基于图表示和匹配的表单定位与提取
2019-04-10谭婷吕淑静吕岳
谭婷,吕淑静,吕岳,
(1. 华东师范大学 上海多维度信息处理重点实验室,上海 200062; 2. 中国邮政集团公司上海研究院 图像分析与智能系统联合实验室,上海 200062)
表单作为重要的信息载体在实际生活和工作中有着广泛的运用,表单中某些特定字段、图案、符号等都有可能包含用户感兴趣的重要信息,如订货单中的订单号、发票的具体项目及金额、快递运单中的收货地址和手机号码等。人工录入的方式采集数据,费时费力,而且容易出错,因此利用计算机对表单图像进行自动化信息提取有着强烈的应用需求,可以大幅度降低工作量,提升工作效率。
表单自动化处理的主要过程包括表单图像采集、表单定位、信息区域提取、识别等[1]。其中表单定位和提取是表单识别前重要的预处理过程,预先获取表单关键信息区域有利于更方便、准确地识别表单填写的内容信息。本文方法主要工作是对物流快递表单中与用户信息相关的文本区域进行定位和提取,如快递表单上收/寄件人姓名、电话号码、地址等信息。该处理过程得到文本图像块可用于后续识别工作的输入数据,建立字符图像数据库,图像特征学习的训练样本,具有广阔的应用前景。
表单提取过程中常见的方法是检测表单中的直线,将其作为表单提取的参考位置[2-3]。基于直线的检测法所处理的对象更倾向于类似于表格类结构化的表单,但对缺乏框线和非固定形式的非结构化表单的处理存在明显的不足。
另一类表单定位与提取的方法是采用对表单的布局或表单元素进行描述的方法,如建立搜索分类树[4]或设定提取信息的关联指令[5]。这种对表单的布局或表单元素进行描述的方法缺乏灵活性。
表单图像具有特定的布局方式,因此采用参考模板来提取表单也是一种重要的研究方法,如使用空白表单模板与待匹配表单基准点对齐[6-7]或使用傅里叶-梅林变换重定向表单[8]的方向。Cesarini[9]提出通过属性图结点的具体数值和图的模型特征实现刚性配准,建立待处理图和参考图的对应。
以往的模板匹配方法依赖于对基准点的严格要求和预先约定,而基于非层次有向关系属性图[9]方法在寻找对应区域位置时,难以避免预先识别关键字。本文将模板匹配和图匹配的方法相结合,提出一种基于图表示和匹配的表单定位与提取方法。
图匹配方法在计算机视觉领域有着广泛的应用,如特征点对应[10-11]、形状匹配[12]、目标检测和识别[13-15]、视频分析[16],图像的视觉特征在图匹配过程中考虑两图之间最小结构失真以实现对应。
本文方法在处理多个类别的表单图像时,需要预先选取对应类别表单图像中已有的图案区域设计匹配待处理表单的参考表单模板图,该过程避免了对字符的识别,简化了分类提取的过程。另外,图匹配方法适用于混杂场景下目标检测和异常点判别,结合这一优势,在定位表单时采用图匹配的方法对定位的正确性进行验证。
1 表单图表示
1.1 参考表单的图表示
1.1.1 参考表单关键区域的选取
本文在建立参考表单图表示时,由用户手动选择能反映表单特征的关键区域,比如具有可区分特征的表单公司标志、特定图案、字符块等。由于表单图像上字符较多,背景较为复杂,后续图匹配过程需要足够多的关键区域实现配准,同时匹配计算量适度,建议选取5~8个图案完整、清晰、大小适中的图像块作为关键区域,图1给出一个从邮政快递包裹面单上选取关键区域的例子。

图1 参考表单关键区域选取样例Fig.1 An example for key area selection of reference form
1.1.2 关键区域的图表示
以关键区域为图结点,建立如图2(a)所示参考表单的全连接无向图表示。将该无向图定义为q=(V,E;o,φ),其中V为图结点,对应表单的关键区域。E为图的边,对应结点间的相互连接关系。ω表示每个结点v的结点属性,φ表示每个结点v在图q中的结构属性。图2(b)为图2(a)中结点v7的结构属性表示。

图2 参考表单图样例Fig.2 An example for graph of reference form
1)结点属性 o。SIFT对图像局部特征的描述具有良好旋转和尺度不变性,对光照有较强的鲁棒性。采用SIFT来描述图的结点属性表示为

