网络嵌入视角下达成注意力经济的实证与仿真分析
2017-01-09唐四慧陈鹤鑫
唐四慧+陈鹤鑫


摘要:本文首先通过对豆瓣社区用户的实际建边行为的追溯,构建了个体获取知识的异质树状网络,然后从树状网络结构出发模拟了三个个体经济的网络模型(DLA、DLCA、BA),用实验数据统计得出与集体搜索效率相关的网络属性指标。结果显示BA模型是以牺牲“公平性”来获得小的平均最短路径,集体经济背后对应的不是个体的经济。基于DLCA模型做了三个比对实验,实验结果证明在不同的“熟人”推荐策略下得到的网络可以同时满足个体经济和集体经济。在个体有限注意力条件下,异质树状网络是高效获取知识的方式,在理论上为社区的建设提供了设计建议同时也将复杂网络的研究贴近实际,用以指导个人经济有效的使用注意力。
关键词:个体注意力经济;集体注意力经济;网络优化;异质树状网络
中图分类号:C931文献标志码:A文章编号:1009-055X(2016)06-0035-06
doi:10.19366/j.cnki.1009-055X.2016.06.006
诺贝尔奖获得者赫伯特·西蒙(HerbertA.Simon)应是注意力经济概念的最早提出者,在他的书中写到:“在信息丰富的世界里,意味着某些东西是稀缺的。因为信息是丰富的,那么稀缺的就是信息消费的东西,这种东西就是消费信息时接受者的注意力。因此我们在过载的数据中收集信息时,需要经济有效的安排我们的注意力。”[1-2]
在互联网的世界里,简洁有效的收集信息的方法有两种:一个是基于自己以往的经验——朋友推荐的方法,另一个是基于陌生人的经验——择优连接。[3]基于朋友推荐的方法就是去关注朋友关心的事务,既然是兴趣相似的朋友,那么朋友去关注的东西总是有朋友的道理;择优连接的理由是关注大家都关注的东西总是没错,错也是大家一起错。这两种高效的信息过滤方法听起来都有各自的道理,那么大家都采用了相同的策略,群体是否会达成注意力经济;在时间维度上是否会经济?
本章分为四部分,第一部分,分析两组独立的豆瓣用户的关注行为、参加小组行为数据证实朋友推荐的方法普遍存在。提出个体获取知识的树状网络模型。第二部分,用DLA模型模拟这种树状网络的生成过程,揭示网络规模与知识获取步数呈现非线性关系。进一步用DLCA模型还原多人合作情景。用整体网络指标比较DLA、DLCA、择优连接模型的信息获取效率。第三部分,以DLCA模型生成的网络结构作为Agent交互的基底,模拟三种知识寻找策略。通过最后的网络的结构评价这三种策略的经济性。第四部分,结合实证分析与仿真实验提出高效的知识获取方式应是一种多标准下的熟人推荐方式。它不仅可以达到个体搜索效率的最优而且可以达到群体搜索效率的最优。
一、基于豆瓣社区个体注意力经济的实证分析
(一)熟人推荐方式的存在
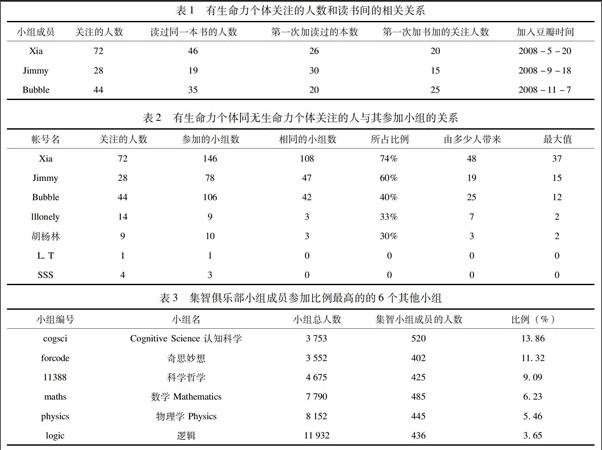
对于个体注意力经济的实验过程,包括样本的确定,实验过程,实验平台,数据分析方法我们在另外的文章中有详细的论述[4-5],这里只将与本文有关的过程和研究结论做一阐述。2008年10月要求2005级人力资源班学生在豆瓣网上建立小组,共建三个小组分别为:“贪吃蛇”“最爱港产片”和“时光影像”。时隔四年,这三个小组已不具成长性,小组中没有新的内容,新的成员或新的活动举办,但小组中有些成员一直在更新自己的主页,分享自己的知识与读书心得。我们取出这些有生命力的成员,对他们的网络进行分析,为什么要分析有生命力成员的原因在于我们认为这些成员可以经济地使用自己的注意力,这种经济性让这些成员保持了兴趣。通过有生命力个体读过书的时间序列与添加关注用户的时间序列的相关分析,发现有生命力个体会通过自己读过的书来找到关注的人。如表1所示。
