基于云挖掘的物流信息智能分析应用平台研究
2016-02-24曾奕棠张玉峰
曾奕棠,张玉峰
(武汉大学信息管理学院,湖北武汉430072)
基于云挖掘的物流信息智能分析应用平台研究
曾奕棠,张玉峰
(武汉大学信息管理学院,湖北武汉430072)
摘要:物流信息日益大数据化,急需实现物流信息分析的智能化。云挖掘是由云计算技术支撑的并行数据挖掘,是实现物流信息智能分析的有效方法。基于云挖掘的物流信息智能分析应用平台具有超强的海量数据处理能力,有很强的可扩展性;用户无需自己开发应用软件,允许用户任意提交服务请求,能够有效处理和利用分布在各节点之间的数据和计算设备,可为不具备数据挖掘相关知识的用户提供“一站式服务”,使用户低成本地利用该平台。
关键词:物流信息;云挖掘;物流信息智能分析;云计算
一、引言
物联网、云计算等技术的广泛应用,使得大量的结构化、非结构化和半结构化数据聚集,大数据已成为重要的数据资产,在一个国家、行业、企业中的价值日益凸显。物流涉及多个业务流程,如采购、出库、入库、运输、保管、配送等,每一个业务流程都会产生大量数据。随着物流信息化的建设和“云物流”的推进,物流数据不仅包括结构化数据,也包括非结构化和半结构化数据;既包括静态数据,也包括动态数据。数据在规模上呈现加速度扩大的趋势,物流信息越来越呈现出大数据化。
物流信息的价值为越来越多的企业所认同,对物流信息进行分析从而得出有价值的认知和思想,成为企业、政府管理部门、行业等主体的追求。不过,传统的物流信息分析存在以下不足:
第一,数据获取手段落后。多以手工或半自动方式为主,需要耗费大量的人力、物力和财力,且效果一般,特别是面对越来越多激增的数据,更难以满足物流信息利益相关者的实时、准确需求;
第二,数据分析过程漫长。虽然也建立了各种分析模型,也能获得相应的分析结果,但过程长、耗时久,物流信息分析的效率低下,难以达到物流信息利益相关者的期望值,不能充分挖掘物流信息的价值;
第三,数据分析结果出错几率大。由于更多地是由专家根据经验对模型结果进行分析与判断,主观因素的影响明显,数据分析结果出错的几率较大,甚至有可能提供给利益相关者的信息和知识与其原始需求南辕北辙。
目前,用户对物流信息分析的智能化需求不断提升,希望通过物流信息智能分析来适时、高效地满足自己的信息需求,以提高决策的科学性。
二、云挖掘技术
(一)云挖掘的概念
经过20余年的发展,数据挖掘技术经历了五个发展阶段:第一代是数据的独立应用;第二代是数据库以及数据仓库集成出现;第三代是预测模型系统集成大量应用;第四代是分布式数据挖掘技术的产生和应用;第五代是基于云计算的并行数据挖掘与服务的发展。[ 1 ]传统的数据挖掘技术已很难适应海量数据的增长,对于实时数据或数据流的挖掘无能为力,难以满足个性化多样化的数据挖掘需求。基于海量的存储能力和强大的计算与数据处理能力,云计算已成为解决海量数据挖掘的有效方式。[ 2 ]第五代数据挖掘技术的出现,为大数据的深度开发与利用提供了前提和基础。
所谓云挖掘,是指由云计算技术支撑的并行数据挖掘,即基于云计算平台的并行动态数据挖掘,以实现海量数据的高性能、高可靠性的存储、分析、处理及挖掘。云挖掘的成功离不开以下关键技术:数据存储方式、基于云平台的数据预处理方式、适于云平台的海量数据挖掘并行算法。[ 3 ]
(二)云挖掘的实现原理
云挖掘能充分发挥集群优势,可实现计算资源自主分配和调度。一方面利用集群上的其他节点来承担相应的存储任务和计算任务;另一方面利用云计算的海量存储能力和并行计算能力,来处理核心的数据挖掘工作,让算法通用、可调、可查和可视,同时提供友好、方便的用户界面和开放接口,让用户在客户端完成隐私数据的加密保护,满足用户的多样化和个性化需求。[ 4 ]
云挖掘的实现原理如下:
1.用户利用计算机、平板电脑、手机等终端,登录云挖掘系统,提出自己的挖掘需求,并可结合自身的具体情况,设置相应的算法参数,同时输入基本数据;
2.云挖掘系统收到用户的挖掘需求后,立即响应需求,对工作节点的空闲状态进行分析,将挖掘任务交由空闲的工作节点去完成;
3.云挖掘系统基于用户之前提交的需求与算法参数,对用户输入的数据和从分布式存储系统中调用的数据推导计算缺值数据,完成数据类型转换、滤除噪声、消除重复记录等预处理工作;
4.云挖掘系统的工作节点自动选择相应的数据挖掘算法,对经过预处理后的数据进行并行数据挖掘,经过模式评估与解释后,获得对用户有用的信息与知识;
5.云挖掘系统将各工作节点的挖掘结果进行合并,选择合适的可视化工具,将挖掘结果传递给用户。
三、基于云挖掘的物流信息智能分析应用平台的架构设计
(一)逻辑架构
