基于邻域三支决策粗糙集模型的软件缺陷预测方法*
2017-02-25李伟湋郭鸿昌
李伟湋 郭鸿昌
(1.南京航空航天大学航天学院,南京,210016;2.东部战区空军装备部,南京,210081)
基于邻域三支决策粗糙集模型的软件缺陷预测方法*
李伟湋1郭鸿昌2
(1.南京航空航天大学航天学院,南京,210016;2.东部战区空军装备部,南京,210081)
基于已有软件缺陷数据,建立分类模型对待测软件模块进行预测,能够提高测试效率和降低测试成本。现有基于机器学习方法对软件缺陷预测的研究大部分基于二支决策方式,存在误分率较高等问题。本文针对软件缺陷数据具有代价敏感特性且软件度量取值为连续值等特性,提出了一种基于邻域三支决策粗糙集模型的软件缺陷预测方法,该方法对易分错的待测软件模块作出延迟决策,和二支决策方法相比,降低了误分类率。在NASA软件数据集上的实验表明所提方法能够提高分类正确率并减小误分类代价。
软件缺陷分类;邻域三支决策粗糙集模型;三支决策
引 言
软件缺陷预测在减少软件开发成本和提高软件质量方面发挥着重要作用[1-3]。在软件测试过程中,通过软件缺陷预测可以帮助软件项目管理者合理安排有限的测试时间和人力资源,从而在有限的测试资源情况下提高软件测试的有效性及软件质量。目前对软件缺陷预测的研究主要可以分为两类:(1)通过对软件模块缺陷数目的预测,将某些模块定位为高缺陷率模块或低缺陷率模块,这种方法通常将软件缺陷预测看作回归问题[4]。(2)将软件缺陷预测看作分类问题[5],将软件缺陷分类为有缺陷趋势模块和无缺陷趋势的模块,通常使用决策树、贝叶斯网络、人工神经网络和支持向量机等机器学习方法[6]。也有部分学者考虑到软件缺陷预测具有代价敏感特性,将代价敏感学习方法应用到软件缺陷分类。如Zheng[7]和Arar等[8]将基于代价敏感神经网络模型用于软件缺陷分类。Liu等[9]将代价敏感特征选择和代价敏感BP神经网络应用与软件缺陷分类。不论在缺陷分类问题中是否考虑代价敏感,现有的研究都是假设缺陷分类是一个二分类问题,并应用二支决策方式,即对软件模块做出接受其为有缺陷趋势模块和拒绝其为有缺陷趋势模块的决策。二支决策方法属于立即决策方式,能够简单快速地给出分类结果,但是存在着误分类率较高的问题。简单二支决策方法会基于多数原则依据给定软件模块属于缺陷趋势模块的条件概率对其进行判定,这就导致对处于中间模糊地带不易划分的软件模块容易做出错误的决策。立即决策方式误分率较高,由此带来的误分类代价也会增加[10]。
针对此类问题提出了一种代价敏感相关的邻域三支决策粗糙集模型,并在此基础上设计了一种三支决策邻域分类方法。该分类方法考虑到软件缺陷预测的代价敏感问题,对软件模块进行分类采用三支决策方法,依据不同错误分类带来的损失代价不同,设置相应的代价函数,计算三支决策所需阈值对,将误分率高的软件模块划分到边界域中,交由专家评判或等待进一步处理,从而能够降低缺陷分类的误分类率,减少代价损失。在NASA软件数据集上进行了相应的对比实验,实验结果表明该方法能有效地提高分类正确率,降低误分类代价。
1 邻域三支决策粗糙集模型
考虑软件缺陷数据具有代价敏感特性,且通过对软件缺陷数据进行度量提取出的特征或属性取值为连续值的特点,结合三支决策粗糙集模型[11]和邻域粗糙集模型的优点,提出了一种邻域三支决策粗糙集模型,使之能够处理具有复杂特性的软件缺陷数据。
1.1 三支决策粗糙集模型
定义1 决策表可表示为一个四元组
(1)
式中:有限集合U为论域;At为属性集合;C为条件属性集;D为决策属性集;Vat表示属性at的值域;Iat:U→Vat为从U到Vat的映射函数,通常Iat假设为单值的,任意对象x∈U在属性at∈At上的取值可以表示为Iat(x)。在粗糙集领域,通常用等价类的形式来刻画或描述对象x。对象x的等价类定义为
(2)
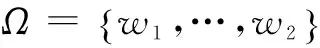
(3)
(4)
表1 不同决策行为在不同状态下的风险代价
Tab. 1 Different decision costs based on different actions
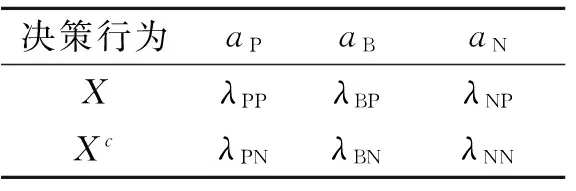
决策行为aPaBaNXλPPλBPλNPXcλPNλBNλNN
根据贝叶斯最小风险决策原则,可以得到的决策规则为
(P)若RP≤RB且RP≤RN,则判定x∈POS(X);
(B)若RB≤RP且RB≤RN,则判定x∈BND(X);
