一种面向财务文本分类的TF-IDF改进算法
2020-02-22孙德华孙晨
孙德华 孙晨
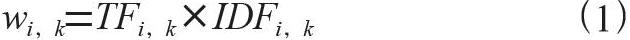
摘 要:结合财务文本特征,对TF-IDF方法在应用到财务文本分类时的不足进行了分析,提出了一种新的特征词权重计算方法(SNGTI-LFDF)。该算法以TF-IDF方法为基础,引入停用词失效的N-Gram方法和特征词位置词频因子,保留特征词位置信息并改善了特征词的权重分配。采用朴素贝叶斯方法对分类性能进行了验证,实验结果表明,相对于TF-IDF和同类改进算法TF-IDF-DL,SNGTI-LFDF方法取得了更高的准确率、召回率和F1值。因此该算法在能较好地提高财务文本分类性能。
关键词:TF-IDF;N-Gram;位置因子;SNGTI-LFDF;财务文本分类
中图分类号:TP301.6 文献标识码:A 文章编号:2096-4706(2020)18-0107-05
Abstract:Combining with the characteristics of financial texts,the TF-IDF algorithm was investigated for its shortcomings when applied to financial text classification,and a new algorithm for calculating the weight of feature words (SNGTI-LFDF) was proposed. This algorithm is based on TF-IDF method,and introduces the N-Gram method of invalid stop words and term frequency location factor,which retains the location information of the feature word and improves the weight distribution of the feature word. The Naive Bayes method is used to verify the classification performance. The experimental results show that compared with TF-IDF and the similar algorithm TF-IDF-DL,the SNGTI-LFDF method achieves higher accuracy,recall and F1 value. Therefore,the algorithm is better improving the performance of financial text classification.
Keywords:TF-IDF;N-Gram;location factor;SNGTI-LFDF;financial text classification
0 引 言
隨着信息技术的发展,网络文本充斥着人们生活的方方面面,财务文本是网络文本中的一大分支,在财务危机预测[1]、资本市场调研、企业管理等方面都有重要的指示作用。就财务文本的性质和作用可以将其划分为政策类财务文本、规章制度类财务文本、统计数据类财务文本。其中政策类财务文本是国家各行政部门、企业财务部门等针对财务状况出台的一系列财务管理的方针、政策,这类文本为个人和企业提供政策指引,做出更好的财务决策;规章制度类财务文本是各企业制定的符合企业发展的章程,对企业和财务工作者制定符合其发展的规章制度有很高的参考价值;统计数据类财务文本是符合客观财务信息并能反映一段时间内企业财务状况的文本,统计类财务文本可以帮助规避投资风险、预防财务诈骗等。然而在这个大数据时代下,各类财务错综复杂,使得我们很难快速准确地找到所需类别的财务文本,由于缺乏信息资料进而造成损失。作者结合实习项目“财务机器人”的开发,对智能财务机器人的实现进行了深入调研,智能财务机器人的实现要依据大量的已知类别的财务文本,通过学习每种类别的文本的特征,总结经验,实现智能化。因此如何快速准确地对财务文本进行分类就成了一个待解决的课题,传统的基于人工进行财务文本分类同时存在效率低下和人为失误不可避免等问题。机器学习和人工智能技术的发展使得自动高效地进行财务文本分类[2]变成了可能,有效地改善了人工分类时所带来的问题,它通过学习已标记类别的文本集,建立文本特征词与文本类别之间的关系模型,进而通过该模型对新的文本进行类别判定。
