基于领域知识抽样的深网资源采集方法
2016-05-04林海伦熊锦华程学旗
林海伦,熊锦华,王 博,程学旗
(1. 中国科学院 计算技术研究所,北京 100190; 2. 中国科学院大学,北京 100049; 3. 国家计算机网络应急技术处理协调中心,北京 100029)
基于领域知识抽样的深网资源采集方法
林海伦1,2,熊锦华1,王 博3,程学旗1
(1. 中国科学院 计算技术研究所,北京 100190; 2. 中国科学院大学,北京 100049; 3. 国家计算机网络应急技术处理协调中心,北京 100029)
深网资源是指隐藏在HTML表单后端的Web数据库资源,这些资源主要通过表单查询的方式访问。然而,目前的网页采集技术由于采用页面超链接的方式采集资源,所以无法有效覆盖这些资源,为此,该文提出了一种基于领域知识抽样的深网资源采集方法,该方法首先利用开源目录服务创建领域属性集合,接着基于置信度函数对属性进行赋值,然后利用领域属性集合选择查询接口并生成查询接口赋值集合,最后基于贪心选择策略选择置信度最高的查询接口赋值生成查询实例进行深网采集。实验表明,该方法能够有效地实现深网资源的采集。
深网;置信度;抽样;领域知识
1 引言
深网(Deep Web)是指网络爬虫通过页面之间的链接关系难以采集到的资源,这些资源通常隐藏在HTML表单后端的Web数据库中,主要通过表单查询的方式动态访问。深网资源具有以下主要特点: 一是深网资源比搜索引擎可索引的资源(浅网[1])在规模上更大,并且增长速度非常快: 2000年BrightPlanet发布的对深网资源进行统计分析的白皮书中指出深网资源是互联网上浅网资源的五百倍[1],而且从2000年到2004年,深网资源增长了 3~7倍[2],并且仍在不断增长[3];二是深网资源领域覆盖面广,数据结构化程度高,为用户提供的信息质量更高: 深网资源覆盖各种不同的领域,如教育、电子商务、房地产、娱乐等[3],而且主要以结构化的数据的形式存储在Web数据库中[4]。
由此可见,与浅网相比,深网具有数据量更大、内容覆盖面更广、结构化更好等优点,这使得深网资源对数据分析类的应用(如市场分析、比价购物)和知识库的构建来说价值更高。目前获取深网资源方法的研究主要集中在利用爬虫技术主动查询深网数据库,迭代地“发现”深网数据库中的内容,这种方法与传统的浅网采集方法不同: 需要爬虫能够自动发现深网资源的查询接口,并且为查询接口中的查询输入项选择合适的取值生成查询,从查询的响应结果页中提取数据记录从而实现深网资源的采集。利用这种方法进行深网采集是一个充满挑战的问题,原因在于: 深网的数据规模比浅网规模更大,尝试覆盖所有的深网资源是不可行的;而且访问深网资源只能通过为用户设计的限制搜索的查询接口,训练一个爬虫使用这个限制搜索的查询接口提取相关的内容是非常困难的。同时,对应用来说,采集所有深网资源的价值可能并不比采集特定的深网资源的价值高。
为此,本文提出了一种面向特定领域(应用)的基于知识抽样的深网采集方法,该方法采用人工辅助的方式,利用人工定义的资源采集需求描述自动实现深网资源采集。具体地说,本文目标是基于特定领域或应用的需求,有针对性地采集深网资源: 该方法首先根据领域或应用需求描述,实现领域知识抽样(采集任务抽样),然后根据领域知识样本实现指定站点的深网资源采集,人工辅助的方式能够支持爬虫对应用或任务相关的深网资源提交查询。该方法的创新之处在于:
• 提出了根据领域或应用需求描述,自动实现领域知识抽样的算法;
• 提供并实现了基于领域知识抽样处理深网资源采集的新方法,包括领域(任务)相关的深网资源选择和查询实例生成技术。