(N)若RN≤RP且RN≤RB,则判定x∈NEG(X)。
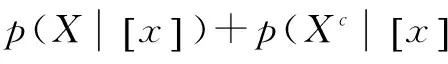
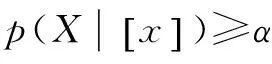
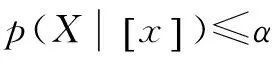
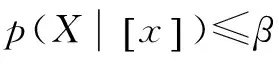
其中α,β和γ值分别为
(5)
考虑条件
(6)
可得0≤β<γ<α≤1,则可以进一步简化上述三支决策规则为
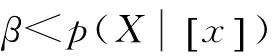
1.2 邻域粗糙集模型
经典粗糙集方法只能处理离散值,而为了能够处理数值型数据,很多学者将其扩展到邻域系统中。一种最具代表性的模型是文献[12]提出的基于距离的邻域粗糙集模型。
定义2 给定决策表S,对象xi∈U且A⊆At,在子空间A中,xi的邻域粒子δA(xi)定义为
(7)
式中Δ为度量函数,两个对象之间的Minkowski距离定义为
(8)
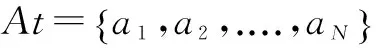
(9)
根据粗糙集的上下近似定义,邻域粗糙集的正域、边界域和负域可表示为
(10)
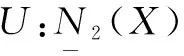
1.3 领域三支决策粗糙集模型
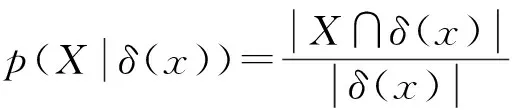
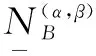
(11)
对于任意子集X⊆U,在子空间B⊆At,X的正域、边界域和负域定义为
(12)
(13)
决策粗糙集可以看作是邻域三支决策粗糙集的一种特例,即δ=0。当δ=0,δ(x)表示等价关系。另外,若邻域决策粗糙集中的α=1且β=0时,则邻域三支决策粗糙集模型转化为经典邻域粗糙集模型。
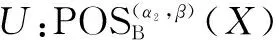
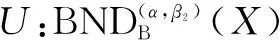
定理2表示随着α值的增大,正域单调性减小,定理3表示随着β值的增大,正域单调性减小。这两个定理表明通过修改(α,β)的值能调整X的正域和边界域的大小。
2 基于三支决策邻域分类器的软件缺陷分类方法
Hu等基于邻域粗糙集模型提出了一种二支决策邻域分类器,该分类器可以直接对连续型数据进行处理。该分类器在对对象x进行分类时,通常分配δ(x)中样本占多数的决策类标D+。二支决策分类器的优势是能够快速地对测试对象做出立即决策。然而,这种立即决策方式常常伴随更多的预测错误和更大的决策代价。假定存在一个模棱两可的对象,它被分到类别D+的概率为51%,分到类别D-的概率为49%。按照多数准则将其划分到D+中时,则意味着其有49%概率被分错。针对二支决策分类的劣势,三支决策方法则将模糊不清的对象划分到边界域中,作出延迟决策,等待专家的进一步处理。基于三支决策理论和邻域二支决策分类器,在邻域三支决策粗糙集模型下设计了一种三支决策邻域分类器用于软件缺陷分类,该分类器的目的是减少分类错误率。该分类算法具体思想如下:对于待分类的软件模块x,计算其属于有缺陷趋势类别D+的概率p(D+|δB(x)),通过判断该概率值与基于代价函数矩阵计算出的阈值对(α,β)之间的大小关系作出相应的三支决策,具体如下:
(P)若p(D+|δB(x))>α,则x属于D+;
(B)若β≤p(D+|δB(x))≤α,则x需进一步检查;
(N)若p(D+|δB(x))<β,则x属于D-。
x若为接受决策则将其划分到D+中,即为有缺陷趋势模块,x若为拒绝决策则将其划分到D-中,即为无缺陷趋势模块,x若为延迟决策则需要等待做进一步检查。详细算法如下所示。
算法1 Three-way decisions based neighborhood classifier (TDNEC)输入: Training set: 〈U,C,D〉;
Testobject:x;
Parameterω;
本文应用ANSYS Workbench全新的断裂力学有限元计算模块,建立在损伤结构一端施加固定约束,另一端施加大小为100 MPa方向背离损伤结构的均布拉伸载荷的情况下,含有中心表面裂纹损伤结构的再制造胶粘修复有限元模型,并利用位移外推法求解裂纹尖端的应力强度因子K。
输出: Class ofx.
