一种基于分层特征学习的标签一致K-SVD图像分类方法
2016-08-10郭继昌
王 博, 郭继昌, 张 艳
(天津大学 电子信息工程学院,天津 300072)
一种基于分层特征学习的标签一致K-SVD图像分类方法
王 博, 郭继昌*, 张 艳
(天津大学 电子信息工程学院,天津 300072)
为更好提取信息丰富的图像表示,提出了一种基于分层特征学习的标签一致K-SVD图像分类方法。首先,对基于灰度或RGB类型的图像进行稠密的块采样,然后利用分层正交匹配追踪获取图像特征,代替传统的基于SIFT描述子结合空间金字塔池化的方式。在引入标签一致性约束后,利用K-SVD算法对已获取特征进行判别式字典的学习,同时得到了最优的线性分类器。实验结果表明,该方法在Caltech101、Oxford Flowers 和UIUC-Sports 3类数据集中,分类准确率分别达到了76.7%、84.9%和87.1%,优于其他算法。
图像表示; 分层特征学习; K-SVD; 图像分类
MR subject classification: 68U10
近年来,对于图像分类任务,新的监督字典学习方法更加有效[1-2]。这类算法在训练字典时,将判别标准或分类误差直接引入需要优化的目标函数中[3]。其中,利用K-SVD进行优化,同时包含标签一致约束和最优分类性能标准的算法备受关注。但是,这种标签一致K-SVD方法[4]仍使用基于尺度不变特征变换(SIFT)的空间金字塔特征进行稀疏编码。
随着深度学习的快速发展,一种建立在原始像素级基础上的完全自动的分层特征学习结构,在图像表示上体现出更优的性能[5-7]。文献[8]使用带有非负约束和选择性的分层反卷积网络(deconvolutional network, DN)结构进行特征学习,但训练层数较多,计算复杂度高。文献[9]证明了一种基于分层正交匹配追踪(hierarchical orthogonal matching pursuit,OMP)的图像表示学习算法,在分类性能上大幅超越了基于空间金字塔匹配(spatial pyramid matching,SPM)和DN的方法,但需对灰度和RGB类型的图像均进行稠密的块采样,以保证提取的图像表示包含丰富的信息,时间开销较大。
针对以上问题,本文提出了仅利用灰度或RGB类型的图像进行稠密的块采样,结合K-SVD和OMP对块级特征分层训练,利用标签一致K-SVD方法对提取的图像特征学习判别式字典和最优线性分类器;并对Caltech101、 Oxford Flowers 和UIUC-Sports基准数据集进行验证,分类准确率分别达到76.7%、85.2%和87.1%,优于其他先进算法。
1 基于分层特征学习的图像分类模型
图像分类作为图像、视频检索以及机器人视觉的基本任务之一,根据不同属性,将图像划分到预设的类别中。相对非监督字典学习方法,监督字典学习不仅考虑图像重构问题,而且利用了训练集中图像的类别信息。标签一致K-SVD是一种典型的将图像标签作为监督信息的方法,把重构和分类误差引入目标函数,通过K-SVD算法进行优化,同时学习到一个判别式字典和一个多类线性分类器。由于来自同类的图像生成了近似的稀疏表示,因此该方法具有良好的分类性能。