本文的组织结构如下: 第二节介绍相关工作;第三节介绍领域知识抽样的原理;第四节介绍基于领域知识抽样的深网资源采集过程,包括查询接口处理和查询实例生成;第五节是实验和评价;最后总结全文。
2 相关工作
为了提高深网资源覆盖率,充分挖掘深网资源的价值,使深网资源能够服务最终用户,近年来,深网资源采集技术得到了广泛研究,已经出现很多支持深网资源采集的工具和方法。Raghavan等人[5]设计了一种深网资源采集的框架HiWE,HiWE采用面向特定领域的方式: 需要人工提供领域属性及属性取值集合,并利用领域属性和属性取值,生成查询集合,然后利用爬虫技术进行资源采集。HiWE还利用深网资源查询接口中选择输入项的取值更新属性取值,但是没有考虑利用爬虫的采集结果自动更新领域属性取值的方式。
不同于HiWE,Wu[6]提出一种基于属性值图的深网资源采集方法,该方法将基于查询的深网采集建模为图的遍历问题。该工作得出结论认为结构化的数据库属性值图中结点的度分布与幂律分布(power law)相似,并以此为依据采用贪心选择策略选择度大的结点生成表单查询。但是该方法需要将每一次的查询结果增加到已有的属性值图中,然后生成下一个新的待提交的查询词,更新属性值图的代价较高。
DeepBot[7-8]是一个基于浏览器内核开发的深网采集的方法,它基于浏览器内核设计深网资源爬虫,解决网页客户端浏览器脚本解析问题,DeepBot与HiWE类似,都采用面向特定领域的方式,接受一组领域定义集合作为输入,指导深网资源的采集。但是该方法完全依赖人工提供的领域定义集合,没有考虑领域定义集合的更新问题。
为此,Madhavan[9]提出了一种基于查询模板的深网资源自动采集方法,该方法自动判断查询接口中输入元素接受的数据类型,选择查询接口中的输入项的一个子集作为约束项构造查询模板,该方法通过表单查询返回结果验证查询模板的有效性。虽然该方法能够自动实现深网查询请求的生成,但是对于包含多个输入项的查询接口来说,其对应文本输入项取值集合的确定、查询模板有效性的验证过程复杂,导致深网资源采集的效率较低。
西安交通大学的Jiang和Wu等人[10-12]提出了基于增强学习(Reinforcement Learning,RL)的深网资源采集方法,该方法在选择查询时除了利用统计信息之外,还利用语言特征以及HTML本身的特征[10]。RL方法允许爬虫根据从已执行的查询中获取的经验自动学习查询选择策略,从而为每一轮查询选择收益最大的查询关键词进行资源采集。但是相比有人工方式参与的深网资源采集方法,该方法的学习过程相对复杂。
上述工作都从不同角度对深网资源采集方法进行研究,通过分析我们发现完全人工和完全自动的深网采集方法都存在局限性,为此,我们需要一种在它们之间折中的深网资源采集方法来克服这种局限性。
3 领域知识抽样
深网数据库的资源通常是属于某个特定领域的,而同一领域的数据库的属性值和属性值的分布相似。因此,考虑同一领域各个数据库之间的相似性,利用同一领域的数据样本,爬虫则可以获得该领域查询接口的属性取值生成查询,实现深网资源的采集。问题的关键在于如何能有效地获取领域知识,并整合到深网资源采集框架中。在本节,我们提出了一种面向领域的知识抽样方法,在介绍抽样方法之前,我们首先讨论领域知识的表示。
3.1 领域知识表示
定义1 领域知识: 关于领域DM的领域知识DK是对领域及领域数据的描述,领域知识由一组领域属性和实例组成:DK=
