密度峰值算法在中文自动文摘中的应用研究
2016-07-21李明丽孙连英石晓达
李明丽,孙连英,邢 邗,石晓达
(北京联合大学信息学院,北京 100101)
密度峰值算法在中文自动文摘中的应用研究
李明丽,孙连英,邢 邗,石晓达
(北京联合大学信息学院,北京 100101)
[摘 要]随着自然语言处理技术的不断创新,自动文摘的质量得到显著提高。面向科技成果文档的中文自动文摘成为研究热点,具有一定的应用价值。把聚类算法应用到自动文摘中,选取聚类中心的思想对文摘去冗余具有一定意义。结合密度峰值算法,设计实现了面向科技成果文档的中文自动文摘系统。实验结果表明:应用密度峰值算法有利于文摘的冗余处理,具有借鉴意义。
[关键词]自动文摘;密度峰值;冗余处理
互联网信息的指数级增长,使得自动文摘的实用价值不断提高。随着文本处理算法的创新,自动文摘的质量不断提高,自动提取文摘有利于科技成果的转化推广。自动文摘从文摘产生的形式上看,可分为抽取式文摘和生成式文摘。抽取式文摘通过对文档原句打分,抽取文档原句组成文摘。生成式文摘通过重组句子或填充文摘模板来生成文摘[1]。生成式文摘的相关技术仍不够成熟,较难应用。从文本数量上看,可分为单文本文摘和多文本文摘。抽取式文摘从句子的权值计算方法上来看,可分为句子独立打分式和通过句子之间关系打分式两种方法。应用于自动文摘的方法有图模型、语义分析、机器学习和聚类等。本文主要研究的是聚类算法在自动文摘系统中的应用。
应用到自动文摘中的聚类算法主要有层次聚类、K均值聚类和密度聚类算法等。层次聚类[2]算法在自动文摘中的应用比较简单,不需要给定文档的聚类数目,但是一个对象被聚类后不可再做调整,可能造成较大的聚类偏差。K均值聚类的经典算法为K-means算法,步骤如下:1)任意选择K个句子作为初始聚类中心;2)分别计算剩余句子与每个聚类的中心距离,根据最小距离重新对句子进行划分;3)重新计算每个新类的聚类中心,即每类中全部对象的均值;4)每当满足一定条件,如均方差函数开始收敛时,则算法终止;否则返回步骤2。初始聚类中心的个数需要提前给定,聚类中心可采用虚拟点。它的局限在于受限于K值,难以发现自然聚类,聚类中心的个数受限,并且对噪声较敏感。K-medoids算法与K-means算法的主要区别在于聚类中心的选择方法,K-medoids算法的时间复杂度较低。K-mesns算法作为聚类的经典算法,经过长期的应用发展,在初始聚类中心的选择上,有很多研究人员进行了不同的探索。应用到自动文摘中的密度聚类算法主要是DBSCAN[3]算法,密度大的点向外扩展聚类。
将聚类算法应用到自动文摘系统的实例有: 2001年,文献[4]将聚类思想应用到自动文摘提取中,结合层次聚类算法与K-means算法,将文本聚类成若干段落类,选取与文献主题相关的类,进而提取文摘;2006年,刘海涛等采用K-medoids算法,根据词频统和位置信息形成关键词向量,将文本进行段落聚类提取文摘[5];2007年,郭庆琳等将层次聚类和K-means分别应用到自动文摘[6]中,实现了面向塑料行业的中文自动文摘系统;2009年,分别采用层次聚类算法和DBSCAN算法,将句子进行聚类提取文摘[7];2015年,基于改进K-means[8]的动态文摘,在初始聚类中心的选取上进行改进,以句子为单位,实现了根据时间更新的动态文摘提取。
科技成果类文档,主题明确、文章结构比较规范,把句子间的余弦相似度看做句子之间的距离衡量标准,采用密度峰值算法选取句子的聚类中心,可以更好地提取文摘句。
1 密度峰值算法
2014年6月,在Science上发表的密度峰值算法[9],兼顾密度聚类两要素:密度和距离,采用二维平面提取聚类中心。该算法选取方法独到、思维新颖、结果直观。密度峰值算法在聚类中心的选取上,充分考虑了聚类中心之间的距离,对文摘去冗余有直接效用。
在密度聚类算法中,有两个主要标准:局部密度ρi和距离δi。ρi是与i的距离小于dc的点的个数,称ρi为局部密度,ρi的公式为
dc是截断距离(cutoff distance),dc值可结合实际需要进行确定,其中χ的函数公式为
根据密度降序排序,依次计算候选密度中心的距离。δi是点i与其他密度大于i的点之间的最小距离,其公式为
密度最大的点与其他参考点的δi计算公式为
密度峰值算法的核心思想是同时考虑ρi和δi,在二维空间中提取聚类中心点,即把ρi看作横轴,δi看作竖轴,提取数轴右上角区域内的点,就是密度较大且与其他参考点之间的距离较大的点,可提取为文章的聚类中心点。
2 系统实现
系统将句子作为抽取的最小单位,把句子看作是词的线性组合,生成单文本的抽取式文摘,设计并实现了面向科技成果类文档的中文自动文摘系统。传统的自动文摘系统S1的处理流程为:预处理、句子余弦相似度计算、句权值计算、去冗余、文摘生成。结合应用密度峰值算法的系统S2的文摘生成框架图如图1所示。
