从经典似然到等级似然的理论概述和应用*
2016-06-24王宁宁徐淑一方积乾
王宁宁徐淑一方积乾
利用得分方程S(θ)在θ0处线性近似,有
从经典似然到等级似然的理论概述和应用*
王宁宁1徐淑一2△方积乾3
1.广州医科大学公共卫生学院统计学系(511436)
2.中山大学岭南学院经济学系
3.中山大学公共卫生学院流行病与医学统计系
Fisher(1921)[1]第一次使用了似然(likelihood)这个概念,以后有关似然理论得到了极大发展和广泛应用。由Lee和Nelder(1996)[2]提出的带随机效应的广义线性模型的等级似然(hierarchicacl likelihood)估计方法,在随机效应统计模型估计中得到了较大的发展和应用。如LI.DA.HA等(2002)[3]、LI.DA.HA等(2005)[4]、徐淑一等(2007)[5]、王宁宁等(2011,2014)[6-7]将等级似然估计方法用于生存分析中脆弱模型的估计。而且近年来学术界关于等级似然方法的应用研究仍在继续,如Lee和Jiang等(2011)[8]使用等级似然方法估计预测疾病测绘时相对风险的区间,模拟显示其不弱于贝叶斯方法。Noh和Lee等(2011)[9]使用等级似然建立非线性混合效应模型处理纵向数据。Noh和Lee等(2012)[10]使用等级似然方法提供了一种减弱对数据缺失机制不正确假定的影响并提供了实例和模拟研究。Lee等(2013)[11]把等级似然函数方法用于缺失数据的建模并应用于厚尾分布的纵向数据分析。Wu和Bentler(2012)[12]使用等级似然解决因子分析模型中二元响应变量的情形,使用简单而且高效。徐淑一等(2009)[13]、HA等(2014)[14]和Lee等(2014)[15]将等级似然估计方法应用于竞争风险模型的估计,取得了良好的效果。
相比较于贝叶斯方法,等级似然估计方法在很多情形下相对较为简洁,而且有较为广泛的应用范围,因此,本文对这一理论进行介绍。
经典似然理论到扩展似然
似然的定义是:假定一个统计模型f(y),其中θ是未知参数,L(θ)是观测到的数据y的概率,将它看作是θ的函数,在这个意义下,L(θ)即为似然。似然函数的作用在于承载未知参数的信息,关于使用似然函数的推论一直以来都是有争议的,但是,目前似然理论最广泛的应用仍然是基于似然函数推导的一些统计量和这些统计量的概率特性。Birnbaum(1962)[16]提出:任何一个通过试验得到的结论都应该来自于似然。
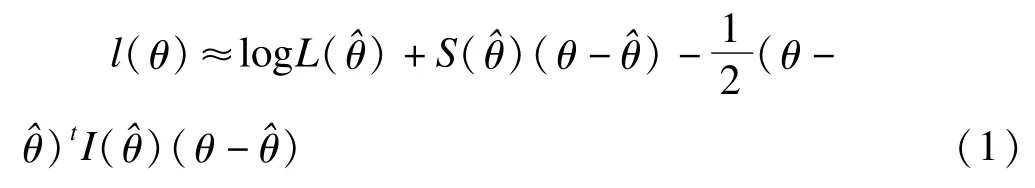
由(1)式可以得到:
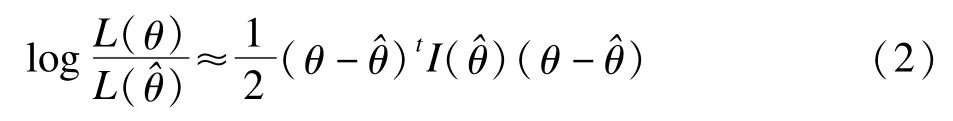
如果数据是来自正态总体,那么二次逼近就是精确的。可以发现,对数似然的二阶近似恰好就对应于^θ的正态近似。由(2)式直接可得:
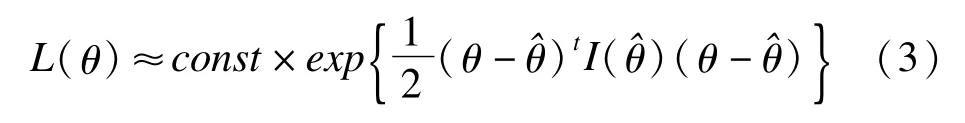
利用得分方程S(θ)在θ0处线性近似,有
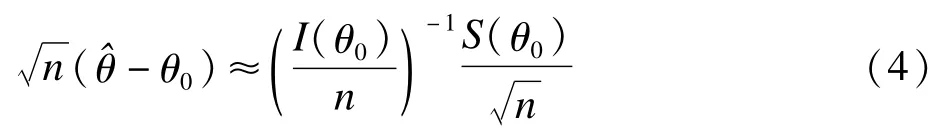
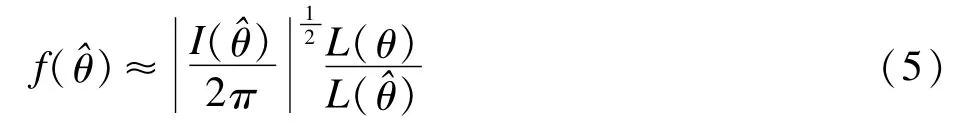
(5)式就是Barndorff-Nielsen的p-formula(1983)[17],已经被证实这个近似比基于的正态近似的密度公式更加精确,而(5)式也正是进一步向轮廓似然和等级似然拓展的基础。
当模型的参数比较多时,我们可能只对一部分参数感兴趣。例如在正态模型里,我们可能只对均值μ感兴趣,此时σ2就是一个讨厌参数(nuisance parameter)。一个方法就是关于感兴趣的参数集中化似然,这就是轮廓似然(profile likelihood)。未知的讨厌参数会带来的额外的不确定性,尤其是在小样本下,考虑这个额外的信息是非常重要的。假定(θ,η)是所有的参数,其中θ是感兴趣的参数,给定联合似然函数L (θ,η),则θ的轮廓似然函数定义为:

其中上面的最大化是固定θ进行的。固定θ以后,得到的η的估计是一个与θ有关的函数,记做L但轮廓似然并不是一个正确的似然函数,它并不是基于观测数据的概率。对于大部分问题,精确的边际似然和条件似然虽然理论上存在,实际却很难得到。设是(θ,η)的极大似然估计令是固定θ时η的极大似然估计,是相应的观测Fisher信息,那么的逼近密度为
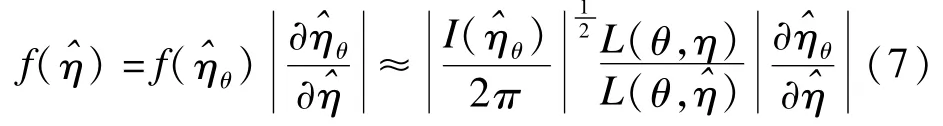
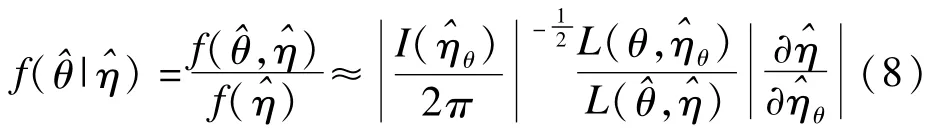
于是,关于θ的条件似然为:
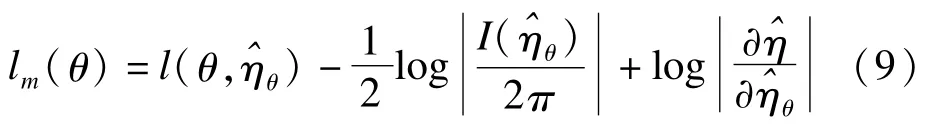
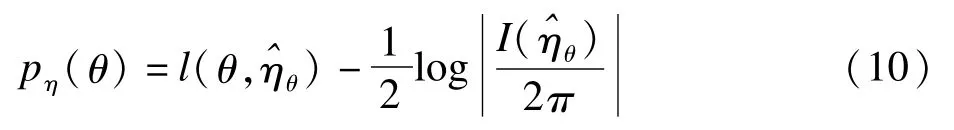
等级似然理论
对于更一般的包括不可观测的随机效应的模型,Fisher似然需要拓展。一直以来,包括不可观测的随机变量的模型的似然的定义,统计学家们没有达成一致。BjØrnstad(1996)[18]建立了扩展似然(extended likelihood)理论,表明一般似然的一个特殊定义包含了固定的和随机的参数的所有信息。Lee和Nelder (1996)[2]介绍了等级GLM模型的等级似然与传统的似然有很大不同。关于似然一个重要的特性是对变换的不变性,这也是区分扩展的似然与等级似然的重要方面,盲目的最优化扩展似然可能会使估计缺乏不变性,参数的不同的尺度(形式)会导致不同的估计,依赖于参数的尺度使得扩展似然面临一些批评,而这个问题,等级似然则通过定义一个特殊的参数的尺度而解决。
