一个新的超记忆梯度法及全局收敛性
2015-12-20李双安陈凤华程慧燕
李双安,陈凤华,程慧燕
(河南理工大学万方科技学院 公共基础教学部,河南 郑州 450026)
教学教育研究
一个新的超记忆梯度法及全局收敛性
李双安,陈凤华,程慧燕
(河南理工大学万方科技学院 公共基础教学部,河南 郑州 450026)
文章提出了一个新的超记忆梯度法解决无约束优化问题.该算法沿着目标函数的下降方向进行搜索,每步迭代提出的算法都充分地利用了前面多步迭代信息,避免目标函数海瑟阵的储存和计算,因此它适合解决大规模无约束优化问题.在适当的假设条件下,证明了所提出的算法具有全局收敛性.数值实验表明此算法的可行性.
无约束优化;超记忆梯度法;非单调线搜索;全局收敛性;数值实验
本文考虑如下优化问题:

其中f∶Rn→R为连续可微函数.
求解问题(1)有很多迭代方法,如线搜索和信赖域方法,见文献[1].线搜索方法迭代公式如下:

这里dk是f(x)在xk处的搜索方向,αk为搜索步长.
为方便,记(fxk)为fk,∇f(xk)为gk.
在线搜索方法中,每一步迭代只用当前迭代信息生成下一步迭代,前面几步的迭代信息被忽略.这对于设计一个高效算法而言是信息的浪费.共轭梯度法用前一步的迭代信息生成下一步的迭代,搜索方向定义如下:

共轭梯度法的优势是避免了牛顿型方法中矩阵的计算和存储,因此它适合解决大规模优化问题[2].
记忆梯度和超记忆梯度是共轭梯度法的推广,因此它们和共轭梯度法有相同的性质.与共轭梯度法相比,记忆梯度法和超记忆梯度法充分利用前几步迭代的信息生成一个新的迭代,这对于设计一个快速收敛的算法十分有效[3].
基于无约束优化问题的牛顿方法,Grippo等人提出了非单调线搜索技术[4],搜索步长αk满足下面的条件:

这里σ∈(0,1),m(0)=0,0≤m(k)≤min{m(k-1)+ 1,M},M是预设非负整数.
非单调技术或结合共轭梯度法,记忆梯度法的变化形式甚至被推广到信赖域方法,它可以用来解无约束优化问题,见文献[5-6].此外,戴彧虹给出了非单调线搜索策略的理论证明.文献[7]中指出,非单调性方法增加了找到全局最优解的可能性,大量的数值实验已表明非单调方案是有效的,尤其对于较困难的优化问题.
尽管基于(3)式的非单调技术在大多数情况下性能良好,但是它也有一些缺点,许多情况下数值效果取决于M值的选取.
受到前面方法的启发,本文提出了一个修正的非单调策略超记忆梯度法解无约束优化问题(1).在每一步迭代,提出的方法充分利用前面多步信息,避免了目标函数海瑟阵的存储和计算,因此它适合解决大规模无约束优化问题.在某些条件下,证明提出的算法具有全局收敛性,且数值实验表明本文提出的算法是可行的.
1 新的超记忆梯度法
由前m步迭代信息构造搜索方向dk(m为一给定正整数):

修正非单调线搜索技术计算步长αk如下,αk= βmk,其中mk是满足下列不等式的最小非负整数:
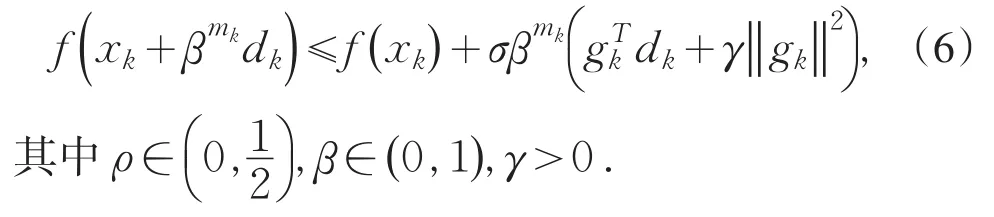
修正非单调线搜索(6)下超记忆梯度算法步骤如下:
算法1 新的超记忆梯度算法:

步骤1:计算gk.若,算法停止;否则转下一步;
步骤2:计算(4)式定义的搜索方向dk;
步骤3:确定满足(6)式的步长αk;
步骤4:令xk+1=xk+αkdk;
步骤5:循环.令k≔k+1,转步骤1.
下面给出修正非单调线搜索超记忆梯度算法的两个性质如下:
引理1 对任一线搜索,搜索方向由(4)式定义,则有

引理1表明搜索方向dk是目标函数f(x)在xk处的下降方向.
引理2 对任意的k,有
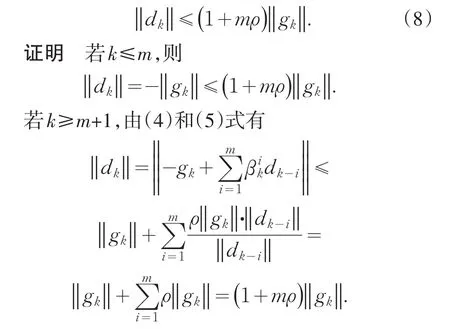
故对任意的k,结论得证.
显然,由(7)和(8)式有

2 全局收敛性分析
为保证全局收敛性,对问题(1)作如下基本假设:
(H1)目标函数f(x)在水平集
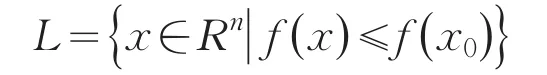
有界.
(H2)(fx)的梯度函数g(x)在闭凸集B⊂L(x0)上是Lipschitz连续的,即存在某一常数L>0满足

引理3 若假设条件(H1)、(H2)成立,则算法1是良定的,即存在一个步长αk使得(6)式成立.
证明 由(6)式有

即证.
引理4 若假设条件(H1)、(H2)成立,γ∈(0,1-mp),则存在一常数η>0使得


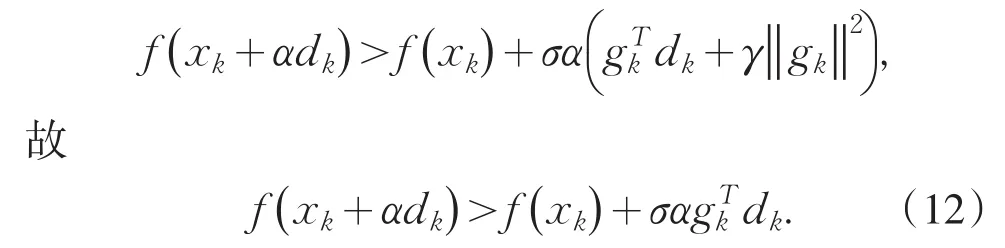
由中值定理,存在θk∈[0,1]使得

由(12)、(13)式有

由假设条件(H2)及柯西-施瓦兹不等式,有
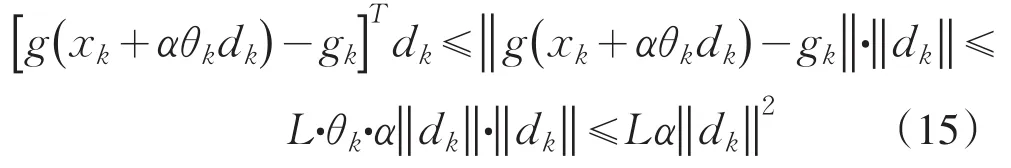
又由(14)、(15)式有
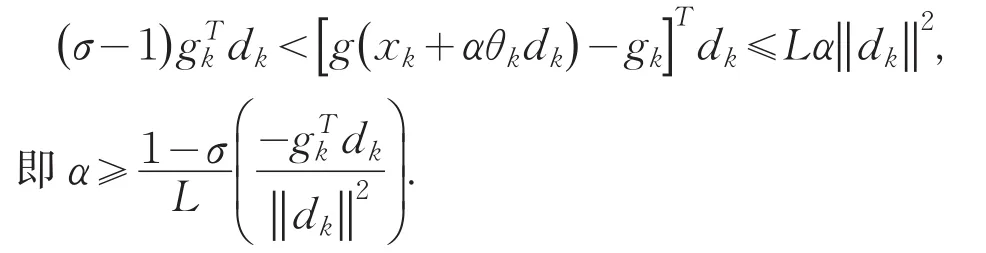
上式结合(9)式有