文献[3]对不同领域的深网查询接口中出现的属性词汇进行统计分析发现: 同一领域的查询接口中出现的属性词汇数量趋于收敛在一个相对小的规模,而且,同一领域深网查询接口中的属性呈现Zipf分布。这就说明通过人工分析方式获取领域属性A的可行性,因此通过分析同一个领域中的几个数据源通常就足以发现领域中重要的属性并获得属性的别名信息。
在深网资源采集中,可以用领域知识定义数据采集任务,领域属性a则表示出现在与采集任务相关的深网查询接口中的查询输入项,属性a的别名aliases则用于标识属性a在查询接口中出现的替代标签,如针对图书采集的领域知识中,属性“作者”可能的别名有“著作者”、“译著者”等,属性a的affinity则用于标识如果查询接口包含该属性时,该深网资源与领域相关的可能性,例如,在针对图书资源采集时,属性“ISBN”的affinity的取值会很高(如0.95),因为,如果查询接口允许对ISBN属性进行查询则几乎可以肯定是对图书进行查询,而“价格”的affinity的取值则会比较低(如0.05)。其中属性的affinity取值并不是固定的,可以因人而异。实例I则表示深网查询接口中的查询输入项可用的取值。
3.2 领域知识抽样算法
领域属性A获取之后,关键问题是如何获得这些属性的取值,即领域的实例集合I。可以通过人工的方式为每个属性选择取值信息,获得实例集合,但是这种方法明显需要大量的时间和人力,难以扩展到大规模的深网采集任务上。为此,本文提出了基于领域属性的抽样算法,其主要思想是基于领域属性的信息,从在线目录服务(如ODP)、维基百科(Wikipedia)中选择一些Web站点作为数据源自动实现属性实例的获取。本文使用OXPath[13]作为数据提取工具对Web页面P进行内容抽取,结果记为Results(P),每条数据记录用键-值对(key-value)的形式表示,即Results(P)={R1,R2, …,Rm},其中,Ri={f1,f2, …,fn},fj表示数据的字段信息:fj=
然而,与通过人工方式提供的属性实例相比,通过抽样方式自动获取的属性实例的置信度无法保证与人工提供的相同,为此,我们引入属性实例置信度函数F(c,a),在抽样过程中利用F(c,a)为属性a的抽样实例c分配一个权重wc(0≤wc≤1),用于表示该抽样实例的置信度。属性实例置信度函数F(c,a)的定义和抽样实例的构造如下:
1) 如果在抽样站点的Web页面中,成功抽取到属性a,则F(c,a)=1: 即在Ri中存在一个字段fj,其对应的key与属性a的名称(a.name)或别名(a.aliases)中的某一个值相等,则构造抽样实例c=
2) 如果在抽样站点的Web页面中,没有抽取到属性a,但是在Results(P)的数据记录中字段fj对应的取值有kj(0
3) 如果在抽样站点的Web页面中,没有抽取到属性a,在Results(P)的数据记录中字段fj对应的取值出现在属性a的实例集合Ia中的次数为0时,则F(c,a)的定义如式(1)所示。
(1)
其中,B=a.aliases∪{a.name},sim(keyj,bi)表示字段fj与bi的相似度:
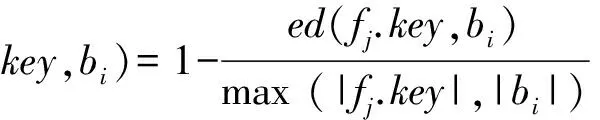
(2)
其中,ed(fj.key,bi)为字段fj的key与bi的编辑距离[14];|·|表示词的长度。在此,选择Results(P)与属性a相似度最大的字段fj的取值构造抽样实例c=
通过上述方式得到针对属性a的抽样实例集合Ia,并得到该实例集合的置信度WIa:WIa={wc|c∈Ia}。下面将详细介绍基于领域知识抽样的深网资源采集方法。
4 深网资源采集