接着分析有生命力个体与无生命力个体关注的人的时间序列与参加小组间的相关分析,发现有生命力的个体有通过关注的人去参加新小组的现象,而无生命力个体则相对较少用关系。如表2所示。
同时,为去除样本对于分析结果的影响,我们采用整体抽样的方法,抽取一个有生命力的小组——集智俱乐部小组,查看其用户参加其他小组的信息,并分析小组组员参加小组时是否会用到以往连边。如表3所示。
在前六个小组里,有五个小组是集智俱乐部的友情小组,只有最后一个逻辑小组不列在友情小组的集合中。从以上的数据分析中我们可以看到,在有生命力组员和小组中都有较大的比例是通过熟人推荐的方式进行知识的搜索。
(二)个体知识获取的树状网络结构
在对用户行为分析后,发现在一个时点上看到的都是该用户看了什么书、想看什么书、关注了什么人、参加了哪些小组,按传统的网络分析方法,这些均为该节点的度,计算指标只有一个。但从时间序列连边行为进行观察后发现,这些关系之间是有先后顺序的,一些边是来自于用户原有一些边的推荐,如果没有时间序列数据的支撑,这些先后的顺序就被隐藏了,我们分析时将这些形成过程按先后顺序进行恢复,用来显示“度”以外的一些特性。用户理性成边的过程还原如图1。
图1中,在原有的网络分析中只看到一个平面的一度的网络结构(图中虚线部分表示的连线)。依据成边的先后将该网络层次化,成员A及成员B都看过书A,这样通过读过同一本书的关系形成的连边1,成员A关注了成员B后,看到成员B读过的书B,这时产生连边2(通过推荐形成的边,在图中用虚线表示),表示自己也想读这本书;同时成员A看到成员B参加了小组A,产生连边3;成员A参加了小组A后发现小组A的友情小组B不错,产生连边4,成员A参加了小组B;接着成员A看到小组B收藏有书C,并对书C产生了兴趣,产生连边5。整个图给出成员A形成自己网络的先后顺序,所有这些成边由有生命力的用户的时间序列相关性分析可以得出,这体现了成员A理性的一面。[5]
二、注意力经济达成的仿真建模
(一)树状网络仿真模型
本文用有限扩散凝聚(Diffusion-limitedaggregation)网络模型来模拟树状过滤信息网络的生成过程。[6]DLA最早来自于物理学的分形体研究,在这里将之映射为Agent搜索知识的过程,个体通过累积结成自己搜寻知识的树状网络,如图2所示。整个知识的搜索过程被分为两个阶段,首先是从图2中黑色区域到达树状网络,然后树状网络中的边缘知识由熟人推荐进入中心点。在(200*200)的平面中心处置入种子,种子最早进入网络,实验中可理解为信息接收者,接着随机放置另一个粒子(选择范围是4万),可理解为接收者不知道的知识,粒子随机游走(也可理解为扩散,因为它不知道种子节点的具体位置),当它运动到种子旁边时,停止行走,与种子建立连边,这里演示的是粒子在找种子。因为运动是相对的,也可理解为种子在找这个粒子。接着第二个粒子被释放出来,也是随机游走,当它靠近种子或第一个粒子时,也停住不动,与它相邻的那个粒子(种子或第一个粒子)建立连边……如此反复,得到一个树形结构的网络,图2中A图为粒子数为3000的树形结构的凝聚体,B图显示出新加入加点找寻到树状网络所需要的步数,红线为总搜索的平均步数。因为树状网络达到3000个粒子时,其半径只有113,相对于黑色区域的找寻步骤要小很多。
在模型模拟的情境为假如个体对一件事一无所知时,在没有这种树状的信息获取网络时,寻找知识需要的步数是6个数量级,而有了树状信息获取网络后,这一寻找过程只要3个数量级的步数。B图中,我们可以看出随着树状结构的不断增大,搜索的平均步数逐渐下降(红线部分)。A图中,蓝色节点为后1500个节点,这些节点可理解为新的知识,这些知识通常是先被树最外面的分枝俘获,只有极小数的蓝色节点进入树状结构的内部,实验中共产生粒子3016个,其中由粉色粒子捕获的蓝色粒子有290个,种子节点捕获的蓝色粒子数为0个,蓝色节点捕获的蓝色粒子数为1226个,这一过程在物理学中被称为屏蔽效应,我们可以理解为,中心节点在获得新的知识时,更多的来自于自己网络中的其他节点,只有非常非常少的新知识(蓝色节点)是自己直接俘获的;同时也可理解为中心节点会屏蔽随机进入的蓝色节点,网络规模越大被屏蔽的可能性越大,过滤信息的效果越好。