由(6)、(7)式有

定理1 若假设条件(H1)、(H2)成立,γ∈(0,1-mρ),则对某一k有gk=0或
证明 由引理3,引理4及文献[8]定理8的证明即证得结论.
3 数值实验
为进一步从数值计算的角度分析算法的可行性,通过Matlab编程将算法进行数值实验,实验结果表明本文提出的新的超记忆梯度法是可行的.算法中m=5,β=0.5,σ=0.2.

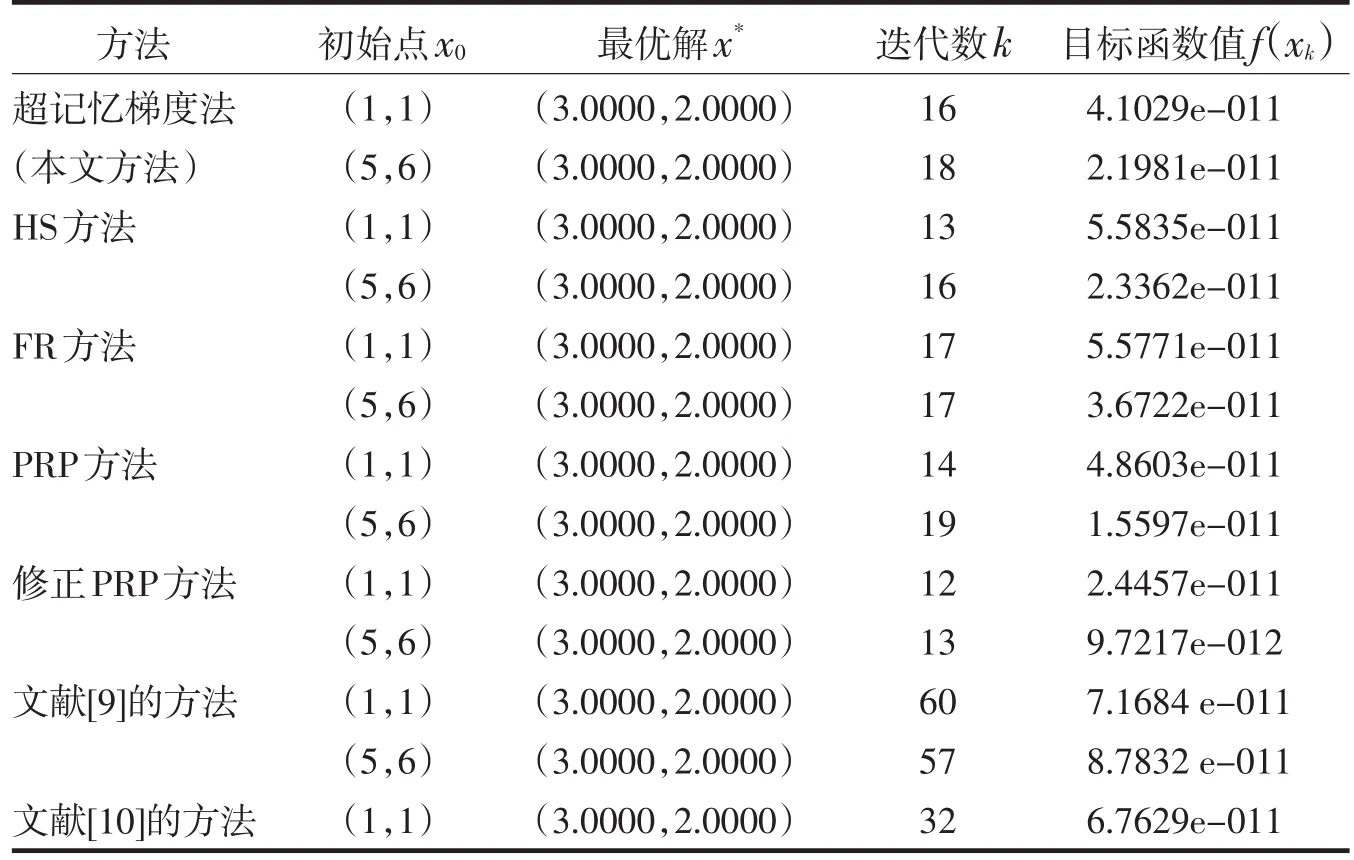