在引言中已分析指出,对深网进行采集时,需要解析页面包含的查询接口,并为查询接口中的输入项选择合适的取值,不断地向查询接口主动提交查询迭代地“发现”深网内容。接下来我们介绍如何利用抽样得到的领域知识,自动实现用户指定的深网资源的采集。
4.1 查询接口处理
查询接口在网页中是以HTML的Form元素表示的表单形式存在的,但是并不是所有的表单都是深网资源的查询接口。因此,为了获得Web站点中与采集任务相关的查询接口,首先需要提取页面包含的表单;然后过滤表单,获得与采集任务相关的深网资源的查询入口。目前,已有很多表单提取工具,如LabelEx[15]、HMME[16]、VisQIExt[17]、ExQ[18]和OPAL[19]等,Khare等人[20]对表单提取的相关工作进行了详细的研究分析,我们使用OPAL[19]工具对页面包含的表单进行提取: OPAL 是典型的基于规则的表单提取工具,它利用表单的视觉信息生成提取规则,通过制定规则匹配常见的Web页面设计方式。下面分别介绍表单提取过程中的查询接口模型以及基于领域知识的查询接口选择算法。
4.1.1 查询接口建模
查询接口(QI, Query Interface)被表示成四元组:QI=
提取页面包含的表单之后,则需要从这些表单中选择与采集任务相关的查询接口。
4.1.2 查询接口选择
如第三节所述,如果一个深网资源属于定义的采集任务(记为T),则该深网资源的查询接口元素的label信息与领域知识DK中某个属性a相关的概率会很高,因此,我们将查询接口选择问题转换为计算查询接口元素与领域属性的相似度计算问题,即查询接口与采集任务的相关度R(QI,T)可以转换为查询接口与领域知识DK的相关度计算R(QI,DK)。R(QI,DK)可通过式(3)计算。
R(QI,T)=R(QI,DK)
(3)
其中,E表示查询接口QI包含的元素集合:E=QI.elements;A为领域知识DK包含的属性集合:A=DK.A;a.affinity表示属性a与领域的相关度(见3.1节);S(e,a)表示查询接口的元素e与领域属性a的相似度:S(e,a)定义为:
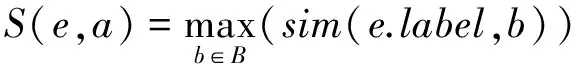
(4)
其中,B={a.name}∪a.aliases;sim(e.label,b)计算方法如式(2)所示(见3.2节)。
查询接口选择算法的基本思想是: 基于抽样获取的领域知识DK和提取的查询接口模式信息,实现查询接口与采集任务相关度R(QI,T)的计算,并根据设定的相关度阈值μ判断查询接口是否属于定义的采集任务。获得与采集任务相关的深网资源的查询入口后,接下来则需要为查询接口选择合适的输入值进行填充,从而生成有效的表单查询请求,实现深网资源的采集。下面我们介绍查询接口的查询请求生成算法。
4.2 查询实例生成
在4.1节,在对查询接口QI进行采集任务相关性判断时,是通过计算查询接口元素e与领域属性a的文本相似度S(e,a)实现的。为此,我们也通过查询接口元素e与领域属性a的文本匹配对元素e进行赋值。具体地说,对于QI的每个元素ei,我们采用以下方式为其取值生成一个赋值集合Vi,并用pvik表示为元素ei选取第k个值的置信度,PVi={pvik|vik∈Vi}表示该赋值行为的置信度:
• 如果ei是选择输入项(radio、checkbox、select类型的元素),则Vi=ei.domains,并且PVi=1;
• 如果ei是文本输入项,则选择属性aj=argmaxaj∈DK.A{S(ei,aj)}的实例集合Iaj对元素ei进行赋值:Vi={ck.value|ck∈Iaj},pvik=wck,PVi=WIa,其中,aj∈DK.A;
