值在样本中的占比为denRDD中的value/m。Step11选取Gini值最小的变量,将样本集按照该变量取值划分成两个子集,用key值保证样本对应完整。
整个算法终止条件为节点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值,或者没有更多的特征。分布式生成CART树后可以利用生成好的CART模型分布式并行分类,只需将数据样本初始化为RDD,然后按照所选取的特征并行分类即可。
2.2.2 随机森林算法的分布式实现
本文先完成样本的初始化为RDD的任务。同时将所有的特征变量名初始化为一个新的RDD,记为featurenameRDD。然后确定使用到的CART数量t,在不同节点分布式生成t棵CART棵树,方法如2.2.1节所述。其中抽样用sampleRDD算子完成。利用sampleRDD算子中的withReplacement参数来指定放回抽样和无放回抽样,完成样本的有放回抽样和特征的无放回抽样。在抽样后利用split函数将featureRDD中对应列变为新的RDD进行训练,完成随机森林算法。
2.3K-means聚类算法在SparkR上的分布式实现
K-means是一种无监督式学习算法,是典型的基于原型的目标函数聚类方法。它以数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则[14]。算法需要首先确定参数k,即整个样本数据需要被划分为多少个类。然后算法将n个数据集合划分到这k个类中,使类间相似度差距比较大,而类内相似度比较低,其中在本文中样本间的相似度以欧氏距离作为度量。下面将讨论在SparkR上如何分布式实现K-means算法。
K-means聚类算法分三个阶段求解。第一步,定义距离函数为样本点之间的欧氏距离,并求出样本与哪个聚类中心最近。第二阶段将样本按照最近的聚集点划分为k份,第三阶段重新计算聚类中心。在第二阶段计算时需要同时计算出每个类中包含样本的数量。具体实现步骤如算法3所示。
算法3K-means算法的分布式实现
输入:数据集、聚类个数k、阈值距离convergeDist
输出:k个类的中心
Step1 读入数据集,并初始化为RDD,记为pointRDD。
Step2 调用takeSample(pointRDD,withReplacement=F)函数,记为kpoint。开始循环迭代。
Step3 调用lapply(pointRDD,fun=function(p) { dist.fun(points,kpoints)}),自定义函数dist.fun = function(P,C) {apply(C,1,function(x) {colSums((t(p)-x)^2)))},记为matRDD。
Step4 调用lapply(matRDD,fun=function(x){max.col(-x)}),结果记为cp。
Step5 调用lapply(pointRDD,fun=function(x){cbind(1, x)}),将1填入每个样本,仍记为pointRDD。
Step6 调用lapplyPartition(lapply(pointRDD,function(x) {c(uninque(cp),split.data.frame(x,cp))})),结果记为splitRDD,将pointRDD划分。
Step7 调用reduceByKey(splitRDD,“+”,2L)。
Step8 计算新的中心点,定义函数计算lapply(splitRDD,function(x){sum=x[[2]][,-1],count= x[[2]][,1] sum/count}),记为newpoint。