BEGIN
(2)FOReachsinU
(3)ComputethedistanceΔ(x,s)betweenxandswiththeusednorm;//计算距离
(4)MIN=min(Δ(x,s));
(5)MAX=max(Δ(x,s));
(7)δ(x)=MIN+ω·(MAX-MIN); //计算其邻域
(8)p=p(D+|δ(x));
(9)IFp>α
(10)AssignD+totestobjectandxisadefect-pronemodule;//将其判定为有缺陷模块
(11)ELSEIFβ≤p≤α
(12)xisintheboundaryregionofD+andxneedstofurther-examined;//等待进一步处理
(13)ELSE
(14)xisanon-defect-pronemodule; //将其判定为无缺陷模块
(15)ENDIF
ENDBEGIN
在该算法中,邻域粒子的大小由阈值δ决定,采用文献[12]中建议的方式,由待测对象x的局部和全局信息动态决定,则
(14)
式中:si(i=1,...,n)为训练对象集;min(Δ(si,x))和max(Δ(si,x)分别表示si和测试对象x最小和最大距离值。
3 实验验证
本节通过实验来考察所提三支决策邻域分类器在软件缺陷分类任务上的性能,实验对比三支决策邻域分类器(TDNEC)、二支决策邻域分类器(NEC)[12],C4.5,k-NN和SVM在分类准确率、F值和误分类代价上的性能。
3.1 实验数据集和参数设置
表2的11个数据集均是NASA的实际项目,来自于公共的PROMISE库[15],包括了卫星飞行软件、卫星模拟器软件和地面站数据管理软件等。数据集覆盖了3种编程语言。在这些数据集中,缺陷模块的百分率分布为3.0%~32.29%。,每个数据采样描述一个模块的属性是否是缺陷。模块的属性包括McCabe度量值、Halstead度量值、操作符数和代码行数等。
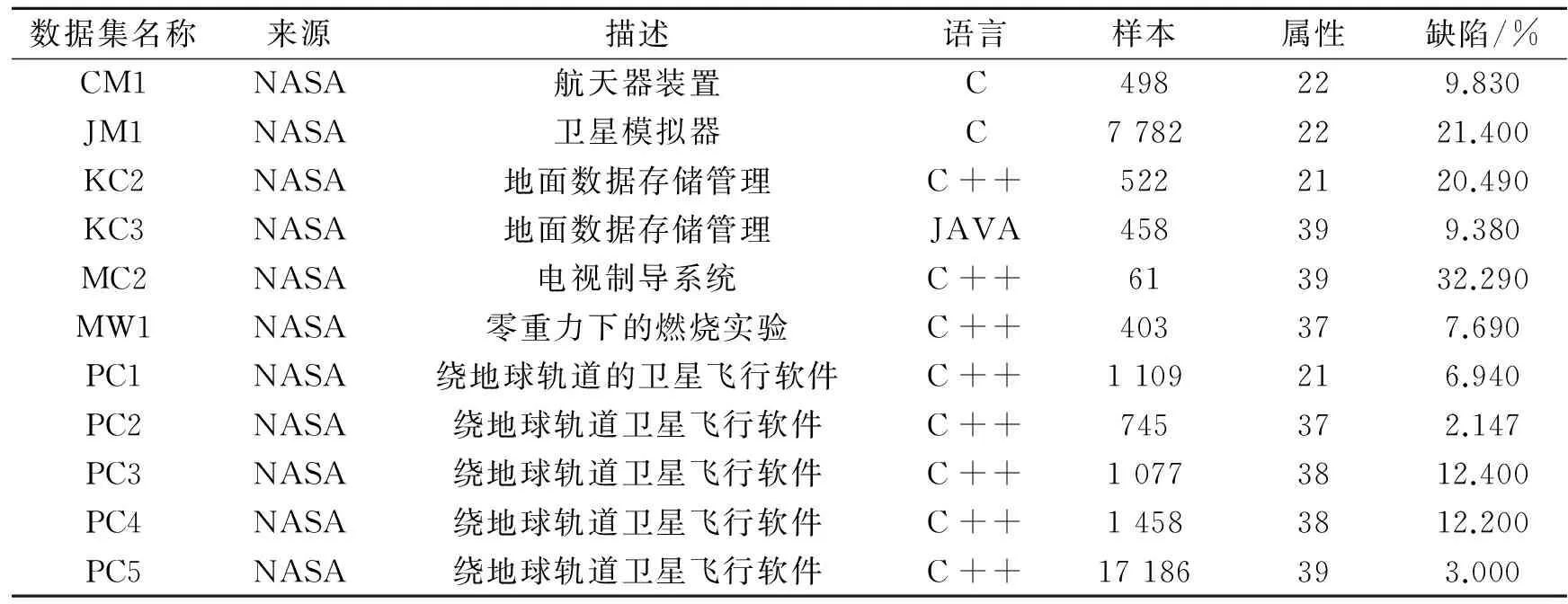
表2 NASA数据集
实验的相关参数设置如表3所示。由于采用10倍交叉验证,在试验结果中仅给出平均结果。对于每个数据集,随机产生10组不同的代价函数,即对每个分类任务运行10次10倍交叉验证。ω值参考文献[12]的设置,ω值介于0和0.1。
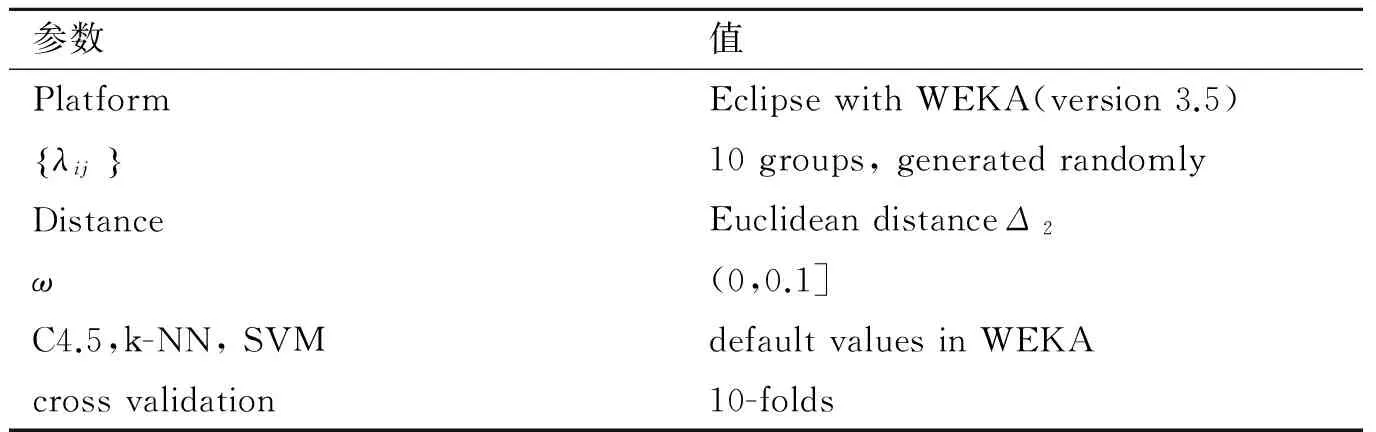
表3 实验各参数设置
3.2 评价标准
令NPP表示分类器将实际为有缺陷的模块判定正确的个数,NNN表示分类器将实际为无缺陷的模块判定正确的个数,NPN表示将无缺陷的模块判定为有缺陷模块的个数,NNP表示将有缺陷的模块判定为无缺陷模块的个数,则分类正确率定义为