但是,在标签一致K-SVD方法中,采用对基于SIFT描述子和SPM算法提取的特征进行稀疏编码,一定程度上限制了该模型的性能。在此基础上,本文提出一种基于分层特征学习的图像分类模型,如图1所示。
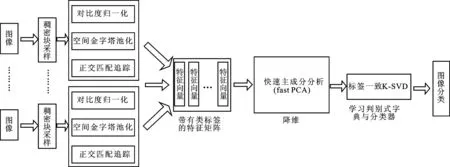
图1 基于分层特征学习的图像分类模型
其中,相对于基追踪(basis pursuit,BP)或欠定系统局灶解法(focal underdetermined system solver,FOCUSS),利用OMP得到的稀疏表示更为高效[10]。空间金字塔池化与稀疏表示结合后的优良性能已在文献[11]中得到了理论和实践的分析与证明。对比度归一化可以得到更低冗余的表示,令对比度差异较大的块特征更易被区分,差异较小的更易被归为同一类。通过分层地学习来自像素级的图像特征,最终可以获得一个完整的带有类标签的特征矩阵。因其中的特征向量都具有较高维度,所以采用快速主成分分析的方法进行降维,并对降维后的特征矩阵学习判别式字典与线性分类器,然后进行图像分类。
2 分层特征提取结构
在上述图像分类模型中,依照贪婪地逐层非监督训练原则进行分层特征提取。文献[12]描述了一种典型的两层深度网络结构,在这种深度学习算法中,每个对应于独立原子的大小为(n-m+1)×(n-m+1)的二维网格都被称为特征图。本文采用的分层特征提取深度结构如图2所示,假定图像是由n×n像素点组成,其中单层特征图均被栈式堆叠。
图2展示了三维的深度结构,包含OMP算法作为编码器,并利用空间金字塔最大池化策略的深度网络主要包含以下4步:
(1)第一层特征提取时,采用m×m尺寸的感受野,因使用稠密的采样方案,其间隔设定为1。通过K-SVD训练可以得到含有D1个原子的字典。接着,利用高效的OMP获得了形如(n-m+1)×(n-m+1)×D1的栈式特征图。
(2)对邻近的s×s空间块,采用取最大值的池化策略,然后生成形如[(n-m+1)/s]×[(n-m+1)/s]×D1的池化表示。
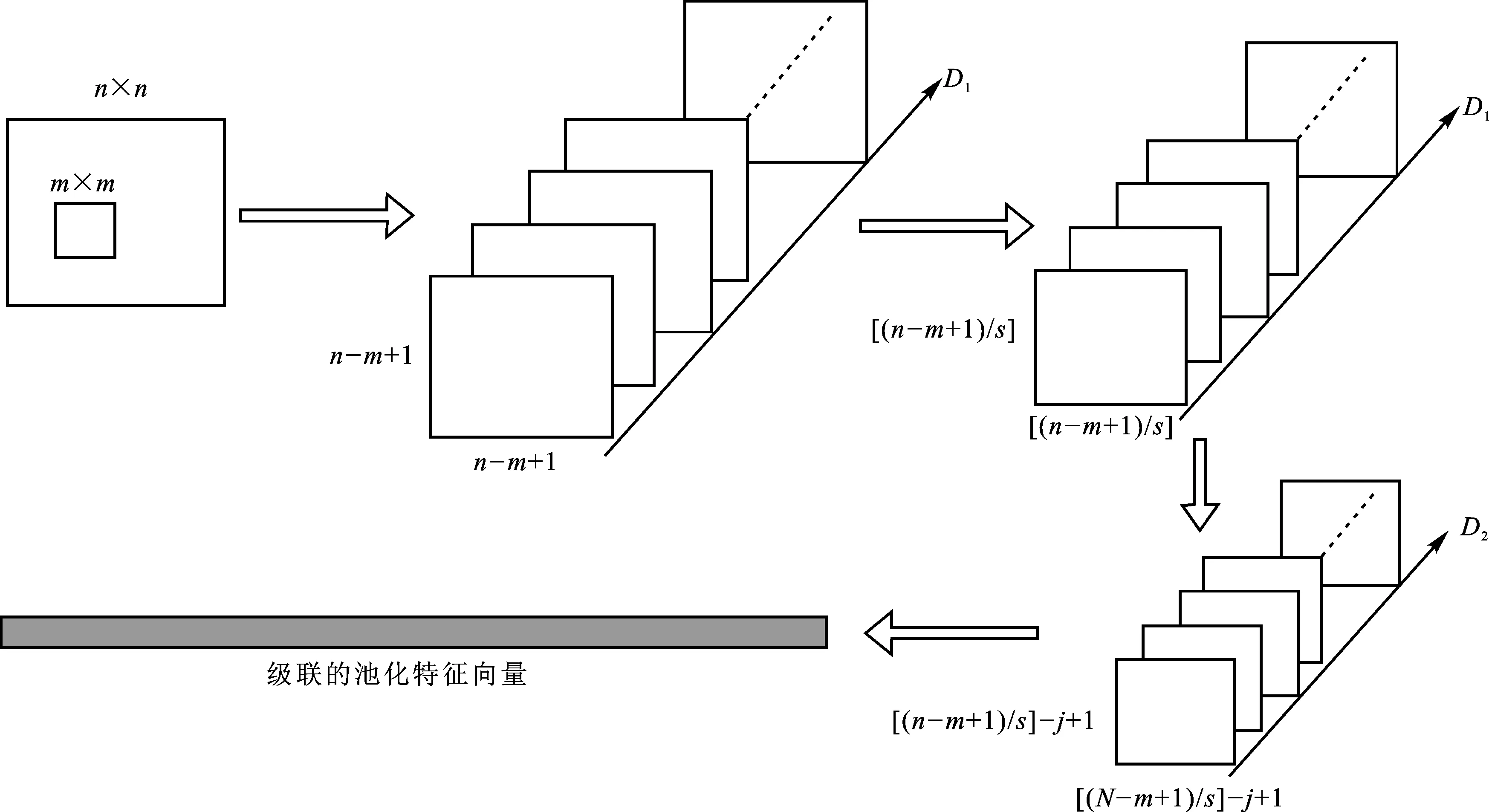
图2分层特征提取结构
Fig.2The architecture of hierarchical feature extraction
(3)在全部D1个特征图上,继续使用稠密块采样方法,利用尺寸大小为j×j的感受野,其间隔仍设定为1,经过多层的块级采样,生成的第二层特征维度变为j×j×D1,特征数量变为
{[n-m+1)/s]-j+1}×{[n-m+1)/s]×
D1-j+1}。
结合K-SVD方法进行训练,可以得到含有D2个原子的字典,D2>D1,然后通过OMP算法得到了第二层的特征图表示,形如
{[(n-m+1)/s]-j+1}×{[(n-m+1)/s]×
D1-j+1}×D2。
(4)利用空间金字塔最大池化方法得到最终的级联图像特征。
其中,用于稀疏编码的K-SVD算法可具体描述如下:令X为b维输入信号集,即X=[x1,x2,…,xN]∈Rb×N。学习带有P个原子的用于稀疏表示的可重构字典,通过解决下面的优化问题实现:

(1)
其中D=[d1,d2,…,dP]∈Rb×P是学习的字典,C=[c1,c2,…,cN]∈RP×N为输入信号的稀疏表示,M是相应的稀疏度,亦即稀疏系数中非零元素的个数。给定D后,可以利用高效的OMP算法计算稀疏近似解,其需解决以下优化问题:

(2)
然而,根据统一的字典D对大规模信号集进行稀疏编码时,必须考虑预计算的问题以节省计算开销。在式(2)优化问题中,原子选择的步骤最为耗时,因此实践中通常采用批处理OMP(BOMP)的方式。BOMP只要考虑DTr,而无需明确计算残差r或稀疏表示c。设γ=DTr,γ0=DTx,G=DTD,可得

(3)
其中,GII表示行与列都由I索引的矩阵。那么,仅预计算γ0和G即可,用于升级步骤的计算开销大幅减低。关于BOMP算法的流程如下:
批处理OMP算法
输入:D、x、M
输出:c
初始化:x=0,I=∅,γ0=DTx,G=DTD
循环至终止条件(t=1∶M)
I=I∪θ
升级γ:γ=γ0-GIcI
3 判别式字典学习
为取得平衡的重构和判别性,并最终同时学习到多类线性分类器,标签一致K-SVD方法需在字典的原子和类标签之间保持明确的一致性。这种利用监督信息的字典学习方法,是将判别式稀疏编码误差和分类误差作为正则项引入到目标函数中。所以(1)式变为如下形式:
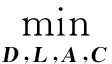
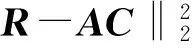

K-SVD是一种高度灵活的且可与任何追踪方法进行结合的算法[10]。K-SVD基于迭代的方式可以高效地获得相应目标函数的最优解。为此,(3)式可重新表示为
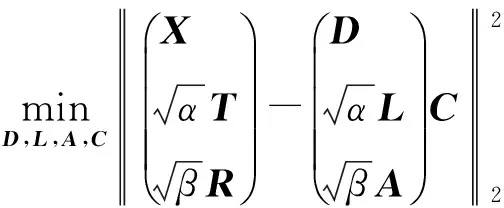
s.t.∀i,‖ci‖0≤M。
(5)
实际上,目标函数(4)等价于以下形式:

(6)



(7)


(8)

标签一致KSVD算法
输入:X、T、R、M、K、、α、β
输出:D、L、A

利用K-SVD搜寻(5)式的最优解,升级D′
从D′中获取D、L、A。
4 实验结果与分析
本节中,采用CPU主频为3.1 GHz,Windows 7 64位操作系统及Matlab 2010b平台进行实验。利用本文提出的基于分层特征学习的标签一致K-SVD算法,3组实验分别对Caltech101、Oxford Flowers 和UIUC-Sports 3个常用基准测试集进行图像分类的测试。
本文训练一种具有双层结构的深度网络用于特征学习,对Caltech101和UIUC-Sports测试集只进行灰度图像的稠密块采样,而对Oxford Flowers测试集只进行RGB图像的稠密块采样。第一层学习中,字典原子个数被设定为100,采样块尺寸设为6×6,OMP-5用于编码,即稀疏系数中至多有5个非零元素。然后利用尺寸为4×4的感受野对特征取最大值池化,得到用于第二层编码的特征矩阵。第二层学习中,训练一个原子个数为1 000的字典,采样块尺寸设为5×5,采用稀疏度为10的OMP进行编码。其中金字塔空间池化的三级子区域分别设置为1×1,2×2,3×3。所有用于测试的图像最大尺寸均被设定为300。
4.1Caltech101分类数据集
Caltech101是一个极具挑战性的目标分类数据集,包括102类,共9 144张图像。除了背景类以外,还有飞机、车辆、动物等类别。为了保证公平的测试条件,依据常规实验设定,本文将随机抽取30幅图像用于训练集,其余图像用于测试集。实验结果是取10次的平均分类准确率。本文算法与其他先进算法对比的结果如表1所示。