对文本进行分类要遵循文本所具有的特征。本文拟根据财务文本特征定向的改进文本分类中常用的方法——TF-IDF算法[3],以较好地提升财务文本分类的性能。因此本文收集调研了大量的财务文本并对财务文本的特征总结为:
(1)财务特征词的不可分割性:财务特征词又可叫作财务术语,不可分割性是指一旦分割就会偏离原词所表达的含义。如“固定资产”虽然可以被拆分为“固定”和“资产”两个有实际意义的词,但是其已经偏离了原特征词所表示的含义;
(2)财务文本结构的严谨性:结构的严谨性是指大多数财务文本都符合类似“总分总”这样的文本特征,在文本始末都会出现对文本进行总结的内容。
TF-IDF算法是一种基于词频统计的特征权重计算方法,通过计算词频和逆文档频率来计算特征词的权重,在应用到文本分类时取得了良好的效果,但是传统的TF-IDF方法还存在有明显的缺陷,第一,依赖于特征词提取的效果,在特征词提取准确率不高的情况下,分类性能较低;第二,未考虑特征词出现的位置信息,默认赋予所有特征词同样的权重。基于此,结合财务文本的特性,本文的主要工作为:
(1)引入了基于去停用词的N-Gram方法,在丰富特征词的同时清除了无效特征词带来的影响;
(2)引入特征词位置因子,加重符合文本主题的特征词的权重;
(3)提出了基于N-Gram特征词失效和位置因子和词频统计的TF-IDF方法(SNGTI-LFDF)并在财务数据集上取得了良好的效果。
1 相关工作
为了考虑一个词语对其上若干个词语的依赖关系,Jestes[4]等人在2013年便提出了N-Gram的概念,N-Gram在保留词汇的特征信息的同时也保留了特征词的位置信息;文献[5]将N-Gram方法用到计算机病毒特征码的提取中,取得了较好的结果;文献[6]在SQL注入检测中结合N-Gram中提取SQL语句固定维数的特征向量,提高了检测率降低了误报率;文献[7]将N-Gram模型结合卷积神经网络,从而提升了短文本分类的分类性能。文献[5-7]的结果表明,N-Gram方法与特定领域结合使用时,可以在一定程度上取得较好的效果。
对于TF-IDF算法来说,其核心就是特征词的权重计算,计算方式为:
其中,wi,k为文本i中的第k个特征词的权重。针对传统的TF-IDF算法存在的不足,众多学者都其进行了研究改进。文献[8]通过改进特征词权重计算,提出词频-逆重力矩计算方法,提升分类效果;文献[9]引入去中心化词频因子和特征词位置因子,加强特征权重的准确性;文献[10]将新词纳入TF-IDF的权重计算中,达到了特征降维的目的,提升了文本分类的效果;文献[11-12]均引入权重影响因子,对TF-IDF算法的权重进行优化,这些改进算法虽然提升了文本分类的准确率,但其在应用到财务文本分类时,由于未结合财务文本特征,还存在着一定的局限性。
2 改进的TF-IDF权重计算方法
2.1 基于停用词失效的N-Gram方法
N-Gram方法是从一个句子中提取连续的N个字的字符串集合,可以获取到字的前后信息的同时还可以提高特征词提取的丰富程度。例如“资产转移手段”,如果按照传统的TF-IDF涉及的关键词计算过程,其关键词信息只有“资产、转移、手段”,但结合N-Gram方法进行词汇特征的选取,以2-Gram为例,程序和执行结果如下所示:
In[1]: content = “资产转移的手段”
...: ls_word = list(content)
...: bigram = []
...: for i in range(len(ls_word)-1):
...: word = “”
...: for j in range(i,i+2):
...: word+=ls_word[j]
...: bigram.append(word)
...: print(bigram)
[“资产”,“产转”,“转移”,“移的”,“的手”,“手段”]