(15)
覆盖率定义为
(16)
TDNEC基于三支决策,一些对象会被分类到边界域中,因此,TDNEC覆盖率的值常常小于1。在大多数情况下,分类正确率和覆盖率是一种tradeoff的关系,常用F值来表示分类器的折衷性能。基于分类正确率和覆盖率的F值定义为
(17)
基于表1给定的代价函数,误分类代价定义为
(18)
3.3 实验结果及分析
表4~6为三支决策邻域分类器,NEC,C4.5,k-NN和SVM五种分类器在分类正确率、F值和误分类代价上的性能对比结果。对于分类正确率,TDNEC在5个数据集上表现优于其他算法,SVM表现其次,4个最优,C4.5有2个最优。TDNEC由于采用三支决策方法,对于模棱两可的对象都将被延迟做进一步的检验,这在理论上保证了三支决策方法具有较高的分类精度。对于F值,SVM最好,有7个最优,C4.5其次,有2个最优,NEC有1个最优。对于TDNEC的表现,这是可预期的,因为F值是由分类正确率和覆盖度共同决定的,虽然TDNEC能够取得较好的分类正确率,TDNEC的覆盖度小于1,而其他算法的覆盖度都等于1,由此决定了TNDEC在一定程度上无法取得较高的F值。对于误分类代价,TDNEC有5个数据集上最优,SVM表现其次,4个最优,C4.5有2个最优。从理论上分析,TDNEC基于最小化贝叶斯决策代价理论,这保证了TDNEC能够得到较小的误分类代价。