基于云挖掘的物流信息智能分析应用平台从逻辑上可以分为6个层次:用户交互层、平台应用层、平台管理层、物流信息分析层、虚拟化资源层、基础设施层,如图1所示。
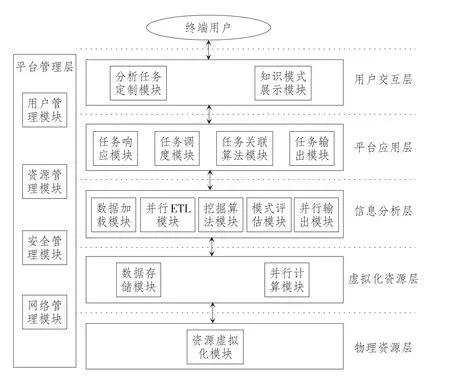
图1 基于云挖掘的物流信息智能分析应用平台的逻辑架构
该平台的“智能分析”主要包括利用虚拟化技术实现虚拟化资源层的建设和物流信息分析层利用云挖掘技术实现虚拟化资源层数据的算法分析这两部分,前者类似于商务智能中的数据仓库,后者类似于商务智能中的数据挖掘,进而形成三种主要的物流信息智能分析方法:基于云分类挖掘的物流信息智能分析方法、基于云聚类挖掘的物流信息智能分析方法、基于云关联挖掘的物流信息智能分析方法。
1.用户交互层
该层为用户与平台交互的通道,实现用户与物流信息智能分析平台之间的数据交互,用户只要有授权,就可以通过相应的接口来登录平台,既可以向平台提出物流信息分析请求,也可以获得平台提供的物流信息分析可视化结果。通过用户交互层,实现了平台与用户之间的按需服务。
2.平台应用层
该层是根据物流信息利益相关者所提出的需求,对用户提供满足其需求的应用,如满足物流企业在路线规划、合作伙伴选择、运输成本优化、运营决策、货物流向分析等方面的业务需求。
3.平台管理层
该层对物流信息智能分析平台提供管理及服务,既包括对用户的管理,如用户定制服务、身份验证、许可管理等,也包括对资源的管理,如资源监控、负载均衡、内容管理、集群管理、故障检测处理等,还包括对平台的安全管理,如基础设施安全管理、系统安全管理、网络安全管理、应用安全管理、平台安全管理、用户安全管理和数据安全管理等。
4.物流信息分析层
该层是整个平台的核心,采用MapReduce作为分布式并行计算模型,结合物流信息利益相关者的信息需求,实现对底层资源的调用,通过对获得的物流信息进行存储管理、数据清理、算法调用、数据挖掘、结果评估、结果输出等作业,达到物流信息智能分析的结果,并以服务方式供平台应用层调用。
5.虚拟化资源层
该层是整个平台的基础,利用虚拟化技术实现应用虚拟化和硬件虚拟化,整合分散的物理资源,从而构建相应的资源池,包括服务器、网络、数据库、应用软件等资源,资源池中的同类资源形成集群,对资源直接操作和优化调度。[ 5 ]虚拟化资源层能为上层提供虚拟系统、虚拟环境、虚拟平台等虚拟化功能,可作为服务对外提供,并对资源的实时状态进行监控与管理。
6.物理资源层
该层是整个平台的基石,为平台提供底层必需的设施与设备,包括机房、电源、云服务器、云传输设备、云存储设备、网络设备及其他硬件物理资源,通过资源虚拟化技术组成一个超强功能的计算机集群,对以上各层提供物理支撑,满足各层正常运行的计算和存储等需求。
(二)逻辑功能模块
1.分析任务定制模块
该模块是指用户登录平台后,根据自身的需求,确定物流信息智能分析任务,这也是物流信息智能分析工作的起点。用户定制任务的形式多样,无论何时、何地,也不管采用什么接入终端,只要能链上平台,就可以利用交互界面提出自己的需求,由平台来完成后续的物流信息分析与结果提供。
2.知识模式展示模块
该模块是平台根据用户的定制任务,调用相应数据挖掘算法对数据进行挖掘后,借助于交互界面,将处理好的知识模式以图形化的方式展现给用户,实现用户对物流信息分析结果的查看、分析和保存等功能。用户能随时查看需要的知识模式,并将展示的知识模式用于自己的运营决策之中,从而实现对物流信息分析结果的应用。
3.任务响应模块
该模块直接与分析定制模式衔接,接收用户提交的物流信息分析任务,对用户提交的物流信息分析任务进行响应。只有经过响应的物流信息分析任务,才能传送到任务调度模块,才有可能引发后续的相应分析任务。该模块相当于物流信息智能分析应用平台的把关器。
4.任务调度模块
该模块是在接收到任务响应模块的指令后,根据用户提交的任务请求,对完成物流信息分析任务所需的子业务进行调用、管理,调度物流信息分析层的多个模块来完成物流信息分析任务,并将分析结果传递给任务输出模块。
5.任务关联算法模块
该模块主要是对与用户物流信息分析任务相关联的算法进行管理和保存,既包括用户之前使用过的算法,又包括有开发能力的用户自己开发的算法或在原有算法基础上改进的算法,也包括用户计划出售的、拥有产权的算法。如果用户能在关联算法模块找到并有能力使用相应的算法,则将直接调用物流信息分析层的相关模块,实现物流信息的分析与应用。
6.任务输出模块
该模块在用户交互层与物流信息分析层之间起着连接的作用,将物流信息分析结果返回给用户交互层,为用户返回可视化任务执行结果,作为知识模式展示模块的源泉。
7.数据加载模块