Step9 调用lapply(newpointRDD,fun=function(p) { dist.fun(points,kpoints)}),记为d,tempDist=d, kpoint=newpoint。
Step10 当tempDist>convergeDist时,迭代Step4-Step10,直到tempDist<=convergeDist停止迭代。
Step11 输出迭代得到的kpoint。即是最后的k个类的集聚中心点。
其中Step1中使用takeSample算子无放回抽样完成抽样任务,Step3和Step4分别求出样本点到聚集点的距离以及最近的聚集点。Step8计算新的中心点。算法直到tempDist小于给定的阈值convergeDist结束。
3 实验及结果分析
3.1 社会化信息对股市波动影响验证
根据第1节的模型,本文进行了如下三组实验。选取2013年到2014年上证50所包含的50只股票作为研究样本,考虑到新闻对股价的影响有一定持续性,所以本文选取这50只股票的周收盘价作为研究节点。以2012年12月28日的收盘价作为初始节点,计算这50只股票的加权收盘价,加权方式采用上证50指数采用的派许加权。利用抓取2013年到2014年新浪财经、和讯财经、腾讯财经上的股票要闻板块新闻作为语料库,并将50家企业主题名作为特征词保存为特征词词典1,新闻权重α=0.75,β=0.25。
3.1.1 第一组实验及结果分析
在第一组实验中,本文探讨新闻信息量与股价波动的关系,实验步骤如下:
Step1 将新闻文本集分词,分布式存储到SparkR平台上。
Step2 通过算法1求取每篇新闻包含哪些特征词词典1的特征词,得到每篇新闻包含的企业主体。
Step3 分别计算50家企业的新闻信息量,并加权得到最后的新闻信息量。
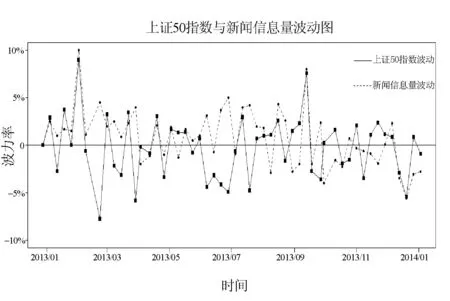
图3 上证50指数与新闻信息量波动图
从图3中可以看出,大部分情况下新闻信息量会随着指数的波动而波动,即当指数发生明显波动时,相应的新闻信息量也会波动到高点。但也存在如下问题:(1) 当股价发生明显波动时,新闻信息量波动与股指波动相差不大,而当股指波动平缓时,两者相差较大。这可能是模型一没有对新闻进行筛选,导致当股价波动较小时,仍有一些对股价影响不大的新闻发生,从而导致新闻波动率的波动幅度小于股指的波动幅度并且波动值高于股指的波动值。(2) 在有些时间段中新闻信息量的波动远远高于股指的波动,本文认为这主要由于一周的新闻信息量虽然发生了很大波动,但所包含的新闻既有正向又有负向,因此对股指波动大小的指示性不够准确。
3.1.2 第二组实验及结果分析
第二组实验通过聚类寻找由关键信息表示的新闻,而这些新闻可以实质性地影响股价上涨或者下跌。再通过分类完成对所有新闻正负情感划分,实验过程如第1节模型二所述,实验步骤如下:
Step1 将新闻文本集分词,分布式存储到SparkR平台上,筛选聚类训练集。
Step2 通过聚类提取分类训练集和特征词候选集。
Step3 按词频大小依次将特征词候选集中极性词添加到特征词中,训练分类模型,直到分类准确率不再发生明显变化。
Step4 通过人工标注调整分类模型。
Step5 对剩余新闻分类,计算新闻情感信息量。
依然按照模型一对股票波动率的定义,分别画出一年来新闻情感信息量和指数波动的时间序列图,结果如图4所示。

图4 上证50指数与新闻情感信息量波动图
