基于Hadoop平台的农产品价格数据爬取和存储系统的研究
2017-04-14杨晓东郜鲁涛杨林楠刘建阳
杨晓东 郜鲁涛 杨林楠* 刘建阳
1(云南农业大学基础与信息工程学院 云南 昆明 650201)2(云南省信息技术发展中心 云南 昆明 650228)
基于Hadoop平台的农产品价格数据爬取和存储系统的研究
杨晓东1郜鲁涛1杨林楠1*刘建阳2
1(云南农业大学基础与信息工程学院 云南 昆明 650201)2(云南省信息技术发展中心 云南 昆明 650228)
目前许多大型农贸市场和农业信息商务平台都在实时发布每天各地区不同农产品的价格数据。针对数据更新快、数据量大、数据形式多样,使数据的爬取和存储以及后续的分析工作变得困难,提出基于Hadoop的农产品价格爬取及存储系统。利用HttpClient框架结合线程池通过多线程爬取,爬取结束后执行完整性检查,过滤出信息不完整的网页,进行二次爬取直到信息完整。对爬取到的网页使用正则表达式进行解析和清洗,提取有用的数据,以文本文件的形式存入HDFS(Hadoop Distributed File System ),此后爬取到的数据以追加的方式写入HDFS 文件中。实验表明HDFS的写入性能满足爬取数据不断递增的现状,副本数越少,数据块越大,写入性能越好。
分布式系统 爬虫 Hadoop HDFS 正则表达式
0 引 言
随着互联网的快速发展,预计2020年全球数字规模将达到40 ZB[1],数据类型以结构化、半结构化和非结构化三种为主,其中半结构化和非结构化数据的存储是当下面临的主要问题。如今全国各地的大型农贸交易市场和农业信息商务平台,借助互联网的实时性高、传播速度快、覆盖面广等特点,在实时发布农产品价格,更新供需数据。出现价格数据不断增加却过于分散的情况,因此通过网络爬虫爬取相关网页,抽取有价值的数据进行存储和应用十分重要。
Hadoop分布式框架支持海量存储,快速数据访问的分布式处理,具有可扩展性、失效转移等特点[2-3]。其中HDFS是分布式文件系统,提供高吞吐量的数据访问,能存储从GB级到TB级别大小的单个文件,以及数千万量级的文件数量。针对从农产品价格网站爬取到的网页大小不等,文件数量过多等特点,HDFS不像其他文件系统,一个小于数据块大小的文件占据整个块。
HDFS文件系统将元数据文件存储在Namenode节点的内存中,因此存储的文件总数与Namenode的内存容量密切相关。文献[4]-文献[7]针对HDFS文件系统的弊端,分别提出了优化方案,使文件存储数量和写入效率都有了提升。本文存储的文件普遍在百兆以上,不断爬取数据进行追加操作,会使单个文件的大小不断增大,而文件数量不会增加。针对HDFS文件系统的不同配置,进行写入性能的测试和比较。