关于对似然的拓展,很多学者都做了尝试,如Lauritzen(1974)[19]、Butler(1986)[20]以及BjØrnstad (1996)[18]等。对似然合理的拓展应该能够处理未知参数θ,不可观测的随机效应v和观测数据y,就数据生成过程来说,随机效应v来自于概率函数fθ(v),当v生成之后,固定v,由概率分布函数fθ(y|v)产生随机数据y。那么联合的随机模型就是:

给定数据y,可以利用边际似然L(θ;y)对θ进行推理;给定θ之后,再利用条件似然L(θ,v;v|y)=fθ(v |y)对随机效应v进行推理。关于(θ,v)的扩展似然定义为:
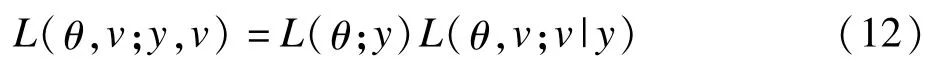
两个过程的联系通过L(θ,v;y,v)=fθ(y,v)给出。扩展似然的定义式中,左边是y固定,(θ,v)变动,右边是θ固定,(y,v)变动。在扩展似然框架下,v作为随机实现出现在数据生成过程中,在参数估计中又作为未知参数待估计。而在经典似然框架下,仅有一类随机数据y。在两类的参数(固定参数和随机参数)都未知的情况下,扩展似然理论没有告诉我们应该如何推理每一部分的参数。
记扩展的似然为le(θ,v)=logL(θ,v;y,v),经典似然记做l(θ)=logL(θ;y)。由扩展似然的定义显然有:le(θ,v)=l(θ)+ logfθ(v|y),对于固定参数采用l(θ)是经典似然方法,对随机效应参数采用logfθ(v|y)是经验贝叶斯方法。由数据生成的过程边际似然可以经由积分得到,于是:
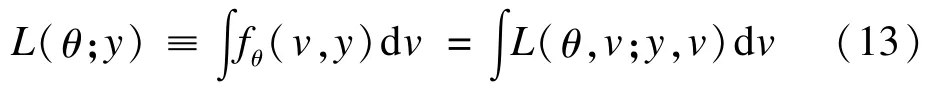
然而对于非正态模型,这种积分很难处理。一种获得固定参数θ的边际极大似然估计的方法是EM算法。EM算法的E步需要E(le)在给定y条件下的解析式,在M步将其最大化。众所周知EM算法收敛得很慢,对于非正态模型,E步的期望很难计算,为此一些模拟算法,比如蒙特卡罗EM方法(Vaida和Meng 2004)[21]和Gibbs抽样(Gelfand和Smith 1990)[22]等都可以用来计算条件期望,但是这些方法的计算都很复杂。另外的经由Gauss-Hermite求积(Crouch和Spiegelman 1990)[23]的数值积分方法可以直接获得ML估计,但是当随机效应参数增加时,计算会相当繁重。
在扩展似然框架下,对固定参数的正确推理要使用由le(θ,v)积分掉随机效应参数获得的边际似然l (θ),由于积分难以处理,边际似然可以采用拉普拉斯近似:
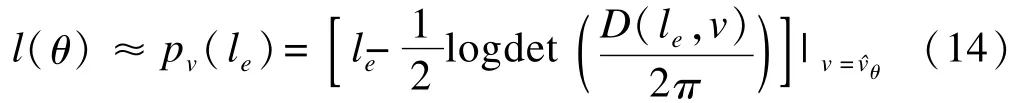
在估计随机效应参数往往叫做随机效应的预测,Nelder认为应该称之为估计,因为一旦数据y已经生成,此时随机效应就是固定的,关于随机效应的最优无偏预测也可以认为是最优无偏估计。令θ1和θ2分别是固定参数θ的任意两个值,这两个参数的信息都包括在似然比L(θ1;y)/ L(θ2;y)中,设存在一个随机效应的尺度v,使θ1和θ2的似然比保持不变:
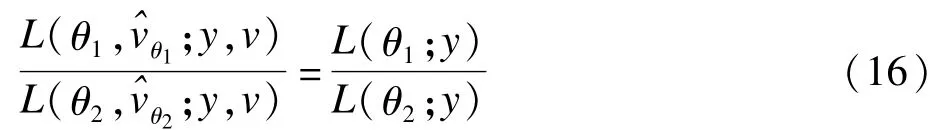

如果存在上述定义的规范尺度的参数v,那么就可以马上得到等级似然,然而,并不是所有的统计问题都存在规范参数,因此需要拓展它的定义。事实上,等级似然的定义正是扩展似然的一个特殊情形,也就是说,当v是规范的时候,扩展似然L(θ,v;y,v)就是等级似然,下面用H(θ,v)表示等级似然,用h(θ,v)表示对数等级似然。对数等级似然可以被看作通常的对数似然函数,可以对它关于固定参数和随即参数(θ,v)一起求导计算相应的Fisher信息,在一般的统计问题中,什么样的随机效应参数应该是规范尺度的随机变量参数不是很明显,然而检验一个特定尺度是否是规范的却很容易。如果规范尺度的随机效应参数存在,关于参数的推理将会大大简化。
关于这些性质的进一步讨论可以参考Lee,Nelder 和Pawitan(2006)[24]。假设v是规范尺度的,非线性变换u≡v(u)将扩展似然变为:
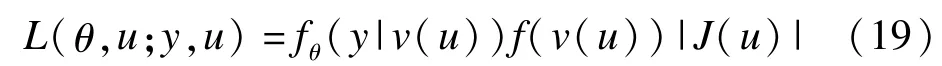
由于雅克比项|J(u)|的存在,u不是规范尺度的。也就是说,在线性变换意义下,规范尺度是唯一的。
上述等级似然的定义比较严格,规范尺度是关于所有固定参数定义的,需要进一步扩展。假定固定参数分为两部分(θ,φ),成立:
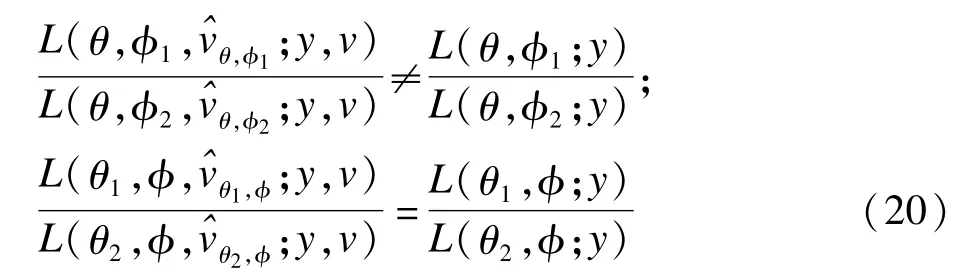
这种情形下,尺度v仅仅是与θ的信息无关,而关于φ则不然。使用等级似然的推理仅适用于(θ,v),而关于φ的推理则需要边际似然,关于φ的边际似然可以使用调整的轮廓似然近似:
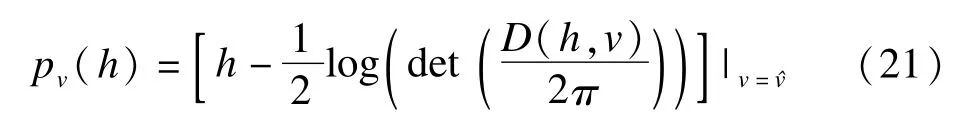
其中,D(h,v)是φ的函数,与θ无关。至此,完成了模型中所有参数(θ,v,φ)的估计。
Lee等(2006)[24]指出,在广义混合线型模型中,如果随机效应和协变量在线性预测部分中可加,那么这种随机效应尺度就是弱规范尺度,弱规范尺度的随机效应总可以找到;而且,此时协变量系数β的估计和随机效应v的实现可以通过最大化等级似然获得,等级似然函数二阶导数的相反数之逆仍然给出了协变量系数和随机效应实现估计值的方差。上面的这些性质为等级似然的应用提供了可行的理论基础。
应用举例
我们以竞争风险下比例危险模型为例说明等级似然估计的应用。我们假定两个竞争风险情形。设观测数据为Tij(i =1,2,…,q,j =1,2,…,ni)表示第i个体的第j个重复观测。用Δij=(δij1,δij2)表示第ij个观测的时间属性,δij1或δij2为1表示事件发生,为0表示删失。设二元随机效应变量V =(V1,V2),假设在给定协变量X以及V的条件下,T1,T2相互独立;第ij个个体在不同风险下的危险函数设为半参数Cox比例危险模型为:
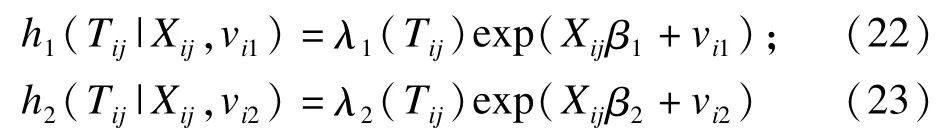

对第ij个个体,可以定义竞争风险下比例危险模型的等级似然函数:它是可观测的生存时间和随机效应因子的联合对数密度函数。记y(k)(k =1,2,…,K)为第k个观测的持续期,y(1)<y(2)<…<y(K)。可以得到:
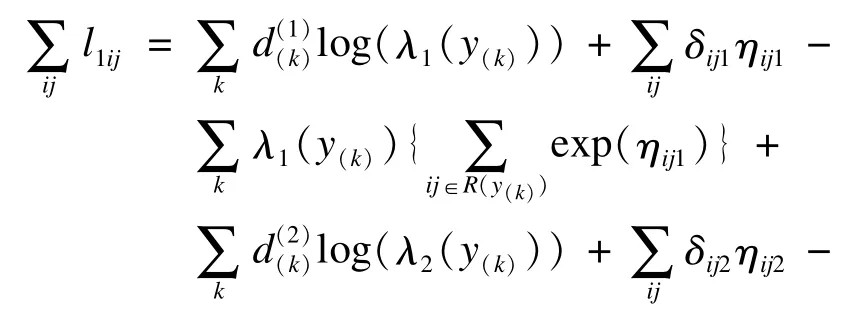
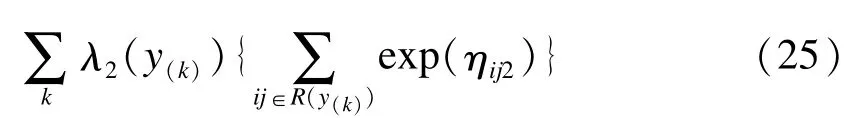
其中,R(y(k))表示y(k)时刻的危险集,是y(k)时刻分别因为两种风险事件发生的数目,ηij1=xijβ1+ vi1,ηij2=xijβ2+ vi2。如果第ij个观测在y(k)时刻因第一种风险事件发生,则令否则令0;同样定义记表示K个时刻第一种风险的基本危险率向量,其中log(λ1(y(k)));同样定义记exp(ηij2),则
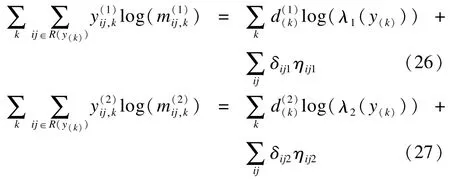
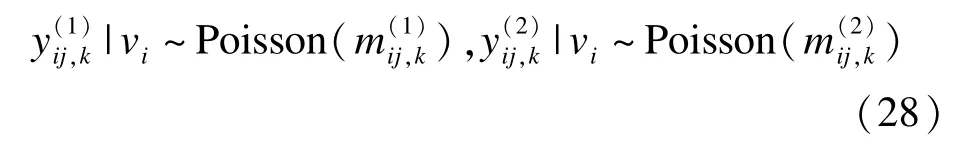
其中(i,j)∈R(y(k)),且parameters)],并不影响上述结论。
通过上述讨论,发现竞争风险下的Cox脆弱性比例危险模型可以纳入混合广义线性模型的框架,也就是说,根据Lee等(2006)[24],竞争风险下Cox比例危险模型中随机效应尺度是弱规范尺度,从而可以利用第三部分讨论的等级似然估计方法和程序对随机效应竞争风险模型进行估计。显然,经典脆弱性Cox比例危险模型也同样可以纳入混合广义线性模型框架,利用等级似然理论,可以扩展Cox脆弱性模型中随机效应的分布。
小 结
本文对近年来模型估计理论中的一个新的热点问题进行了介绍和讨论:即等级似然理论及其应用。本文从经典的似然理论开始,引出其扩展,接着介绍了当模型的参数比较多时,估计感兴趣参数的轮廓似然方法,由此过渡到随机效应模型的等级似然估计方法。在上述基础上,本文介绍了等级似然估计对于模型中三类参数的估计方法和程序,即模型中关注变量的系数、随机效应的实现值、随机效应分布参数。最后,本文对等级似然理论的应用进行举例说明。等级似然理论相对于贝叶斯理论的应用较为简洁,对于随机效应广义线性的估计而言,是一种有效的估计方法。对于等级似然估计方法,期待未来更多地应用领域。
参考文献
[1]Fisher RA.On the“Probable Error”of a Coefficient of Correlation Deduced from a Small Sample.Metron,1921,1:3-32.