从图4中可以看出,与图3相比,新闻情感信息量的波动与股价波动规律更接近,更准确地说明了两者相关性。根据市场规律,本文假设对企业股价产生影响的新闻是有规律性的,例如企业的财报,企业盈利或者亏损,企业并购重组等,但是也存在一些日常波动往往与消息面关系并不那么密切,例如超跌反弹,获利回吐,或者庄家的洗盘行为等,导致新闻情感信息量与股指波动不会完全吻合。所以本文认为,除却这些日常波动外,新闻情感信息量波动与指数波动基本相关。
3.1.3 第三组实验及结果分析
第三组实验探讨新闻情感词强度对股价波动的影响。本文引入路透社金融词典并对其进行人工修正选出其中的情感词,并保存为特征词词典2。具体实验步骤如下:
Step1 将新闻文本集分词,分布式存储到SparkR平台上。
Step2 通过算法1计算每篇新闻包含的特征词词典2中的特征词个数,计算每篇新闻的正负情感词词数之差。
Step3 通过算法1求取每篇新闻包含哪些特征词词典1的特征词,得到每篇新闻包含的企业主体。
Step4 分别计算50家企业的新闻情感词强度,并加权得到最后的新闻情感词强度。
如实验二做法,比较企业新闻情感词强度波动与指数波动的关系,结果如图5所示。

图5 上证50指数与新闻情感词强度波动图
与实验二相比,两者都可以明显地衡量股指的剧烈波动,不同的是当股指波动较小时,新闻情感词强度的波动要小于实际股指的波动。这很有可能是模型三受限于情感词典,并且新闻量较大,情感词典很难准确表达新闻情感。这导致在指数波动较小时,包含特定情感词的新闻较少,不能准确衡量股指的波动幅度。
通过上述三个实验,本文讨论了三种衡量社会化信息情感的方式并分别验证了其与股指波动的关系。通过波动图可知,模型二使用的新闻情感信息量来衡量社会化信息情感最为准确。这不仅表现在当股指波动较大时新闻情感信息量的波动幅度也较大,还表现在当股指波动较小,新闻情感信息不明显或者有效新闻量不充足时,新闻情感信息量的波动也与上证50指数波动大致一致。这主要由于模型二与模型一、模型三相比有以下两点优势:(1) 通过有偏样本的选择可以有效去除对股市波动影响较小的新闻,以便有效进行特征选择,并尽量准确地筛选出与股市波动最相关的新闻。(2) 通过聚类算法的特征选择方式可以更充分利用大量新闻灵活筛选出最有效的特征,由于这些特征所代表的新闻情感均较为突出明显,所以使用这些特征对剩余新闻进行分类时结果较为准确。在最后的情感值计算时忽略掉那些有一定量分类树给出结果为无法分类的新闻,也使得最后选取出的新闻情感较为明显,最大可能去除不相关新闻的影响。综上两点都使得模型二的新闻筛选是最有效的,这在大数据环境下,信息量庞大的情况下尤为重要。并且由于中国股市的变化日新月异,金融情感词典很难完全准确获取,使用聚类算法训练可以极大节省人力,更适合大数据环境的需求。
由上述三个实验可以证实本文的实验方案是有效可行的。利用SparkR平台可以并行化爬取、分类、聚类算法,从而提高数据处理效率。同时还可以分布式存储数据,方便完成更复杂的算法实现。尤其在特征选择时,利用SparkR的高效性,可以反复迭代训练,以提高准确率。
3.2 SparkR平台性能验证
为了进一步验证SparkR平台的性能,本文以分类模型训练为例设计一组与单机运行的对比实验,实验内容为2.2节介绍的随机森林算法在SparkR平台上运行与在单机平台上运行效率对比。本文使用第1节模型二挑选出的特征,从有偏新闻样本中选取10 000,50 000,100 000,200 000条新闻作为训练集,分别在SparkR平台和单机平台训练随机森林模型。连续运行10次分别记录两个平台所使用的时间,取其平均值作为最后的时间。