由以上结果可以看出,原来仅有的3个特征词,经过2-Gram的处理变长到了6个,特征词的丰富程度得到了极大的提升,但这种方式也带来了无效特征词的干扰,如上述结果中的“产转、移的、的手”,这类特征词不仅不具备特定的意义而且还会对文本处理的结果产生干扰,影响文本分类的性能。其中部分的无效特征词可以通过一定的手段将其识别并从特征词分词表中删除,如“移的、的手”两词都包含有字符“的”,而“的”通常是描述定語和形容词之间的修饰关系,与其组成的词在语义上无任何意义,相同的一类词在文本中经常出现的还有“是、为、也、了、个”等,与这些词组成的特征词在语义上无任何意义,因而又被称为停用词。停用词失效是指一个特征词如果包含有停用词,那么这个特征词是无意义的,对文本分类结果产生负面影响。
基于停用词失效的N-Gram方法就是在使用N-Gram方法进行特征词划分选取时,对特征词是否包含停用词进行判别,判别公式如式(2)所示:
其中,termi,k指文本i中的第k个特征词,validi,k第k个特征词的有效性,stw指停用词。
其具体步骤为:
(1)使用N-Gram方法对文本处理得到一个特征词集合TC;
(2)使用式(2)对TC中的第k个特征词进行有效性判定,结果为True则转到步骤(3);若结果为False,转到(4);
(3)从TC移除当前的第k个特征词,TC长度减1;
(4)k加1,转到(2),直到k值等于TC的长度,结束处理过程。
2.2 特征词位置词频影响因子
在财务文档中,大多数文档都符合中文文本“总分总”的结构,即在文本的开始和末尾都会包含符合文本主题的特征词信息,这类特征词对文本较为重要,应该赋予更高的权重,所以本文将特征词的位置信息作为特征词权重调节的重要影响因子。以1为度量单位,将所有的特征词以第一次出现的位置排列成一个序列,取文本序列最中间的位置为原点,建立二维直角坐标系,x轴存储特征词的相对位置信息,y轴存储特征词的词频(Term Frequency,TF)信息,以原点为基础,计算其他特征词与原点的距离(x轴绝对距离),距离越大,说明其越是位于文本的开始或者末尾,应该赋予更高的权重。在一份文档中,文本的开始和末尾包含有若干特征词,特征词的TF值可以客观地反映特征词对文本的重要程度,将特征词位置因子和词频因子结合,距离越远、频次越高的特征词对文本更重要,应赋予更高的权重。但在实际处理过程中,会出现某个特征词在长文本中出现的频次比短文本中出现频次高,产生偏袒长文本的现象,因此需要对TF值进行规范化处理,通过取特征词的词频和文本中特征词的总数的比值定义规范化公式如式(3)所示:
其中,RTFi,x为规范化处理后的词频值,结果取两位小数点,Mi为文本i包含的特征词的总数,TFi,x为文档i中位置x的特征词的词频。
将位置因子和词频因子结合,定义位置词频(Location Factor Term Frequency,LFDF)影响因子,要增加的文本i中x位置的权重LFDF值计算如式(4)所示:
其中,ε为权重值倍数,范围在(1,+)之间,η的范围在(0,D/2)之间,D为序列总长度。
2.3 SNGTI-LFDF算法
将基于停用词失效的N-Gram方法与特征词位置词频影响因子相结合,定义基于停用词失效和改进TF-IDF算法的特征词权重计算算法(SNGTI-LFDF),算法步骤为:
(1)引入N-Gram模型,使用2.1章节的方法对特征词集处理,得到一个有效特征词集合;
(2)引入特征词位置词频影响因子,使用式(4)计算特征词的LFDF值;
(3)将特征词的位置词频影响因子纳入TF-IDF权重计算公式中,最终得到SNGTI-LFDF公式,由式(1)和式(4)得:
其中,weighti,k为由SNGTI-LFDF算法计算的文本i中第k个特征词的权重值。
3 实验与结果分析
3.1 实验数据
目前公开的数据集中少有中文财务文本档,本文从国内一些财经网站和相关金融媒体微博、公众号等搜集整理了一个包含3 720条数据的财务文本集,其数据遵循的格式为:
为了保证出差人员工作和生活的需要,合理使用差旅费用,提高出差效率,特制定差旅费用报销管理制度。
交通工具按标准乘坐,采用实报实销制……
……
差旅费用报销制度即日起施行
同时,对获取的文档进行分类处理,将其划分为政策类、统计类、制度类三种类型的文本,各类文本的测试集和训练集数量的划分如表1所示。
3.2 实验步骤
本文采用传统的TF-IDF算法、文献[8]中的TF-IDF-DL算法和SNGTI-LFDF算法进行特征词权重计算。并使用朴素贝叶斯方法实现对文本的分类,结合实验结果进行分析,具体实验步骤为:
(1)提取特征词并将生成的特征词转化词频向量;