(二)多人合作网络的仿真模型
在现实生活中,找寻知识的动作不是单个个体独自进行的,而是很多个节点同时进行,那么如果把DLA模型中的中心点放宽为多个,DLA模型就转变为有限扩散集团凝聚(DLCA)模型,在这个模型中中心粒子是多个。[6]与DLA不同的是DLCA模型中初始状态是许多的单体粒子被放置在二维网络中,所有粒子都处于随机游走的状态。当相邻的格点被随机行走的粒子占据后,相邻粒子形成一个联合体,然后该联合体作为一个单体再随机运动,这样不断地继续下去,直到形成一个联合体。如图3所示。
网络中Agent数为3000,粒子形成终态凝聚体只需1200多步少于DLA模型的3000步。这是一种与现实比较接近的多人搜寻知识过程,这个凝聚体比DLA模型的凝聚体要开放和松散些。
(三)择优连接仿真模型
新发表的文章更倾向于引用已被广泛引用的重要文献,新的网页上的超文本链接更可能指向新浪、雅虎等著名的站点。在找寻知识的过程中,最省力的方式就是关注热点,这些热点通过吸引了很多人的注意力后再去获得更多的关注。这种现象被称为“富者更富(richgetricher)”或“马太效应(Matrheweffect)”,从信息接收者的角度来看这也是较省力的过滤信息的方式。为解释这一现象,Barabási和Albert提出了BA模型,BA模型的两个重要特性[7]:
(1)增长(growth):指网络的规模是不断扩大的,主要是指节点数量不断扩大。例如,每个月都会有大量的新的科研文章发表,而WWW上则每天都有大量新的网页产生。
(2)择优连接(preferentialattachment):指新增节点更倾向于与那些具有较高连接度的“大”节点相连。通过这两个建边规则构建了一个BA网络,网络中的节点数为2397个,与DLCA模型相似择优连接也是基于多个个体的选择进行结网的过程,不过个体的判断是基于他人的行为来连入网络,DLCA模型则基于自己的积累,如果与自己相连的人找到了粒子自己也就算找到了。如图4所示。
(四)三个网络与集体注意力经济相关的网络统计数据
在BA、DLA及DLCA模型中,讨论了个体搜寻信息的方式,以及单个个体和多个个体行动形成的网络,经过一段时间后,对这些行为形成的网络进行整体性能的分析,用以发现这些网络是否能达成集体注意力经济。具体如表4所示。
表4中,在网络中如果我们采用随机游走的方式去找寻知识,那么搜索效率与网络的平均路径长度正相关的[8],从这一结论可以看出BA模型具有优势,因为该模型的平均路径长度只有7.5,DLA模型其次,DLCA模型最弱。再来看网络的这种搜索特性是如何达成的,BA模型中节点度的差异性最大,节点度之间差了三个数量级,标准差为3.6,而DLA模型节点间的度数差别不大,最大的也只有5,最小的为1,标准差为0.79。与DLA模型相比BA模型牺牲了3个数量级的节点差异性换回了1个数量级的平均路径长度,因此从经济的角度来看DLA模型要有优势。从个体的角度来看,在BA模型中介数中心性最大的和接近中心性最小的点都是度最大的点1。而在DLA和DLCA模型中,介数中心性最大和接近中心性最小的点不是度数最大的,这两个点的度数均为3,在DLA模型中也不是种子节点。从这里我们可以看到在网络DLA和DLCA模型中,个体通过较少的关注达到了好的效果(介数中心性最大和接近中心性最小),这就是我们要实现的个体注意力经济。