本文中搭建的实验平台有5台机器,每台机器的配置如下:CPU为Intel Core2 Duo ,内存为1 GB。Hadoop版本为2.6.0,Java版本为1.7.0_67。Spark版本为1.3.1,R版本为3.1.3。每台机器通过实验室局域网连接。最后的运行时间如表1所示。

表1 基于SparkR和单机平台随机森林算法运行时间对比
由表1可见,SparkR平台的处理时间远远小于单机平台,尤其是数据量越来越大时性能提升更为明显,说明SparkR平台运行效率远远高于单机平台。
3.3 SparkR平台伸缩性验证
为了进一步验证SparkR平台在大数据情形下的稳定性表现,本文通过测试不同数据集以及不同节点数上SparkR平台的表现情况来验证其伸缩性。测试数据集为从有偏新闻集中选取10 000、50 000、100 000、200 000条新闻,将每组实验重复进行十次,取其平均执行时间作为实验最终结果,结果如表2所示。

表2 不同节点数基于SparkR运行随机森林算法时间对比
由表2可见,SparkR平台具有良好的伸缩性,这使得本文可以通过增加平台节点数的方式来提高SparkR平台的运行效率,确保SparkR平台可以胜任大数据分析的任务。
3.4 特征选择方法对比
为了进一步说明利用有偏样本通过聚类算法进行特征筛选要比通过词典进行特征筛选有效,本文设计如下对比实验。因社会化新闻数量多且并不是所有新闻都有明确的情感态度,所以无法通过人工标注的方式来获取分类所需的训练集和测试集。因此本文从第1节模型二聚类完成后的样本中分别从正向样本和负向样本各选取3 000篇新闻作为训练集,再从聚类完成样本中挑选出600篇与训练集不重复的新闻作为验证集。由于第1节模型二的样本选择是有偏的,因此可以大概认为聚类完成后的单向新闻文本情感态度一致。然后分别通过第1节模型二的聚类算法和第1节模型三的词典进行特征筛选,并利用上述训练集训练分类模型,分类算法采用的是2.2节介绍的随机森林分类算法,再通过测试集验证分类准确率,以此来比较聚类算法与人工词典进行特征选择的有效性。为了充分验证两种方法的准确率,本文将训练集中新闻数量依次递增为1 000、2 000、4 000、6 000篇新闻进行准确率对比。将每组对比进行10次,取其平值作为最后的准确率,实验结果如表3所示。
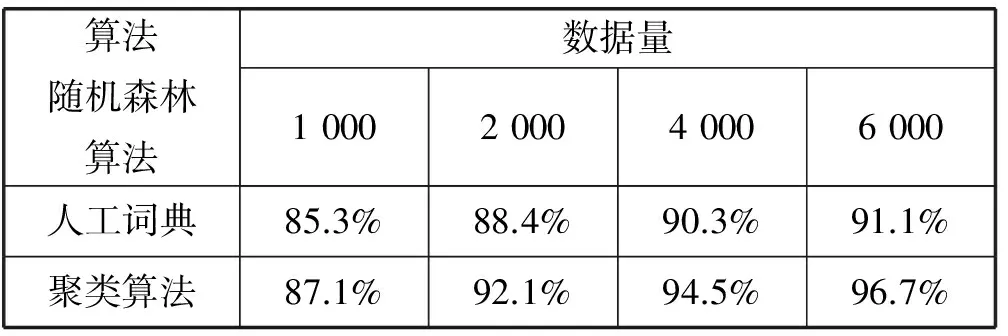
表3 基于聚类和人工字典的特征选择后随机森林算法分类准确率对比
从表3看出,虽然因为样本有偏导致两者的分类准确率都较高,但是聚类进行特征选择的准确率还是要高于人工词典法,并且随着训练集的不断增大,可以更加充分的提取关键信息,使得聚类算法的准确率更加优于人工词典,从侧面说明模型二中情感分类的准确率要高于模型三,更加有利于刻画社会化信息的情感。
4 结 语
本文讨论了基于SparkR平台分析社会化信息对股市波动性影响,并给出了综合解决方案,克服了数据量繁杂以及尽量减少了人工介入带来的不可操作性。本文通过三个实验详细阐述了如何衡量社会化信息的情感并分别验证了其对股市波动的影响。其次,还分析了SparkR平台的性能以及伸缩性,证明了该平台可以有效地用于大数据环境下的金融数据分析。最后,通过实验验证了聚类算法进行特征选择的有效性,讨论并分析了三个模型的各自优缺点。不过现在SparkR平台还处于发展初期,文中选择实现的算法比较基础,后期可以尝试通过改进算法来适应更加复杂的应用,同时进一步研究量化方法以便更准确地说明社会化信息对股市的影响作用。
[1] Amplab-extras.SparkR(R frontend for Spark)[EB/OL].[2014-9-25].http://amplab-extras.github.io/SparkR-pkg/.