(2)分别采用传统TF-IDF、TF-IDF-DL和SNGTI-LFDF算法对特征词的权重进行计算,选取权重最高的M个特征词;
(3)将训练集文本的特征词送入到朴素贝叶斯分类器,训练分类器模型;
(4)对测试文本按照朴素贝叶斯理论[13]进行相似度的计算,对最后相似度的大小排序,选择相似度最大的作为待分类文本的类别;
(5)对比分析实验结果。使用准确率、召回率、和F1值作为分类器性能的评估指标。其中准确率指分类结果中正确分类为A类别的样本数占所有分类为A类别的样本数的比例;召回率指分类结果中正确分类为A类别的样本数占实际为A类别的样本数的比例;F1值为准确率和召回率的调和平均值。
3.3 实验对比
采用SNGTI-LFDF算法进行特征词权重计算时,首先需要计算出需要选取的N-Gram方法中的N值来完成特征词的划分。由于N-Gram方法也適用于所有的权重计算方法,本文采用TF-IDF方法对不同的N值设定的情况下,财务文本集分类的准确率结果进行了计算验证,结果如表2所示。由表2可知,分类的准确率、召回率和F1值随着N值的增加均有上升的趋势,在N=4时,分类的准确率、召回率和F1值均达到最高,而后随着N值的增加分类的性能不断降低,因此可以断定4为分类的一个峰值,应采用4-Gram作为本文的特征词划分方法。
3.3.1 参数选择
在文本分类中,特征词的选取直接关系到文本分类的结果。少量的特征词不能准确的表达文本的主题,造成文本分类效果较差,但特征词数量过大,也会对实验产生一定的消极影响。因此在分类前,首先要计算出需要送入朴素贝叶斯分类器中的权重值最高的M个特征词数量M。由于特征词数量的选取适用于所有的权重值计算方法,因此本文采用传统的TF-IDF方法在财务数据集上的文本分类的准确率和时间两个方面综合考虑M值的选取,图1为特征词数量对分类的准确率的影响。
假设文本i中的特征词的总数量为D,由图1可知,当选取的特征词数量M占总量D的40%左右时分类的准确率增长速度开始变慢,由图2可知,当M占总量D的50%时,分类需要的时间开始急剧增加。因此,为了兼顾文本分类的准确率和时间性能,本实验选取中间值45%作为每个文本作为分类的特征词数量比例,即M=0.45×D。
此外还需要计算出特征词位置信息的影响因子ε和η的值。η值反应特征词的位置信息,ε为加权因子。本文等比例地从三个种类的财务文本集中抽取200个文本,其中政策类财务文本70个、统计类财务文本82个,制度类财务文本48个,对每个文本经过4-Gram方法进行分词后,分别计算每个财务文本的始末特征词数量与文本特征词总数量的商,得到一个文本比例数据集,经过对数据集进行分析,发现其符合均值μ为0.12,方差σ为0.03的正态分布,其分布如图2所示,因此可以假设所有的财务文本的始末特征词数量与特征词总数量的商也都符合这一分布,即需要根据位置信息对特征词进行加权操作的特征词数量占总特征词数量的12%,此外,对这200个文本进行平均特征词权重数量的计算,得到每个文本平均特征词数量为545,由于这200个文本是随机选取的,可以认为整财务文本数据集中的平均特征词数量为545,因此η的最优值计算为545×(1-0.12)/2,即η=240。
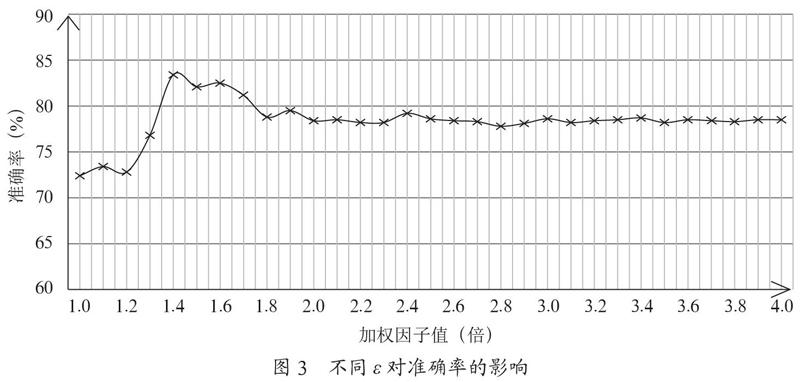
在η值确定后,把ε作为变量,对财务文本分类的准确率进行了验证,结果如图3所示。
由图3可知,随着加权因子ε的增加,文本分类的准确率也会有一定的提升,但在ε值达到1.4时,分类的准确率达到峰值,此后ε值再增加,分类的准确率反而会降低,因此本文选取ε=1.4作为特征词权重的调节值。
3.3.2 结果分析
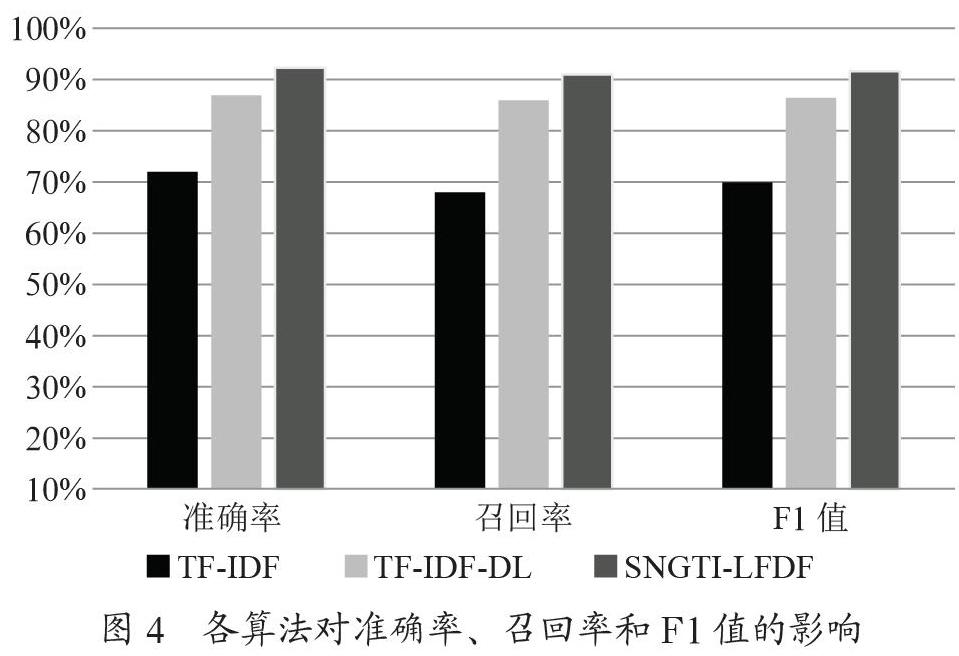
完成了对各个实验参数的求解,分别使用TF-IDF、TF-IDF-DL和SNGTI-LFDF算法对财务数据文本进行特征词权重的计算,并将训练集文本的特征词经由贝叶斯方法训练得到朴素贝叶斯分类器,对测试集文本进行验证,记录每个方法计算得到的准确率、召回率和F1值,结果如图4所示。
通过实验对比,由图4可知,SNGTI-LFDF算法在财务文本分类的准确率、召回率以及F1值的性能表现方面都较TF-IDF和TF-IDF-DL算法有了较明显的提升。其中SNGTI-LFDF的准确率、召回率以及F1值较TF-IDF方法分别提升了20.3%、23.0%和21.7%,较TF-IDF-DL算法分别提升了5.3%、5.0%和5.2%。说明SNGTI-LFDF在财务文本分类中,能适应财务文本的特征,分类效果更好,是一种良好的特征词权重计算方法。