式中:fij为128维的SIFT特征向量,表示vi中第j个特征点;M为正整数,表示结点vi的特征维度。
2)结构属性 φ 。 φ表示结点vi结构属性,它包括两个子属性:结点权重属性 ω 和夹角属性 θ,结点vi的结构属性表示为 φi={ωi,θi}。
权重属性 ωi。该属性表示以结点vi为固定端点,vi与其所有邻接点vj连接边eij的长度的向量集合。该属性表示如下:

如v7射线簇属性为{e71, e72, e73, e74, e75, e76,e78}。
夹 角 属 性 θi。 α(eij,eik)表 示 图 中 以 结 点vi为顶点,eij和eik分别为与邻接点vj和vk连接边缘所组成的夹角,结点vi所具有的夹角属性表示为以vi为顶点的夹角向量集合 θi,表示如下:

根据上述描述, 即为参考表单关键区域的图表示。
q=(V,E;o,φ)
1.2 待处理表单的图表示
1.2.1 待处理表单候选关键区域的选取
本文采用选择性搜索方法[17]将待处理表单分割得到许多图像小块,这些图像块中包含与参考表单关键区域对应的区域或部分的区域。如图3所示,该算法使得灰度相似且位置相近的像素合并,然后根据图像块的大小、灰度梯度实现图像块粗略过滤,选择图案、字符相对较集中的区域作为待处理表单图像的候选关键区域。

图3 待处理表单候选关键区域选取样例Fig.3 An example for candidate key area selection of test form
1.2.2 候选结点筛选
为提高匹配参考表单图的效率,比较候选关键区域与关键区域的结点属性ω相似度,筛选出相似度最高的前3个图像块作为图匹配的候选结点,建立关键区域与候选关键区域的对应关系,去除大量相似度过小的候选关键区域,降低匹配复杂度。
1.2.3 候选关键区域图表示
对候选结点参照参考表单图建立的过程,建立如图4(b)所示待处理表单的全连接图G。与参考表单图全连接不同的是,对应同一关键区域的3个候选关键区域间不连接。随后,对图G中标签互异的候选子图g进行结点和结构属性描述。

图4 候选同构图Fig.4 Candidate isomorphic graph
2 表单图匹配
由于图像分割策略局限性,分割的候选关键区域可能出现欠分割和过分割的问题。另外,对应于关键区域的位置出现局部遮挡,容易得到错误的候选关键区域。为此,通过对参考表单与待处理表单进行图匹配,验证和确认关键区域是否对应准确。
2.1 候选同构图
给定 G=(V,E)和 G1=(V1,E1)是两个图,假设存在双射 ς :V→V1使得对所有x,y∈V均有xy∈E等价于 ς (x)ς(y)∈ E1,则称G和G1是同构的。假设参考表单图表示为 q =(Vq,Eq;oq,φq),待处理表单图表示为 G =(VG,EG;oG,φG),图g与图q中对应的候选结点赋予与q中相同的标签,如图4(a)中的{a}对应于图4(b)中的{a1,a2,a3}。图G中结点标签互异的图g与图q,恰好满足 ς这一映射关系,故称图g为图q的同构图。因此,图像匹配过程为从图G中寻找一个与图q最相似的同构图g,或寻找与子图qs最相似的同构子图gs,是一个图匹配的问题。通过度量同构图g与图q的相似性,找到相似差异最小的同构图gm或同构子图gsm,作为与图q最佳匹配图。如图4所示,按照同构映射 ς 的定义,在图4(b)所示图G中,图4(a)所示图q:{a,b,c,d}对应的候选同构图有 g1:{a1,b1,c1,d1}, g2:{a1, b1, a, d2},···,g64: {a3,b3,c3,d3}。图匹配目的即为在图4(b)所示的图G中找到最佳匹配的候选同构图gm:{a2,b1,c2,d2}。 ς表示筛选与对应关键区域最相似的前3个候选关键区域,这些候选区域中,可能包含了纹理相似,但在表单上位置不同的图案区域,从而导致候选图中对应的结点出现较大幅度的位置偏差,如图4(b)中b2和d2。因此,需要进一步度量图结构的相似度,寻找图G中与参考表单图q最相似的同构图,如gm,或去除误匹配结点的最相似的同构子图,如果d2为误匹配结点,则目标匹配为同构子图 gsm:{a2,b1,c2}。
2.2 距离度量
将表单进行图表示和属性定义,然后通过度量G中同构图g和q间的属性差异,衡量两图间的距离,距离越小则表示子图g和q的结构越相似,根据属性的差异,确定最相似的同构图gm或同构子图gsm。可以从以下几个方面度量图的差异。
1)结点相似度
对g和q中结点 Vg和 V 的SIFT特征点采取最近邻匹配进而得到匹配特征点对的F-Score值F1(oi),则图结点间的相似距离定义为