该模块是根据用户的物流信息分析任务,或从外部的节点集群中导入符合数据格式的相关物流数据,或从数据存储系统中获取需要分析的数据,用于此次物流信息分析,同时按MapReduce框架并行化后,将外部数据提交到虚拟化资源层,存放到系统的开放式文件系统(如HDFS)中。
8.并行ETL模块
该模块主要用于对源数据进行预处理,对存储在分布式存储系统中的数据进行抽取、转换、清洗与集成等预处理工作,降低数据的异构性,保证数据完整一致,提高数据的质量,保证数据适合于云计算环境下的MapReduce计算模型,为接下来的数据挖掘服务。通过该模块,可去除噪声数据和重复数据,处理不完整数据,识别并提取关键数据,统一数据格式,保存在HDFS中,为数据挖掘做准备。
9.挖掘算法模块
该模块是整个平台中最重要的模块,其功能是实现挖掘算法的并行化,包括并行分类算法、并行关联规则算法和并行聚类算法,构成一个能提供各种基于云计算进行并行数据挖掘算法的库,然后提交到虚拟化资源层,实现海量物流数据的挖掘任务。该模块作为数据挖掘的引擎,能在Ha⁃doop平台中将传统挖掘算法进行并行化处理,即将这些算法Map/Reduce化,实现挖掘算法库的自动更新、补充与删除,使之能够部署到云计算平台的分布式环境中并行执行。[ 6 ]
10.模式评估模块
该模块是对挖掘出的模式进行性能评估,如可靠性、可信度等。该模块同时还承载着结果对比的功能,让用户可以对同一任务进行多种方法挖掘或多次挖掘,对不同的挖掘结果进行对比,为用户提供更为可靠合理的结果。模式评估模块可以被挖掘算法模块调用。
11.并行输出模块
该模块是从虚拟化资源层获得挖掘结果,存放挖掘产生的各种模式,同时将数据挖掘的结果以表格或图形等方式反馈给平台应用层。
12.数据存储模块
该模块是存储海量物流数据,通过分布式文件系统HDFS,将一个大的数据文件分割为多个小文件块,将海量物流数据分布存储在多台计算机集群上,发挥MapReduce可伸缩性的优势,既为并行计算提供临时的存储空间,同时也为数据挖掘结果提供持久化的存储空间,成为知识库的保存空间,使数据挖掘有大量的数据保障和知识保障。[ 7 ]该模块能对存储的信息进行管理,如数据备份、数据模型管理等。为实现对海量物流数据的存储与管理,并为并行计算提供数据支持,还需要建立各类数据的属性索引信息和空间索引信息。
13.并行计算模块
该模块是凭借Hadoop提供的MapReduce分布式计算框架,使用并行工作模式,对算法并行化执行,可将一个任务分解成多个子任务,从而在云平台上获得对海量数据的处理能力。每个任务将被分为Map和Reduce两类任务集,分布式地执行实际的挖掘任务,当有大量用户同时提出挖掘请求时,实现分布式挖掘任务的高效调度,运行相应的挖掘算法,完成数据挖掘计算能力的并行,然后将处理结果汇总,迅速给予回应并提供服务。[ 8 ]
14.资源虚拟化模块
该模块是利用虚拟化技术,将底层的分布式网络设备、存储器、服务器和安全设备等接入到网络中,以抽象的数字化表达方法进行统一描述与封装,将各类异构的存储、计算和网络资源虚拟化为虚拟资源,抽象为可调配的资源,构成一个服务器集群与运行环境,形成全局统一的大型虚拟资源池,实现各类网络节点资源的全面互联。该模块采用集群技术进行统一调度管理,对外提供统一的访问接口,实现物理资源的集成和管理,实现
计算资源、存储资源和网络资源的透明访问,满足虚拟化资源层、物流信息分析层正常运行的需求。
15.用户管理模块
该模块主要是对利用物流信息智能分析平台的各个节点企业和用户信息进行管理,提供统一的接口路径,用于识别用户身份、注册管理服务、提供用户交互接口、创建用户程序的执行环境、用户权限设置、用户交互管理、消息管理及对用户的使用计费等工作。
16.资源管理模块
该模块主要是对物流信息智能分析应用平台的资源进行均衡调配,优化配置资源,实现资源利用效率的提升。
17.安全管理模块
该模块主要是负责物流信息智能分析应用平台的整体安全,通过集中管理和使用VPN、防火墙、防病毒、IDS、数据加密、访问授权、身份认证、安全审计等多种安全方法,实现网络安全、基础设施安全、系统安全、平台安全、数据安全、应用安全和用户安全等,构建完整的安全防护体系。
18.网络管理模块
该模块是对物流信息智能分析应用平台的网络体系进行管理,通过故障检测、故障恢复、监视统计等工作,保障网络的正常运转,为用户提供畅通的网络接口与网络应用。
(三)物理架构