1 爬虫系统的设计与实现
本系统针对特定农产品价格网站进行数据爬取,系统总共分为4个模块:爬取、完整性检查、解析、HDFS存储。爬虫系统基于Hadoop框架通过URL并行爬取网页,针对不同网页的内容分类方式,根据需要设定爬取深度为n,保证数据爬取的完整性。在爬取过程中,由于网络或者被爬取网站所在服务器的稳定性,可能导致网页爬取失败。所以每次发起Http请求都会验证返回值,保证请求成功。使用正则表达式对网页进行解析,将解析得到的数据以文本文件格式存入HDFS。抽取特定标签中包含的URL放入请求函数中,循环执行上述过程直到爬取深度达到n值。
1.1 爬虫基本原理
网络爬虫的主要作用是从网上下载网页进行使用,可以建立索引提供搜索引擎的功能,解析其中的数据进行分析挖掘等[8-14]。其基本工作原理如下:首先初始化一个URL,判断该URL是否处理过,如果没有,则根据要求遍历该URL中的链接地址,爬取所有遍历的网页直到结束。然后根据一定的遍历算法传入新的初始化URL,继续遍历链接,爬取网页,直到待初始化队列中没有可用的URL为止。网络爬虫工作原理如图1所示。
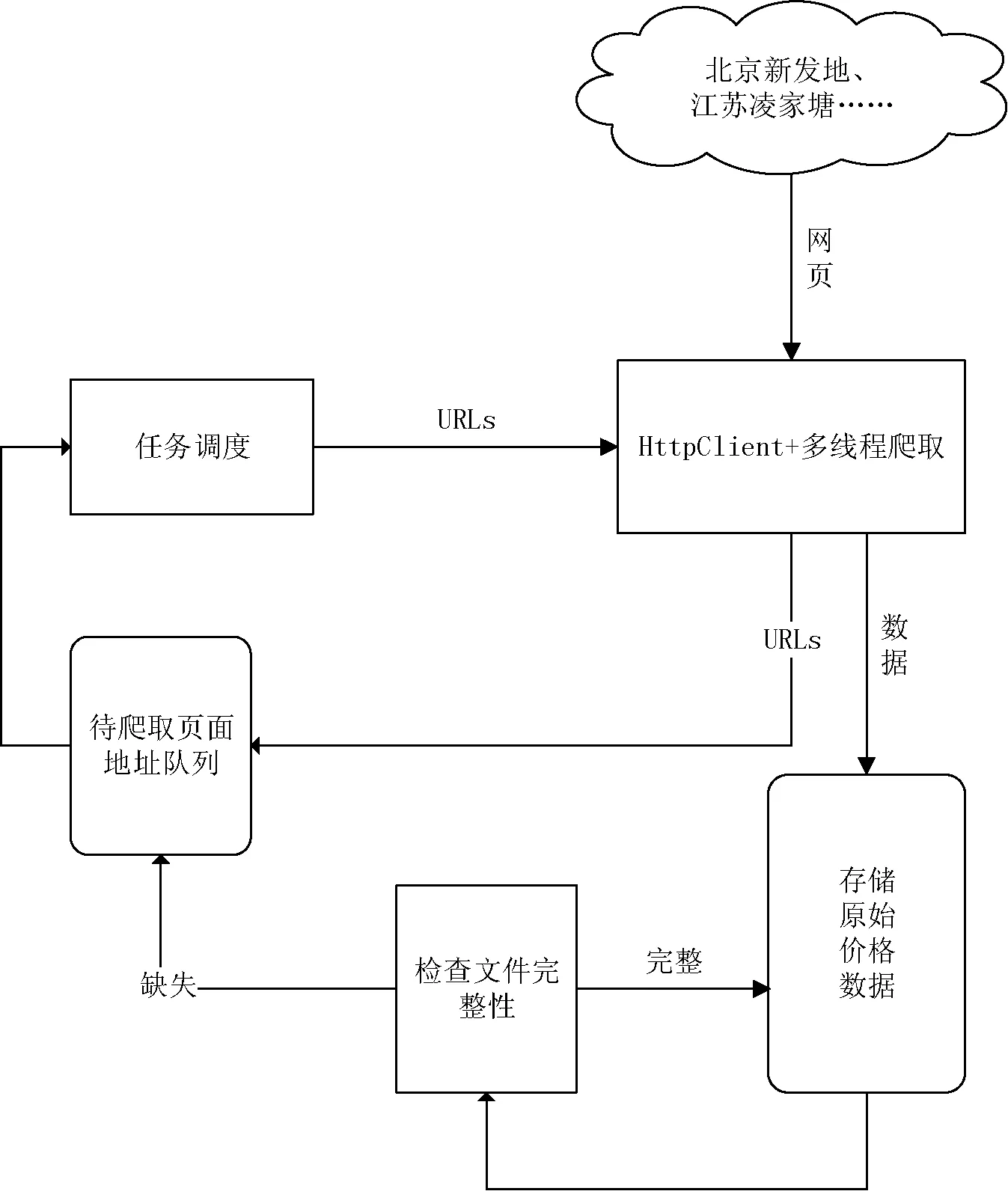
图1 网络爬虫工作原理图
1.2 爬取策略设计
在进行农产品价格数据爬取过程中,发现价格的发布方式主要分为两类:一类是以表格的形式列出所有价格数据,不支持品种、产地等方式筛选查看价格数据,例如北京新发地农产品批发市场。此类网站分页较多,但是网页中链接的页面较少,可以使用深度优先爬取网页。目前有近30万条农产品价格数据,分为1万多个页面,每个页面的Http地址可以按规则进行分解,使用多线程技术爬取页面,提高爬取的速度。另一类是支持品种、产地等筛选的价格数据表格,例如一亩田农产品商务网站。数据分页较少,但是网页中的链接页面多,适合广度优先的搜索策略,遍历所有需要的链接地址爬取网页。
1.3 爬取模块
本爬虫系统的爬取模块主要任务是读取URL地址并将其放入集合,拆分队列,使用多线程技术获取网页。基于爬取策略,分析网站内容的组织形式,对于URL地址满足特定规律即URL地址中只有部分路径或者网页名不相同,同时知道总的页面数,可拆分页面数放入不同的线程进行处理,在每个线程中通过变量循环遍历所有待爬取网页地址。以江苏凌江唐农产品批发市场为例,该市场目前共发布近1 000 000条数据,66 000多个页面。每个页面对应一个URL地址,形成一个有66 000多个地址的URL列表,将列表进行拆分放入线程池,通过HttpClient框架发起GET请求并下载价格数据进行解析。最终存入HDFS中,通过配置形成3个副本的自动备份。如图2为爬取模块工作机制。