• 如果通过上述两种情况无法获得元素ei的取值,则Vi=∅,并且令PVi=1。
对QI的每个元素ei按照上述方式赋值之后,基于领域知识抽样DK为查询接口QI生成的所有的赋值集合为Q(QI,DK)={
(5)
利用贪心选择策略,从Q(QI,DK)中选择φr最大的赋值生成查询实例,并对查询实例的响应结果利用抽样算法为查询接口生成新的赋值。通过上述过程,迭代地为查询接口QI自动生成查询实例,实现查询接口QI后端深网资源的采集。
5 实验和评价
深网资源采集一般选用查询提交效率(submission efficient,SE)和资源覆盖率(coverage rate,CR)作为方法评价指标[5]。查询提交效率的定义如下:SE=Nsuccess/Ntotal,其中,Ntotal表示在采集过程中对查询接口QI生成的查询实例的总数;用Nsuccess表示在查询实例对应的响应结果页中能够获得一个或多个搜索结果的查询实例的数目;资源覆盖率的定义如下:CR=Rretrieval/RDB,其中,RDB表示该深网数据库的资源总数,Rretrieval表示通过查询提交采集到的资源数目。查询提交效率用于评估在给定时间内,深网采集方法完成采集任务的有效率,查询提交效率越高,将会获取更多有用的深网资源的可能性越大;资源覆盖率用于评价采集深网资源的能力,资源覆盖率越高,采集到的深网资源的数据量越大。本文也采用它们作为我们工作的评价指标。本文利用基于随机策略的查询实例生成方法[6](记为Random)和基于Zipf策略的查询实例生成方法[11](记为Zipf)与基于领域知识抽样的查询实例生成方法(记为DKS)进行对比测试。
5.1 数据集
我们选择了一个论文数据库: DBLP数据库,记为DBLP,该数据库可以免费从Web下载,我们选择的DBLP包含一百万条记录,将其部署在远程服务器上,用于模拟深网资源的抓取,我们设定DBLP数据库的每个查询结果列表页最多包含20条记录。另外,我们又选用了两个在线图书数据库: 当当图书和京东图书,分别记为DBooks和JBooks,当当目前在库图书有60万种,京东目前在库图书有40万种。对于DBLP,我们选取论文题目、作者名、期刊/会议名称、时间作为查询实例生成属性,对于当当图书和京东图书,选择书名、作者名、出版社、类别作为查询实例生成属性。
5.2 实验结果与分析
在上述三个数据库上,分别利用领域知识抽样方法(DSK)、随机方法(Random)和Zipf方法(Zipf)对查询提交的效率和资源覆盖率进行比较。从ODP目录划分的“图书”分类中选择当当网和亚马逊作为图书领域知识抽样站点,从“Conferences”分类中选择DBLP和IEEE作为学术论文知识抽样站点,生成初始候选查询集合。Random方法每次随机地从响应结果页中选择一个新词生成下一轮的查询实例,Zipf方法则利用词在页面中出现的词频选择出现频率最大的新词生成下一轮的查询实例。
(1) 查询提交效率
我们利用DSK、Random、Zipf在三个数据库上分别生成查询实例用于查询提交效率的测试,图1(a)(b)(c)分别表示不同数据库上三种方法得到的查询提交效率的比较。

图1 查询提交效率实验
图1中,横坐标表示查询实例的个数,纵坐标表示查询提交的效率(SE),由实验结果可知,随着提交的查询实例数的增加,三种方法的查询提交效率都在降低,但是DSK方法的查询提交效率在所有测试用例中均优于Random方法和Zipf方法,而且当提交的查询数量增加时,其优势越明显。由此可见,在对深网资源进行采集时,人工参与可以提高深网采集方法获取更多有用的深网资源的概率,使得在给定时间内完成采集任务的效率越高。