表1 问题1的数值实验结果Tab.1 Numerical results for question 1
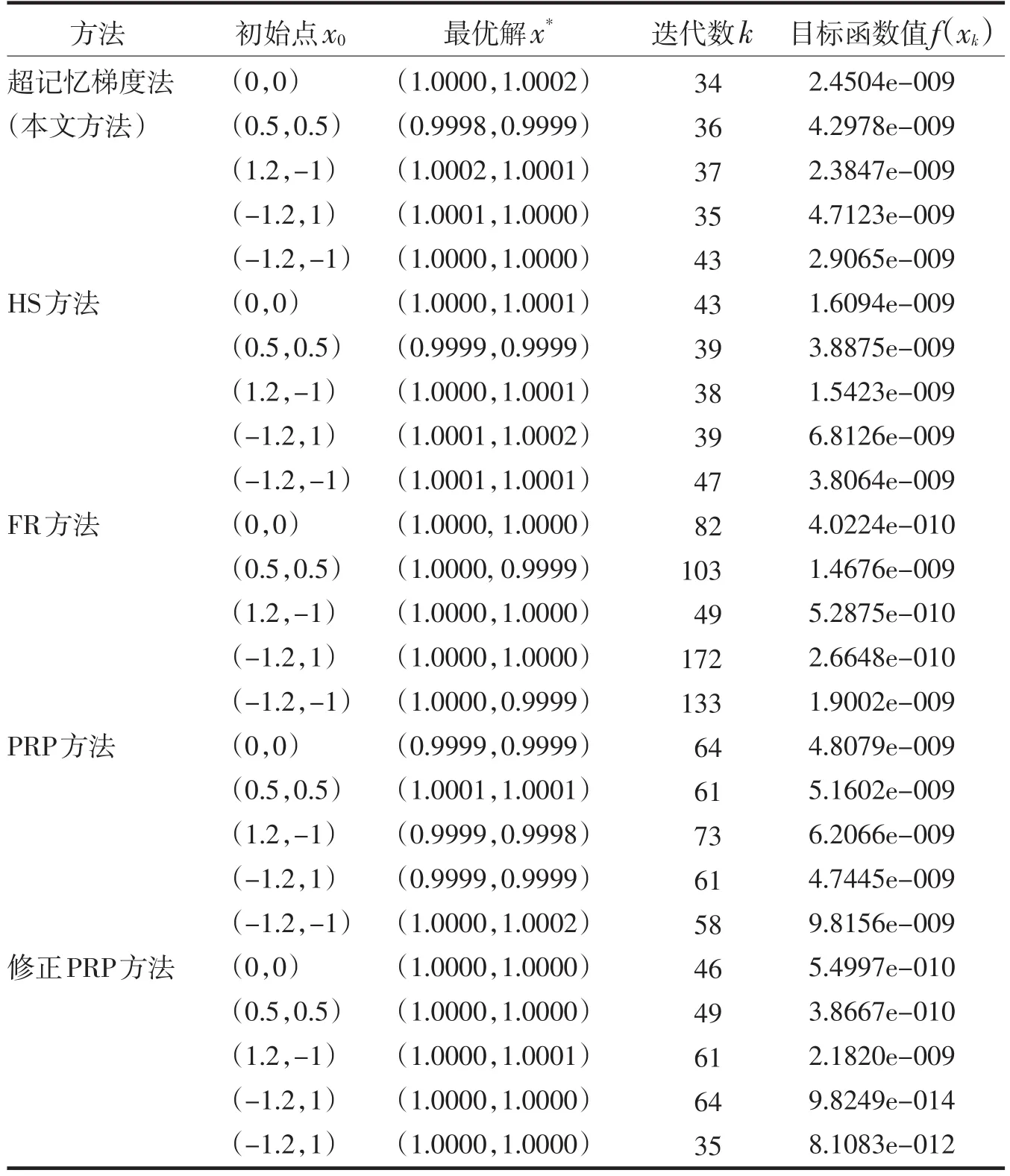
表2 问题2的数值实验结果Tab.2 Numerical results for question 2
4 结论
本文提出了一个新的超记忆梯度法,该算法的特点:
1)搜索方向总是目标函数的下降方向,且不依赖于使用何种线搜索;