系统S1与系统S2的主要区别在于,S1采用去冗余方法,S2采用密度峰值聚类,尝试达到共同的效果。S1的句权值为S2句权值减去聚类中心加权的差值。
系统S2主要把词频分布特征、词性、句子长度和句子类型作为句子筛选的标准。句子按权值排序,按文档压缩率抽取文摘句。
2.1文档预处理
文档预处理主要包括分词、去停用词和词频统计。分词之前先进行分句和选句,去除不宜选入文摘的句子。采用ansj_seg分词和词性标注,去停用词后,统计词频TF。选取名词、动词、副词和形容词作为计算词集。
2.2句子聚类
把文档的所有句子当做无向有权图处理,采用余弦相似度算法计算句子之间的关系,采用密度峰值对句子进行聚类,提取聚类中心。
2.2.1余弦相似度
把文档中的每个句子都看作由词组成的向量,假设句子向量A=(tfi1,tfi2,…,tfin),向量 B= (tfj1,tfj2,…,tfjn),则两句子的余弦相似度 S (Similarity)的公式为
把一篇文档中的所有句子看做是无向有权图的节点,S值看做边的权值。设一篇文章有n个句子,无向图的边为n(n-1)/2条,计算S并将S值降序排序。
2.2.2句子聚类
聚类中的距离d=1-S。dc是使得相邻点的平均数占总数据点数的1.6%。
聚类中心点的选取:取右上角的点,横纵坐标从右上角为起点限定范围,根据范围里点的个数来确定是否继续扩大范围。系统提取4到8个聚类中心,如遇到重叠严重,随机在重叠点中抽取所需,并将提取出的聚类中心加权。
2.3句权值的计算和文摘生成
句权值=词频平均值+余弦相似度平均值+句子位置+C(聚类中心加权)。将句权值降序排序,根据文档压缩率提取文摘。
3 实验对比分析
结合密度峰值算法的系统S2与系统S1进行实验对比,采用3种评测方法,分别以文本压缩率为10%和20%进行文摘测评。
3.1评测库的创建
为了实验评测,建立一个科技成果语料库,文章来自国家科技成果网。语料库根据文档长度划分成两个文档数据集,各100篇,共200篇科技成果文档。文档内容包括题目、关键字和正文等。4名研究人员协同提取文摘和人工标注,完成2个评测数据集SAT2015-L和SAT2015-S的建立。分别按10%和20%的压缩率提取文摘,数据集的统计信息如表1所示。
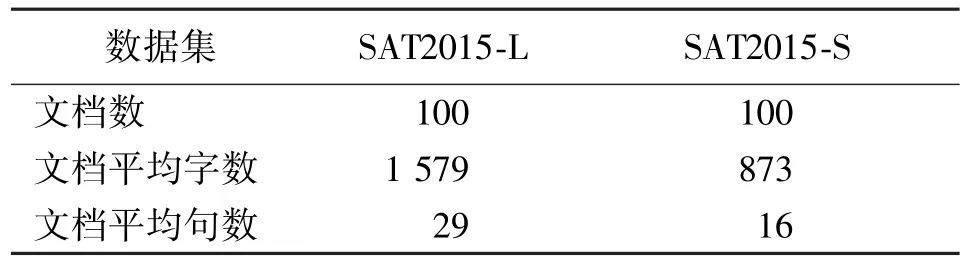
表1 数据集的统计信息Table 1 Statistics of data sets
3.2评测方法
采用内部评测和相似度评测两种方法,对应用密度峰值算法的自动文摘系统进行评测。
1)内部评测
F-Measur(简称F-M)。如果参考文摘为n个句子,机器文摘为k个句子,并且有p个参考文摘中的句子包含在机器文摘中,则F-M的公式为
2)余弦相似度评测
假设参考文摘词的向量为S,机器文摘词的向量为M,把它们组合成一个新文档,向量计算方法参考2.2.1的公式(5)。
3)调整标题评测方法(简称K)
由于采用自建评测数据集,其中人工因素不可控。为了增加评测的客观性,结合评测方法,将文档的标题和关键词建立成评测标注集,简称关键字(Keyword)集。采用余弦相似度算法对机器文摘与关键词集进行相似度计算。关键词集的不足在于词类范围比较局限。
内部评测F-M和相似度评测比较,余弦相似度的算法比较稳定。由于内部评测方法过于武断,当两个句子完全相同时为真,否则为假。相似度评测方法以数据集中的词为基本单位进行比较,所以评测效果较好。余弦相似度评测与K评测都是相似度评测,有较好的实验效果。
采用自建的科技成果语料库,人工筛选文摘,K评测增加了评测结果的可信度。
3.3实验结果及分析
采用密度峰值算法聚类中心提取结果如图2所示。
图中右上角框出的矩形区域内,有4个聚类中心点,进行加权。
考虑到文摘压缩率对文摘测评的影响,分别以10%和20%的压缩率进行文摘提取。原系统S1和系统S2进行对比,实验结果如表2所示。

表2 评测结果对比表Table 2 Comparison of the results
根据不同的评测方法,在文档压缩率为10%和20%的情况下,计算出改进系统较原系统的文摘质量提升值如表3所示。
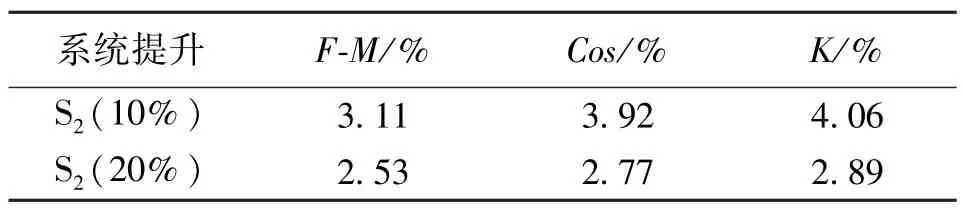
表3 评测提升表Table 3 Improved system upgrade data
在不同文档压缩率的情况下,系统S2较系统S1的提升图如图3所示。
评测实验结果表明:
1)在系统S2中,不同压缩率的情况下,当文档压缩率为10%提取文摘时,加入密度峰值的系统提升效果更明显。此差异与文档和评测语料的大小相关,压缩率继续提升,测评结果不一定提升。
2)在压缩率一定的情况下,采用余弦相似度评测和K评测时,提升效果较明显。这是由于F-M评测方法,当提取文摘句与评测文摘句完全相同时,才认定为文摘句提取成功。相似度评测对比的最小单位是词。
4 结束语