(2) 资源覆盖率
我们利用DSK、Random、Zipf分别对三个数据库进行资源采集,在本实验中,只要有一种方法爬取的资源覆盖率大于80%就停止实验。图2(a)(b)(c)分别表示不同数据库上三种方法得到的资源覆盖率的比较。
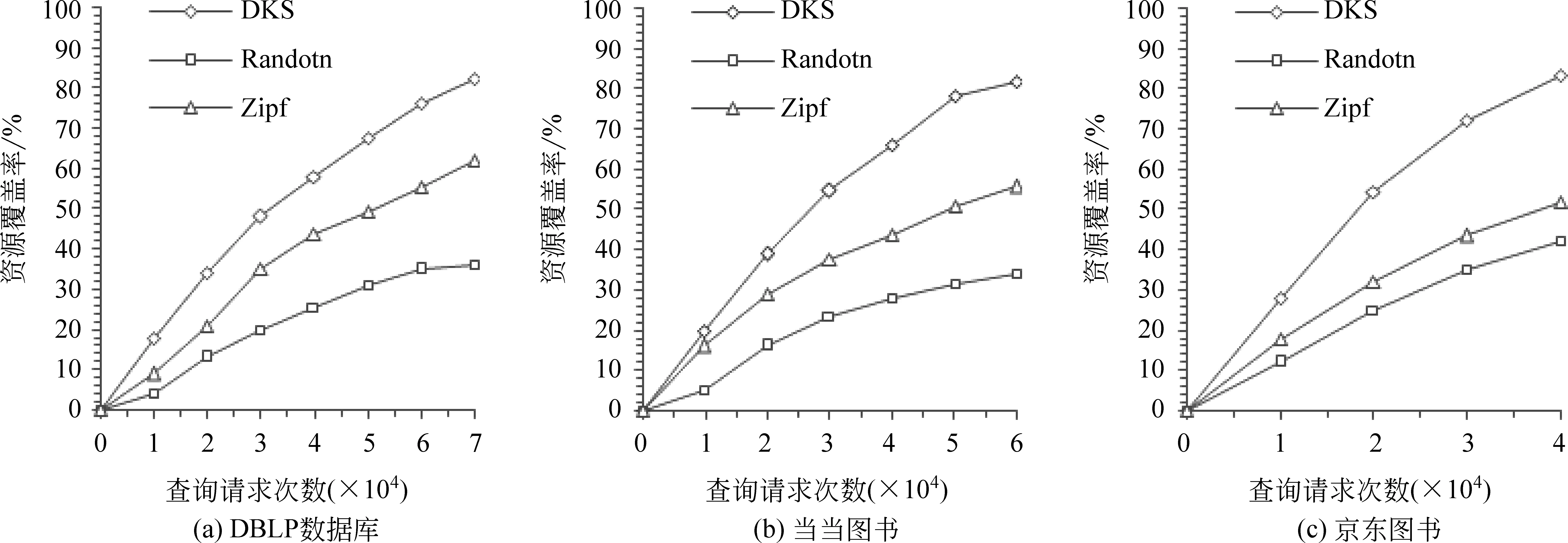
图2 资源覆盖率实验
图2中,横坐标表示向数据库提交查询的次数,这里的查询次数不是查询实例提交的个数,而是查询请求的次数(一个查询实例返回的结果可能分多页显示,如果想获取该查询实例对应的所有结果必须通过翻页得到,每一次翻页相当于一次查询请求),纵坐标表示数据库资源的覆盖率(CR),由实验结果可以,在三个数据库上都是DKS方法最先达到80%以上的资源覆盖率,由此可见,人工参与的基于领域知识抽样的深网资源采集方法能够以最小的代价获取更多的深网资源。
实验结果表明,本文提出的基于领域知识抽样的深网资源采集方法比随机方法和Zipf方法具有更优异的性能表现,它的查询提交效率和资源覆盖率均优于其它对比系统。
6 总结
在本文中,我们提出了一种面向特定领域/应用的深网采集方法,该方法利用在线目录服务实现特定采集任务的知识抽样,基于知识抽样自动实现深网资源的采集。实验表明该方法能够有效解决隐藏在Form表单后端的深网资源的采集问题。目前,本文所采用的领域知识的抽样方法依赖人工分析获取的领域属性和抽样站点信息,下一步我们将研究利用深网站点自身提供的数据自动生成查询实例,实现深网采集。
[1] M K Bergman, The Deep Web: Surfacing Hidden Value[J]. Journal of Electronic Publishing, 2001,7(1)[DB/OL]DOI:http://dx.doi.org110.399813336451.0007.104
[2] K C C Chang, B He, C Li, et al. Structured databases on the web: Observations and implications[R]. ACM SIGMOD Record, 2004,33(3): 61-70.
[3] B He, M Patel, et al., Accessing the deep web:A Survey[C]//Proceedings of the Communications of the ACM, 2007, 50(5): 94-101.
[4] 刘伟, 孟小峰, 凌妍妍, 一种基于图模型的 Web 数据库采样方法[J]. 软件学报, 2008, 19(2): 179-193.
[5] S Raghavan, H Garcia-Molina. Crawling the Hidden Web[C]//Proceedings of 27th VLDB. 2001:129-138.
[6] P Wu, J R Wen, H Liu, et al. Query selection techniques for efficient crawling of structured web sources[C]//Proceedings of the 22nd International Conference on Data Engineering. 2006: 47-56.