[2] The R Foundation.The R Project for StatisticalComputing[EB/OL].[2014-10-6].http://www.r-project.org/.
[3] Lavrenko V,Schmill M,Lawrie D,et al.Mining of concurrent text and time series[C]//KDD-2000 Workshop on Text Mining.2000:37-44.
[4] Bollen J,Mao H,Zeng X.Twitter mood predicts the stock market[J].Journal of Computational Science,2011,2(1):1-8.
[5] Gilbert E,Karahalios K.Predicting tie strength with social media[C]//Proceedings of the SIGCHI Conference on Human Factors in Computing Systems.ACM,2009:211-220.
[6] Zhang X,Fuehres H,Gloor P A.Predicting stock market indicators through twitter “I hope it is not as bad as I fear”[J].Procedia-Social and Behavioral Sciences,2011,26:55-62.
[7] Peramunetilleke D,Wong R K.Currency exchange rate forecasting from news headlines[J].Australian Computer Science Communications,2002,24(2):131-139.
[8] 黄润鹏,左文明,毕凌燕.基于微博情绪信息的股票市场预测[J].管理工程学报,2015,29(1):47-52.
[9] 赖凯声,陈浩,钱卫宁,等.微博情绪与中国股市:基于协整分析[J].系统科学与数学,2014,34(5):565-575.
[10] 朱浩然,梁循,马跃峰,等.金融领域中文微博情感分析[C]//第八届中国管理学年会——中国管理的国际化与本土化,2013.
[11] 王岩.面向金融领域BBS的话题发现和热度评价[D].哈尔滨工业大学,2010.
[12] Zaharia M,Chowdhury M,Das T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX conference on Networked Systems Design and Implementation,2012.
[13] De Ath G,Fabricus K E.Classification and Regression Trees:A Powerful Yet Simple[J].Technique for Ecological Data Analysis,2000,81(11):3178-3192.
[14] 周丽娟,王慧,王文伯,等.面向海量数据的并行KMeans算法[J].华中科技大学学报(自然科学版),2012(S1):150-152.
THE RESEARCH OF THE IMPACT OF SOCIAL INFORMATION ON STOCKMARKET VOLATILITY BASED ON THE SPARKR
Ni Liping Ma Chiyu Liu Xiaojun
(SchoolofManagement,HefeiUniversityofTechnology,Hefei230009,Anhui,China)(KeyLaboratoryofProcessOptimizationandIntelligentDecision-making,MinistryofEducation,Hefei230009,Anhui,China)
With the rapid development of information society, social information is becoming richer. This information will influence the stock market volatility. However, the data is in huge amount, and most of them are unstructured, thus increasing the difficulty of analyzing the impact of the social information on the market. This problem is trying to be solved by the distributed calculating technology and discuss the impact of social information on the stock market from two aspects of information volume and information sentiment. By building SparkR platform firstly how to use this platform to solve the problem of feature selection and sentiment classification of social information of the stock market is discussed. Secondly, the impact on the market of information volume and sentimental information is compared. Experimental result shows the sentimental information can accurately describe the changes of market. In order to validate the feasibility of this solution further, this paper defines the different sentimental measurement method, compares the advantages and disadvantages of these different solutions, and then gives the integrated solutions for analyzing the impact of social information on stock market volatility. Finally, the effectiveness of the proposed solution is verified by experiment.
SparkR Feature selection Distributed analysis Text mining Sentiment classification
2016-01-13。国家自然科学
71301041,71271071)。倪丽萍,副教授,主研领域:金融数据分析,数据挖掘,人工智能。马驰宇,硕士。刘小军,硕士。
TP181 TP391
A
10.3969/j.issn.1000-386x.2017.03.033