基于云挖掘的物流信息智能分析应用平台,将在大型物流企业及其下属分支机构、供应商、渠道商等层面都设立节点,利用虚拟化技术形成资源集群,物理资源池则由节点资源集群形成。物理资源池汇聚在云计算数据中心,能够实现数据存储、算法设计、数据分析及信息服务。分布式集群服务器构成云计算数据中心。基于云挖掘的物流信息智能分析应用平台要能充分利用网络中大量的廉价资源,在Hadoop平台的集群环境下,将数据预处理、数据挖掘算法等任务进行并行处理。数据预处理后的结果由分布式文件系统HDFS来进行分布式的存储,存储在节点磁盘中;数据挖掘任务采用MapReduce编程模型,由分布在各处的节点计算机来并行处理,实现挖掘算法的并行编程模式,其物理架构如图2所示。
第一,用于智能分析的物流信息在地理分布上具有分散性,不同地理位置的物流信息由不同的节点集群进行收集、整理、分类与处理,并由节点集群对资源进行自行维护。利用虚拟化技术,将所有资源分配到虚拟机。虚拟机对各节点集群资源进行管理、协调与分配,是一种集群式云计算服务器。
第二,云计算数据中心由三层构成:云管理及云服务层、服务器集群层和虚拟机层。云管理及云服务层是云计算数据中心在软件即服务和平台即服务上的体现,云管理服务器主要负责对集群服务器进行管理,调度与分配计算资源和存储资源,并对外提供平台服务;云应用服务器主要负责向用户提供物流信息智能分析服务。服务器集群层作为云计算数据中心的核心,由大规模的集群服务器构成,提供海量存储能力和高性能计算能力,既间接管理节点集群的资源,又直接管理虚拟服务器,通过虚拟化技术,为用户提供整体化基础设施服务。虚拟机层由众多运行在服务器上的虚拟机系统构成,负责管理节点集群资源,利用映射技术,将节点集群资源映射到服务器集群层。
第三,应用服务采用B/S模式,物流信息利益相关者通过网络即可访问应用服务,从而获得自己需要的物流知识与信息。

图2 基于云挖掘的物流信息智能分析应用平台物理架构
四、基于云挖掘的物流信息智能分析应用平台的特点
(一)平台各逻辑层之间的结构内部是相互独
立的,每层都透明地为其上层服务。各层的任务非常明晰,通过各层之间的接口,上层可以调用其直接或间接的下层所有功能。同层之间的功能模块能够有效共享和调用数据,有利于各层集中处理各自的任务,便于平台的设计和关键技术的解决。
(二)平台具有超强的海量数据处理能力,具有很强的可扩展性。用户可以利用良好的用户界面,根据自己的需要,对平台功能进行拓展,从而得到自己需要的物流知识与信息。
(三)用户无需自己开发应用软件,允许用户任意提交服务请求。可以通过交互层的相关功能模块定制物流数据挖掘对象、物流数据挖掘任务、物流数据挖掘算法等,而数据集的存储、算法的执行过程等都运行在Hadoop平台上。[ 9 ]
(四)平台采用分布式并行数据挖掘来挖掘与分析物流数据,能够有效处理和利用分布在各节点之间数据和计算设备。统一信息格式,实现多模块、多源、多格式、多媒体数据的存储和计算,实现实时高效的物流信息分析。
(五)平台为不具备数据挖掘相关知识的用户提供“一站式服务”。用户无需了解平台内部的功能,也不用担心平台的存储与计算能力的不足,平台具备良好的结果展示能力,将不同算法的结果进行比较后能以可视化的形式输出。
(六)用户无需建立机房和数据中心,可以低成本地利用信息分析平台。用户可根据需要获取存储空间、计算能力和信息分析服务,节省了用户的信息化成本,同时也能强化大型物流企业在供应链中核心节点的地位,提升供应链的竞争力。
参考文献:
[1] Sheryl A. S.,Ananth J. P..Parallel Processing Agents For Data Mining With Cloud Computing & Multi-Agent Sys⁃tems[J].International Journal of Applied Engineering Re⁃search,2015(7):17469-17478.
[2]周晏,桑书娟.浅谈基于云计算的数据挖掘技术[J].电脑知识与技术,2010(34):9681-9683.
[3]李金凤,姜利群.基于微软云计算平台的海量数据挖掘系统[J].电脑知识与技术,2011(34):8766-8768.
[4]杜艳绥.基于Hadoop云计算平台的数据挖掘分析[J].信息技术与标准化,2013(4):36-39.
[5]Joan M. John,G. Venifa Mini,E. Arun.User Profile Tracking by Web Usage Mining in Cloud Computing[J].Proce⁃dia Engineering,2012(10):3270-3277.