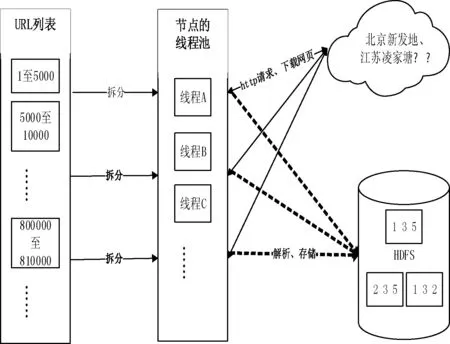
图2 爬取模块工作机制
1.4 解析模块
不同网页的编码方式差异较大,使用正则表达式针对不同的编码方式生成规则模板过滤信息,可以有效提取内容,但是会使解析工作变得繁杂和冗余,需要不断地设计解析规则。本文通过标签名或标签对中的唯一特征值锁定标签对,再抽取标签对中的内容,实验表明能快速有效提取信息,避免大量重复设计解析规则。如图3为数据解析过程。

图3 数据解析过程
通过重载FileSystem提供的get()函数确定要使用的文件系统以及读取配置文件,使用open()函数来获取文件的输入流,获取Html类型信息后通过标签名或特征值使用正则表达式解析DOM。以北京新发地农产品批发市场公布的网页价格数据为例,从body标签开始获取“class=table”的标签对,再从该标签对中获取包含价格数据的标签对“class=hq_table”,最后利用Java的split()方法通过空格拆分数据,解析出需要的数据。如图4所示为解析前数据格式,图5为解析后的数据格式。

图4 解析前数据格式
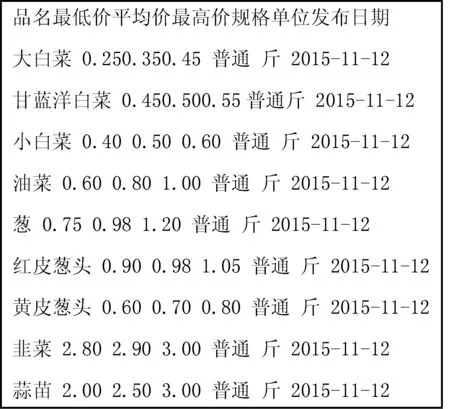
图5 解析后数据格式
2 HDFS存储模块
相对于传统的分布式文件系统,HDFS具有高容错性和高可用性的特点[15]。HDFS的“一次写,多次读”的特性,很好地支持大数据量的一次写入、多次读取,有助于对元数据的保存和后期的查询分析。HDFS文件系统包括一个主控节点NameNode和一组DataNode节点,NameNode用于管理整个文件系统的命名空间和元数据,DataNode是实际存储和管理文件的数据块。图2中HDFS包含三个小方块,每个方块代表一个DataNode节点,节点中重复的数字表示数据的副本,本系统通过配置hdfs-site.xml文件中的dfs.replication属性,将副本数设置为3个。
分布式文件系统HDFS提供了命令行和API两种文件操作方式,包含常用的写入、读取、关闭等操作。本系统使用正则表达式解析原始网页并保存为文本文件格式,此后通过append()方法向文件中不断追加解析出来的数据。以下是通过API将数据写入HDFS的过程:
1) 通过Path类定义需要的路径,该路径为即将写入数据的路径。
2) 在创建文件系统实例前,需要获取当前的环境变量,Configuration类提供了封装好配置的实例,该配置在core-site.xml中设置。
3) 接下来需要重载HDFS文件系统提供的get()方法,加载当前环境变量和建立读写路径。