[2]Lee Y,Nelder JA.Hierarchical generalized linear models.Journal of the Royal Statistical Society.Series B(Methodological),1996,619-678.
[3]Do Ha I,Lee Y,Song JK.Hierarchical-likelihood approach for mixed linear models with censored data.Lifetime data analysis,2002,8(2):163-176.
[4]Do Ha I,Lee Y.Multilevel mixed linear models for survival data.Lifetime data analysis,2005,11(1):131-142.
[5]徐淑一,王宁宁.竞争风险下纵列数据的随机效应建模和估计.中山大学学报(自然科学版),2007,46(1):7-10.
[6]Wang N,Xu S,Fang J.Hierarchical likelihood approach for the Weibull frailty model.Journal of Statistical Computation and Simulation,2011,81(3):343-356.
[7]王宁宁,徐淑一,方积乾.重复观测生存数据的AR(1)随机效应建模和估计.中国卫生统计,2014,31(6):1-4.
[8]Lee Y,Jang M,Lee W.Prediction interval for disease mapping using hierarchical likelihood.Computational Statistics,2011,26(1):159-179.
[9]Noh M,Lee Y,Kenward MG.Robust estimation of dropout models using hierarchical likelihood.Journal of Statistical Computation and Simulation,2011,81(6):693-706.
[10]Noh M,Wu L,Lee Y.Hierarchical likelihood methods for nonlinear and generalized linear mixed models with missing data and measurement errors in covariates.Journal of Multivariate Analysis,2012,109:42-51.
[11]Lee D,Lee Y,Paik MC,et al.Robust inference using hierarchical likelihood approach for heavy-tailed longitudinal outcomes with missing data:An alternative to inverse probability weighted generalized estimating equations.Computational Statistics &Data Analysis,2013,59(0):171-179.
[12]Wu J,Bentler PM.Application of H-likelihood to factor analysis models with binary response data.Journal of Multivariate Analysis,2012,106:72-79.
[13]徐淑一,王宁宁,王美今.竞争风险下纵列持续数据随机效应模型的估计与模拟研究.数理统计与管理,2009,28(6):1013-1023.
[14]Ha ID,Lee M,Oh S,et al.Variable selection in subdistribution hazard frailty models with competing risks data.Statistics in medicine,2014,33(26):4590-4604.
[15]Lee M,Do Ha I,Lee Y.Frailty modeling for clustered competing risks data with missing cause of failure.Statistical methods in medical research,2014,0962280214545639.
[16]Birnbaum A.On the foundations of statistical inference.Journal of the American Statistical Association,1962,57(298):269-306.
[17]Barndorff-Nielsen O.On a formula for the distribution of the maximum likelihood estimator.Biometrika,1983,70(2):343-365.
[18]BjØrnstad JF.On the generalization of the likelihood function and the likelihood principle.Journal of the American Statistical Association,1996,91(434):791-806.
[19]Lauritzen SL.Sufficiency,prediction and extreme models.Scandinavian Journal of Statistics,1974:128-134.
[20]Butler RW.Predictive likelihood inference with applications.Journal of the Royal Statistical Society.Series B(Methodological),1986:1-38.
[21]Vaida F,Meng XL,Xu R.Mixed effects models and the EM algorithm.Applied Bayesian Modeling and Causal Inference from Incomplete-Data Perspectives:An Essential Journey with Donald Rubin′s Statistical Family,2004:253-264.
[22]Gelfand AE,Smith AF.Sampling-based approaches to calculating marginal densities.Journal of the American Statistical Association,1990,85(410):398-409.
[23]Crouch EA,Spiegelman D.The Evaluation of Integrals of the form∫+∞-∞f(t)exp(-t2)dt:Application to logistic-Normal Models.Journal of the American Statistical Association,1990,85(410):464-469.
[24]Lee Y,Nelder JA,Pawitan Y.Generalized linear models with random effects:unified analysis via H-likelihood.CRC Press,2006.
[25]Lee Y,Nelder JA.Likelihood for random-effect models.SORT,2005,29(2):141-164.
(责任编辑:郭海强)
·短篇报道·
*基金项目:广州医科大学项目(L135021);广东省软科学项目(2013B070206027)
通信作者:△徐淑一