4 结 论
通过调研财务文本的特征,总结TF-IDF方法在应用到财务文本分类中存在的不足,引入N-Gram方法进行财务文本特征词提取的同时引入特征词位置因子对TF-IDF方法进行改进,提出SNGTI-LFDF算法并结合朴素贝叶斯方法对算法的性能进行验证。实验采用自整理的财务文本数据集,结果表明该算法在财务文本分类中取得了较高的准确率、召回率和F1值,较好地提升了财务文本分类的效果。
参考文献:
[1] 刘佳明.引入财务状态分析的上市公司财务危机预测方法研究 [D].哈尔滨:哈尔滨工业大学,2018.
[2] 苏金树,张博锋,徐昕.基于机器学习的文本分类技术研究进展 [J].软件学报,2006(9):1848-1859.
[3] QU Z,SONG X,ZHENG S,et al. Improved Bayes Method Based on TF-IDF Feature and Grade Factor Feature for Chinese Information Classification [C]// 2018 IEEE International Conference on Big Data and Smart Computing (BigComp),2018:677-680.
[4] KIM Y,PARK H,SHIM K,et al. Efficient processing of substring match queries with inverted variable-length gram indexes [J]. Information Sciences,2013,244:119-141.
[5] YANG Y,JIANG G P.Improved Method of Computer Virus Signature Automatic Extraction Basedon N-Gram [J]. Computer Science,2017,44(S2):338-341(in Chinese).
[6] 萬卓昊,徐冬冬,梁生,等.基于N-Gram的SQL注入检测研究 [J].计算机科学,2019,46(7):108-113.
[7] WANG H T,HE J,ZHANG X H,et al. A Short Text Classification Method Based on N-Gram and CNN [J]. Chinese Journal of Electronics,2020,29(2):248-254.
[8] CHEN K W,ZHANG Z P,LONG J,et al. Turning from TF-IDF to TF-IGM for term weighting in text classification [J]. Expert Systems With Applications,2016,66:245-260.
[9] 许甜华,吴明礼.一种基于TF-IDF的朴素贝叶斯算法改进 [J].计算机技术与发展,2020,30(2):75-79.
[10] 叶雪梅,毛雪岷,夏锦春,等.文本分类TF-IDF算法的改进研究 [J].计算机工程与应用,2019,55(2):104-109+161.
[11] 董蕊芳,柳长安,杨国田.一种基于改进TF-IDF的SLAM回环检测算法 [J].东南大学学报(自然科学版),2019,49(2):251-258.
[12] 但唐朋,许天成,张姝涵.基于改进TF-IDF特征的中文文本分类系统 [J].计算机与数字工程,2020,48(3):556-560.
[13] LIU P,ZHAO H H,TENG J Y,et al. Parallel naive Bayes algorithm for large-scale Chinese text classification based on spark [J].Journal of Central South University,2019,26(1):1-12.
作者简介:孙德华(1994—),男,汉族,河南周口人,硕士研究生在读,研究方向:自然语言处理。