表1 Caltech101数据集分类准确率
首先,可以发现本文算法在分类准确率上大幅优于基于SIFT描述子进行特征提取的单层稀疏编码方法,如ScSPM[13]和LLC[14]。其次,相对几种分层特征学习方法,如DNNS[8]、HSC[5]、HSSL[7],本文算法的分类性能最大提高了3.4%。最后,本文方法超越了利用SIFT描述子结合空间金字塔池化方式提取特征的LC-KSVD2算法[4],最大提高了3.1%。此外,在降维实验中,分别选择3 000和6 000两种不同维度,实验结果表明,特征维度较低会严重影响分类准确率。而当实验中选择更高维度时,运算效率会严重下降。
4.2Oxford Flowers分类数据集
Oxford Flowers包括17类,共计1 360张图像。虽然属于小规模的数据集,但这个关于鲜花的基准库中,花朵表现出的类内差异甚至会大于类间差异,且存在不同类型花朵间极其相似的情况,因此该数据集也具有一定挑战性。根据常规实验设定,为确保公正性,随机抽取60幅用于训练的图像,其余用于测试。在进行10次实验后取平均分类准确率作为最终结果。通过表2可以看出,本文算法的分类准确率高出另一种基于显著性的分层学习方法(HSSL)[7]8.7%。同时,相对一种先进的基于共生异构性特征(Color-CoHOG,CoHD)的方法[15],本文算法亦在分类准确率上超越6%。
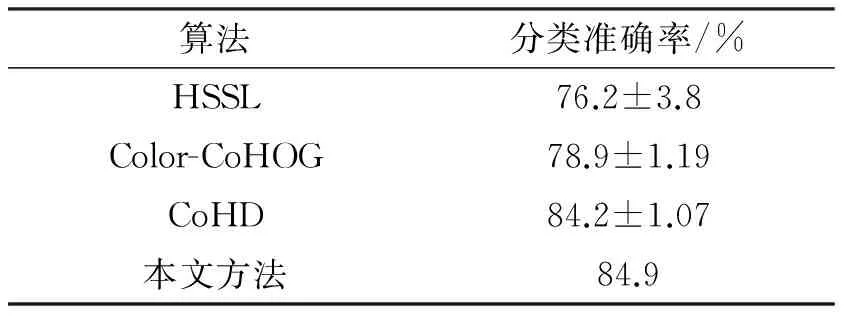
表2 Oxford Flowers数据集分类准确率
4.3UIUC-Sports分类数据集
在完成了针对目标数据集的测试后,本文对一个静态事件类数据集UIUC-Sports进行实验。该数据集包括8类,共计1 579张图像。因为该数据集中的图像均带有复杂的背景,且每类图像的尺寸及内容差异较大,所以也具有较高的挑战性。 为了保证公平的测试条件,依然根据常规实验设定,即从每类中随机抽取70张作为训练图像,60张用于测试。表3给出了分类准确率对照结果。本文算法的分类准确率高于目标库(OB)方法[16]10.8%,同时优于自适应高斯模型(AGM)[17]和拉普拉斯稀疏编码(LSC)[18]。此外,相比分层匹配追踪的算法(HMP)[9],本文方法在小规模UIUC-Sports事件类数据集上表现出1.4%的优势。