[6]Fernadez Alberto,Peralta Daniel,Benitez Jose Manu⁃el,Herrera Francisco.E-learning and Educational Data Min⁃ing in Cloud Computing:an Overview[J].International Journal of Learning Technology,2014(1):25-52.
[7]Cuzzocrea Alfredo. Models and Algorithms for High-Performance Data Management and Mining on Computational Grids and Clouds[J].Journal of Grid Computing,2014(3):443-445.
[8]Kong Xiongsheng. Scientific Data Mining and Process⁃ing Using MapReduce in Cloud Environments[J].Journal of Chemical & Pharmaceutical Research,2014(6):1270-1276.
[9]Fei Long.Research on Algorithms of Data Mining Un⁃der Cloud Computing Environment[J].Journal of Chemical & Pharmaceutical Research,2014(7):1152-1157.
责任编辑:方程
The Research of Intelligent Analyzing Application Platform of Logistics Information Based on Cloud Mining
ZENG Yi-tang and ZHANG Yu-feng
(Wuhan University,Wuhan,Hubei430072,China)
Abstract:With the logistics information becoming big data,realizing the intelligent analyzing of logistics information is emergent. Cloud mining is a parallel data mining supported by cloud computing technology;it is an effective method to realize the intelligent analyzing of logistics information. The intelligent analyzing application platform of logistics information based on cloud mining has superpower in processing massive data and very extensible;it is not necessary for the users to develop app;and the users can be allowed to submit requirement of service at their option;this platform can effectively take advantage of data and computing equipment naturally distributing among different nodes,provide the users with“one stop service”,and reduce the cost of users.
Key words:logistics information;cloud mining;intelligent analyzing of logistics information;cloud computing
作者简介:曾奕棠(1978—),女,湖南省株洲市人,武汉大学信息管理学院博士生,主要研究方向为电子商务与知识管理;张玉峰(1946—),女,河南省封丘县人,武汉大学信息管理学院教授,博士生导师,主要研究方向为信息系统工程、人工智能、知识管理与电子商务。
基金项目:国家自然科学 “基于动态数据挖掘的物流信息智能分析研究”(项目编号:71373197)。
收稿日期:2015-10-12
中图分类号:F490.5
文献标识码:A
文章编号:1007-8266(2016)01-0031-06