2)结构相似度
向量余弦相似度来表示:
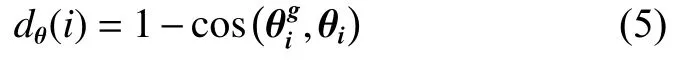
式中 dθ(i)∈ [0,1]。

式中:EX、DX分别为变量X的均值和方差。则该图的权重相似距离为
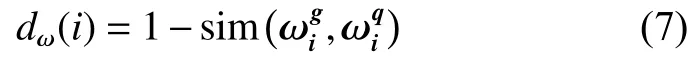
式中 dω(i)∈ [0,1]。
同构图g和图q对应结点的相似度定义为

在进行参考表单q与g的图匹配时,考虑到g与q对应结点缺失或选择错误的情况,若g与q对应结点纹理极为相似,但实际位置并不匹配,较高的纹理相似度会对图的相似度有一定程度的干扰;同样的,当夹角、射线簇边缘相似度过高,同样会影响该结点的整体相似度的评判。故需对当前匹配的g中的结点剪枝,对结点vi中 do(i)、dθ(i)、 dω(i)设置一定的阈值,不符合条件的vi设值为离群点,同时将离群点纳入相似度量的整体评价中,即对g和q的子图进行匹配,寻找一个与q最相似的同构子图gsm。该离群点相似度度量如下:
离群点相似度,用经剪枝过后的离群点数量(outlier Number,ON)表示:

式中: dNum∈[0,1], Nq表 示图q中结点 V 的数量,图g和图q的相似距离表示为

式中:ci∈{0,1},0表示离群点,1表示符合阈值要求的结点, d (q,g)值越小则两图的相似度越大;故在G中,将与q相似距离最小的gm或gsm作为G与q的最终匹配结果:
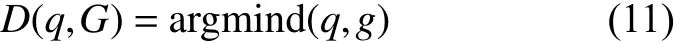
通过图相似性度量,得到与参考表单图最佳匹配的同构图gm或同构子图gsm,图5给出了一个待处理热敏表单最佳匹配结果。

图5 热敏表单图匹配结果Fig.5 Graph matching result for free form
2.3 待处理表单定位
如图5所示,参考表单与待处理表单的关键区域仅实现了部分对应,且匹配出的图像块不完整或轮廓不吻合,这是由于图像分割算法对复杂的字符图案分割不准确所致,这将直接导致表单提取的位置不准确。因此,本文在提取后处理过程中对匹配关键区域的位置进行修正,即迭代建立参考表单与待处理表单的位置映射函数,以此提高表单提取的准确性。通过映射函数,实现待处理表单上任意感兴趣区域的定位,从而完成表单信息的提取。
3 实验及分析
3.1 数据集
对快递包裹分拣机中采集的两类快递表单图像,建立多联表单(table like form,TF)和热敏表单(free form,FF)两类实验数据集,TF和FF共计1 477幅灰度快递表单图像。这些表单图像的分辨率偏转角度不同,且未进行归一化处理。其中TF为表格类图像,该类表单由制表单位统一印刷,表单内容依据表格线布局,包括中国邮政国内快递小包邮件详情单(C-XB)和EMS国内标准快递(EMS-MULT),这些图像的字符和图案较为清晰,其中有部分图像具有褶皱、模糊、扭曲或缺损、遮挡或字迹重叠等问题。FF数据集为非表格类表单图像,该类表单常见于物流集散点、商家网点自行打印,包括EMS标准快递(EMS-FLAT)和韵达快递表单(YUNDA),除存在上述TF数据集中特点以外,该数据集中表单印刷墨迹清晰度不一。另外,为验证算法在光照、尺度、旋转变换等情况下具有良好的鲁棒性,本实验将TF、FF数据集记为o-i,对o-i进行了旋转、缩放、亮度调节等扩展数据集。旋转扩展是对o-i分别旋转45°、90°、135°、180°,新增 r-1、r-2、r-3、r-4 扩展数据集。缩放扩展是对o-i缩扩放至原表单图像的75%、50%、125%、150%,新增s-1、s-2、e-1、e-2扩展数据集。亮度调节扩展是对o-i的亮度提高至原来的125%、150%和降低至原来的75%、50%,新增b-1、b-2、d-1、d-2扩展数据集。经过数据集扩充,本文实验的表单图像共计19 201幅。
3.2 评价标准
本文通过表单图匹配的置信度和表单相关信息的提取结果准确率来分析算法的性能。
首先,采用表单图匹配的置信度来衡量根据图匹配所建立的参考表单图像与待处理图像的映射是否可靠,该置信度由重叠率(average overlap,AO)和平均准确率 (mean average precision,MAP)来评定。如果映射的置信度高,那么表单信息提取的准确性也会提高。重叠率定义为映射过程中关键区域重合度比例的均值:
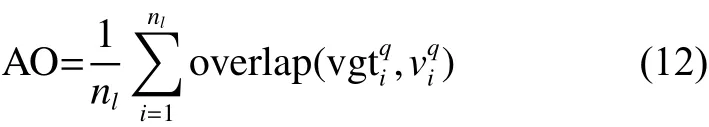
式中:nl为关键区域的数量,为参考表单关键区域的位置,为待处理表单图像上关键区域的定位结果, o verlap(·)表示区域的重叠率。
MAP是当重叠率AO高于某一阈值T时,则待处理表单的匹配位置为准确位置,故MAP表示为