表3 UIUC-Sports数据集分类准确率
5 结论
本文提出了一种基于分层特征学习的标签一致K-SVD图像分类方法,它能够利用灰度或RGB类型图像,稠密地一次性进行块采样,避免了时间开销较大的缺点。同时,基于分层特征学习的方法取代了传统的基于SIFT描述子结合空间金字塔池化的方式,获得了更优的图像表示。因此,在仅使用由标签一致K-SVD学习的线性分类器情况下,依然取得了较高的图像分类准确率。实验结果表明,本文算法性能优于分层图像表示学习、基于SIFT的稀疏表示以及其他基于先进算法的模型。
[1] MAIRAL J,BACH F, PONCE J.Task-driven dictionary learning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 791-804.
[2] YANG M, ZHANG L, FENG X C, et al.Fisher discrimination dictionary learning for sparse representation[C]//Proceedings of IEEE International Conference on Computer Vision. Barcelona:IEEE, 2011:543-550.
[3] ZHANG Q, LI B X. Discriminative K-SVD for dictionary learning in face recognition[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. San Francisco:IEEE,2010: 2691-2698.
[4] JIANG Z L, LIN Z, DAVIS L S. Label consistent K-SVD: learning a discriminative dictionary for recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(11):2651-2664.
[5] YU K, LIN Y Q, LAFFERTY J.Learning image representations from the pixel level via hierarchical sparse coding[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Providence:IEEE, 2011: 1713-1720.
[6] BO L F, REN X F, FOX D. Multipath sparse coding using hierarchical matching pursuit[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Portland:IEEE, 2013: 660-667.
[7] YANG J M, YANG M H. Learning hierarchical image representation with sparsity,saliency and locality[C]//Proceedings of the British Machine Vision Conference. Dundee, 2011: 19.1-19.11.
[8] LIU B Y,LIU J, BAI X, et al. Regularized hierarchical feature learning with non-negative sparsity and selectivity for image classification [C]//Proceedings of the 22nd International Conference on Pattern Recognition.Stockholm, 2014: 4293-4298.
[9] BO L F, REN X F, FOX D.Hierarchical matching pursuit for image classification: architecture and fast algorithms[C]//Advances in Neural Information Processing Systems 24. Granada, 2011: 1-9.
[10] AHARON M, ELAD M, BRUCKSTEIN A.K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation[J]. IEEE Transactions on Signal Processing, 2006, 54 (11): 4311-4322.
[11] BOUREAN Y L,BACH F,LECUN Y, et al. Learning mid-level features for recognition [C]// Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. San Francisco:IEEE, 2010: 2559-2566.
[12] COATES A, NG A Y.Selecting receptive fields in deep networks[C]//Advances in Neural Information Processing Systems 24. Granada, 2011: 1-9.
[13] YANG J C, YU K, GONG Y H, et al. Linear spatial pyramid matching using sparse coding for image classification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Miami, 2009: 1794-1801.
[14] WANG J J, YANG J C, YU K, et al. Locality-constrained linear coding for image classification [C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. San Francisco:IEEE, 2010: 3360-3367.
[15] SATOSHI I, SUSUMU K.Object classification using heterogeneous co-occurrence features [C]//Proceedings of the 11th European Conference on Computer Vision. Heraklion,2010: 209-222.
[16] LI L J, SU H, XING E P, et al. Object Bank: A high-level image representation for scene classification and semantic feature sparsification[C]//Advances in Neural Information Processing Systems 23.Vancouver,2010: 1-9.
[17] DIXIT M, RASIWASIA N, VASCONCELOS N.Adapted gaussian models for image classification [C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Providence:IEEE, 2011: 937-943.
[18] GAO S H, TSANG I W, CHIA L T, et al. Local features are not lonely-laplacian sparse coding for image classification[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. San Francisco:IEEE, 2010: 3555-3561.
〔责任编辑宋轶文〕
An image categorization approach based on hierarchical feature learning and label consistent K-SVD
WANG Bo, GUO Jichang*, ZHANG Yan
(School of Electronic Information Engineering, Tianjin University, Tianjin 300072, China)
In order to extract image representation including useful information, a method is proposed based on hierarchical feature learning and label consistent K-SVD. Firstly, a great number of patches are densely sampled only from grey or RGB type of images. Secondly, image features are generated using hierarchical orthogonal matching pursuit instead of traditional pattern based on scale invariant feature transform (SIFT) descriptor combined with spatial pyramid pooling. With a label consistency constraint, a discriminative dictionary is learned by K-SVD algorithm employing the acquired features, as well as an optimal linear classifier. The experiments on Caltech101, Oxford Flowers and UIUC-Sports benchmark datasets show that the proposed method can achieve 76.7%, 84.9% and 87.1% respectively in terms of classification accuracy, which performs better than other algorithms.
image representation; hierarchical feature learning; K-SVD; image categorization
1672-4291(2016)04-0017-06
10.15983/j.cnki.jsnu.2016.04.145
2015-08-18
高等学校博士学科点专项科研基金(20120032110034); 天津市自然科学基金(15JCYBJC15500)
郭继昌,男,教授,博士。E-mail: jcguo@tju.edu.cn.
TP391.4
A