三、个体与集体注意力经济达成的仿真实验
通过实证分析,我们知道个体在进行选择的时候会通过熟人推荐的方式,或者是择优连接的方式,我们把这两种目前来看经济的方式加载到模拟现实网络的DLCA模型上,让个体通过这两种方式去搜寻知识,然后再比较经过一段时间的累积后这两种方式在集体注意力经济的表现上是否有差异。实验参数的设定是依据DLA模型中个体尝试的次数,我们在DLA模型上做了100次模拟,计算出初始种子的连边(出度)平均数为4。在DLCA模型上让每个Agent做均值为2的尝试,这样的尝试按熟人推荐的方式和择优的方式去连边,然后再比较整体网络与搜索相关的指标。实验中DLCA_1模型是随机选择前向链接的邻居的前向邻居进行连边;DLCA_2模型是如果没有前向链接的邻居的邻居时,则随机选择一个节点进行连边;DLCA_3模型是如果没有前向链接的邻居的邻居时,则择优连边。如表5所示。
实验后,我们看到仅通过熟人推荐的方式并不能使得网络的直径变小,它与DLCA模型还是在同一个数量级,网络的特性还是与DLCA模型的特性一样。但有了随机连边后,则网络的结构发生了很大的变化,网络的直径只有9.2,其他特性与DLCA相似,网络三种指标中的介数中心性改为另一个点2459,它的度数仅为5。加了择优机制后,网络的集聚系数虽然很大,但网络还是回归到择优模型的那种网络结构,具有中心性的节点也是度数最大的节点,节点与节点度数的差异更大了,网络中心势比前两个网络高3个数量级,但它的网络直径与DLCA_2模型的却是在同一个数量级。
四、结论
人与人之间的关系起到的主要作用就是过滤信息,在丰富信息的世界里这是一种高效率获取信息的方式,因此个体可以把多次注意力作用在同一个对象或相关对象后沉淀、固化为关系,通过这些关系去经济有效地找寻自己需要的信息,是否通过个体经济的方式就能达成集体的经济,在网络优化的过程中仍需要研究。在BA的择优模型中,通过择优度最大的点占据了网络的介数中心性和接近中心性,该点也为此付出了比一般节点高3至4个数量级的连边代价,而在WS的小世界模型中个体的连边数是均匀分布的,但这个网络的网络直径却与BA模型是同一数量级,Watts在文章中给出的解释是熟人推荐与随机连接的方式共存造成了这一经济现象[9,10],但如果个体习惯了熟人推荐方式然后还会有随机连边方式就不太符合人类行为一致性的解释。在本文中,我们通过实证研究得出个体有通过熟人推荐的方式进行过滤信息的行为,在解释模型中的随机连边方式时,我们采用另一维度的解释来描述这一现象,如人们会通过书来找人,通过人来找小组,通过小组来找书,扩充了“熟人”的定义。本文中将人、书及小组看成不同的维度,在某一维度下某一行为是随机的,但在另一维度下却是“熟人”推荐。通过不同维度的熟人推荐方式的仿真实验,看到无论在个体还是在群体上过滤信息都可以达到经济的效果。通过多维度下的熟人推荐实现了个体经济性与集体经济的一致达成,这是以往的网络研究中没有发现的。在实际应用的设计时,可以设计多个关注点比如豆瓣社区中的书籍、音乐等,或者是将用户分成不同的兴趣小组,这样在做熟人推荐方式时可以达到集体经济。从复杂网络研究的角度来看,改变了原来仿真过程通过调整参数的实验范式,而是先从实际出发,依据实际个体中的行为方式来进行实验的设计进而回归到实际系统设计的建议,在论证环节上要更完善、更合理。本文的仿真实验中的规则还可以做的更细致些,比如在随机连边时的概率、方式都可以再精确些,这是以后研究的方向。
参考文献:
[1]SIMONHA.DesigningOrganizationsforanInformation-RichWorld[M].Maryland:JohnsHopkinsUniversityPress,1991.