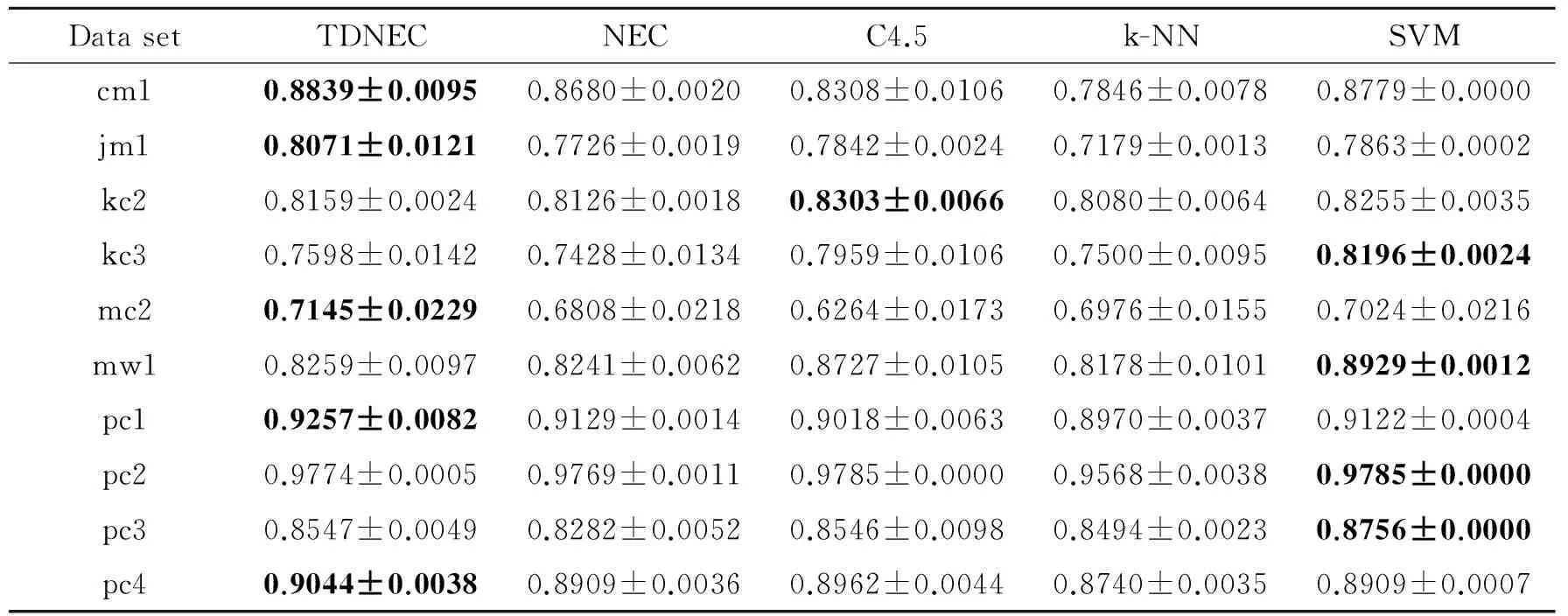
表4 各分类器在航天软件缺陷数据上分类正确率的对比结果(加粗表示最好的值)
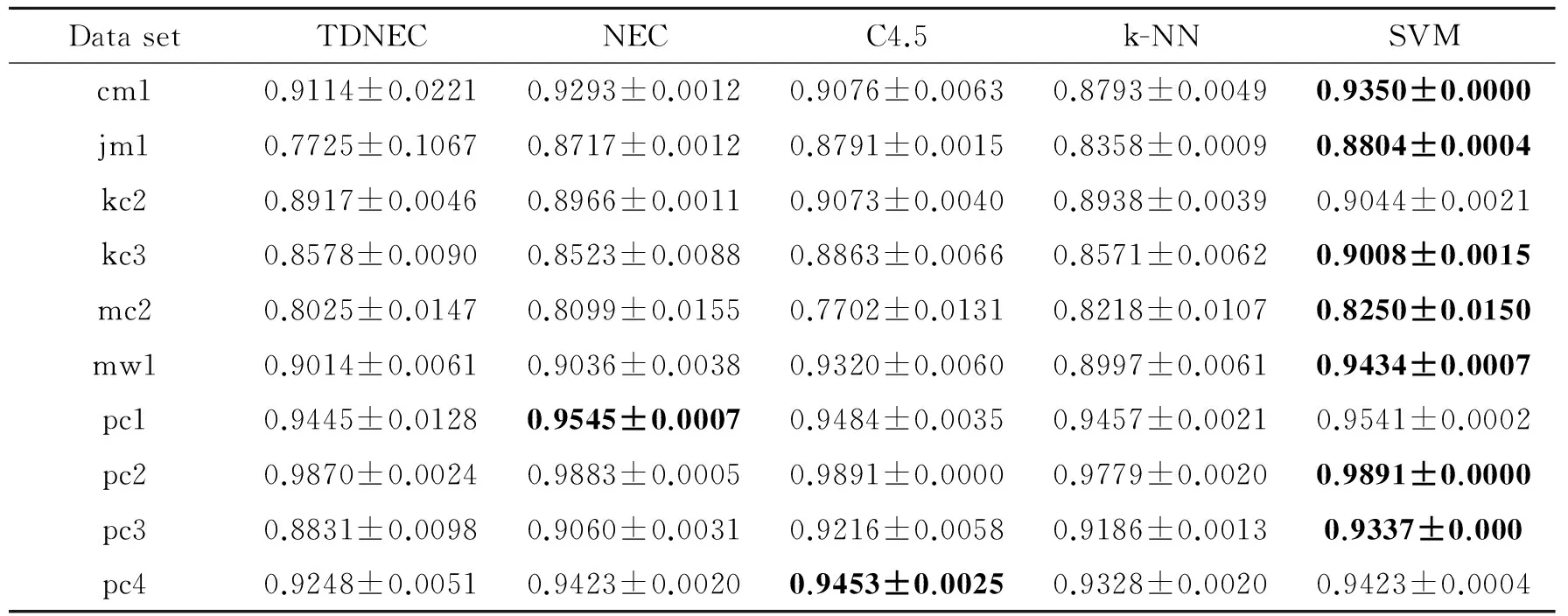
表5 各分类器在航天软件缺陷数据上F值的对比结果(加粗表示最好的值)

表6 各分类器在航天软件缺陷数据上误分类代价的对比结果(加粗表示最好的值)
4 结束语
本文针对软件缺陷数据具有代价敏感特性且属性值为连续型数据等特点,提出了一种基于邻域三支决策粗糙集模型的软件缺陷预测方法。在邻域三支决策粗糙集模型中,既可以通过代价函数矩阵求出三支决策所需的阈值,又能通过邻域系统来表示和计算连续型数据。基于该模型提出的三支决策分类器对于具有较高确信度和较低确信度的待测软件模块作出明确的接受和拒绝决策,而对于模糊不清的待测软件模块则做出延迟决策,交由专家进一步处理。在NASA数据集上的实验结果表明,三支决策邻域分类器在大部分数据集上能够取得较高的分类正确率和较低的误分类代价。
[1] Huai J P. Views about future networked software technologies[J].Communications of the CCF, 2008, 4(1):19-26.