表3 问题3-8的数值实验结果Tab.3 Numerical results for question 3-8
2)每步迭代,充分利用前面多步迭代信息,避免了目标函数海瑟阵的存储和计算,算法适合解大规模无约束优化问题.
在适当的假设条件下,本文证明了提出的新的超记忆梯度法具有全局收敛性,且数值实验结果表明本文提出的算法是可行的.
[1]Sun W Y,Yuan Y S.Optimization theory and methods[M]. New York:Springer,2006.
[2]Dai Y.Nonlinear conjugate gradient methods[M].Wiley En⁃cyclopedia of Operations Research and Management Science, 2011.
[3]Zheng Y,Wan Z.A new variant of the memory gradient method for unconstrained optimization[J].Optimization Letters,2012,6(8):1643-1655.
[4]Grippo L,Lampariello S,Lucidi F.A nonmonotone line search technique for newton's method[J].SIAM Journal on Numerical Analysis,1986,23(4):707-716.
[5]Liu H G,Jing L L,Han X,et al.A class of nonmonotone conjugate gradient methods for unconstrained optimization [J].Journal of optimization theory and applications,1999,101 (1):127-140.
[6]Shi Z,Wang S,Xu Z.The convergence of conjugate gradi⁃ent method with nonmonotone line search[J].Applied Mathematics and Computation,2010,217(5):1921-1932.
[7]Dai Y H.On the nonmonotone line search[J].J of Optim Theory and Appl,2002,112(2):315-330.
[8]Ou Y,Liu Y.A nonmonotone supermemory gradient algo⁃rithm for unconstrained optimization[J].Journal of Applied Mathematics and Computing,2014,46(2):215-235.
[9]房明磊,张聪,陈凤华.一种新的Wolfe线搜索技术及全局收敛性[J].桂林电子科技大学学报,2008,28(1):62-65.
[10]陈凤华,张聪,房明磊.曲线搜索下的新的记忆拟牛顿法[J].广西科学,2008,15(3):254-256.
责任编辑:刘 红
A New Supermemory Gradient Method and the Global Convergence
LI Shuang’an,CHEN Fenghua,CHENG Huiyan
(Wanfang Institute of Science and Technology,Henan Polytechnic University,Zhengzhou 450026,China)
In this paper,we propose a new supermemory gradient method for unconstrained optimization.An attractive prop⁃erty of the proposed method is that the direction generated by the method is always a descent for the objective function.The proposed method sufficiently uses the previous multi-step iterative information at each iteration and avoids the storage and computation of matrices associated with the Hessian of objective functions.Therefore,it is suitable to solve large-scale un⁃constrained optimization problems.Under appropriate conditions,we show that the new supermemory gradient method with nonmonotone line search is globally convergent.Numerical experiments show that the proposed algorithm is effective.
unconstrained optimization;supermemory gradient method;nonmonotone line search;global convergence;nu⁃merical experiments
O 224
A
1674-4942(2015)03-0237-05
2015-06-09
国家自然科学基金(11361018);广西杰出青年基金(2012GXSFFA060003);河南省教育厅科学技术研究重点项目(12B110011);高等学校重点科研项目(15B110008)