式中:num(AO≥ T)表示阈值为T时准确定位的图像数量,I为测试图像的数量。
此外,采用标注工具LableImg标记待处理表单中提取区域真值,计算真值与检测目标交叠率(intersection-over-union,IOU),准确表示为

其中,IOU DetectionResult和GroundTruth表示信息提取区域检测位置和工具标注区域真值位置。
3.3 实验结果及分析
通过实验对TF、FF数据集分别计算了阈值T为0.5、0.6、0.7、0.8、0.9时图像的平均准确率和图像的平均重叠率(mean average overlap,MAO)。当T=0.8时,表示验证过程中参考表单和待处理表单中关键区域相互映射的重叠区域高于80%,实验表明:此时用于定位的映射关系相对准确,能实现大部分图像的准确定位和提取。因此本文实验将该阈值对应的MAP作为算法准确定位的置信度。
表1是TF、FF数据集的平均准确率和重叠率的实验统计情况,其中MAO反映了样本中通过映射关键区域的整体重合情况。数据显示:TF、FF中原图像数据集和扩展数据集的MAO主要分别在90%以上和80%以上,说明根据图匹配建立的关键区域映射关系,能较好的实现待处理表单与参考表单上关键区域的位置对应,因此可以通过这种映射进行表单的提取。TF、FF数据集的MAP大部分在87%~98%和75%~86%,这表明本文算法对多联表单和热敏表单具有良好的定位准确率。图6中,当T=0.9时,FF数据集的MAP相对TF数据集低约20%~30%,波动幅度较大,原因有以下两点:1)TF数据集中,关键区域均为表单出厂印制图案和字符,同类表单的差异较小,FF数据集表单印制要求不统一,故而差异较大;2)FF数据集为非表格类表单,其内容的自由度较大,选取关键区域的难度较大,可参照的关键区域少,因此建立表单映射时严格匹配的特征点对较少,因此对阈值高的AO的MAP值相对较低。图6,TF中原图像数据集在进行旋转、亮度调节变换后,平均准确率的变化趋于重合, FF数据集的平均准确率仅有小幅度范围内的波动。因此,该表单提取算法对旋转和亮度变化的图像具有良好的稳定性。另外,图6中图像缩至75%,T=0.8时,TF、FF数据集的分别为79.83%、70.11%,与原图像数据集o-i相比MAP分别下降了48.89%、19.54%, TF数据集s-2与原图数据集o-i和其他扩展数据集偏离幅度较大,FF数据集也有明显的降低。出现这种变化的原因有:图像缩小比率过大时,表单图像上关键区域块纹理信息损失较多,这将导致图匹配时可参考的正确位置少,同时过度缩小的图像使得关键区域中对应的特征点位置出现偏差,建立表单的映射关系缺乏准确的参考点,则重合度偏差大,准确率下降,定位不准确。总体来说,算法对旋转、亮度调节、放大变换、小幅度缩小变换的表单图像的提取能保持良好的稳定性。

表1 多联表单和热敏表单的平均重叠率和平均准确率Table1 Mean average overlap (MAO) and mean Average Precision (MAP) of TF and FF datasets