[2] President′s information technology advisory committee. Computational Science: Ensuring America's competitiveness[R].Washington: PITAC,2005.
[3] Ramler R, Wolfmaier K. Economic perspectives in test automation: Balancing automated and manual testing with opportunity cost[C]//Proceedings of the 2006 International Workshop on Automation of Software Test. New York, USA:ACM,2006: 85-91.
[4] 王青, 伍书剑, 李明树. 软件缺陷预测技术[J]. 软件学报, 2008, 19(7): 1565-1580.
Wang Qing,Wu Shujian,Li Mingshu. Software defect prediction[J]. Journal of Software,2008,19(7):1565-1580.
[5] Lessmann S, Baesens B, Mues C, et al. Benchmarking classification models for software defect prediction: A proposed framework and novel findings[J]. Software Engineering, IEEE Transactions on, 2008, 34(4):485-496.
[6] 黎铭,霍轩.半监督软件缺陷挖掘研究综述[J].数据采集与处理,2016,31(1):56-64.
Li Ming,Huo Xuan. Software defect mining based on semi-supervised learning [J]. Journal of Data Acquisition and Processing,2016,31(1):56-64.
[7] Zheng J. Cost-sensitive boosting neural networks for software defect prediction [J]. Expert Systems with Applications, 2010, 37(6): 4537-4543.
[8] Arar O F,Ayan K. Software defect prediction using cost-sensitive neural network[J]. Applied Soft Computing,2015,33:263-277.
[9] Liu M X, Miao L S, Zhang D Q. Two-stage cost-sensitive learning for software defect prediction[J]. IEEE Transactions on Reliability, 2014, 63(2): 676-686.
[10] Li W W,Huang Z Q,Li Q. Three-way decisions based software defect prediction[J]. Knowledge-Based Systems,2016,91:263-274.
[11] Yao Y Y. The superiority of three-way decisions in probabilistic rough set models[J]. Information Sciences, 2011, 181(6): 1080-1096.
[12] Hu Q H, Yu D R, Xie Z X. Neighborhood classifiers[J]. Expert Systems with Applications: An International Journal, 2008, 34: 866-876.
[13] 杨霁琳,张贤勇,唐孝. 基于三支决策的模糊信息系统OWA算子参数选择[J].数据采集与处理,2016,31(6):1156-1163.
Yang Jilin,Zhang Xianyong,Tang Xiao. Three-way decisions based parameter selection of OWA operations in fuzzy information system[J]. Journal of Data Acquisition and Processing,2016,31(6):1156-1163.
[14] Jia X Y,Liao W H,Tang Z M,et al. Minimum cost attribute reduction in decision-theoretic rough set models[J]. Information Sciences,2013,219:151-167.
[15] Sayyad S J, Menzies T J. The PROMISE repository of software engineering databases[EB/OL].University of Ottawa, Canada, http://promise.site.uottawa.ca/SERepository, 2006-01-01/2017-01-10.
Software Defect Prediction Method Based on Neighborhood Three-way Decision-theoretic Rough Set Model
Li Weiwei1, Guo Hongchang2
(1.College of Astronautics, Nanjing University of Aeronautics and Astronautics, Nanjing, 210016, China; 2. Air Force Equipment Department of Eastern Theater Command,Nanjing, 210081, China)
Based on existing software defect data, it is possible to improve the efficiency of software testing and reduce the test cost by establishing the classification model to predict the software modules. Most machine learning based defect prediction researches are based on two-way decision method. Since software defect prediction can be seen as a kind of cost-sensitive learning problem, and the software data has continuous values, this paper proposes a classification method based on neighborhood three-way decision-theoretic rough set model. For ambiguous testing modules, compared with two-way decision methods, this method makes a deferment decision to reduce the misclassification rate. Experimental results on NASA software datasets show that the proposed method can get a higher classification accuracy and a lower misclassification cost.
software defect classification; neighborhood three-way decision-theoretic rough set model; three-way decisions
国家高技术研究发展计划(“八六三”计划)(2015AA105303)资助项目。
2016-10-21;
2017-01-01
TP18
A

李伟湋(1981-),女,助理研究员,研究方向:软件挖掘、机器学习,E-mail:liweiwei@nuaa.edu.cn。
郭鸿昌(1979-),男,工程师, 研究方向:软件工程、机器学习。