[2]SimonHA.TheSciencesoftheArtificial[M].3rded.Cambridge,MA:TheMITPress,1996.
[3]LANHAMR.TheEconomicsofAttention:StyleandSubstanceintheAgeofInformation[M].Chicago:UniversityofChicagoPress,2006.
[4]唐四慧,杨建梅.两种交互式信息传播网络的传播模型比较研究[J].科学学研究,2008,26(3):476-479.
[5]唐四慧.异质复杂信息网络上的搜索路径研究[J].华南理工大学学报(社科版),2011,13(4):8-13.
[6]费孝通.乡土中国[M].北京:人民出版社,2008.
[7]张济忠.分形[M].北京:清华大学出版社,1995.
[8]BARABSIAL,ALBERTR.Emergenceofscalinginrandomnetworks[J].Science.1999,286:509-512.
[9]REAGANSR,MCEVILYB.Networkstructureandknowledgetransfer:theeffectsofcohesionandrange[J].Administrativesciencequarterly,2003,48:240-267.
[10]DODDSPS.ROBYM,WATTSDJ.Anexperimentalstudyofsearchinglobalsocialnetworks[J].Science,2003,301:827-829.
[11]WATTSDJ,DODDSPS,NEWMANMEJ.Identityandsearchinsocialnetworks[J].Science,2002,296:1302-1305.
[12]NEWMANMEJ.Thestructureandfunctionofcomplexnetworks[J].SIAMReview,2003,42(2):167-256.
[13]罗家德.社会网分析讲义[M].2版.北京:社会科学文献出版社,2010.
Abstract:Thispapershowsthat,basedontheretrospectoftheactualmakeedgebehaviorofDoubanusers,aheterogeneoustreenetworkofindividualsacquiringknowledgeisconstructed,andthenthreeindividualeconomicnetworkmodels(DLA,DLCA,BA)aremade.TheresultsindicatethattheBAmodelsacrificesfairnesstogetasmallaverageshortestpath.ThreecomparisonexperimentsbasedonDLCAwereconducted,andtheresultsprovethatthenetworkofdifferentacquaintancesrecommendedcanreachboththeindividualeconomyandcollectiveeconomy.Underconditionsoflimitedindividualattention,theheterogeneoustreenetworkisefficienttoobtainknowledge.
KeyWords:individualattentioneconomic;collectiveattentioneconomy;networkoptimization;heterogeneoustreenetwork
(责任编辑:潘江曼邓泽辉)