[7] M A lvarez, J Raposo, F Cacheda, et al., A Task-specific approach for crawling the deep web[J]. Journal Engineering Letters. Special Issue: Advances in Information Engineering, 2006, 13(2): 204-215.
[8] M A Lvarez, J Raposo, A Pan, et al. DeepBot: a focused crawler for accessing hidden web content[C]//Proceedings of the ACM Conference on Electronic Commerce. 2007:18-25.
[9] J Madhavan, D Ko, L Kot, et al. Google’s deep web crawl[J]. VLDB Endowment, 2008,1(2): 1241-1252.
[10] L Jiang, Z Wu, Q Zheng, et al. Learning deep web crawling with diverse features[C]//Proceedings of the IEEE/WIC/ACM International Joint Conferences on Web Intelligence and Intelligent Agent Technologies. 2009: 572-575.
[11] L Jiang, Z Wu, Q Feng, et al., Efficient deep web crawling using reinforcement learning[J]. Advances in Knowledge Discovery and Data Mining, 2010: 428-439.
[12] Q Zheng, Z Wu, X Cheng, et al., Learning to Crawl Deep Web[R]. Information Systems, 2013,38(6):801-819.
[13] T Furche, G Gottlob, G Grasso, et al., OXPATH: A Language for Scalable Data Extraction, Automation, and Crawling on the Deep Web[J]. The VLDB Journal, 2012,22(1): 47-72.
[14] V I Levenshtein. Binary codes capable of correcting deletions[J], insertions and reversals. 1966,10(8): 707-710.
[15] H Nguyen, T Nguyen, J Freire, Learning to extract form labels[R]. VLDB Endowment, 2008,1(1): 684-694.
[16] R Khare. An empirical study on using hidden markov model for search interface segmentation[C]//Proceedings of the 18th ACM Conference on Information and Knowledge Management, 2009: 17-26.
[17] E C Dragut, T Kabisch, C Yu, et al., A hierarchical approach to model web query interfaces for web source integration[C]//Proceedings of the VLDB Endowment, 2009,2(1): 325-336.
[18] W Wu, A H Doan, C Yu, et al., Modeling and extracting deep-web query interfaces[J]. Advances in Information and Intelligent Systems, 2009: 65-90.
[19] T Furche, G Gottlob, G Grasso, et al. OPAL: automated form understanding for the deep web[C]//Proceedings of the 21st International Conference on World Wide Web. 2012: 829-838.
[20] R Khare, Y An, I Y Song, Understanding deep web search interfaces: a survey[R]. SIGMOD record, 2010,39(1): 33-40.
An Approach to Crawling the Deep Web Based on Domain Knowledge Sampling
LIN Hailun1,2, XIONG Jinhua1, WANG Bo3, CHENG Xueqi1
(1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100049, China; 3. CNCERT/CC, Beijing 100029, China)
The Deep Web refers to the Web databases content hidden behind HTML forms, which can only be accessed by performing form submissions. The current web page collection technologies can not cover these resources effectively by employing only hyperlinks. For this purpose, this paper proposes an approach to crawling the deep web based on domain knowledge sampling. Firstly, it creates a domain attributes set using open source directory services and assigns the attributes based on a confidence function; Secondly, it uses the domain attributes set to select query interface and generate assignments, and finally, it selects the assignment with the highest confidence as a query instance for deep web crawling based on greedy algorithm. Experiments show that our approach can effectively collect the deep web resources.
deep web; confidence; sampling; domain knowledge

林海伦(1987-),通信作者,博士,助理研究员,主要研究领域为数据挖掘、知识图谱。E⁃mail:linlunnian@software.ict.ac.cn熊锦华(1972-),博士,副研究员,主要研究领域为大规模数据处理、搜索引擎等。E⁃mail:xjh@ict.ac.cn王博(1982-),博士,高级工程师,主要研究领域为网络与信息安全、社会计算。E⁃mail:wbxyz@163.com
1003-0077(2016)02-0175-07
2013-06-08 定稿日期: 2013-12-09
国家科技支撑计划课题(2011BAH11B02,2012BAH46B04);国家242专项(2013G129);国家自然科学基金(61300206)
TP391
A