4) 通过FSDataOutputStream类创建输出流,其中write()方法可以对数据文件进行相应的写操作。为了提高写入速度,以及解析过程不影响写入性能,使用Java的多线程技术对数据流进行操作,将解析好的数据提前放入队列再执行写入操作。
5) 执行完写操作后,通过closeStream()方法关闭当前线程的写出流,再用notify()方法唤醒另一个线程执行写操作。数据写入HDFS的流程如图6所示。
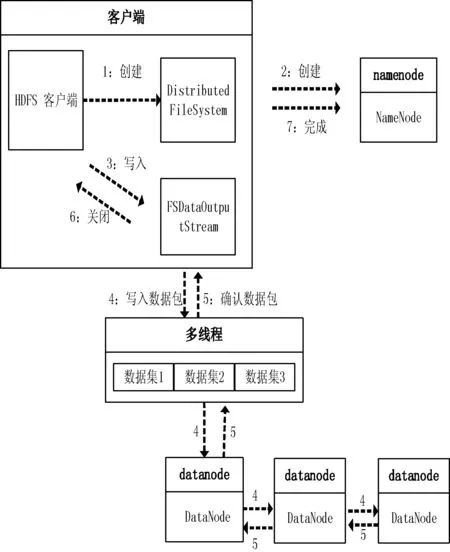
图6 数据写入HDFS的流程图
3 实验结果及分析
本系统可以解析并存储北京新发地农产品批发市场、江苏凌家塘农副产品批发市场、浙江省金华农产品批发市场、北京城北回龙观商品交易市场等。实验选取从北京新发地和江苏凌家塘农产品批发市场爬取的价格数据为测试对象。
3.1 测试环境
测试使用了3台服务器搭建测试环境,每台服务器的硬件配置见表1所示,Hadoop版本为2.6.0。

表1 硬件配置
3.2 测试数据
测试数据集为爬取的80 000多个网页,原始数据集共120多GB,通过正则表达式对数据解析后写入HDFS。
3.3 测试场景
数据块是磁盘进行数据读/写的最小单位,HDFS也一样,增大HDFS的块大小,可以减少寻址开销。实验通过设置不同的块大小和副本数量,比较HDFS的写入性能。如图7和图8为不同数据块大小,不同副本数的写入时间比较。
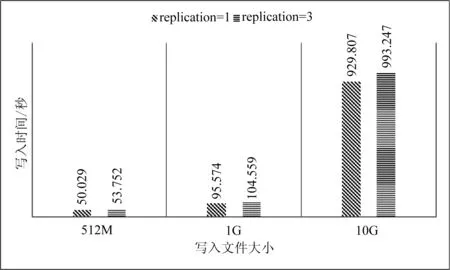
图7 HDFS写入性能(64 MB/块)
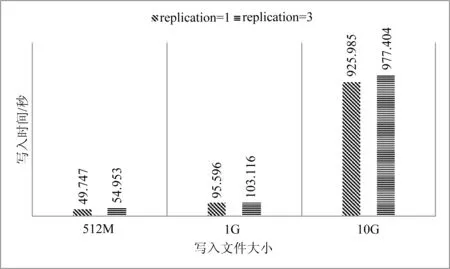
图8 HDFS写入性能(128 MB/块)
3.4 实验结果
实验过程用多线程技术预先解析数据,排除了解析速度慢导致的延迟和误差。通过实验数据可以看出1个副本的写入速度要比多个副本快,时间差距会随着数据量的变大而增大。数据块大小设置为64和128MB时的写入速度相近,总体来看,当设置数据块为128MB时写入速度要比64MB时略快。
4 结 语
本文针对网络资源的不断丰富,爬取到的数据量巨大,而且增长速度快等特点,导致后期的存储和分析难的现状。设计了网络爬虫系统并且利用Hadoop平台的HDFS文件系统进行存储,并进行了写入性能的实验设计。从实验得到的数据来看HDFS能很好地支持网络爬虫爬取的数据不断递增的现状。即使设置了多副本的备份机制,也能很好地进行数据的写入和自动备份。充分利用Hadoop平台的优势,对已经解析和清洗后的数据进行分析、挖掘是下一步的主要研究工作。
[1]IDC最新数字宇宙研究报告:中国数据量增长显著[EB/OL].2013-03-01.http://www.searchbi.com.cn/showcontent_70996.htm.