图6 多联表单和热敏表单平均准确率Fig.6 Mean average precision (MAP) of TF and FF
本文实验通过计算提取结果与LableImg工具标记真值交叠率来评估定位的准确性。常见目标检测系统中常将0.8交叠率值作为正确检测阈值,本文在评估提取区域的准确率和平均交叠率时,这两组值变化趋势与映射置信度变化大致相似。因此,仅在表2中列出两类图像评估结果的平均情况。对比表1和表2,说明图匹配结果越准确映射变换置信度越高,定位和提取的准确率越高。当IOU阈值为0.8时,多联表单和热敏表单提取准确率分别为97.41%和83.93%,说明本文算法对这两类表单具有良好的定位与提取效果。
通过图匹配结果对待处理表单的候选关键位置进行修正,使参考表单到待处理表单的位置映射关系更加准确。通过对上述图匹配和映射后置信度的评估,验证了算法能对表单图像进行良好的定位。据此,图7~10所示为表单图像中用户感兴趣关键区域的定位与提取结果,其中图7和图8为TF类表单图像,图9和图10为FF类表单图像。图7~10中(b)图的提取结果自上往下分别表示提取的收货人地址、姓名、手机号。上述4组表单图像具有不同分辨率、亮度、方向偏转、面单褶皱和形变的差异,定位结果说明本文算法能适应不同图像质量差异和不同类别的图像。由于保证了准确定位的置信度,分割得到的表单区域的字符较为完整、清晰、准确。此外,对表单分割得到的图像块进行简单的字符连通域合并,得到图7中4组表单相关信息的提取结果。

表2 多联表单和热敏表单的提取准确率Table2 Extraction precision of TF and FF datasets
本文方法与文献[10, 13-14]中方法类似,均为采用模板匹配的方法解决表单填写内容提取的问题,该方法的关键问题是实现参考表单和待处理图像配准。文献[10, 13]中采用傅里叶-梅林算法以表单局部区域或全局图像为配准目标,能实现不同方向的表单矫正,但该方法难以适应参考表单和待处理表单不同尺度的情况,不能准确找到表单图案的对应位置。此外文献[13]提取文本字符时的像素投票策略对图像噪声较为敏感,处理分拣机中现实采集到的污损和局部遮挡难以达到理想的提取效果。文献[14]中预先设定表单配准起始和终止参考点,作为表单方向校准的基准点,该方法更适用于具有相同分辨率、亮度和对比度的扫描图像,另外,当基准点出现异物遮挡或缺损的情况难以灵活处理。本文方法采用表单图匹配的方法以解决上述处理过程中存在的不足,根据不同表单已有的图案选取多个参考关键区域构建图,采用图匹配的配准方式以解决单一参考基准点鲁棒性差的问题。此外图匹配配准方式能更好的适应不同尺度、方向、分辨率、光照条件的图像,以及基准位置局部遮挡的问题。

图7 C-XB表单定位和提取结果Fig.7 Results for C-XB form Location and extraction
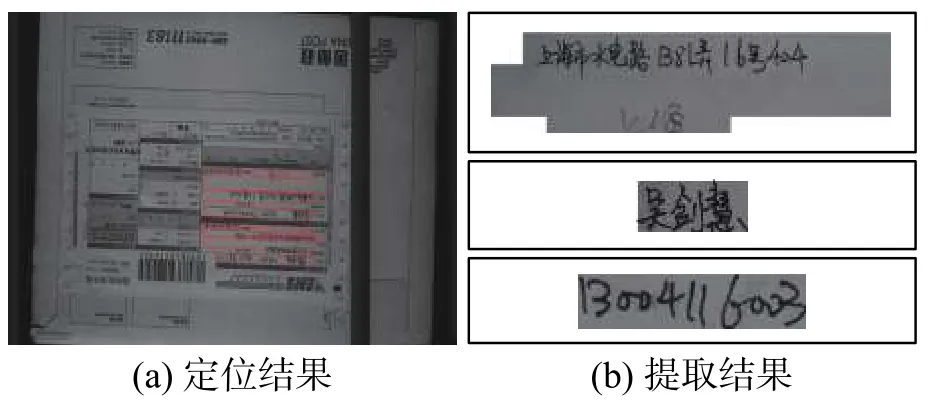
图8 EMS-MULT表单定位和提取结果Fig.8 Results for EMS-MULT form Location and extraction

图9 YUNDA表单定位和提取结果Fig.9 Results for YUNDA form Location and extraction

图10 EMS-FLAT表单定位和提取结果Fig.10 Results for EMS-FLAT form Location and extraction
4 结束语
本文提出了一种基于图表示和匹配的表单定位与提取方法,实验表明:本文方法适用于局部遮挡和不同类别、分辨率、方向、旋转、光照条件下的表单图像的处理,是一种通用的表单图像准确定位和相关区域的提取方法。虽然本文方法实现了大部分表单图像相关信息的准确定位和提取,但在缩小和单面形变幅度较大的图像上表现效果不佳,下一步将考虑采用不同方法建立表单关键区域的映射,以适应缩小比例大和较大范围形变图像的处理,同时,采用更为准确的后处理方法,去除无关的空白区域,使表单相关信息的提取精确到完整的字符串。