传统方法普遍通过生成候选集后去除冗余的提取文摘方法,候选集的大小对文摘质量有直接影响且不易设定。将密度峰值算法应用到文摘中,可以同时考虑文本聚类中心的密度和文本聚类中心间的距离,即同时选取具有代表性的句子并减少句子间的冗余。结合密度峰值算法,设计面向科技成果文档的自动文摘系统,有较高的研究价值。
[参考文献]
[1] Radev D R,Hovy E,McKeown K.Introduction to the Special Issue on Summarization[J].Computational Linguistics,2002,28(4):399-408.
[2] Corinna Cortes,Vladimir Vapnik.Support-vector networks[J].Machine Learning,1995,20(1):273-297.
[3] Betous-Almeida C,Kanoun K.Construction and stepwise refinement of dependability models[J].Performance Evaluation,2004(56):277-306.
[4] 杨建林.一种使用自动聚类思想的自动文摘方法[J].情报学报,2001,20(5):532-536.
[5] 刘海涛,老松杨,韩智广.自动文摘系统中的段落自适应聚类研究[J].微计算机信息,2006,22(6-3):288-291.
[6] 郭庆琳,吴克河,吴慧芳,等.基于文本聚类的多文档自动文摘研究[J].计算机研究与发展,2007,44(Z2):140-144.
[7] 张磊.基于聚类算法的中文自动文摘方法研究[D].福建:厦门大学,2009.
[8] 郭海蓉,张晖,赵旭剑,等.一种基于改进K-means的动态文摘提取方法[J].软件导刊,2015,14(5):77-79.
[9] Alex Rodriguez,Alessandro Laio.Clustering by fast search and find of density peaks[J].Science,2014(344):1492.
(责任编辑 柴 智)
Application of Density Peak Algorithm in Chinese Automatic Summarization
LI Ming-li,SUN Lian-ying,XING Han,SHI Xiao-da
(College of Information Technology,Beijing Union University,Beijing 100101,China)
Abstract:With the innovation of natural language processing technology,the quality of automatic summarization has beensignificantlyimproved.Chineseautomaticsummarizationforthescientificandtechnological achievements has become a hot research topic,and has a certain application value.Clustering algorithm is applied to the automatic summarization,and the idea of extract clustering center has a certain significance to remove redundancy.With the application of the density peak algorithm to automatic summarization,the automatic summarization system for the scientific and technological achievements has been realized.
Key words:Automatic summarization;Density peak;Redundancy processing
[中图分类号]O 212.4
[文献标志码]A
[文章编号]1005-0310(2016)02-0046-04
DOI:10.16255/j.cnki.ldxbz.2016.02.08
[收稿日期]2015-11-19
[作者简介]李明丽(1989-),女,河北省唐山市人,北京联合大学信息学院硕士研究生,研究方向为知识工程。
[通讯作者]孙连英(1968-),女,吉林梅河口人,北京联合大学信息学院教授,博士,研究方向为数据挖掘与知识发现。E-mail:sunlychina@163.com