[2]BorisLublinsky,KevinTSmith,AlexeyYakubovich.ProfessionalHadoopSolution[M].Wrox,2013:3-4.
[3]TomWbite.Hadoop:TheDefinitiveGuide[M].O’ReillyMedia,2010:497.
[4] 张海,马建红.基于HDFS的小文件存储与读取优化策略[J].计算机系统应用,2014,23(5):167-171.
[5] 李铁,燕彩蓉,黄永锋,等.面向Hadoop分布式文件系统的小文件存取优化方法[J].计算机应用,2014,34(11):3091-3095,3099.
[6] 张春明,芮建武,何婷婷.一种Hadoop小文件存储和读取的方法[J].计算机应用与软件,2012,29(11):95-100.
[7] 尹颖,林庆,林涵阳.HDFS中高效存储小文件的方法[J].计算机工程与设计,2015(2):406-409.
[8] 孔涛,曹丙章,邱荷花.基于MapReduce的视频爬虫系统研究[J].华中科技大学学报(自然科学版),2015(5):129-132.
[9] 程锦佳.基于Hadoop的分布式爬虫及实现[D].北京邮电大学,2010.
[10] 万涛.基于Hadoop的分布式网络爬虫研究与实现[D].西安电子科技大学,2014.
[11] 王庆红,李广凯,周育忠,等.一种基于银行家算法的网络爬虫资源配置策略[J].智能系统学报,2015(3):494-498.
[12]PrashantDahiwale,MMRaghuwanshi,LateshMalik.PDDCrawler:Afocusedwebcrawlerusinglinkandcontentanalysisforrelevanceprediction[C]//InternationalConferenceonInformationRetrieval,7-8,Nov,2014.
[13] 于娟,刘强.主题网络爬虫研究综述[J].计算机工程与科学,2015,37(2):231-237.
[14] 周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用,2014,34(11):3131-3134.
[15] 黄宜华,苗凯翔.深入理解大数据:大数据处理与编程实践[M].北京:机械工业出版社,2014:57,65-68.
RESEARCH ON DATA CRAWLING AND STORAGE SYSTEM OF AGRICULTURALPRODUCT PRICE BASED ON HADOOP PLATFORM
Yang Xiaodong1Gao Lutao1Yang Linnan1*Liu Jianyang2
1(CollegeofBasicScienceandInformationEngineering,YunnanAgricultureUniversity,Kunming650201,Yunnan,China)2(YunnanInformationTechnologyDevelopmentCenter,Kunming650228,Yunnan,China)
At present, many large farm product markets and agricultural information commerce platforms release the information of agricultural product prices from different regions in real-time each day. Because of a large number of various fast-updating data, the data crawling and storage as well as the following analysis work come to be difficult. Therefore, we put forward a data crawling and storage system of agricultural product price based on Hadoop. We implement multi-threaded crawling by HttpClient framework combined with thread pool and finish integrity checking. After filtering out the web pages whose information is incomplete, we crawl again until the information comes to be complete. We analyze and clean the crawled web pages by regular expression, and save the useful extracted data in the form of text file into HDFS (Hadoop Distributed File System). The data crawled later is supplemented into HDFS. Experiment shows that the writing performance of HDFS can satisfy the incremental crawling data. The less duplicates are, the bigger the data block is, then the better the writing performance is.
Distributed system Crawler Hadoop HDFS Regular expression
2016-03-12。国家“十二五”科技支撑计划课题(2014BAD10B03)。杨晓东,硕士生,主研领域:数据挖掘。郜鲁涛,讲师。杨林楠,教授。刘建阳,高级工程师。
TP393
A
10.3969/j.issn.1000-386x.2017.03.013
